pax_global_header�����������������������������������������������������������������������������������0000666�0000000�0000000�00000000064�14730024002�0014502�g����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������52 comment=a80d261de8958cd20887b2db0f2c9b97cfb74ef0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/����������������������������������������������������������������������0000775�0000000�0000000�00000000000�14730024002�0016157�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.dockerignore���������������������������������������������������������0000664�0000000�0000000�00000000124�14730024002�0020630�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������.git
.cache
.*
_*
*.cache
*.pyc
build
*.egg-info
gource*
*.tar.gz
*.pdf
TODO
*.lock
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.github/��������������������������������������������������������������0000775�0000000�0000000�00000000000�14730024002�0017517�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.github/workflows/����������������������������������������������������0000775�0000000�0000000�00000000000�14730024002�0021554�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.github/workflows/badge.svg�������������������������������������������0000664�0000000�0000000�00000006164�14730024002�0023346�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.github/workflows/cleanup.yml�����������������������������������������0000664�0000000�0000000�00000000724�14730024002�0023731�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
name: Delete old workflow runs
on:
schedule:
- cron: '0 15 14 * *'
# Run monthly, at 15:00 on the 14t day of month. (testing)
jobs:
del_runs:
runs-on: ubuntu-latest
permissions:
actions: write
steps:
- name: Delete workflow runs
uses: Mattraks/delete-workflow-runs@v2
with:
token: ${{ github.token }}
repository: ${{ github.repository }}
retain_days: 30
keep_minimum_runs: 6
��������������������������������������������LanguageMachines-frog-a80d261/.github/workflows/frog.yml��������������������������������������������0000664�0000000�0000000�00000007513�14730024002�0023242�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
name: C/C++ CI
on:
schedule:
# Run monthly, at 4:00 on the 10t day of month.
- cron: "0 4 10 * *"
push:
branches:
- master
- develop
paths:
- configure.ac
- 'src/**'
- 'include/**'
- .github/workflows/**.yml
pull_request:
branches: [master]
jobs:
notification:
runs-on: ubuntu-latest
name: Notify start to gitlama
steps:
- name: IRC notification
uses: LanguageMachines/ticcactions/irc-init@v1
- name: Cancel Previous Runs
uses: styfle/cancel-workflow-action@0.12.1
with:
access_token: ${{ github.token }}
build:
needs: notification
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, macos-latest]
compiler: [g++-12, clang++]
steps:
- uses: actions/checkout@v4.1.1
- uses: LanguageMachines/ticcactions/cpp-build-env@v1
- uses: LanguageMachines/ticcactions/cpp-dependencies@v1
- uses: LanguageMachines/ticcactions/setup-cppcheck@v1
- uses: LanguageMachines/ticcactions/irc-nick@v1
- name: Install Special Dependencies
run: |
if [ "$RUNNER_OS" == "Linux" ]
then
sudo apt-get install expect
else
brew install telnet
fi
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
branch: ${{ github.ref_name }}
module: ticcutils
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
branch: ${{ github.ref_name }}
module: libfolia
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
branch: ${{ github.ref_name }}
module: timbl
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
branch: ${{ github.ref_name }}
module: mbt
- uses: LanguageMachines/ticcactions/add-textcat@v1
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
module: uctodata
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
branch: ${{ github.ref_name }}
module: ucto
- uses: LanguageMachines/ticcactions/cpp-submodule-build@v1
with:
module: frogdata
- name: Static Code-check
if: ${{ env.action_status == '' }}
run: cppcheck ${{ env.cpc_opts }} .
- uses: LanguageMachines/ticcactions/cpp-safe-build@v1
- name: Notify IRC of build result
uses: LanguageMachines/ticcactions/irc-status@v1
with:
branch: ${{ github.ref_name }}
nickname: ${{ env.nick }}
step: build
status: ${{ env.action_status }}
details: ${{ env.action_details }}
- name: frogtests
id: frogtests
if: ${{ env.action_status == '' }}
run: |
git clone --depth=1 --single-branch https://github.com/LanguageMachines/frogtests.git
cd frogtests
frog_bin=/usr/local/bin LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib ./testaction.sh
TEST_STAT=$(cat status.tmp)
if [ $TEST_STAT != 0 ]
then
echo "action_status=frogtests" >> $GITHUB_ENV
fi
echo "action_details=$TEST_STAT errors" >> $GITHUB_ENV
continue-on-error: true
- name: log problems
if: >-
${{ env.action_status == '' &&
steps.frogtests.outcome != 'success' }}
run: |
cat frogtests/*.err
cat frogtests/*.diff
- name: Notify IRC of end result
uses: LanguageMachines/ticcactions/irc-status@v1
with:
branch: ${{ github.ref_name }}
nickname: ${{ env.nick }}
step: testing
status: ${{ env.action_status }}
details: ${{ env.action_details }}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.gitignore������������������������������������������������������������0000664�0000000�0000000�00000001237�14730024002�0020152�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*.tar.gz
ChangeLog
INSTALL
Makefile
Makefile.in
aclocal.m4
autom4te.cache/
compile
config.guess
config.h
config.h.in
config.log
config.status
config.sub
configure
depcomp
libtool
ltmain.sh
stamp-h1
test-driver
frog.*.debug
docs/Makefile
docs/Makefile.in
frog.pc
include/Makefile
include/Makefile.in
include/frog/Makefile
include/frog/Makefile.in
install-sh
m4/Makefile
m4/Makefile.in
m4/ax_lib_readline.m4
m4/ax_pthread.m4
m4/libtool.m4
m4/ltoptions.m4
m4/ltsugar.m4
m4/ltversion.m4
m4/lt~obsolete.m4
m4/pkg.m4
missing
src/.deps/
src/.libs/
src/*.lo
src/*.o
src/*.la
src/frog
src/mbma
src/mblem
src/ner
src/test-suite.log
src/tst.out
src/tst.sh.log
src/tst.sh.trs
build/
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/.travis.yml�����������������������������������������������������������0000664�0000000�0000000�00000007562�14730024002�0020302�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������--- # frog.yml
sudo: required
group: edge
dist: bionic
# whitelist
branches:
only:
- master
notifications:
irc:
channels:
- "irc.uvt.nl#gitlama"
template:
- "%{repository_slug}#%{build_number}-%{branch} : \
%{message} --> %{build_url}"
skip_join: true
language: cpp
matrix:
include:
- os: linux
compiler: g++
cache: ccache
env:
- SCAN=echo
- os: linux
compiler: clang++
cache: ccache
env:
- SCAN=scan-build
- OPENMPFLAG=--disable-openmp
- os: osx
osx_image: xcode11
compiler: clang++
cache:
directories:
- $HOME/Library/Caches/Homebrew
before_cache:
- brew cleanup
env:
- SCAN=echo
before_install:
- if [[ "$TRAVIS_OS_NAME" == "linux" ]]; then
sudo apt-get update;
sudo apt-get install pkg-config autoconf-archive autotools-dev ccache;
sudo apt-get install cppcheck libicu-dev libxml2-dev libbz2-dev;
sudo apt-get install zlib1g-dev libtar-dev;
sudo apt-get install expect libexttextcat-dev;
fi
- if [[ "$TRAVIS_OS_NAME" == "osx" ]]; then
brew update;
brew install pkg-config;
brew install autoconf-archive;
brew install telnet;
brew install libxml2;
brew install bzip2;
brew install zlib;
brew install libtar;
brew install cppcheck;
brew install ccache;
brew install libtextcat;
brew install icu4c;
brew install llvm;
export PATH="/usr/local/opt/llvm/bin:$PATH";
export LDFLAGS="-L/usr/local/opt/llvm/lib";
export CXXFLAGS="-I/usr/local/opt/llvm/include $CXXFLAGS";
fi
- export PATH="/usr/lib/ccache/bin/:/usr/local/opt/ccache/libexec/:$PATH"
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/ticcutils
- cd ticcutils
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/libfolia
- cd libfolia
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/uctodata
- cd uctodata
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/ucto
- cd ucto
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/timbl
- cd timbl
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/mbt
- cd mbt
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/frogdata
- cd frogdata
- bash bootstrap.sh
- ./configure $OPENMPFLAG
- make
- sudo make install
- cd ..
install:
- bash bootstrap.sh
- ./configure $OPENMPFLAG
# - cat config.log
- cppcheck --enable=all --quiet --error-exitcode=0 .
- $SCAN --status-bugs make
- make
- sudo make install
script:
- export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
- make check
- git clone --depth=1 --single-branch https://github.com/LanguageMachines/frogtests.git;
- cd frogtests
- export frog_bin=/usr/local/bin
- if [[ "$TRAVIS_OS_NAME" == "osx" ]]; then
./testmac >&2 ;
else
./testall.sh >&2 ;
fi
after_failure:
- for file in *.diff; do echo DIFF in $file; cat $file; done
- diff issue71_e_2_out.xml issue71_e_2.out.ok.xml
- for file in *.log; do echo SERVER LOGS in $file; cat $file; done
# - for file in *.err; do
# echo ERRORS in $file;
# cat $file; cat $(echo $file| cut -f 1 -d '.').out;
# done
����������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/AUTHORS���������������������������������������������������������������0000664�0000000�0000000�00000001127�14730024002�0017230�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Authors:
People who wrote and rewrote the Frog code, starting from 0.1
Bertjan Busser
Antal van den Bosch
Maarten van Gompel
Ko van der Sloot
Contributors:
People who contributed code for NLP modules that found
their way into Frog:
Sander Canisius (CSI-DP)
Jakub Zavrel (MBT)
Supporters:
People who contributed to Frog by suggesting improvements,
filing bug reports, asking the right questions etc.:
Matje van de Camp
Walter Daelemans
Jesse de Does
Iris Hendrix
Micha Hulsbosch
Emmanuel Keuleers
Martin Reynaert
Erik Tjong Kim Sang
Manos Tsagkias
Frederik Vaassen
Tim Voets
and many others.
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/COPYING���������������������������������������������������������������0000664�0000000�0000000�00000104513�14730024002�0017216�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������ GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc.
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
Copyright (C)
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see .
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
Copyright (C)
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/Dockerfile������������������������������������������������������������0000664�0000000�0000000�00000002763�14730024002�0020161�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������FROM alpine:latest
#VERSION can be:
# - stable: builds latest stable versions from source (default)
# - distro: uses packages as provided by Alpine Linux (may be slightly out of date)
# - devel: latest development version (git master/main branch)
ARG VERSION="stable"
LABEL org.opencontainers.image.authors="Maarten van Gompel "
LABEL description="Frog - A Tagger-Lemmatizer-Morphological-Analyzer-Dependency-Parser for Dutch, container image"
RUN mkdir -p /data
RUN mkdir -p /usr/src/frog
COPY . /usr/src/frog
RUN if [ "$VERSION" = "distro" ]; then \
rm -Rf /usr/src/frog &&\
echo -e "----------------------------------------------------------\nNOTE: Installing latest release as provided by Alpine package manager.\nThis version may diverge from the one in the git master tree or even from the latest release on github!\nFor development, build with --build-arg VERSION=development.\n----------------------------------------------------------\n" &&\
apk update && apk add frog; \
else \
PACKAGES="libbz2 icu-libs libxml2 libexttextcat libgomp libstdc++" &&\
BUILD_PACKAGES="build-base autoconf-archive autoconf automake libtool bzip2-dev icu-dev libxml2-dev libexttextcat-dev git" &&\
apk add $PACKAGES $BUILD_PACKAGES &&\
cd /usr/src/ && ./frog/build-deps.sh &&\
cd frog && sh ./bootstrap.sh && ./configure && make && make install &&\
apk del $BUILD_PACKAGES && rm -Rf /usr/src; \
fi
WORKDIR /
ENTRYPOINT [ "frog" ]
�������������LanguageMachines-frog-a80d261/MAINTAINERS�����������������������������������������������������������0000664�0000000�0000000�00000000155�14730024002�0017655�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Maarten van Gompel (KNAW Humanities Cluster)
Ko van der Sloot
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/Makefile.am�����������������������������������������������������������0000664�0000000�0000000�00000000617�14730024002�0020217�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������ACLOCAL_AMFLAGS = -I m4 --install
SUBDIRS = src include m4 docs tests
EXTRA_DIST = bootstrap.sh AUTHORS TODO NEWS README.md codemeta.json
pkgconfigdir = $(libdir)/pkgconfig
pkgconfig_DATA = frog.pc
ChangeLog: $(top_srcdir)/NEWS
git pull; git2cl > ChangeLog
docker:
docker build -t frog:latest .
docker-dev:
docker build -t frog:dev --build-arg VERSION=development .
deps:
./build-deps.sh
�����������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/NEWS������������������������������������������������������������������0000664�0000000�0000000�00000043457�14730024002�0016673�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������0.34 - 2024-04-26
[Ko van der Sloot]
* require C++17
* require latest ticcutils and libfolia
* some code refactoring
* improved GitHub CI
* removed dependency on libtar
0.33 - 2024-04-26
[Ko van der Sloot]
* --KANON was not always hounored
* after a change in ucto, it was needed to reset the tokenizer more often
* in the lemmatizer, fuzzy matching of CGN tags is implemented
0.32 - 2023-12-05
[Ko van der Sloot]
* ignore but warn on empty derivations, a lame fix for https://github.com/LanguageMachines/frog/issues/103
0.31 - 2023-10-21
[Ko van der Sloot]
* use ticcutils > 0.34. NFC normalizations is standard now
* use Tokenizer::config_prefix() instead of magic string 'tokconfig-'
* code cleanup and quality improvement (cppcheck is very useful)
[Maarten van Gompel]
* added frog demo gif
0.30 - 2023-05-08
[Ko van der Sloot]
* finally fixed a major memory-leak in MBMA which bothered me for months
* also some minor leaks are plugged
0.29 - 2023-05-05
[Ko van der Sloot]
* added a fix for https://github.com/LanguageMachines/frog/issues/100
(where Frog created invalid FoLiA in a cornercase)
* improved api_test
* small code refactorings
* require libfolia >= 2.15, for correct working of word correction
* improved MWU code. Using Unicode strings and detecting MWU's with a starting
Capital.
[Maarten van Gompel]
* .gitignore: added build dir
0.28 - 2023-02-28
[Ko van der Sloot]
* We no longer accept FoLiA paragraphs with both Words and Sentences.
[Maarten van Gompel]
* Software metadata fix
0.27.2 - 2023-02-23
[Maarten van Gompel]
* Minor software metadata fix only, no functional changes
0.27.1 - 2023-02-22
[Maarten van Gompel]
* Software metadata update only, no functional changes
0.27 - 2023-02-22
[Ko van der Sloot]
* Major Release.
* Internally we always perform a 'deep' morphological analysis.
* This information is used for XML and JSON output.
* For the 'classic' Tabbed output, we maintain backward comptability.
* You need to specify '--deep-morph' to get the deep analysis in the output.
* You may also specify '--compounds' to get an extra column with compound
information.
Other changes:
* C++ code quality
* adapted to more recent Timbl implementations (Unicode awareness)
* Tokenizer:
- Better handling of --languages option.
- 'und' is now also acceptable as a "language"
- Better debugging possibility
* Mbma: To many alternatives with Inverted Verbs were generated. As the
Tagger doesn't help us directly, we filter on the person of the next
word, and only return V/te2I when the next word is 2-nd person
0.26 - 2023-01-02
[Ko van der Sloot]
* fix for https://github.com/LanguageMachines/frog/issues/96
* code improvements, readability and fixing CppCheck warnings
* needs recent ticcutils (>=0.30)
* needs newest Timbl (6.8) for more Unicode awarenes
* updated GigHub action
[Maarten van Gompel]
* added MAINTAINERS file
* updated codemeta.json
0.25 - 2022-07-22
[Maarten van Gompel]
* updated metadata (codemeta.json) following new (proposed) CLARIAH requirements (CLARIAH/clariah-plus#38)
* added builds-deps.sh for automatically building and installing dependencies
* added Dockerfile and instructions
* added support for user-based configuration dirs ($XDG_CONFIG_HOME/frog), takes precedence over global data dirs
[Ko vd Sloot]
* updated Doxygen config file
0.24 - 2021-12-15
[Ko vd Sloot]
* start using the newest UTF8 aware Timbl and Mbt and Ucto
* use NFC normalized UnicodeString more general internaly
* added a fix in MBMA codng, to get better reproducable result on different
OS/Compiler combinations
* lots of small refactoring
* bumped library version, because of some API changed
[Maarten van Gompel]
* merged a patch suggested by Helmut Grohne
- configure.ac: Bug#993123: frog FTCBFS: hard codes the build
architecture pkg-config Source: frog Version: 0.20-2
Tags: patch upstream User:
debian-cross@lists.debian.org Usertags:
ftcbfs frog fails to cross build from source, because configure.ac hard
codes the build architecture pkg-config in one place (after
correctly detecting the host architecture one). Simply using the
correct substitution variable makes frog cross buildable. Please
consider applying the attached patch.
Helmut Signed-off-by: Maarten van Gompel
0.23 - 2021
* requires libfolia 2.9
* replaced TravisCI by GitHub actions
* fixed https://github.com/proycon/python-frog/issues/20
* some refactoring to avoid unneeded creation of files
0.22 - 2020-11-17
[Ko vd Sloot]
* start using the tmp_stream() class form ticcutils 0.25
0.21 - 2020-07-22
[Ko van der Sloot]
* Fixes a problem with temporary files not being cleaned up properly #92
0.20.1 - 2020-04-15
[Ko vd Sloot]
Bug fix release.
- added missing Doxygen.cfg to the tarball
0.20 - 2020-04-15
[Ko vd Sloot]
* added Doxygen to the build
* added a lot of comment in Doxygen format
* adapted to the newest ticcutils version
* adapted to latest libfolia
* adapted to latest ucto
* lots of code refactorings
* implemented --JSONin option (server only)
* implemented --JSONout option
* added a --allow-word-correction option which allows ucto to correct FoLiA
Word nodes
[Iris Hendrix]
Documentation updates
0.19.1 - 2019-11-15
[Ko vd Sloot]
* fixed an overseen incompatability problem with the new libfolia.
(https://github.com/proycon/tscan/issues/13)
* removed dependency on MbtServer
* Some documentation updates
* improved using Alpino, using unique filenames now.
0.19 - 2019-10-21
[Ko vd Sloot]
* added code to use al locally installed Alpino parser
* added code to use a remote Alpino Server
* added code to use (remote) timblservers and mbtservers for alle modules
using JSON calls. Stil experimental.
* several code refactoring and small fixes:
- memory leaks
- using NER files in non-standard locations
- bug fixes for some corner cases.
* frog.*.debug files are cleaned up after 1 day.
0.18.3 - 2019-07-22
[Ko vd Sloot]
Bug fix release:
* Fixes:
- https://github.com/LanguageMachines/frog/issues/78
0.18.2 - 2019-07-15
[Ko vd Sloot]
Bug fix release:
* Fixes for:
- https://github.com/LanguageMachines/frog/issues/75
- https://github.com/LanguageMachines/frog/issues/77
0.18.1 - 2019-06-19
[Ko vd Sloot]
Bug fix release:
"tabbed" output contained 1 tab to much when --skip=a was specified
0.18 - 2019-06-19
[Ko vd Sloot]
Bug fixes and enhancements:
* provenance uses new 'generate_id' option in libfolia:processor
* solved problems when frogging partly tokenized FoLiA
* solved problems when processing with --skip=t
* small improvement in compound detection (still more to do...)
0.17 - 2019-05-29
[Ko vd Sloot]
This release supports FoLiA 2.0
* some bug fixes
- trust the tokenizer to get the default language
- don't stumble upon empty sentences introduced by a non-breaking-space
- provenance data is added for all the modules
0.16 - 2019-05-15
[Ko vd Sloot]
This is the last release using pre FoLiA 2.0
It includes a total rework of the Frog Internals, aiming at better
maintainability and hoping for a speedup and a smaller memory footprint.
This work will continue in the upcoming release for FoLiA 2.0
Major Changes:
* total rework. Not using a FoLiA document as the internal datastructure anymore
but a FrogData structure.
* use folia::engine for all FoLiA processing
* -Q option is NOT supported anymore. It was unreliable anyway
* builds on the newest ucto versions only
* fix for https://github.com/proycon/LaMachine/issues//135
https://github.com/LanguageMachines/frog/issues/66
* handles some corner cases in FoLiA better
* lots of code cleanup
* numerous small fixes ( e.g. in NER and MBMA results)
* improved working of --languages option
* avoid invalid FoLiA: https://github.com/LanguageMachines/frog/issues/60
* fixed memory leaks
* better handling of weird FoLiA
[Maarten van Gompel]
* added skeleton for new Frog documentation
0.15 - 2018-05-16
[Ko vd Sloot]
* ucto_tokenizer_mod: removed call of (useless) ucto:setSentenceDetection(true)
* fix to close the server when a socket fails
* when frogging a file, and the docID is NOT specified, use the filename as
the docID (filtering out non-NCName characters)
* fix building the documentation from TeX files
* a lot of small code improvements
[Maarten van Gompel]
* added codemeta.json
* Fixed python-frog example in documentation (closes #48)
0.14 - 2018-02-19
[Ko vd Sloot]
* use TiCC::UniFilter now
* use TiCC::diacritics_filter now
* configuration modernized. OSX build supported too
* XML (FoLiA) files are autodetected
* some more logging and time stamps added
* added code to NER module to override original tags (e.g. from gazeteer)
0.13.9 - 2017-11-07
[Ko vd Sloot]
Bug fix release, to get all our releases into balance. (Toad release
requires 0.13.9)
0.13.8 - 2017-10-26
[Ko vd Sloot]
* Now with new and enhanced NER and IOB chunker. (needs Frogdata >0.15)
* added -t / --textredundancy option, which is passed to ucto
* set textclass attributes on entities (folia 1.5 feature)
* better textclass handling in general
* multiple types of entities (setnames) are stored in different layers
* some small provisions for 'multi word' words added. mblem may use them
other modules just ignore them (seeing a multiword as multi words)
* added --inpuclass and --outputclass options. (prefer over textclass)
* added a --retry option, to redo complete directories, skipping what is done.
* added a --nostdout option to suppress the tabbed output to stdout
* refactoring and small fixes
[Maarten van Gompel]
* new --override option
0.13.7 - 2017-01-23
* Data files are now in share/ rather than etc/ (requires frogdata >= v0.13)
0.13.6 - 2017-01-05
[Ko van der Sloot]
* rework done on compounding in MBMA. (still work in progress)
* lots of improvement in MBMA rule handling. (but still work in progress)
- support for 'glue' rules added.
- support for 'hidden' morphemes added.
- proper CELEX tags are outputted now in the XML
- some structure labels have better names now
* removed exit() calls from library modules (issue #17)
* added languages option which is handled over to ucto too.
- detect multiple languages
- handle a selected language an ignore the rest
0.13.5 - 2016-09-13
* Added safeguards against faulty data
* Added manpage for ner tool (issue #8)
* Added some more compounding rules
* Read and display frogdata version
0.13.4 - 2016-07-11
[Ko van der Sloot]
- added long options --help and --version
- interactive use is limited to TTY's only, so pipes from std in work
- added a --language='name' option. it tries to read the configuration from
a subdirectory with 'name' in the configdir
The default is 'nl'
- tokenizer timing is fixed at last
- be robust agains a missing clex tag
- better warning when OpenMP is not present
- adaptation in mbma
- added 2 convenience functions to FragAPI:
get_full_morph_analysis() and
get_compound_analysis()
- CompoundType is now in it;s own namespace
- some code refactoring, as usual
0.13.3 - 2016-03-10
[Ko van der Sloot]
* Now based on libfolia 1.0
* lot of code refactoring
* minor bug fixes
0.13.0 - 2015-09-28
[Ko van der Sloot]
* moved repository to GitHub
* added Travis support
* First version without Python dependencies!
The CSI parser is implemented in C++
* use more stuff from >ticcutils (BasicServer)
* frog now runs on a minimal configurations too
* a lot more stuff is configurable (te become more language independent)
* added NER lookup from a file
* mbma is improved.
Doesn't have the "eer" and "ere" hacks anymore
does hande C tags/inflections better
better 'daring' mode
adds some comopund info
* fixed the mbma_prog and mblem_prog to run without a tagger or tokenizer
* added a 'ner' commandline tool
* a lot of smaller bug fixes and code refactoring
0.12.20 - 2015-01-29
[Ko van der Sloot]
* release
* fixed terrible bug in FrogServer (unitialized MWU could happen)
0.12.19 - 2014-12-01
[Ko van der Sloot]
* release
* some bug fixes for FoliA support
0.12.18 - 2014-09-16
* A true FrogAPI is added
* depends on ticcutils 0.6 or above (for CommandLine mostly)
* a lot of changes in the MBMA module. It now can produce nested morphemes
using the --daring option of frog. Still experimental!
* Frog can now run interactive with readline support too.
* -t option is optional, multiple inputfiles are supported
* -o works for multiple files
* -d works better now (--debug even better)
* added xml:id to Entities and Chunks
* a lot off small bug fixes
0.12.17 - 2013-04-03
* the servermode now kan handle multiline input (non XML only).
Can be switched off with the -n option.
* A lot of refactoring regarding FoLiA stuff
* start using ticcutils
* the -Q option now works
* added a --uttmarker option
* added mbma and mblem programs
* updated man pages
0.12.16 - 2013-02-19
* bug fix release. Some stuff was moved from Timbl to libticcutils
0.12.15 - 2012-03-29
* using the new Mbt 3.2.8 API for Tagging.
The code is much simpler and less error-prone now.
* depends on libfolia 0.9
* improved mblem module: tags for alternative readings, faster too
* refactoctoring all over the place
* We no longer ship the datafiles. Use frogdata package instead
0.12.14 - 2012-02-29
* NER was disabled. fixed
0.12.13 - 2012-02-27
* adapted to libfolia 0.8, which is more strict on set definitions
* added an IOB NER
* added a --max-parser-tokens option
* the mwu list is reduced a lot (by AntalB)
* fixed a threading problem
* code refactoring continues
0.12.12 - 2012-02-09
[Ko vd Sloot]
* fixed stupid error in frog-dp-update script
* added a manpage for that script
0.12.11 - 2012-02-09
[Ko vd Sloot]
* added a simple script: frog-dp-update.sh
this installs the DP config and a full functional frog.cfg
* some small cleanups in iob-chunker code.
* added newest chunker configuration, now also gives confidence values
* fixed some problems with iob chunker
0.12.10 - 2012-02-06
[Ko vd Sloot]
* now frog ships with small-frog.cfg. Larger config is to be distributed
separately from the DPconfig directory.
* made debug handling better and the same for all modules
* added IOB chunker
* added -x option
* added --xmldir option
* fixed --skip=t. It was totally ignored!?
* removed the 0.12.2 patch. TimblServer solves it now.
* fixed problem with tags containing //
* update usage()
* updated man page
0.12.9 - 2012-01-12
[Ko vd Sloot]
* fixed threading problems.
* split very long function into 2 parts
[Maarten van Gompel]
* when in servermode, set_omp_num_threads(1). Otherwise every call
to the server would start extra threads.
0.12.8 - 2012-01-10
[Ko vd Sloot]
* fixed argument escaping problem when calling libfolia
[ Maarten van Gompel ]
* fixed a typo in cgn_tagger_mod
0.12.7 - 2012-01-05
* fixed compilation on GNU/Hurd
* temporary parserfiles get a unique name now (using the pid).
0.12.6 - 2011-12-22
* merged with the foliabased branch. So now we use the folia based Tokenizer.
folia XML is now the main interface between the modules in Frog.
0.12.5 - 2011-10-10
* is released
0.12.4 - ??
* missing in action
0.12.3 - 2011-08-23
[Ko vd Sloot]
* added a column for confidence. Needs the most recent Timbl and Mbt!
* changed the behaviour of the -Q option. (adapt to ucto 0.4.7)
[ Maarten van Gompel ]
* moved nasty sentence per line patch away, support now in ucto itself
0.12.2 - 2011-04-19
[ Maarten van Gompel ]
* fixed max read buffer (2048 byte) problem in server mode
0.12.1 - 2011-04-18
[ Ko vd Sloot ]
* added a fixed mbma.igtree file
* better reaction when startup fails. Try to bail out asap.
0.12.0 - 2011-03-21
{ Ko vd Sloot ]
* decapped progs and man
0.11.1 - 2011-03-20
[ Joost van Baal ]
* NEWS: record changes and releases
* docs/Frog.1, docs/Makefile.am: add Frog.1 .so link: consistent with name of
binary
0.11.0 - 2011-03-17
[ Ko van der Sloot ]
* Reworked mblem and mbma: less dependant on tagger results
* minor fixes
* more stuff is handled in parallel (work in progress)
* docs/frog.1: added a man page
[ Antal van den Bosch ]
* config/mblem.tree: "weesten" issue
* config/mblem.tree: let's hope this tree file reverts to the correct encoding
situation
* config/mblem.tree, config/mblem.tree.wgt: fixed "emmen" and "vrienden" errors
0.10.4 - 2011-03-01
[ Ko van der Sloot ]
* configure.ac: We need the most recent ucto!
* Makefile.am: now bootstrap works
[ Maarten van Gompel ]
* src/Frog-util.cxx: when using testdir, ignore hidden files (dotfiles)
* src/Frog.cxx: sentence per line on input side
* src/Frog.cxx: prettier help output
0.10.3 - 2011-02-27
[ Joost van Baal ]
* scripts/Makefile.am, scripts/pylet/{data,util}/Makefile.am: Minor changes
to make life easier for software packagers. Install python code and
compiled python in sane locations.
[ Ko van der Sloot ]
* src/Frog.cxx: added a '-n' option to do 'one sentence per line' tokenizing.
0.10.2 - 2011-02-13
[ Joost van Baal ]
* Minor changes to make life easier for software packagers.
0.10.1 - 2011-02-12
[ Joost van Baal ]
* configure.ac: merge frog-ng patch to deal with unavailable icu 4.6
[ Ko van der Sloot ]
* configure.ac: we need ucto >= 0.3.6
* src/Frog.cxx: added -e option to set the encoding
* configure.ac: bumped version, now uses ucto-icu.pc
[ Antal van den Bosch ]
* config/Frog.mwu.1.0, config/Makefile.am, config/frog.cfg,
config/mwu.suspects5: moved to a more comprehensive MWU file
based on the Lassy + Alpino treebanks
0.9.3 - 2010-01-26
[ Ko van der Sloot ]
* New release
[ Maarten van Gompel ]
* 2010-08-30 Added paragraph detection, added beginofsentence role, restyled
view of usage options, implemented '--stok' mode for tokenisation (one
sentence per line), roles are now shown explicitly in verbose tokeniser
output. (0.6)
* 2010-08-17 Improved server mode, without intermediate files (new tokeniser
only) (0.5)
* 2010-05-11 Integrated new tokeniser (from ucto) (0.3?)
2008-06-01 Ko vd Sloot
Source is moved to SVN
2007-12-03 Ko vd Sloot
Finished packaging.
2007-10-09 Started packaging
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/README����������������������������������������������������������������0000664�0000000�0000000�00000000053�14730024002�0017035�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Please see README.md for more information.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/README.md�������������������������������������������������������������0000664�0000000�0000000�00000016500�14730024002�0017440�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������[](https://github.com/LanguageMachines/frog/actions/)
[](https://frognlp.readthedocs.io/?badge=latest)
[](http://applejack.science.ru.nl/languagemachines/)
[](https://zenodo.org/badge/latestdoi/20526435) [](https://GitHub.com/LanguageMachines/frog/releases/)
[](https://www.repostatus.org/#active)
# Frog - A Tagger-Lemmatizer-Morphological-Analyzer-Dependency-Parser for Dutch
Copyright 2006-2020
Ko van der Sloot, Maarten van Gompel, Antal van den Bosch, Bertjan Busser
Centre for Language and Speech Technology, Radboud University Nijmegen
Induction of Linguistic Knowledge Research Group, Tilburg University
KNAW Humanities Cluster
**Website:** https://languagemachines.github.io/frog
Frog is an integration of memory-based natural language processing (NLP)
modules developed for Dutch. All NLP modules are based on Timbl, the Tilburg
memory-based learning software package. Most modules were created in the 1990s
at the ILK Research Group (Tilburg University, the Netherlands) and the CLiPS
Research Centre (University of Antwerp, Belgium). Over the years they have been
integrated into a single text processing tool, which is currently maintained
and developed by the Language Machines Research Group and the Centre for
Language and Speech Technology at Radboud University Nijmegen. A dependency
parser, a base phrase chunker, and a named-entity recognizer module were added
more recently. Where possible, Frog makes use of multi-processor support to run
subtasks in parallel. Frog offers a command-line interface (that can also run
as a daemon) and a C++ library.
Various (re)programming rounds have been made possible through funding by NWO,
the Netherlands Organisation for Scientific Research, particularly under the
CGN project, the IMIX programme, the Implicit Linguistics project, the
CLARIN-NL programme and the CLARIAH programme.
## Demo
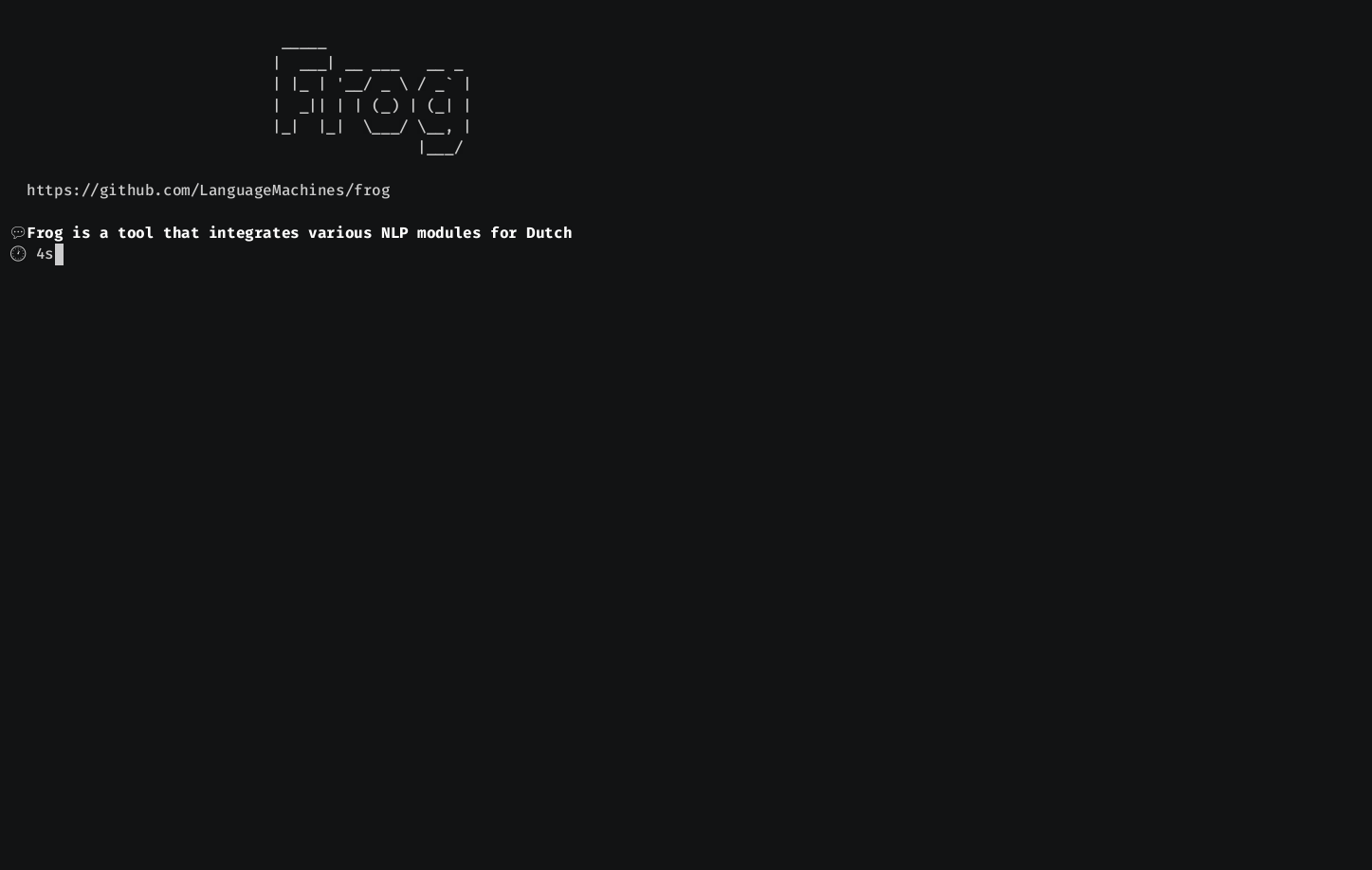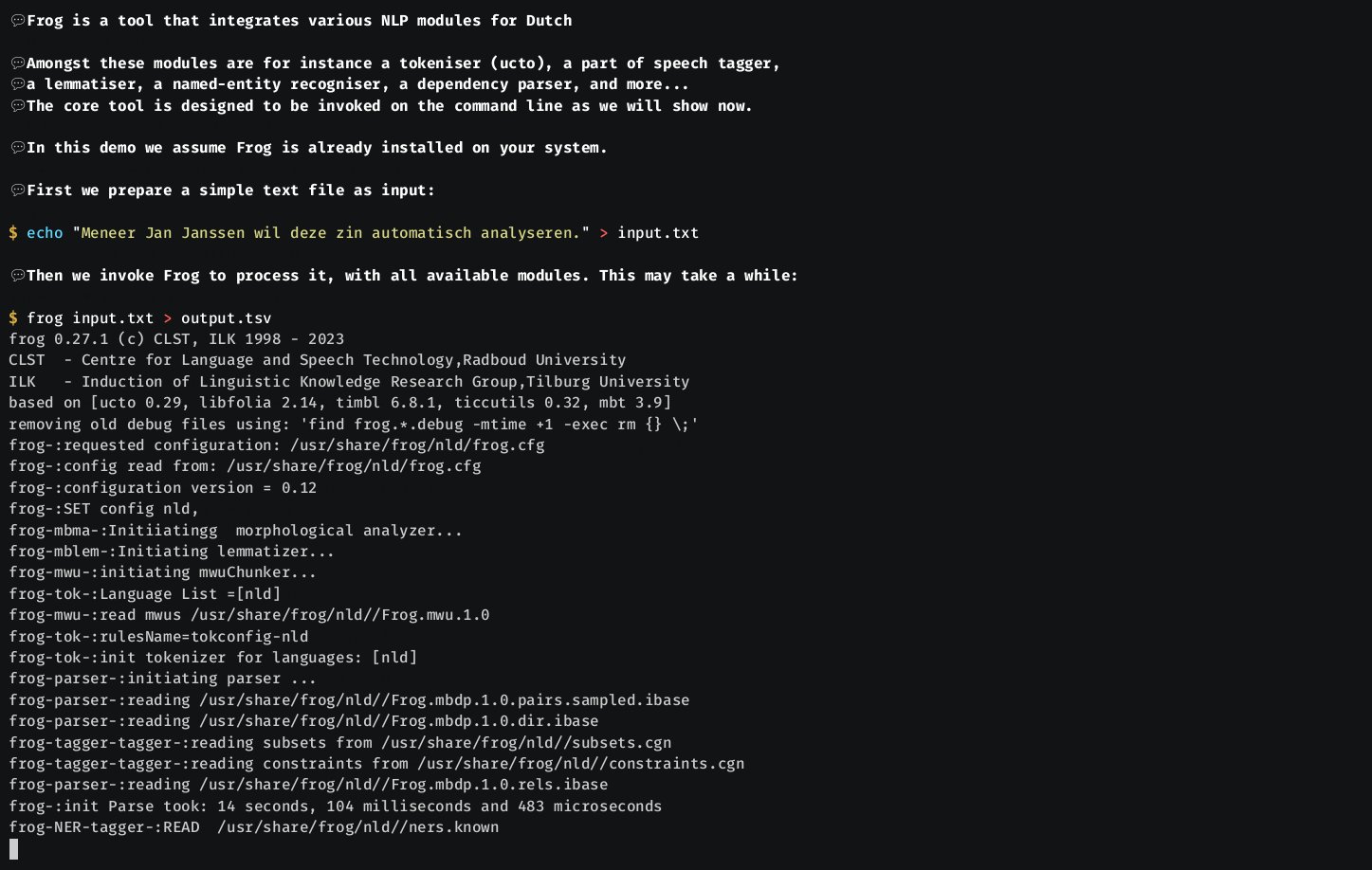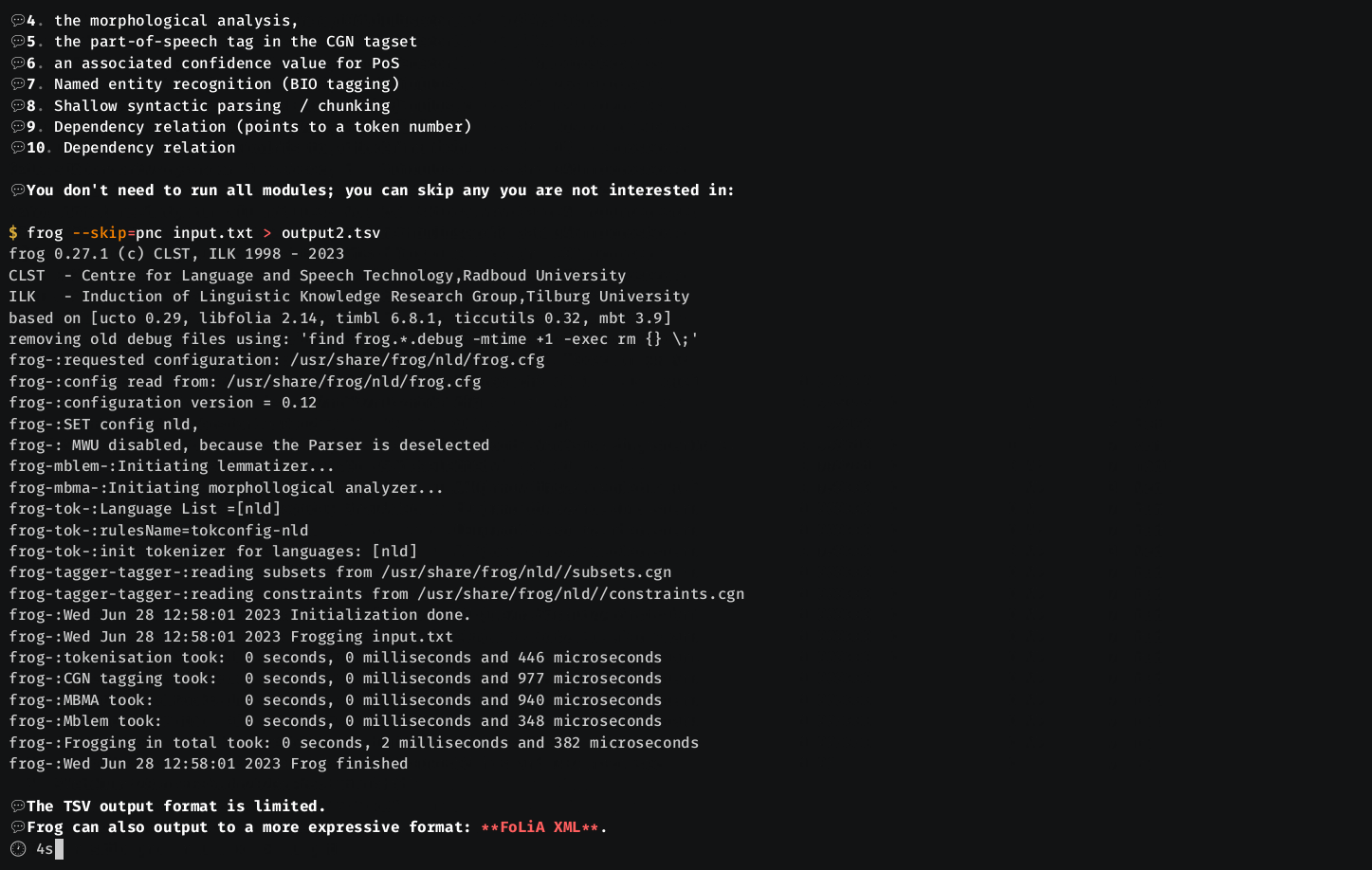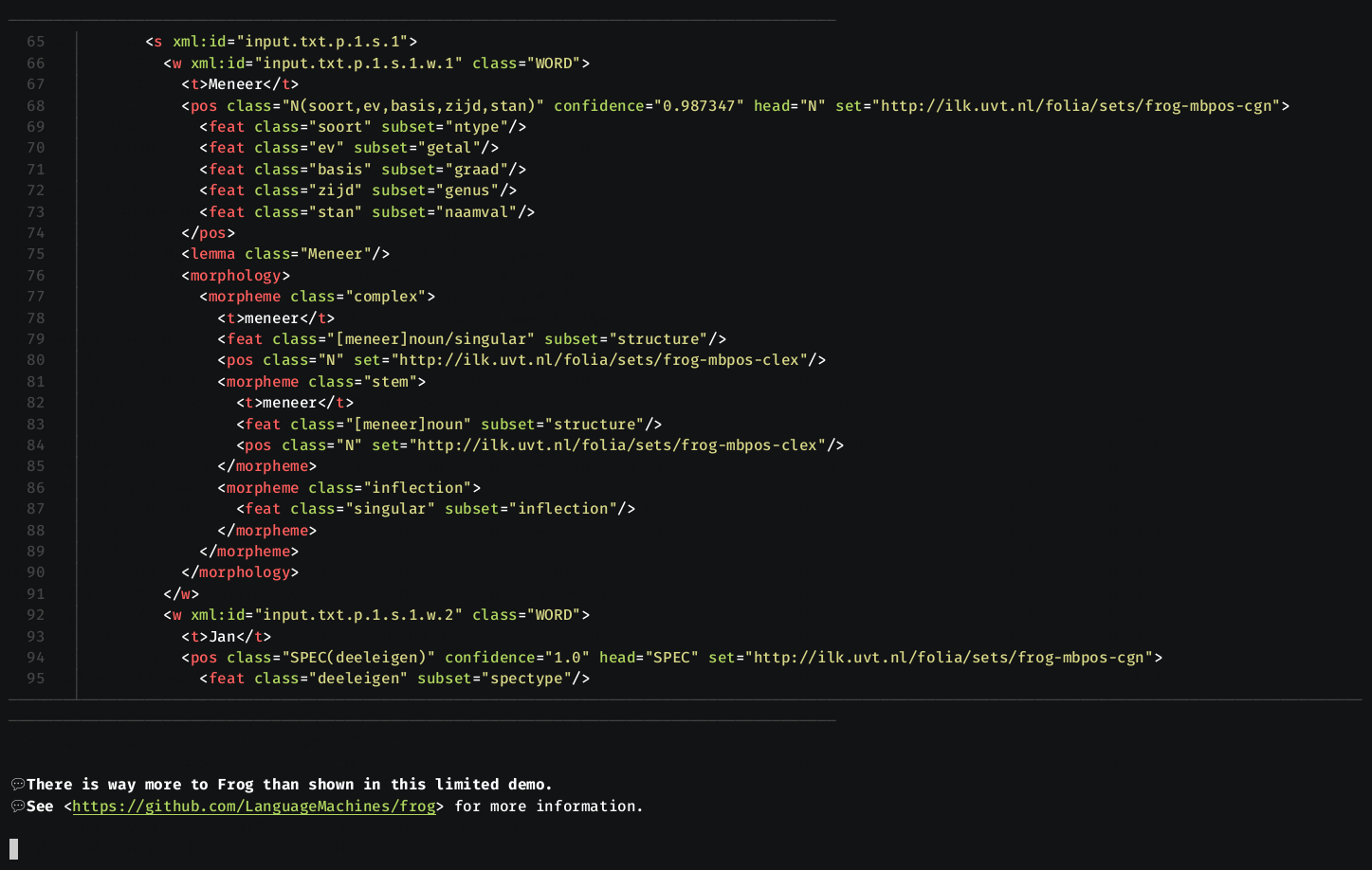
## License
Frog is free software; you can redistribute it and/or modify it under the terms
of the GNU General Public License as published by the Free Software Foundation;
either version 3 of the License, or (at your option) any later version (see the file COPYING)
frog is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
Comments and bug-reports are welcome at our [issue tracker](https://github.com/LanguageMachines/frog/issues) or by mailing
lamasoftware (at) science.ru.nl.
Updates and more info may be found on https://languagemachines.github.io/frog .
## Installation
To install Frog, first consult whether your distribution's package manager has
an up-to-date package:
* Alpine Linux users can do `apk install frog`.
* Debian/Ubuntu users can do `apt install frog` but this version will likely be significantly out of date!
* Arch Linux users can install Frog via the [AUR](https://aur.archlinux.org/packages/frog).
* macOS users with [homebrew](https://brew.sh/) can do: `brew tap fbkarsdorp/homebrew-lamachine && brew install frog`
* An OCI container image is also available and can be used with Docker: `docker pull proycon/frog`. Alternatively, you can build an OCI container image yourself using the provided `Dockerfile` in this repository.
To compile and install manually from source instead, do the following:
$ bash bootstrap.sh
$ ./configure
$ make
$ make install
and optionally:
$ make check
If you want to automatically download and install the latest stable versions of
the required dependencies, then run `./build-deps.sh` prior to the above. You
can pass a target directory prefix as first argument and you may need to
prepend `sudo` to ensure you can install there. The dependencies are:
* [ticcutils](https://github.com/LanguageMachines/ticcutils)
* [libfolia](https://github.com/LanguageMachines/libfolia)
* [uctodata](https://github.com/LanguageMachines/uctodata)
* [ucto](https://github.com/LanguageMachines/ucto)
* [timbl](https://github.com/LanguageMachines/timbl)
* [mbt](https://github.com/LanguageMachines/mbt)
* [frogdata](https://github.com/LanguageMachines/frogdata)
You will still need to take care to install the following 3rd party
dependencies through your distribution's package manager, as they are not
provided by our script:
* ``icu`` - A C++ library for Unicode and Globalization support. On Debian/Ubuntu systems, install the package libicu-dev.
* ``libxml2`` - An XML library. On Debian/Ubuntu systems install the package libxml2-dev.
* ``libexttextcat`` - A language detection package.
* A sane build environment with a C++ compiler (e.g. gcc 4.9 or above or clang), make, autotools, libtool, pkg-config
This software has been tested on:
* Intel platforms running several versions of Linux, including Ubuntu, Debian, Arch Linux, Fedora (both 32 and 64 bits)
* Apple platform running macOS
Contents of this distribution:
* Sources
* Licensing information ( COPYING )
* Installation instructions ( INSTALL )
* Build system based on GNU Autotools
* Container build file ( Dockerfile )
* Example data files ( in the demos directory )
* Documentation ( in the docs directory and on https://frognlp.readthedocs.io )
## Usage
Run ``frog --help`` for basic usage instructions.
## Documentation
The Frog documentation can be found on
## Container Usage
A pre-made container image can be obtained from Docker Hub as follows:
``docker pull proycon/frog``
You can also build a container image yourself as follows, make sure you are in the root of this repository:
``docker build -t proycon/frog .``
This builds the latest stable release, if you want to use the latest development version
from the git repository instead, do:
``docker build -t proycon/frog --build-arg VERSION=development .``
Run the frog container interactively as follows, you can pass any additional arguments that ``frog`` takes.
``docker run -t -i proycon/frog``
Add the ``-v /path/to/your/data:/data`` parameter if you want to mount your data volume into the container at `/data`.
## Python Binding
If you are looking to use Frog from Python, please see instead for the python binding. It is not included in this repository.
## Webservice
If you are looking to run Frog as a webservice yourself, please see . It is not included in this repository.
## Credits
Many thanks go out to the people who made the developments of the Frog
components possible: Walter Daelemans, Jakub Zavrel, Ko van der Sloot, Sabine
Buchholz, Sander Canisius, Gert Durieux, Peter Berck and Maarten van Gompel.
Thanks to Erik Tjong Kim Sang and Lieve Macken for stress-testing the first
versions of Tadpole, the predecessor of Frog
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/TODO������������������������������������������������������������������0000664�0000000�0000000�00000000631�14730024002�0016647�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������* discard -t and --testdir- options.
use Frog file/port/dir instead
file: Frog this file (wildcards too?)
dir: Frog all files in dir
port: run as a server
* rethink/arrange common datastructures
* Make server also support daemonizing stuff and --pid and --log
(server now logs to terminal)
* Server logs incorrect timing (seems to count from the moment the client is accepted)
�������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/bootstrap.sh����������������������������������������������������������0000775�0000000�0000000�00000004215�14730024002�0020535�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# bootstrap - script to bootstrap the distribution rolling engine
# usage:
# $ sh ./bootstrap && ./configure && make dist[check]
#
# this yields a tarball which one can install doing
#
# $ tar zxf PACKAGENAME-*.tar.gz
# $ cd PACKAGENAME-*
# $ ./configure
# $ make
# # make install
# requirements:
# GNU autoconf, from e.g. ftp.gnu.org:/pub/gnu/autoconf/
# GNU automake, from e.g. http://ftp.gnu.org/gnu/automake/
automake=automake
aclocal=aclocal
# inspired by hack as used in mcl (from http://micans.org/)
# autoconf-archive Debian package, aclocal-archive RPM, obsolete/badly supported OS, installed in home dir
acdirs="/usr/share/autoconf-archive/ /usr/share/aclocal/ /usr/local/share/aclocal/ $HOME/local/share/autoconf-archive/ /opt/homebrew/share/aclocal/"
found=false
for d in $acdirs
do
if test -f ${d}pkg.m4
then
found=true
break
fi
done
if ! $found
then
cat <&2
echo " Building latest stable release of main dependencies from source.">&2
echo "------------------------------------------------------------------------">&2
else
echo "------------------------------------------------------------------------">&2
echo " Building development versions of main dependencie from source.">&2
echo " (This is experimental and may contain bugs! DO NOT PUBLISH!)">&2
echo "-----------------------------------------------------------------------">&2
fi
PWD="$(pwd)"
BUILDDIR="$(mktemp -dt "build-deps.XXXXXX")"
cd "$BUILDDIR"
BUILD_SOURCES="LanguageMachines/ticcutils LanguageMachines/libfolia LanguageMachines/uctodata LanguageMachines/ucto LanguageMachines/timbl LanguageMachines/mbt LanguageMachines/timblserver LanguageMachines/mbtserver LanguageMachines/frogdata"
for SUFFIX in $BUILD_SOURCES; do \
NAME="$(basename "$SUFFIX")"
git clone "https://github.com/$SUFFIX"
cd "$NAME"
REF=$(git tag -l | grep -E "^v?[0-9]+(\.[0-9])*" | sort -t. -k 1.2,1n -k 2,2n -k 3,3n -k 4,4n | tail -n 1)
if [ "$VERSION" = "stable" ] && [ -n "$REF" ]; then
git -c advice.detachedHead=false checkout "$REF"
fi
sh ./bootstrap.sh && ./configure --prefix "$PREFIX" && make && make install
cd ..
done
cd "$PWD"
[ -n "$BUILDDIR" ] && rm -Rf "$BUILDDIR"
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/codemeta.json���������������������������������������������������������0000664�0000000�0000000�00000027041�14730024002�0020637�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������{
"@context": [
"https://doi.org/10.5063/schema/codemeta-2.0",
"http://schema.org",
"https://w3id.org/software-types",
"https://w3id.org/software-iodata"
],
"@type": "SoftwareSourceCode",
"identifier": "frog",
"name": "Frog",
"version": "0.34",
"description": "Frog is an integration of memory-based natural language processing (NLP) modules developed for Dutch. It performs automatic linguistic enrichment such as part of speech tagging, lemmatisation, named entity recognition, shallow parsing, dependency parsing and morphological analysis. All NLP modules are based on TiMBL.",
"license": "https://spdx.org/licenses/GPL-3.0-only",
"url": "https://languagemachines.github.io/frog",
"thumbnailUrl": "https://raw.githubusercontent.com/LanguageMachines/frog/master/logo.svg",
"producer": {
"@id": "https://huc.knaw.nl",
"@type": "Organization",
"name": "KNAW Humanities Cluster",
"url": "https://huc.knaw.nl",
"parentOrganization": {
"@id": "https://knaw.nl",
"@type": "Organization",
"name": "KNAW",
"url": "https://knaw.nl",
"location": {
"@type": "Place",
"name": "Amsterdam"
}
}
},
"author": [
{
"@type": "Person",
"givenName": "Ko",
"familyName": "van der Sloot",
"email": "ko.vandersloot@let.ru.nl",
"affiliation": {
"@id": "https://www.ru.nl/clst",
"@type": "Organization",
"name": "Centre for Language and Speech Technology",
"url": "https://www.ru.nl/clst",
"parentOrganization": {
"@id": "https://www.ru.nl/cls",
"@type": "Organization",
"name": "Centre for Language Studies",
"url": "https://www.ru.nl/cls",
"parentOrganization": {
"@id": "https://www.ru.nl",
"name": "Radboud University",
"@type": "Organization",
"url": "https://www.ru.nl",
"location": {
"@type": "Place",
"name": "Nijmegen"
}
}
}
}
},
{
"@id": "https://orcid.org/0000-0003-2493-656X",
"@type": "Person",
"givenName": "Antal",
"familyName": "van den Bosch",
"email": "antal.vandenbosch@let.ru.nl"
},
{
"@id": "https://orcid.org/0000-0002-1046-0006",
"@type": "Person",
"givenName": "Maarten",
"familyName": "van Gompel",
"email": "proycon@anaproy.nl",
"affiliation": [
{ "@id": "https://huc.knaw.nl" },
{ "@id": "https://www.ru.nl/clst" }
]
}
],
"sourceOrganization": { "@id": "https://www.ru.nl/clst" },
"programmingLanguage": {
"@type": "ComputerLanguage",
"identifier": "c++",
"name": "C++"
},
"operatingSystem": [ "Linux", "BSD", "macOS" ],
"codeRepository": "https://github.com/LanguageMachines/frog",
"softwareRequirements": [
{
"@type": "SoftwareApplication",
"identifier": "icu",
"name": "icu"
},
{
"@type": "SoftwareApplication",
"identifier": "libxml2",
"name": "libxml2"
},
{
"@type": "SoftwareApplication",
"identifier": "ticcutils",
"name": "ticcutils"
},
{
"@type": "SoftwareApplication",
"identifier": "timbl",
"name": "timbl"
},
{
"@type": "SoftwareApplication",
"identifier": "libfolia",
"name": "libfolia"
},
{
"@type": "SoftwareApplication",
"identifier": "mbt",
"name": "mbt"
},
{
"@type": "SoftwareApplication",
"identifier": "ucto",
"name": "ucto"
}
],
"funding": [
{
"@type": "Grant",
"name": "CLARIN-NL (NWO grant 184.021.003)",
"url": "https://www.clariah.nl",
"funder": {
"@type": "Organization",
"name": "NWO",
"url": "https://www.nwo.nl"
}
},
{
"@type": "Grant",
"name": "CLARIAH-CORE (NWO grant 184.033.101)",
"url": "https://www.clariah.nl",
"funder": {
"@type": "Organization",
"name": "NWO",
"url": "https://www.nwo.nl"
}
},
{
"@type": "Grant",
"name": "CLARIAH-PLUS (NWO grant 184.034.023)",
"funder": {
"@type": "Organization",
"name": "NWO",
"url": "https://www.nwo.nl"
}
}
],
"readme": "https://github.com/LanguageMachines/frog/blob/master/README.md",
"softwareHelp": [
{
"@id": "https://frognlp.readthedocs.io",
"@type": "WebSite",
"name": "Introduction â frog documentation",
"url": "https://frognlp.readthedocs.io"
}
],
"issueTracker": "https://github.com/LanguageMachines/frog/issues",
"contIntegration": "https://github.com/LanguageMachines/frog/actions/workflows/frog.yml",
"releaseNotes": "https://github.com/LanguageMachines/frog/releases",
"developmentStatus": [ "https://www.repostatus.org/#active", "https://w3id.org/research-technology-readiness-levels#Level9Proven" ],
"keywords": [ "nlp", "natural language processing", "pos", "lemma", "ner", "parser", "tagger", "part-of-speech tagging", "lemmatisation", "dependency parsing", "shallow parsing", "dutch" ],
"applicationCategory": [ "https://vocabs.dariah.eu/tadirah/annotating", "https://vocabs.dariah.eu/tadirah/tagging", "https://vocabs.dariah.eu/tadirah/namedEntityRecognition", "https://vocabs.dariah.eu/tadirah/posTagging", "https://vocabs.dariah.eu/tadirah/segmenting", "https://vocabs.dariah.eu/tadirah/treeTagging", "https://vocabs.dariah.eu/tadirah/contextualizing" , "https://w3id.org/nwo-research-fields#Linguistics", "https://w3id.org/nwo-research-fields#TextualAndContentAnalysis" ],
"referencePublication": [
{
"@type": "TechArticle",
"name": "Frog: A Natural Language Processing Suite for Dutch",
"author": [ "Iris Hendrickx", "Antal van den Bosch", "Maarten van Gompel", "Ko van der Sloot", "Walter Daelemans" ],
"pageStart": "99",
"pageEnd": 114,
"isPartOf": {
"@type": "PublicationIssue",
"datePublished": "2016",
"name": "CLST Technical Report",
"issue": "16-02",
"location": "Nijmegen, the Netherlands"
},
"url": "https://github.com/LanguageMachines/frog/raw/master/docs/frogmanual.pdf"
},
{
"@type": "ScholarlyArticle",
"name": "An efficient memory-based morphosyntactic tagger and parser for Dutch",
"author": [ "Antal van den Bosch", "Bertjan Busser", "Sander Canisius", "Walter Daelemans" ],
"pageStart": "99",
"pageEnd": 114,
"isPartOf": {
"@type": "PublicationIssue",
"datePublished": "2007",
"name": "Selected Papers of the 17th Computational Linguistics in the Netherlands Meeting",
"location": "Leuven, Belgium"
},
"url": "https://www.clinjournal.org/CLIN_proceedings/XVII/vandenbosch.pdf"
}
],
"dateCreated": "2011-03-31T12:35:01Z+0000",
"dateModified": "2023-12-05T15:43:06Z+0100",
"targetProduct": [
{
"@type": "SoftwareLibrary",
"executableName": "libfrog",
"name": "libfrog",
"runtimePlatform": [ "Linux", "BSD", "macOS" ],
"description": "Frog Library with API for C++"
},
{
"@type": "CommandLineApplication",
"executableName": "frog",
"name": "frog",
"runtimePlatform": [ "Linux", "BSD", "macOS" ],
"description": "Command-line interface to the full NLP suite",
"consumesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": {
"@id": "https://iso639-3.sil.org/code/nld",
"@type": "Language",
"name": "Dutch",
"identifier": "nld"
}
},
{
"@type": "TextDigitalDocument",
"encodingFormat": "application/folia+xml",
"inLanguage": {
"@id": "https://iso639-3.sil.org/code/nld",
"@type": "Language",
"name": "Dutch",
"identifier": "nld"
}
}
],
"producesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": {
"@id": "https://iso639-3.sil.org/code/nld",
"@type": "Language",
"name": "Dutch",
"identifier": "nld"
}
},
{
"@type": "TextDigitalDocument",
"encodingFormat": "application/folia+xml",
"inLanguage": {
"@id": "https://iso639-3.sil.org/code/nld",
"@type": "Language",
"name": "Dutch",
"identifier": "nld"
}
}
]
},
{
"@type": "CommandLineApplication",
"executableName": "mbma",
"runtimePlatform": [ "Linux", "BSD", "macOS" ],
"name": "mbma",
"description": "Memory-based Morphological Analysis (standalone)",
"consumesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
],
"producesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
]
},
{
"@type": "CommandLineApplication",
"executableName": "mblem",
"name": "mblem",
"description": "Memory-based Lemmatiser (standalone)",
"consumesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
],
"producesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
]
},
{
"@type": "CommandLineApplication",
"executableName": "ner",
"name": "ner",
"description": "Named Entity Recogniser (standalone)",
"consumesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
],
"producesData": [
{
"@type": "TextDigitalDocument",
"encodingFormat": "text/plain",
"inLanguage": { "@id": "https://iso639-3.sil.org/code/nld" }
}
]
}
]
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/configure.ac����������������������������������������������������������0000664�0000000�0000000�00000007616�14730024002�0020457�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- Autoconf -*-
# Process this file with autoconf to produce a configure script.
AC_PREREQ([2.69])
#also adapt version number in codemeta.json
AC_INIT([frog],[0.34],[lamasoftware@science.ru.nl]) #adapt version number in codemeta.json as well
AM_INIT_AUTOMAKE
AC_CONFIG_SRCDIR([configure.ac])
AC_CONFIG_MACRO_DIR([m4])
AC_CONFIG_HEADERS([config.h])
AX_REQUIRE_DEFINED([AX_CXX_COMPILE_STDCXX_17])
# Checks for programs.
AC_PROG_CXX( [g++ c++] )
AX_CXX_COMPILE_STDCXX_17
# use libtool
LT_INIT
# when running tests, use CXX
AC_LANG([C++])
# Checks for libraries.
# Checks for typedefs, structures, and compiler characteristics.
# check OpenMP support
AC_OPENMP
if test "x$ac_cv_prog_cxx_openmp" != "x"; then
if test "x$ac_cv_prog_cxx_openmp" != "xunsupported"; then
CXXFLAGS="$CXXFLAGS $OPENMP_CXXFLAGS"
AC_DEFINE([HAVE_OPENMP], [1] , [Define to 1 if you have OpenMP] )
else
AC_MSG_NOTICE([We don't have OpenMP. Multithreaded operation is disabled])
fi
fi
AC_HEADER_STDBOOL
AC_C_INLINE
AC_TYPE_SIZE_T
AC_CHECK_HEADERS([unistd.h])
# Checks for library functions.
AC_FUNC_FORK
AC_CHECK_FUNCS([strerror])
AX_PTHREAD([],[AC_MSG_ERROR([We need pthread support!])])
if test x"$acx_pthread_ok" = xyes; then
LIBS="$PTHREAD_LIBS $LIBS" \
CXXFLAGS="$CXXFLAGS $PTHREAD_CFLAGS"
fi
if test $prefix = "NONE"; then
prefix="$ac_default_prefix"
fi
PKG_PROG_PKG_CONFIG
if test "x$PKG_CONFIG_PATH" = x; then
export PKG_CONFIG_PATH="$prefix/lib/pkgconfig"
else
export PKG_CONFIG_PATH="$prefix/lib/pkgconfig:$PKG_CONFIG_PATH"
fi
AC_OSX_PKG( [icu4c libtextcat] )
PKG_CHECK_MODULES( [TEXTCAT],
[libexttextcat],
[TEXTCAT_FOUND=1
CXXFLAGS="$CXXFLAGS $TEXTCAT_CFLAGS"
LIBS="$TEXTCAT_LIBS $LIBS"],
[PKG_CHECK_MODULES( [TEXTCAT],
[libtextcat],
[TEXTCAT_FOUND=1
CXXFLAGS="$CXXFLAGS $TEXTCAT_CFLAGS"
LIBS="$TEXTCAT_LIBS $LIBS"],
[TEXTCAT_FOUND=0]
)]
)
if test $TEXTCAT_FOUND = 0; then
# So, no pkg-config for textcat found.
# Hopefully an old style version can be found???
AC_CHECK_OLD_TEXTCAT
if test $TEXTCAT_FOUND = 1; then
AC_DEFINE([HAVE_OLD_TEXTCAT], [1], [textcat needs C linkage])
fi
fi
if test $TEXTCAT_FOUND = 1; then
AC_SEARCH_LM
fi
if test $TEXTCAT_FOUND = 0; then
AC_MSG_ERROR( [no working libtextcat or libexttextcat found!] )
else
AC_DEFINE([HAVE_TEXTCAT], [1], [textcat])
fi
PKG_CHECK_MODULES([XML2], [libxml-2.0 >= 2.6.16] )
CXXFLAGS="$CXXFLAGS $XML2_CFLAGS"
LIBS="$XML2_LIBS $LIBS"
PKG_CHECK_MODULES([ICU], [icu-uc >= 50 icu-io] )
CXXFLAGS="$CXXFLAGS $ICU_CFLAGS"
LIBS="$ICU_LIBS $LIBS"
AX_LIB_READLINE
PKG_CHECK_MODULES([ticcutils], [ticcutils >= 0.36] )
CXXFLAGS="$CXXFLAGS $ticcutils_CFLAGS"
LIBS="$ticcutils_LIBS $LIBS"
PKG_CHECK_MODULES([timbl], [timbl >= 6.8] )
CXXFLAGS="$CXXFLAGS $timbl_CFLAGS"
LIBS="$timbl_LIBS $LIBS"
PKG_CHECK_MODULES([mbt], [mbt >= 3.7] )
CXXFLAGS="$CXXFLAGS $mbt_CFLAGS"
LIBS="$mbt_LIBS $LIBS"
PKG_CHECK_MODULES([folia],[folia >= 2.17])
CXXFLAGS="$CXXFLAGS $folia_CFLAGS"
LIBS="$folia_LIBS $LIBS"
PKG_CHECK_MODULES([ucto], [ucto >= 0.30] )
CXXFLAGS="$CXXFLAGS $ucto_CFLAGS"
LIBS="$ucto_LIBS $LIBS"
UCTO_VERSION=`$PKG_CONFIG --modversion ucto`
UCTO_INT="${UCTO_VERSION//.}" # no dots
UCTO_INT=$((10#$UCTO_INT)) # no leading 0 (that's octal)
AC_DEFINE_UNQUOTED( [UCTO_INT_VERSION],
[${UCTO_INT}],
[The integer representation of the ucto version])
PKG_CHECK_MODULES([frogdata], [frogdata >= 0.21] )
AC_CHECK_PROGS([DOXYGEN], [doxygen])
if test -z "$DOXYGEN"; then
AC_MSG_WARN([Doxygen not found - continue without Doxygen support])
else
AC_CHECK_PROGS([DOT], [dot])
if test -z "$DOT"; then
AC_MSG_ERROR([Doxygen needs dot, please install dot first])
fi
fi
AM_CONDITIONAL([HAVE_DOXYGEN], [test -n "$DOXYGEN"])
AC_CONFIG_FILES([
Makefile
frog.pc
m4/Makefile
docs/Makefile
tests/Makefile
src/Makefile
include/Makefile
include/frog/Makefile
])
AC_OUTPUT
������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/docs/�����������������������������������������������������������������0000775�0000000�0000000�00000000000�14730024002�0017107�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������LanguageMachines-frog-a80d261/docs/Doxygen.cfg������������������������������������������������������0000664�0000000�0000000�00000372217�14730024002�0021221�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Doxyfile 1.9.8
# This file describes the settings to be used by the documentation system
# doxygen (www.doxygen.org) for a project.
#
# All text after a double hash (##) is considered a comment and is placed in
# front of the TAG it is preceding.
#
# All text after a single hash (#) is considered a comment and will be ignored.
# The format is:
# TAG = value [value, ...]
# For lists, items can also be appended using:
# TAG += value [value, ...]
# Values that contain spaces should be placed between quotes (\" \").
#
# Note:
#
# Use doxygen to compare the used configuration file with the template
# configuration file:
# doxygen -x [configFile]
# Use doxygen to compare the used configuration file with the template
# configuration file without replacing the environment variables or CMake type
# replacement variables:
# doxygen -x_noenv [configFile]
#---------------------------------------------------------------------------
# Project related configuration options
#---------------------------------------------------------------------------
# This tag specifies the encoding used for all characters in the configuration
# file that follow. The default is UTF-8 which is also the encoding used for all
# text before the first occurrence of this tag. Doxygen uses libiconv (or the
# iconv built into libc) for the transcoding. See
# https://www.gnu.org/software/libiconv/ for the list of possible encodings.
# The default value is: UTF-8.
DOXYFILE_ENCODING = UTF-8
# The PROJECT_NAME tag is a single word (or a sequence of words surrounded by
# double-quotes, unless you are using Doxywizard) that should identify the
# project for which the documentation is generated. This name is used in the
# title of most generated pages and in a few other places.
# The default value is: My Project.
PROJECT_NAME = Frog
# The PROJECT_NUMBER tag can be used to enter a project or revision number. This
# could be handy for archiving the generated documentation or if some version
# control system is used.
PROJECT_NUMBER =
# Using the PROJECT_BRIEF tag one can provide an optional one line description
# for a project that appears at the top of each page and should give viewer a
# quick idea about the purpose of the project. Keep the description short.
PROJECT_BRIEF =
# With the PROJECT_LOGO tag one can specify a logo or an icon that is included
# in the documentation. The maximum height of the logo should not exceed 55
# pixels and the maximum width should not exceed 200 pixels. Doxygen will copy
# the logo to the output directory.
PROJECT_LOGO =
# The OUTPUT_DIRECTORY tag is used to specify the (relative or absolute) path
# into which the generated documentation will be written. If a relative path is
# entered, it will be relative to the location where doxygen was started. If
# left blank the current directory will be used.
OUTPUT_DIRECTORY =
# If the CREATE_SUBDIRS tag is set to YES then doxygen will create up to 4096
# sub-directories (in 2 levels) under the output directory of each output format
# and will distribute the generated files over these directories. Enabling this
# option can be useful when feeding doxygen a huge amount of source files, where
# putting all generated files in the same directory would otherwise causes
# performance problems for the file system. Adapt CREATE_SUBDIRS_LEVEL to
# control the number of sub-directories.
# The default value is: NO.
CREATE_SUBDIRS = NO
# Controls the number of sub-directories that will be created when
# CREATE_SUBDIRS tag is set to YES. Level 0 represents 16 directories, and every
# level increment doubles the number of directories, resulting in 4096
# directories at level 8 which is the default and also the maximum value. The
# sub-directories are organized in 2 levels, the first level always has a fixed
# number of 16 directories.
# Minimum value: 0, maximum value: 8, default value: 8.
# This tag requires that the tag CREATE_SUBDIRS is set to YES.
CREATE_SUBDIRS_LEVEL = 8
# If the ALLOW_UNICODE_NAMES tag is set to YES, doxygen will allow non-ASCII
# characters to appear in the names of generated files. If set to NO, non-ASCII
# characters will be escaped, for example _xE3_x81_x84 will be used for Unicode
# U+3044.
# The default value is: NO.
ALLOW_UNICODE_NAMES = NO
# The OUTPUT_LANGUAGE tag is used to specify the language in which all
# documentation generated by doxygen is written. Doxygen will use this
# information to generate all constant output in the proper language.
# Possible values are: Afrikaans, Arabic, Armenian, Brazilian, Bulgarian,
# Catalan, Chinese, Chinese-Traditional, Croatian, Czech, Danish, Dutch, English
# (United States), Esperanto, Farsi (Persian), Finnish, French, German, Greek,
# Hindi, Hungarian, Indonesian, Italian, Japanese, Japanese-en (Japanese with
# English messages), Korean, Korean-en (Korean with English messages), Latvian,
# Lithuanian, Macedonian, Norwegian, Persian (Farsi), Polish, Portuguese,
# Romanian, Russian, Serbian, Serbian-Cyrillic, Slovak, Slovene, Spanish,
# Swedish, Turkish, Ukrainian and Vietnamese.
# The default value is: English.
OUTPUT_LANGUAGE = English
# If the BRIEF_MEMBER_DESC tag is set to YES, doxygen will include brief member
# descriptions after the members that are listed in the file and class
# documentation (similar to Javadoc). Set to NO to disable this.
# The default value is: YES.
BRIEF_MEMBER_DESC = YES
# If the REPEAT_BRIEF tag is set to YES, doxygen will prepend the brief
# description of a member or function before the detailed description
#
# Note: If both HIDE_UNDOC_MEMBERS and BRIEF_MEMBER_DESC are set to NO, the
# brief descriptions will be completely suppressed.
# The default value is: YES.
REPEAT_BRIEF = YES
# This tag implements a quasi-intelligent brief description abbreviator that is
# used to form the text in various listings. Each string in this list, if found
# as the leading text of the brief description, will be stripped from the text
# and the result, after processing the whole list, is used as the annotated
# text. Otherwise, the brief description is used as-is. If left blank, the
# following values are used ($name is automatically replaced with the name of
# the entity):The $name class, The $name widget, The $name file, is, provides,
# specifies, contains, represents, a, an and the.
ABBREVIATE_BRIEF = "The $name class" \
"The $name widget" \
"The $name file" \
is \
provides \
specifies \
contains \
represents \
a \
an \
the
# If the ALWAYS_DETAILED_SEC and REPEAT_BRIEF tags are both set to YES then
# doxygen will generate a detailed section even if there is only a brief
# description.
# The default value is: NO.
ALWAYS_DETAILED_SEC = NO
# If the INLINE_INHERITED_MEMB tag is set to YES, doxygen will show all
# inherited members of a class in the documentation of that class as if those
# members were ordinary class members. Constructors, destructors and assignment
# operators of the base classes will not be shown.
# The default value is: NO.
INLINE_INHERITED_MEMB = NO
# If the FULL_PATH_NAMES tag is set to YES, doxygen will prepend the full path
# before files name in the file list and in the header files. If set to NO the
# shortest path that makes the file name unique will be used
# The default value is: YES.
FULL_PATH_NAMES = YES
# The STRIP_FROM_PATH tag can be used to strip a user-defined part of the path.
# Stripping is only done if one of the specified strings matches the left-hand
# part of the path. The tag can be used to show relative paths in the file list.
# If left blank the directory from which doxygen is run is used as the path to
# strip.
#
# Note that you can specify absolute paths here, but also relative paths, which
# will be relative from the directory where doxygen is started.
# This tag requires that the tag FULL_PATH_NAMES is set to YES.
STRIP_FROM_PATH =
# The STRIP_FROM_INC_PATH tag can be used to strip a user-defined part of the
# path mentioned in the documentation of a class, which tells the reader which
# header file to include in order to use a class. If left blank only the name of
# the header file containing the class definition is used. Otherwise one should
# specify the list of include paths that are normally passed to the compiler
# using the -I flag.
STRIP_FROM_INC_PATH =
# If the SHORT_NAMES tag is set to YES, doxygen will generate much shorter (but
# less readable) file names. This can be useful is your file systems doesn't
# support long names like on DOS, Mac, or CD-ROM.
# The default value is: NO.
SHORT_NAMES = NO
# If the JAVADOC_AUTOBRIEF tag is set to YES then doxygen will interpret the
# first line (until the first dot) of a Javadoc-style comment as the brief
# description. If set to NO, the Javadoc-style will behave just like regular Qt-
# style comments (thus requiring an explicit @brief command for a brief
# description.)
# The default value is: NO.
JAVADOC_AUTOBRIEF = NO
# If the JAVADOC_BANNER tag is set to YES then doxygen will interpret a line
# such as
# /***************
# as being the beginning of a Javadoc-style comment "banner". If set to NO, the
# Javadoc-style will behave just like regular comments and it will not be
# interpreted by doxygen.
# The default value is: NO.
JAVADOC_BANNER = NO
# If the QT_AUTOBRIEF tag is set to YES then doxygen will interpret the first
# line (until the first dot) of a Qt-style comment as the brief description. If
# set to NO, the Qt-style will behave just like regular Qt-style comments (thus
# requiring an explicit \brief command for a brief description.)
# The default value is: NO.
QT_AUTOBRIEF = NO
# The MULTILINE_CPP_IS_BRIEF tag can be set to YES to make doxygen treat a
# multi-line C++ special comment block (i.e. a block of //! or /// comments) as
# a brief description. This used to be the default behavior. The new default is
# to treat a multi-line C++ comment block as a detailed description. Set this
# tag to YES if you prefer the old behavior instead.
#
# Note that setting this tag to YES also means that rational rose comments are
# not recognized any more.
# The default value is: NO.
MULTILINE_CPP_IS_BRIEF = NO
# By default Python docstrings are displayed as preformatted text and doxygen's
# special commands cannot be used. By setting PYTHON_DOCSTRING to NO the
# doxygen's special commands can be used and the contents of the docstring
# documentation blocks is shown as doxygen documentation.
# The default value is: YES.
PYTHON_DOCSTRING = YES
# If the INHERIT_DOCS tag is set to YES then an undocumented member inherits the
# documentation from any documented member that it re-implements.
# The default value is: YES.
INHERIT_DOCS = YES
# If the SEPARATE_MEMBER_PAGES tag is set to YES then doxygen will produce a new
# page for each member. If set to NO, the documentation of a member will be part
# of the file/class/namespace that contains it.
# The default value is: NO.
SEPARATE_MEMBER_PAGES = NO
# The TAB_SIZE tag can be used to set the number of spaces in a tab. Doxygen
# uses this value to replace tabs by spaces in code fragments.
# Minimum value: 1, maximum value: 16, default value: 4.
TAB_SIZE = 4
# This tag can be used to specify a number of aliases that act as commands in
# the documentation. An alias has the form:
# name=value
# For example adding
# "sideeffect=@par Side Effects:^^"
# will allow you to put the command \sideeffect (or @sideeffect) in the
# documentation, which will result in a user-defined paragraph with heading
# "Side Effects:". Note that you cannot put \n's in the value part of an alias
# to insert newlines (in the resulting output). You can put ^^ in the value part
# of an alias to insert a newline as if a physical newline was in the original
# file. When you need a literal { or } or , in the value part of an alias you
# have to escape them by means of a backslash (\), this can lead to conflicts
# with the commands \{ and \} for these it is advised to use the version @{ and
# @} or use a double escape (\\{ and \\})
ALIASES =
# Set the OPTIMIZE_OUTPUT_FOR_C tag to YES if your project consists of C sources
# only. Doxygen will then generate output that is more tailored for C. For
# instance, some of the names that are used will be different. The list of all
# members will be omitted, etc.
# The default value is: NO.
OPTIMIZE_OUTPUT_FOR_C = NO
# Set the OPTIMIZE_OUTPUT_JAVA tag to YES if your project consists of Java or
# Python sources only. Doxygen will then generate output that is more tailored
# for that language. For instance, namespaces will be presented as packages,
# qualified scopes will look different, etc.
# The default value is: NO.
OPTIMIZE_OUTPUT_JAVA = NO
# Set the OPTIMIZE_FOR_FORTRAN tag to YES if your project consists of Fortran
# sources. Doxygen will then generate output that is tailored for Fortran.
# The default value is: NO.
OPTIMIZE_FOR_FORTRAN = NO
# Set the OPTIMIZE_OUTPUT_VHDL tag to YES if your project consists of VHDL
# sources. Doxygen will then generate output that is tailored for VHDL.
# The default value is: NO.
OPTIMIZE_OUTPUT_VHDL = NO
# Set the OPTIMIZE_OUTPUT_SLICE tag to YES if your project consists of Slice
# sources only. Doxygen will then generate output that is more tailored for that
# language. For instance, namespaces will be presented as modules, types will be
# separated into more groups, etc.
# The default value is: NO.
OPTIMIZE_OUTPUT_SLICE = NO
# Doxygen selects the parser to use depending on the extension of the files it
# parses. With this tag you can assign which parser to use for a given
# extension. Doxygen has a built-in mapping, but you can override or extend it
# using this tag. The format is ext=language, where ext is a file extension, and
# language is one of the parsers supported by doxygen: IDL, Java, JavaScript,
# Csharp (C#), C, C++, Lex, D, PHP, md (Markdown), Objective-C, Python, Slice,
# VHDL, Fortran (fixed format Fortran: FortranFixed, free formatted Fortran:
# FortranFree, unknown formatted Fortran: Fortran. In the later case the parser
# tries to guess whether the code is fixed or free formatted code, this is the
# default for Fortran type files). For instance to make doxygen treat .inc files
# as Fortran files (default is PHP), and .f files as C (default is Fortran),
# use: inc=Fortran f=C.
#
# Note: For files without extension you can use no_extension as a placeholder.
#
# Note that for custom extensions you also need to set FILE_PATTERNS otherwise
# the files are not read by doxygen. When specifying no_extension you should add
# * to the FILE_PATTERNS.
#
# Note see also the list of default file extension mappings.
EXTENSION_MAPPING =
# If the MARKDOWN_SUPPORT tag is enabled then doxygen pre-processes all comments
# according to the Markdown format, which allows for more readable
# documentation. See https://daringfireball.net/projects/markdown/ for details.
# The output of markdown processing is further processed by doxygen, so you can
# mix doxygen, HTML, and XML commands with Markdown formatting. Disable only in
# case of backward compatibilities issues.
# The default value is: YES.
MARKDOWN_SUPPORT = YES
# When the TOC_INCLUDE_HEADINGS tag is set to a non-zero value, all headings up
# to that level are automatically included in the table of contents, even if
# they do not have an id attribute.
# Note: This feature currently applies only to Markdown headings.
# Minimum value: 0, maximum value: 99, default value: 5.
# This tag requires that the tag MARKDOWN_SUPPORT is set to YES.
TOC_INCLUDE_HEADINGS = 0
# The MARKDOWN_ID_STYLE tag can be used to specify the algorithm used to
# generate identifiers for the Markdown headings. Note: Every identifier is
# unique.
# Possible values are: DOXYGEN use a fixed 'autotoc_md' string followed by a
# sequence number starting at 0 and GITHUB use the lower case version of title
# with any whitespace replaced by '-' and punctuation characters removed.
# The default value is: DOXYGEN.
# This tag requires that the tag MARKDOWN_SUPPORT is set to YES.
MARKDOWN_ID_STYLE = DOXYGEN
# When enabled doxygen tries to link words that correspond to documented
# classes, or namespaces to their corresponding documentation. Such a link can
# be prevented in individual cases by putting a % sign in front of the word or
# globally by setting AUTOLINK_SUPPORT to NO.
# The default value is: YES.
AUTOLINK_SUPPORT = YES
# If you use STL classes (i.e. std::string, std::vector, etc.) but do not want
# to include (a tag file for) the STL sources as input, then you should set this
# tag to YES in order to let doxygen match functions declarations and
# definitions whose arguments contain STL classes (e.g. func(std::string);
# versus func(std::string) {}). This also make the inheritance and collaboration
# diagrams that involve STL classes more complete and accurate.
# The default value is: NO.
BUILTIN_STL_SUPPORT = YES
# If you use Microsoft's C++/CLI language, you should set this option to YES to
# enable parsing support.
# The default value is: NO.
CPP_CLI_SUPPORT = NO
# Set the SIP_SUPPORT tag to YES if your project consists of sip (see:
# https://www.riverbankcomputing.com/software/sip/intro) sources only. Doxygen
# will parse them like normal C++ but will assume all classes use public instead
# of private inheritance when no explicit protection keyword is present.
# The default value is: NO.
SIP_SUPPORT = NO
# For Microsoft's IDL there are propget and propput attributes to indicate
# getter and setter methods for a property. Setting this option to YES will make
# doxygen to replace the get and set methods by a property in the documentation.
# This will only work if the methods are indeed getting or setting a simple
# type. If this is not the case, or you want to show the methods anyway, you
# should set this option to NO.
# The default value is: YES.
IDL_PROPERTY_SUPPORT = YES
# If member grouping is used in the documentation and the DISTRIBUTE_GROUP_DOC
# tag is set to YES then doxygen will reuse the documentation of the first
# member in the group (if any) for the other members of the group. By default
# all members of a group must be documented explicitly.
# The default value is: NO.
DISTRIBUTE_GROUP_DOC = NO
# If one adds a struct or class to a group and this option is enabled, then also
# any nested class or struct is added to the same group. By default this option
# is disabled and one has to add nested compounds explicitly via \ingroup.
# The default value is: NO.
GROUP_NESTED_COMPOUNDS = NO
# Set the SUBGROUPING tag to YES to allow class member groups of the same type
# (for instance a group of public functions) to be put as a subgroup of that
# type (e.g. under the Public Functions section). Set it to NO to prevent
# subgrouping. Alternatively, this can be done per class using the
# \nosubgrouping command.
# The default value is: YES.
SUBGROUPING = YES
# When the INLINE_GROUPED_CLASSES tag is set to YES, classes, structs and unions
# are shown inside the group in which they are included (e.g. using \ingroup)
# instead of on a separate page (for HTML and Man pages) or section (for LaTeX
# and RTF).
#
# Note that this feature does not work in combination with
# SEPARATE_MEMBER_PAGES.
# The default value is: NO.
INLINE_GROUPED_CLASSES = NO
# When the INLINE_SIMPLE_STRUCTS tag is set to YES, structs, classes, and unions
# with only public data fields or simple typedef fields will be shown inline in
# the documentation of the scope in which they are defined (i.e. file,
# namespace, or group documentation), provided this scope is documented. If set
# to NO, structs, classes, and unions are shown on a separate page (for HTML and
# Man pages) or section (for LaTeX and RTF).
# The default value is: NO.
INLINE_SIMPLE_STRUCTS = NO
# When TYPEDEF_HIDES_STRUCT tag is enabled, a typedef of a struct, union, or
# enum is documented as struct, union, or enum with the name of the typedef. So
# typedef struct TypeS {} TypeT, will appear in the documentation as a struct
# with name TypeT. When disabled the typedef will appear as a member of a file,
# namespace, or class. And the struct will be named TypeS. This can typically be
# useful for C code in case the coding convention dictates that all compound
# types are typedef'ed and only the typedef is referenced, never the tag name.
# The default value is: NO.
TYPEDEF_HIDES_STRUCT = NO
# The size of the symbol lookup cache can be set using LOOKUP_CACHE_SIZE. This
# cache is used to resolve symbols given their name and scope. Since this can be
# an expensive process and often the same symbol appears multiple times in the
# code, doxygen keeps a cache of pre-resolved symbols. If the cache is too small
# doxygen will become slower. If the cache is too large, memory is wasted. The
# cache size is given by this formula: 2^(16+LOOKUP_CACHE_SIZE). The valid range
# is 0..9, the default is 0, corresponding to a cache size of 2^16=65536
# symbols. At the end of a run doxygen will report the cache usage and suggest
# the optimal cache size from a speed point of view.
# Minimum value: 0, maximum value: 9, default value: 0.
LOOKUP_CACHE_SIZE = 0
# The NUM_PROC_THREADS specifies the number of threads doxygen is allowed to use
# during processing. When set to 0 doxygen will based this on the number of
# cores available in the system. You can set it explicitly to a value larger
# than 0 to get more control over the balance between CPU load and processing
# speed. At this moment only the input processing can be done using multiple
# threads. Since this is still an experimental feature the default is set to 1,
# which effectively disables parallel processing. Please report any issues you
# encounter. Generating dot graphs in parallel is controlled by the
# DOT_NUM_THREADS setting.
# Minimum value: 0, maximum value: 32, default value: 1.
NUM_PROC_THREADS = 1
# If the TIMESTAMP tag is set different from NO then each generated page will
# contain the date or date and time when the page was generated. Setting this to
# NO can help when comparing the output of multiple runs.
# Possible values are: YES, NO, DATETIME and DATE.
# The default value is: NO.
TIMESTAMP = YES
#---------------------------------------------------------------------------
# Build related configuration options
#---------------------------------------------------------------------------
# If the EXTRACT_ALL tag is set to YES, doxygen will assume all entities in
# documentation are documented, even if no documentation was available. Private
# class members and static file members will be hidden unless the
# EXTRACT_PRIVATE respectively EXTRACT_STATIC tags are set to YES.
# Note: This will also disable the warnings about undocumented members that are
# normally produced when WARNINGS is set to YES.
# The default value is: NO.
EXTRACT_ALL = YES
# If the EXTRACT_PRIVATE tag is set to YES, all private members of a class will
# be included in the documentation.
# The default value is: NO.
EXTRACT_PRIVATE = NO
# If the EXTRACT_PRIV_VIRTUAL tag is set to YES, documented private virtual
# methods of a class will be included in the documentation.
# The default value is: NO.
EXTRACT_PRIV_VIRTUAL = NO
# If the EXTRACT_PACKAGE tag is set to YES, all members with package or internal
# scope will be included in the documentation.
# The default value is: NO.
EXTRACT_PACKAGE = NO
# If the EXTRACT_STATIC tag is set to YES, all static members of a file will be
# included in the documentation.
# The default value is: NO.
EXTRACT_STATIC = NO
# If the EXTRACT_LOCAL_CLASSES tag is set to YES, classes (and structs) defined
# locally in source files will be included in the documentation. If set to NO,
# only classes defined in header files are included. Does not have any effect
# for Java sources.
# The default value is: YES.
EXTRACT_LOCAL_CLASSES = YES
# This flag is only useful for Objective-C code. If set to YES, local methods,
# which are defined in the implementation section but not in the interface are
# included in the documentation. If set to NO, only methods in the interface are
# included.
# The default value is: NO.
EXTRACT_LOCAL_METHODS = NO
# If this flag is set to YES, the members of anonymous namespaces will be
# extracted and appear in the documentation as a namespace called
# 'anonymous_namespace{file}', where file will be replaced with the base name of
# the file that contains the anonymous namespace. By default anonymous namespace
# are hidden.
# The default value is: NO.
EXTRACT_ANON_NSPACES = NO
# If this flag is set to YES, the name of an unnamed parameter in a declaration
# will be determined by the corresponding definition. By default unnamed
# parameters remain unnamed in the output.
# The default value is: YES.
RESOLVE_UNNAMED_PARAMS = YES
# If the HIDE_UNDOC_MEMBERS tag is set to YES, doxygen will hide all
# undocumented members inside documented classes or files. If set to NO these
# members will be included in the various overviews, but no documentation
# section is generated. This option has no effect if EXTRACT_ALL is enabled.
# The default value is: NO.
HIDE_UNDOC_MEMBERS = NO
# If the HIDE_UNDOC_CLASSES tag is set to YES, doxygen will hide all
# undocumented classes that are normally visible in the class hierarchy. If set
# to NO, these classes will be included in the various overviews. This option
# will also hide undocumented C++ concepts if enabled. This option has no effect
# if EXTRACT_ALL is enabled.
# The default value is: NO.
HIDE_UNDOC_CLASSES = NO
# If the HIDE_FRIEND_COMPOUNDS tag is set to YES, doxygen will hide all friend
# declarations. If set to NO, these declarations will be included in the
# documentation.
# The default value is: NO.
HIDE_FRIEND_COMPOUNDS = NO
# If the HIDE_IN_BODY_DOCS tag is set to YES, doxygen will hide any
# documentation blocks found inside the body of a function. If set to NO, these
# blocks will be appended to the function's detailed documentation block.
# The default value is: NO.
HIDE_IN_BODY_DOCS = NO
# The INTERNAL_DOCS tag determines if documentation that is typed after a
# \internal command is included. If the tag is set to NO then the documentation
# will be excluded. Set it to YES to include the internal documentation.
# The default value is: NO.
INTERNAL_DOCS = NO
# With the correct setting of option CASE_SENSE_NAMES doxygen will better be
# able to match the capabilities of the underlying filesystem. In case the
# filesystem is case sensitive (i.e. it supports files in the same directory
# whose names only differ in casing), the option must be set to YES to properly
# deal with such files in case they appear in the input. For filesystems that
# are not case sensitive the option should be set to NO to properly deal with
# output files written for symbols that only differ in casing, such as for two
# classes, one named CLASS and the other named Class, and to also support
# references to files without having to specify the exact matching casing. On
# Windows (including Cygwin) and MacOS, users should typically set this option
# to NO, whereas on Linux or other Unix flavors it should typically be set to
# YES.
# Possible values are: SYSTEM, NO and YES.
# The default value is: SYSTEM.
CASE_SENSE_NAMES = YES
# If the HIDE_SCOPE_NAMES tag is set to NO then doxygen will show members with
# their full class and namespace scopes in the documentation. If set to YES, the
# scope will be hidden.
# The default value is: NO.
HIDE_SCOPE_NAMES = NO
# If the HIDE_COMPOUND_REFERENCE tag is set to NO (default) then doxygen will
# append additional text to a page's title, such as Class Reference. If set to
# YES the compound reference will be hidden.
# The default value is: NO.
HIDE_COMPOUND_REFERENCE= NO
# If the SHOW_HEADERFILE tag is set to YES then the documentation for a class
# will show which file needs to be included to use the class.
# The default value is: YES.
SHOW_HEADERFILE = YES
# If the SHOW_INCLUDE_FILES tag is set to YES then doxygen will put a list of
# the files that are included by a file in the documentation of that file.
# The default value is: YES.
SHOW_INCLUDE_FILES = YES
# If the SHOW_GROUPED_MEMB_INC tag is set to YES then Doxygen will add for each
# grouped member an include statement to the documentation, telling the reader
# which file to include in order to use the member.
# The default value is: NO.
SHOW_GROUPED_MEMB_INC = NO
# If the FORCE_LOCAL_INCLUDES tag is set to YES then doxygen will list include
# files with double quotes in the documentation rather than with sharp brackets.
# The default value is: NO.
FORCE_LOCAL_INCLUDES = NO
# If the INLINE_INFO tag is set to YES then a tag [inline] is inserted in the
# documentation for inline members.
# The default value is: YES.
INLINE_INFO = YES
# If the SORT_MEMBER_DOCS tag is set to YES then doxygen will sort the
# (detailed) documentation of file and class members alphabetically by member
# name. If set to NO, the members will appear in declaration order.
# The default value is: YES.
SORT_MEMBER_DOCS = YES
# If the SORT_BRIEF_DOCS tag is set to YES then doxygen will sort the brief
# descriptions of file, namespace and class members alphabetically by member
# name. If set to NO, the members will appear in declaration order. Note that
# this will also influence the order of the classes in the class list.
# The default value is: NO.
SORT_BRIEF_DOCS = NO
# If the SORT_MEMBERS_CTORS_1ST tag is set to YES then doxygen will sort the
# (brief and detailed) documentation of class members so that constructors and
# destructors are listed first. If set to NO the constructors will appear in the
# respective orders defined by SORT_BRIEF_DOCS and SORT_MEMBER_DOCS.
# Note: If SORT_BRIEF_DOCS is set to NO this option is ignored for sorting brief
# member documentation.
# Note: If SORT_MEMBER_DOCS is set to NO this option is ignored for sorting
# detailed member documentation.
# The default value is: NO.
SORT_MEMBERS_CTORS_1ST = NO
# If the SORT_GROUP_NAMES tag is set to YES then doxygen will sort the hierarchy
# of group names into alphabetical order. If set to NO the group names will
# appear in their defined order.
# The default value is: NO.
SORT_GROUP_NAMES = NO
# If the SORT_BY_SCOPE_NAME tag is set to YES, the class list will be sorted by
# fully-qualified names, including namespaces. If set to NO, the class list will
# be sorted only by class name, not including the namespace part.
# Note: This option is not very useful if HIDE_SCOPE_NAMES is set to YES.
# Note: This option applies only to the class list, not to the alphabetical
# list.
# The default value is: NO.
SORT_BY_SCOPE_NAME = NO
# If the STRICT_PROTO_MATCHING option is enabled and doxygen fails to do proper
# type resolution of all parameters of a function it will reject a match between
# the prototype and the implementation of a member function even if there is
# only one candidate or it is obvious which candidate to choose by doing a
# simple string match. By disabling STRICT_PROTO_MATCHING doxygen will still
# accept a match between prototype and implementation in such cases.
# The default value is: NO.
STRICT_PROTO_MATCHING = NO
# The GENERATE_TODOLIST tag can be used to enable (YES) or disable (NO) the todo
# list. This list is created by putting \todo commands in the documentation.
# The default value is: YES.
GENERATE_TODOLIST = YES
# The GENERATE_TESTLIST tag can be used to enable (YES) or disable (NO) the test
# list. This list is created by putting \test commands in the documentation.
# The default value is: YES.
GENERATE_TESTLIST = YES
# The GENERATE_BUGLIST tag can be used to enable (YES) or disable (NO) the bug
# list. This list is created by putting \bug commands in the documentation.
# The default value is: YES.
GENERATE_BUGLIST = YES
# The GENERATE_DEPRECATEDLIST tag can be used to enable (YES) or disable (NO)
# the deprecated list. This list is created by putting \deprecated commands in
# the documentation.
# The default value is: YES.
GENERATE_DEPRECATEDLIST= YES
# The ENABLED_SECTIONS tag can be used to enable conditional documentation
# sections, marked by \if ... \endif and \cond
# ... \endcond blocks.
ENABLED_SECTIONS =
# The MAX_INITIALIZER_LINES tag determines the maximum number of lines that the
# initial value of a variable or macro / define can have for it to appear in the
# documentation. If the initializer consists of more lines than specified here
# it will be hidden. Use a value of 0 to hide initializers completely. The
# appearance of the value of individual variables and macros / defines can be
# controlled using \showinitializer or \hideinitializer command in the
# documentation regardless of this setting.
# Minimum value: 0, maximum value: 10000, default value: 30.
MAX_INITIALIZER_LINES = 30
# Set the SHOW_USED_FILES tag to NO to disable the list of files generated at
# the bottom of the documentation of classes and structs. If set to YES, the
# list will mention the files that were used to generate the documentation.
# The default value is: YES.
SHOW_USED_FILES = YES
# Set the SHOW_FILES tag to NO to disable the generation of the Files page. This
# will remove the Files entry from the Quick Index and from the Folder Tree View
# (if specified).
# The default value is: YES.
SHOW_FILES = YES
# Set the SHOW_NAMESPACES tag to NO to disable the generation of the Namespaces
# page. This will remove the Namespaces entry from the Quick Index and from the
# Folder Tree View (if specified).
# The default value is: YES.
SHOW_NAMESPACES = YES
# The FILE_VERSION_FILTER tag can be used to specify a program or script that
# doxygen should invoke to get the current version for each file (typically from
# the version control system). Doxygen will invoke the program by executing (via
# popen()) the command command input-file, where command is the value of the
# FILE_VERSION_FILTER tag, and input-file is the name of an input file provided
# by doxygen. Whatever the program writes to standard output is used as the file
# version. For an example see the documentation.
FILE_VERSION_FILTER =
# The LAYOUT_FILE tag can be used to specify a layout file which will be parsed
# by doxygen. The layout file controls the global structure of the generated
# output files in an output format independent way. To create the layout file
# that represents doxygen's defaults, run doxygen with the -l option. You can
# optionally specify a file name after the option, if omitted DoxygenLayout.xml
# will be used as the name of the layout file. See also section "Changing the
# layout of pages" for information.
#
# Note that if you run doxygen from a directory containing a file called
# DoxygenLayout.xml, doxygen will parse it automatically even if the LAYOUT_FILE
# tag is left empty.
LAYOUT_FILE =
# The CITE_BIB_FILES tag can be used to specify one or more bib files containing
# the reference definitions. This must be a list of .bib files. The .bib
# extension is automatically appended if omitted. This requires the bibtex tool
# to be installed. See also https://en.wikipedia.org/wiki/BibTeX for more info.
# For LaTeX the style of the bibliography can be controlled using
# LATEX_BIB_STYLE. To use this feature you need bibtex and perl available in the
# search path. See also \cite for info how to create references.
CITE_BIB_FILES =
#---------------------------------------------------------------------------
# Configuration options related to warning and progress messages
#---------------------------------------------------------------------------
# The QUIET tag can be used to turn on/off the messages that are generated to
# standard output by doxygen. If QUIET is set to YES this implies that the
# messages are off.
# The default value is: NO.
QUIET = NO
# The WARNINGS tag can be used to turn on/off the warning messages that are
# generated to standard error (stderr) by doxygen. If WARNINGS is set to YES
# this implies that the warnings are on.
#
# Tip: Turn warnings on while writing the documentation.
# The default value is: YES.
WARNINGS = YES
# If the WARN_IF_UNDOCUMENTED tag is set to YES then doxygen will generate
# warnings for undocumented members. If EXTRACT_ALL is set to YES then this flag
# will automatically be disabled.
# The default value is: YES.
WARN_IF_UNDOCUMENTED = YES
# If the WARN_IF_DOC_ERROR tag is set to YES, doxygen will generate warnings for
# potential errors in the documentation, such as documenting some parameters in
# a documented function twice, or documenting parameters that don't exist or
# using markup commands wrongly.
# The default value is: YES.
WARN_IF_DOC_ERROR = YES
# If WARN_IF_INCOMPLETE_DOC is set to YES, doxygen will warn about incomplete
# function parameter documentation. If set to NO, doxygen will accept that some
# parameters have no documentation without warning.
# The default value is: YES.
WARN_IF_INCOMPLETE_DOC = YES
# This WARN_NO_PARAMDOC option can be enabled to get warnings for functions that
# are documented, but have no documentation for their parameters or return
# value. If set to NO, doxygen will only warn about wrong parameter
# documentation, but not about the absence of documentation. If EXTRACT_ALL is
# set to YES then this flag will automatically be disabled. See also
# WARN_IF_INCOMPLETE_DOC
# The default value is: NO.
WARN_NO_PARAMDOC = NO
# If WARN_IF_UNDOC_ENUM_VAL option is set to YES, doxygen will warn about
# undocumented enumeration values. If set to NO, doxygen will accept
# undocumented enumeration values. If EXTRACT_ALL is set to YES then this flag
# will automatically be disabled.
# The default value is: NO.
WARN_IF_UNDOC_ENUM_VAL = NO
# If the WARN_AS_ERROR tag is set to YES then doxygen will immediately stop when
# a warning is encountered. If the WARN_AS_ERROR tag is set to FAIL_ON_WARNINGS
# then doxygen will continue running as if WARN_AS_ERROR tag is set to NO, but
# at the end of the doxygen process doxygen will return with a non-zero status.
# If the WARN_AS_ERROR tag is set to FAIL_ON_WARNINGS_PRINT then doxygen behaves
# like FAIL_ON_WARNINGS but in case no WARN_LOGFILE is defined doxygen will not
# write the warning messages in between other messages but write them at the end
# of a run, in case a WARN_LOGFILE is defined the warning messages will be
# besides being in the defined file also be shown at the end of a run, unless
# the WARN_LOGFILE is defined as - i.e. standard output (stdout) in that case
# the behavior will remain as with the setting FAIL_ON_WARNINGS.
# Possible values are: NO, YES, FAIL_ON_WARNINGS and FAIL_ON_WARNINGS_PRINT.
# The default value is: NO.
WARN_AS_ERROR = NO
# The WARN_FORMAT tag determines the format of the warning messages that doxygen
# can produce. The string should contain the $file, $line, and $text tags, which
# will be replaced by the file and line number from which the warning originated
# and the warning text. Optionally the format may contain $version, which will
# be replaced by the version of the file (if it could be obtained via
# FILE_VERSION_FILTER)
# See also: WARN_LINE_FORMAT
# The default value is: $file:$line: $text.
WARN_FORMAT = "$file:$line: $text"
# In the $text part of the WARN_FORMAT command it is possible that a reference
# to a more specific place is given. To make it easier to jump to this place
# (outside of doxygen) the user can define a custom "cut" / "paste" string.
# Example:
# WARN_LINE_FORMAT = "'vi $file +$line'"
# See also: WARN_FORMAT
# The default value is: at line $line of file $file.
WARN_LINE_FORMAT = "at line $line of file $file"
# The WARN_LOGFILE tag can be used to specify a file to which warning and error
# messages should be written. If left blank the output is written to standard
# error (stderr). In case the file specified cannot be opened for writing the
# warning and error messages are written to standard error. When as file - is
# specified the warning and error messages are written to standard output
# (stdout).
WARN_LOGFILE =
#---------------------------------------------------------------------------
# Configuration options related to the input files
#---------------------------------------------------------------------------
# The INPUT tag is used to specify the files and/or directories that contain
# documented source files. You may enter file names like myfile.cpp or
# directories like /usr/src/myproject. Separate the files or directories with
# spaces. See also FILE_PATTERNS and EXTENSION_MAPPING
# Note: If this tag is empty the current directory is searched.
INPUT = ../src \
../include/frog/
# This tag can be used to specify the character encoding of the source files
# that doxygen parses. Internally doxygen uses the UTF-8 encoding. Doxygen uses
# libiconv (or the iconv built into libc) for the transcoding. See the libiconv
# documentation (see:
# https://www.gnu.org/software/libiconv/) for the list of possible encodings.
# See also: INPUT_FILE_ENCODING
# The default value is: UTF-8.
INPUT_ENCODING = UTF-8
# This tag can be used to specify the character encoding of the source files
# that doxygen parses The INPUT_FILE_ENCODING tag can be used to specify
# character encoding on a per file pattern basis. Doxygen will compare the file
# name with each pattern and apply the encoding instead of the default
# INPUT_ENCODING) if there is a match. The character encodings are a list of the
# form: pattern=encoding (like *.php=ISO-8859-1). See cfg_input_encoding
# "INPUT_ENCODING" for further information on supported encodings.
INPUT_FILE_ENCODING =
# If the value of the INPUT tag contains directories, you can use the
# FILE_PATTERNS tag to specify one or more wildcard patterns (like *.cpp and
# *.h) to filter out the source-files in the directories.
#
# Note that for custom extensions or not directly supported extensions you also
# need to set EXTENSION_MAPPING for the extension otherwise the files are not
# read by doxygen.
#
# Note the list of default checked file patterns might differ from the list of
# default file extension mappings.
#
# If left blank the following patterns are tested:*.c, *.cc, *.cxx, *.cxxm,
# *.cpp, *.cppm, *.c++, *.c++m, *.java, *.ii, *.ixx, *.ipp, *.i++, *.inl, *.idl,
# *.ddl, *.odl, *.h, *.hh, *.hxx, *.hpp, *.h++, *.ixx, *.l, *.cs, *.d, *.php,
# *.php4, *.php5, *.phtml, *.inc, *.m, *.markdown, *.md, *.mm, *.dox (to be
# provided as doxygen C comment), *.py, *.pyw, *.f90, *.f95, *.f03, *.f08,
# *.f18, *.f, *.for, *.vhd, *.vhdl, *.ucf, *.qsf and *.ice.
FILE_PATTERNS = *.c \
*.cc \
*.cxx \
*.cpp \
*.c++ \
*.java \
*.ii \
*.ixx \
*.ipp \
*.i++ \
*.inl \
*.idl \
*.ddl \
*.odl \
*.h \
*.hh \
*.hxx \
*.hpp \
*.h++ \
*.cs \
*.d \
*.php \
*.php4 \
*.php5 \
*.phtml \
*.inc \
*.m \
*.markdown \
*.md \
*.mm \
*.dox \
*.py \
*.pyw \
*.f90 \
*.f95 \
*.f03 \
*.f08 \
*.f \
*.for \
*.tcl \
*.vhd \
*.vhdl \
*.ucf \
*.qsf
# The RECURSIVE tag can be used to specify whether or not subdirectories should
# be searched for input files as well.
# The default value is: NO.
RECURSIVE = YES
# The EXCLUDE tag can be used to specify files and/or directories that should be
# excluded from the INPUT source files. This way you can easily exclude a
# subdirectory from a directory tree whose root is specified with the INPUT tag.
#
# Note that relative paths are relative to the directory from which doxygen is
# run.
EXCLUDE =
# The EXCLUDE_SYMLINKS tag can be used to select whether or not files or
# directories that are symbolic links (a Unix file system feature) are excluded
# from the input.
# The default value is: NO.
EXCLUDE_SYMLINKS = NO
# If the value of the INPUT tag contains directories, you can use the
# EXCLUDE_PATTERNS tag to specify one or more wildcard patterns to exclude
# certain files from those directories.
#
# Note that the wildcards are matched against the file with absolute path, so to
# exclude all test directories for example use the pattern */test/*
EXCLUDE_PATTERNS =
# The EXCLUDE_SYMBOLS tag can be used to specify one or more symbol names
# (namespaces, classes, functions, etc.) that should be excluded from the
# output. The symbol name can be a fully qualified name, a word, or if the
# wildcard * is used, a substring. Examples: ANamespace, AClass,
# ANamespace::AClass, ANamespace::*Test
EXCLUDE_SYMBOLS =
# The EXAMPLE_PATH tag can be used to specify one or more files or directories
# that contain example code fragments that are included (see the \include
# command).
EXAMPLE_PATH =
# If the value of the EXAMPLE_PATH tag contains directories, you can use the
# EXAMPLE_PATTERNS tag to specify one or more wildcard pattern (like *.cpp and
# *.h) to filter out the source-files in the directories. If left blank all
# files are included.
EXAMPLE_PATTERNS = *
# If the EXAMPLE_RECURSIVE tag is set to YES then subdirectories will be
# searched for input files to be used with the \include or \dontinclude commands
# irrespective of the value of the RECURSIVE tag.
# The default value is: NO.
EXAMPLE_RECURSIVE = NO
# The IMAGE_PATH tag can be used to specify one or more files or directories
# that contain images that are to be included in the documentation (see the
# \image command).
IMAGE_PATH =
# The INPUT_FILTER tag can be used to specify a program that doxygen should
# invoke to filter for each input file. Doxygen will invoke the filter program
# by executing (via popen()) the command:
#
#
#
# where is the value of the INPUT_FILTER tag, and is the
# name of an input file. Doxygen will then use the output that the filter
# program writes to standard output. If FILTER_PATTERNS is specified, this tag
# will be ignored.
#
# Note that the filter must not add or remove lines; it is applied before the
# code is scanned, but not when the output code is generated. If lines are added
# or removed, the anchors will not be placed correctly.
#
# Note that doxygen will use the data processed and written to standard output
# for further processing, therefore nothing else, like debug statements or used
# commands (so in case of a Windows batch file always use @echo OFF), should be
# written to standard output.
#
# Note that for custom extensions or not directly supported extensions you also
# need to set EXTENSION_MAPPING for the extension otherwise the files are not
# properly processed by doxygen.
INPUT_FILTER =
# The FILTER_PATTERNS tag can be used to specify filters on a per file pattern
# basis. Doxygen will compare the file name with each pattern and apply the
# filter if there is a match. The filters are a list of the form: pattern=filter
# (like *.cpp=my_cpp_filter). See INPUT_FILTER for further information on how
# filters are used. If the FILTER_PATTERNS tag is empty or if none of the
# patterns match the file name, INPUT_FILTER is applied.
#
# Note that for custom extensions or not directly supported extensions you also
# need to set EXTENSION_MAPPING for the extension otherwise the files are not
# properly processed by doxygen.
FILTER_PATTERNS =
# If the FILTER_SOURCE_FILES tag is set to YES, the input filter (if set using
# INPUT_FILTER) will also be used to filter the input files that are used for
# producing the source files to browse (i.e. when SOURCE_BROWSER is set to YES).
# The default value is: NO.
FILTER_SOURCE_FILES = NO
# The FILTER_SOURCE_PATTERNS tag can be used to specify source filters per file
# pattern. A pattern will override the setting for FILTER_PATTERN (if any) and
# it is also possible to disable source filtering for a specific pattern using
# *.ext= (so without naming a filter).
# This tag requires that the tag FILTER_SOURCE_FILES is set to YES.
FILTER_SOURCE_PATTERNS =
# If the USE_MDFILE_AS_MAINPAGE tag refers to the name of a markdown file that
# is part of the input, its contents will be placed on the main page
# (index.html). This can be useful if you have a project on for instance GitHub
# and want to reuse the introduction page also for the doxygen output.
USE_MDFILE_AS_MAINPAGE =
# The Fortran standard specifies that for fixed formatted Fortran code all
# characters from position 72 are to be considered as comment. A common
# extension is to allow longer lines before the automatic comment starts. The
# setting FORTRAN_COMMENT_AFTER will also make it possible that longer lines can
# be processed before the automatic comment starts.
# Minimum value: 7, maximum value: 10000, default value: 72.
FORTRAN_COMMENT_AFTER = 72
#---------------------------------------------------------------------------
# Configuration options related to source browsing
#---------------------------------------------------------------------------
# If the SOURCE_BROWSER tag is set to YES then a list of source files will be
# generated. Documented entities will be cross-referenced with these sources.
#
# Note: To get rid of all source code in the generated output, make sure that
# also VERBATIM_HEADERS is set to NO.
# The default value is: NO.
SOURCE_BROWSER = NO
# Setting the INLINE_SOURCES tag to YES will include the body of functions,
# classes and enums directly into the documentation.
# The default value is: NO.
INLINE_SOURCES = NO
# Setting the STRIP_CODE_COMMENTS tag to YES will instruct doxygen to hide any
# special comment blocks from generated source code fragments. Normal C, C++ and
# Fortran comments will always remain visible.
# The default value is: YES.
STRIP_CODE_COMMENTS = YES
# If the REFERENCED_BY_RELATION tag is set to YES then for each documented
# entity all documented functions referencing it will be listed.
# The default value is: NO.
REFERENCED_BY_RELATION = NO
# If the REFERENCES_RELATION tag is set to YES then for each documented function
# all documented entities called/used by that function will be listed.
# The default value is: NO.
REFERENCES_RELATION = NO
# If the REFERENCES_LINK_SOURCE tag is set to YES and SOURCE_BROWSER tag is set
# to YES then the hyperlinks from functions in REFERENCES_RELATION and
# REFERENCED_BY_RELATION lists will link to the source code. Otherwise they will
# link to the documentation.
# The default value is: YES.
REFERENCES_LINK_SOURCE = YES
# If SOURCE_TOOLTIPS is enabled (the default) then hovering a hyperlink in the
# source code will show a tooltip with additional information such as prototype,
# brief description and links to the definition and documentation. Since this
# will make the HTML file larger and loading of large files a bit slower, you
# can opt to disable this feature.
# The default value is: YES.
# This tag requires that the tag SOURCE_BROWSER is set to YES.
SOURCE_TOOLTIPS = YES
# If the USE_HTAGS tag is set to YES then the references to source code will
# point to the HTML generated by the htags(1) tool instead of doxygen built-in
# source browser. The htags tool is part of GNU's global source tagging system
# (see https://www.gnu.org/software/global/global.html). You will need version
# 4.8.6 or higher.
#
# To use it do the following:
# - Install the latest version of global
# - Enable SOURCE_BROWSER and USE_HTAGS in the configuration file
# - Make sure the INPUT points to the root of the source tree
# - Run doxygen as normal
#
# Doxygen will invoke htags (and that will in turn invoke gtags), so these
# tools must be available from the command line (i.e. in the search path).
#
# The result: instead of the source browser generated by doxygen, the links to
# source code will now point to the output of htags.
# The default value is: NO.
# This tag requires that the tag SOURCE_BROWSER is set to YES.
USE_HTAGS = NO
# If the VERBATIM_HEADERS tag is set the YES then doxygen will generate a
# verbatim copy of the header file for each class for which an include is
# specified. Set to NO to disable this.
# See also: Section \class.
# The default value is: YES.
VERBATIM_HEADERS = YES
# If the CLANG_ASSISTED_PARSING tag is set to YES then doxygen will use the
# clang parser (see:
# http://clang.llvm.org/) for more accurate parsing at the cost of reduced
# performance. This can be particularly helpful with template rich C++ code for
# which doxygen's built-in parser lacks the necessary type information.
# Note: The availability of this option depends on whether or not doxygen was
# generated with the -Duse_libclang=ON option for CMake.
# The default value is: NO.
CLANG_ASSISTED_PARSING = NO
# If the CLANG_ASSISTED_PARSING tag is set to YES and the CLANG_ADD_INC_PATHS
# tag is set to YES then doxygen will add the directory of each input to the
# include path.
# The default value is: YES.
# This tag requires that the tag CLANG_ASSISTED_PARSING is set to YES.
CLANG_ADD_INC_PATHS = YES
# If clang assisted parsing is enabled you can provide the compiler with command
# line options that you would normally use when invoking the compiler. Note that
# the include paths will already be set by doxygen for the files and directories
# specified with INPUT and INCLUDE_PATH.
# This tag requires that the tag CLANG_ASSISTED_PARSING is set to YES.
CLANG_OPTIONS =
# If clang assisted parsing is enabled you can provide the clang parser with the
# path to the directory containing a file called compile_commands.json. This
# file is the compilation database (see:
# http://clang.llvm.org/docs/HowToSetupToolingForLLVM.html) containing the
# options used when the source files were built. This is equivalent to
# specifying the -p option to a clang tool, such as clang-check. These options
# will then be passed to the parser. Any options specified with CLANG_OPTIONS
# will be added as well.
# Note: The availability of this option depends on whether or not doxygen was
# generated with the -Duse_libclang=ON option for CMake.
CLANG_DATABASE_PATH =
#---------------------------------------------------------------------------
# Configuration options related to the alphabetical class index
#---------------------------------------------------------------------------
# If the ALPHABETICAL_INDEX tag is set to YES, an alphabetical index of all
# compounds will be generated. Enable this if the project contains a lot of
# classes, structs, unions or interfaces.
# The default value is: YES.
ALPHABETICAL_INDEX = YES
# The IGNORE_PREFIX tag can be used to specify a prefix (or a list of prefixes)
# that should be ignored while generating the index headers. The IGNORE_PREFIX
# tag works for classes, function and member names. The entity will be placed in
# the alphabetical list under the first letter of the entity name that remains
# after removing the prefix.
# This tag requires that the tag ALPHABETICAL_INDEX is set to YES.
IGNORE_PREFIX =
#---------------------------------------------------------------------------
# Configuration options related to the HTML output
#---------------------------------------------------------------------------
# If the GENERATE_HTML tag is set to YES, doxygen will generate HTML output
# The default value is: YES.
GENERATE_HTML = YES
# The HTML_OUTPUT tag is used to specify where the HTML docs will be put. If a
# relative path is entered the value of OUTPUT_DIRECTORY will be put in front of
# it.
# The default directory is: html.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_OUTPUT = html
# The HTML_FILE_EXTENSION tag can be used to specify the file extension for each
# generated HTML page (for example: .htm, .php, .asp).
# The default value is: .html.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_FILE_EXTENSION = .html
# The HTML_HEADER tag can be used to specify a user-defined HTML header file for
# each generated HTML page. If the tag is left blank doxygen will generate a
# standard header.
#
# To get valid HTML the header file that includes any scripts and style sheets
# that doxygen needs, which is dependent on the configuration options used (e.g.
# the setting GENERATE_TREEVIEW). It is highly recommended to start with a
# default header using
# doxygen -w html new_header.html new_footer.html new_stylesheet.css
# YourConfigFile
# and then modify the file new_header.html. See also section "Doxygen usage"
# for information on how to generate the default header that doxygen normally
# uses.
# Note: The header is subject to change so you typically have to regenerate the
# default header when upgrading to a newer version of doxygen. For a description
# of the possible markers and block names see the documentation.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_HEADER =
# The HTML_FOOTER tag can be used to specify a user-defined HTML footer for each
# generated HTML page. If the tag is left blank doxygen will generate a standard
# footer. See HTML_HEADER for more information on how to generate a default
# footer and what special commands can be used inside the footer. See also
# section "Doxygen usage" for information on how to generate the default footer
# that doxygen normally uses.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_FOOTER =
# The HTML_STYLESHEET tag can be used to specify a user-defined cascading style
# sheet that is used by each HTML page. It can be used to fine-tune the look of
# the HTML output. If left blank doxygen will generate a default style sheet.
# See also section "Doxygen usage" for information on how to generate the style
# sheet that doxygen normally uses.
# Note: It is recommended to use HTML_EXTRA_STYLESHEET instead of this tag, as
# it is more robust and this tag (HTML_STYLESHEET) will in the future become
# obsolete.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_STYLESHEET =
# The HTML_EXTRA_STYLESHEET tag can be used to specify additional user-defined
# cascading style sheets that are included after the standard style sheets
# created by doxygen. Using this option one can overrule certain style aspects.
# This is preferred over using HTML_STYLESHEET since it does not replace the
# standard style sheet and is therefore more robust against future updates.
# Doxygen will copy the style sheet files to the output directory.
# Note: The order of the extra style sheet files is of importance (e.g. the last
# style sheet in the list overrules the setting of the previous ones in the
# list).
# Note: Since the styling of scrollbars can currently not be overruled in
# Webkit/Chromium, the styling will be left out of the default doxygen.css if
# one or more extra stylesheets have been specified. So if scrollbar
# customization is desired it has to be added explicitly. For an example see the
# documentation.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_EXTRA_STYLESHEET =
# The HTML_EXTRA_FILES tag can be used to specify one or more extra images or
# other source files which should be copied to the HTML output directory. Note
# that these files will be copied to the base HTML output directory. Use the
# $relpath^ marker in the HTML_HEADER and/or HTML_FOOTER files to load these
# files. In the HTML_STYLESHEET file, use the file name only. Also note that the
# files will be copied as-is; there are no commands or markers available.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_EXTRA_FILES =
# The HTML_COLORSTYLE tag can be used to specify if the generated HTML output
# should be rendered with a dark or light theme.
# Possible values are: LIGHT always generate light mode output, DARK always
# generate dark mode output, AUTO_LIGHT automatically set the mode according to
# the user preference, use light mode if no preference is set (the default),
# AUTO_DARK automatically set the mode according to the user preference, use
# dark mode if no preference is set and TOGGLE allow to user to switch between
# light and dark mode via a button.
# The default value is: AUTO_LIGHT.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_COLORSTYLE = AUTO_LIGHT
# The HTML_COLORSTYLE_HUE tag controls the color of the HTML output. Doxygen
# will adjust the colors in the style sheet and background images according to
# this color. Hue is specified as an angle on a color-wheel, see
# https://en.wikipedia.org/wiki/Hue for more information. For instance the value
# 0 represents red, 60 is yellow, 120 is green, 180 is cyan, 240 is blue, 300
# purple, and 360 is red again.
# Minimum value: 0, maximum value: 359, default value: 220.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_COLORSTYLE_HUE = 220
# The HTML_COLORSTYLE_SAT tag controls the purity (or saturation) of the colors
# in the HTML output. For a value of 0 the output will use gray-scales only. A
# value of 255 will produce the most vivid colors.
# Minimum value: 0, maximum value: 255, default value: 100.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_COLORSTYLE_SAT = 100
# The HTML_COLORSTYLE_GAMMA tag controls the gamma correction applied to the
# luminance component of the colors in the HTML output. Values below 100
# gradually make the output lighter, whereas values above 100 make the output
# darker. The value divided by 100 is the actual gamma applied, so 80 represents
# a gamma of 0.8, The value 220 represents a gamma of 2.2, and 100 does not
# change the gamma.
# Minimum value: 40, maximum value: 240, default value: 80.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_COLORSTYLE_GAMMA = 80
# If the HTML_DYNAMIC_MENUS tag is set to YES then the generated HTML
# documentation will contain a main index with vertical navigation menus that
# are dynamically created via JavaScript. If disabled, the navigation index will
# consists of multiple levels of tabs that are statically embedded in every HTML
# page. Disable this option to support browsers that do not have JavaScript,
# like the Qt help browser.
# The default value is: YES.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_DYNAMIC_MENUS = YES
# If the HTML_DYNAMIC_SECTIONS tag is set to YES then the generated HTML
# documentation will contain sections that can be hidden and shown after the
# page has loaded.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_DYNAMIC_SECTIONS = NO
# If the HTML_CODE_FOLDING tag is set to YES then classes and functions can be
# dynamically folded and expanded in the generated HTML source code.
# The default value is: YES.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_CODE_FOLDING = YES
# With HTML_INDEX_NUM_ENTRIES one can control the preferred number of entries
# shown in the various tree structured indices initially; the user can expand
# and collapse entries dynamically later on. Doxygen will expand the tree to
# such a level that at most the specified number of entries are visible (unless
# a fully collapsed tree already exceeds this amount). So setting the number of
# entries 1 will produce a full collapsed tree by default. 0 is a special value
# representing an infinite number of entries and will result in a full expanded
# tree by default.
# Minimum value: 0, maximum value: 9999, default value: 100.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_INDEX_NUM_ENTRIES = 100
# If the GENERATE_DOCSET tag is set to YES, additional index files will be
# generated that can be used as input for Apple's Xcode 3 integrated development
# environment (see:
# https://developer.apple.com/xcode/), introduced with OSX 10.5 (Leopard). To
# create a documentation set, doxygen will generate a Makefile in the HTML
# output directory. Running make will produce the docset in that directory and
# running make install will install the docset in
# ~/Library/Developer/Shared/Documentation/DocSets so that Xcode will find it at
# startup. See https://developer.apple.com/library/archive/featuredarticles/Doxy
# genXcode/_index.html for more information.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
GENERATE_DOCSET = NO
# This tag determines the name of the docset feed. A documentation feed provides
# an umbrella under which multiple documentation sets from a single provider
# (such as a company or product suite) can be grouped.
# The default value is: Doxygen generated docs.
# This tag requires that the tag GENERATE_DOCSET is set to YES.
DOCSET_FEEDNAME = "Doxygen generated docs"
# This tag determines the URL of the docset feed. A documentation feed provides
# an umbrella under which multiple documentation sets from a single provider
# (such as a company or product suite) can be grouped.
# This tag requires that the tag GENERATE_DOCSET is set to YES.
DOCSET_FEEDURL =
# This tag specifies a string that should uniquely identify the documentation
# set bundle. This should be a reverse domain-name style string, e.g.
# com.mycompany.MyDocSet. Doxygen will append .docset to the name.
# The default value is: org.doxygen.Project.
# This tag requires that the tag GENERATE_DOCSET is set to YES.
DOCSET_BUNDLE_ID = org.doxygen.Project
# The DOCSET_PUBLISHER_ID tag specifies a string that should uniquely identify
# the documentation publisher. This should be a reverse domain-name style
# string, e.g. com.mycompany.MyDocSet.documentation.
# The default value is: org.doxygen.Publisher.
# This tag requires that the tag GENERATE_DOCSET is set to YES.
DOCSET_PUBLISHER_ID = org.doxygen.Publisher
# The DOCSET_PUBLISHER_NAME tag identifies the documentation publisher.
# The default value is: Publisher.
# This tag requires that the tag GENERATE_DOCSET is set to YES.
DOCSET_PUBLISHER_NAME = Publisher
# If the GENERATE_HTMLHELP tag is set to YES then doxygen generates three
# additional HTML index files: index.hhp, index.hhc, and index.hhk. The
# index.hhp is a project file that can be read by Microsoft's HTML Help Workshop
# on Windows. In the beginning of 2021 Microsoft took the original page, with
# a.o. the download links, offline the HTML help workshop was already many years
# in maintenance mode). You can download the HTML help workshop from the web
# archives at Installation executable (see:
# http://web.archive.org/web/20160201063255/http://download.microsoft.com/downlo
# ad/0/A/9/0A939EF6-E31C-430F-A3DF-DFAE7960D564/htmlhelp.exe).
#
# The HTML Help Workshop contains a compiler that can convert all HTML output
# generated by doxygen into a single compiled HTML file (.chm). Compiled HTML
# files are now used as the Windows 98 help format, and will replace the old
# Windows help format (.hlp) on all Windows platforms in the future. Compressed
# HTML files also contain an index, a table of contents, and you can search for
# words in the documentation. The HTML workshop also contains a viewer for
# compressed HTML files.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
GENERATE_HTMLHELP = NO
# The CHM_FILE tag can be used to specify the file name of the resulting .chm
# file. You can add a path in front of the file if the result should not be
# written to the html output directory.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
CHM_FILE =
# The HHC_LOCATION tag can be used to specify the location (absolute path
# including file name) of the HTML help compiler (hhc.exe). If non-empty,
# doxygen will try to run the HTML help compiler on the generated index.hhp.
# The file has to be specified with full path.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
HHC_LOCATION =
# The GENERATE_CHI flag controls if a separate .chi index file is generated
# (YES) or that it should be included in the main .chm file (NO).
# The default value is: NO.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
GENERATE_CHI = NO
# The CHM_INDEX_ENCODING is used to encode HtmlHelp index (hhk), content (hhc)
# and project file content.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
CHM_INDEX_ENCODING =
# The BINARY_TOC flag controls whether a binary table of contents is generated
# (YES) or a normal table of contents (NO) in the .chm file. Furthermore it
# enables the Previous and Next buttons.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
BINARY_TOC = NO
# The TOC_EXPAND flag can be set to YES to add extra items for group members to
# the table of contents of the HTML help documentation and to the tree view.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
TOC_EXPAND = NO
# The SITEMAP_URL tag is used to specify the full URL of the place where the
# generated documentation will be placed on the server by the user during the
# deployment of the documentation. The generated sitemap is called sitemap.xml
# and placed on the directory specified by HTML_OUTPUT. In case no SITEMAP_URL
# is specified no sitemap is generated. For information about the sitemap
# protocol see https://www.sitemaps.org
# This tag requires that the tag GENERATE_HTML is set to YES.
SITEMAP_URL =
# If the GENERATE_QHP tag is set to YES and both QHP_NAMESPACE and
# QHP_VIRTUAL_FOLDER are set, an additional index file will be generated that
# can be used as input for Qt's qhelpgenerator to generate a Qt Compressed Help
# (.qch) of the generated HTML documentation.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
GENERATE_QHP = NO
# If the QHG_LOCATION tag is specified, the QCH_FILE tag can be used to specify
# the file name of the resulting .qch file. The path specified is relative to
# the HTML output folder.
# This tag requires that the tag GENERATE_QHP is set to YES.
QCH_FILE =
# The QHP_NAMESPACE tag specifies the namespace to use when generating Qt Help
# Project output. For more information please see Qt Help Project / Namespace
# (see:
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#namespace).
# The default value is: org.doxygen.Project.
# This tag requires that the tag GENERATE_QHP is set to YES.
QHP_NAMESPACE = org.doxygen.Project
# The QHP_VIRTUAL_FOLDER tag specifies the namespace to use when generating Qt
# Help Project output. For more information please see Qt Help Project / Virtual
# Folders (see:
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#virtual-folders).
# The default value is: doc.
# This tag requires that the tag GENERATE_QHP is set to YES.
QHP_VIRTUAL_FOLDER = doc
# If the QHP_CUST_FILTER_NAME tag is set, it specifies the name of a custom
# filter to add. For more information please see Qt Help Project / Custom
# Filters (see:
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-filters).
# This tag requires that the tag GENERATE_QHP is set to YES.
QHP_CUST_FILTER_NAME =
# The QHP_CUST_FILTER_ATTRS tag specifies the list of the attributes of the
# custom filter to add. For more information please see Qt Help Project / Custom
# Filters (see:
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-filters).
# This tag requires that the tag GENERATE_QHP is set to YES.
QHP_CUST_FILTER_ATTRS =
# The QHP_SECT_FILTER_ATTRS tag specifies the list of the attributes this
# project's filter section matches. Qt Help Project / Filter Attributes (see:
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#filter-attributes).
# This tag requires that the tag GENERATE_QHP is set to YES.
QHP_SECT_FILTER_ATTRS =
# The QHG_LOCATION tag can be used to specify the location (absolute path
# including file name) of Qt's qhelpgenerator. If non-empty doxygen will try to
# run qhelpgenerator on the generated .qhp file.
# This tag requires that the tag GENERATE_QHP is set to YES.
QHG_LOCATION =
# If the GENERATE_ECLIPSEHELP tag is set to YES, additional index files will be
# generated, together with the HTML files, they form an Eclipse help plugin. To
# install this plugin and make it available under the help contents menu in
# Eclipse, the contents of the directory containing the HTML and XML files needs
# to be copied into the plugins directory of eclipse. The name of the directory
# within the plugins directory should be the same as the ECLIPSE_DOC_ID value.
# After copying Eclipse needs to be restarted before the help appears.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
GENERATE_ECLIPSEHELP = NO
# A unique identifier for the Eclipse help plugin. When installing the plugin
# the directory name containing the HTML and XML files should also have this
# name. Each documentation set should have its own identifier.
# The default value is: org.doxygen.Project.
# This tag requires that the tag GENERATE_ECLIPSEHELP is set to YES.
ECLIPSE_DOC_ID = org.doxygen.Project
# If you want full control over the layout of the generated HTML pages it might
# be necessary to disable the index and replace it with your own. The
# DISABLE_INDEX tag can be used to turn on/off the condensed index (tabs) at top
# of each HTML page. A value of NO enables the index and the value YES disables
# it. Since the tabs in the index contain the same information as the navigation
# tree, you can set this option to YES if you also set GENERATE_TREEVIEW to YES.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
DISABLE_INDEX = NO
# The GENERATE_TREEVIEW tag is used to specify whether a tree-like index
# structure should be generated to display hierarchical information. If the tag
# value is set to YES, a side panel will be generated containing a tree-like
# index structure (just like the one that is generated for HTML Help). For this
# to work a browser that supports JavaScript, DHTML, CSS and frames is required
# (i.e. any modern browser). Windows users are probably better off using the
# HTML help feature. Via custom style sheets (see HTML_EXTRA_STYLESHEET) one can
# further fine tune the look of the index (see "Fine-tuning the output"). As an
# example, the default style sheet generated by doxygen has an example that
# shows how to put an image at the root of the tree instead of the PROJECT_NAME.
# Since the tree basically has the same information as the tab index, you could
# consider setting DISABLE_INDEX to YES when enabling this option.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
GENERATE_TREEVIEW = NO
# When both GENERATE_TREEVIEW and DISABLE_INDEX are set to YES, then the
# FULL_SIDEBAR option determines if the side bar is limited to only the treeview
# area (value NO) or if it should extend to the full height of the window (value
# YES). Setting this to YES gives a layout similar to
# https://docs.readthedocs.io with more room for contents, but less room for the
# project logo, title, and description. If either GENERATE_TREEVIEW or
# DISABLE_INDEX is set to NO, this option has no effect.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
FULL_SIDEBAR = NO
# The ENUM_VALUES_PER_LINE tag can be used to set the number of enum values that
# doxygen will group on one line in the generated HTML documentation.
#
# Note that a value of 0 will completely suppress the enum values from appearing
# in the overview section.
# Minimum value: 0, maximum value: 20, default value: 4.
# This tag requires that the tag GENERATE_HTML is set to YES.
ENUM_VALUES_PER_LINE = 4
# If the treeview is enabled (see GENERATE_TREEVIEW) then this tag can be used
# to set the initial width (in pixels) of the frame in which the tree is shown.
# Minimum value: 0, maximum value: 1500, default value: 250.
# This tag requires that the tag GENERATE_HTML is set to YES.
TREEVIEW_WIDTH = 250
# If the EXT_LINKS_IN_WINDOW option is set to YES, doxygen will open links to
# external symbols imported via tag files in a separate window.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
EXT_LINKS_IN_WINDOW = NO
# If the OBFUSCATE_EMAILS tag is set to YES, doxygen will obfuscate email
# addresses.
# The default value is: YES.
# This tag requires that the tag GENERATE_HTML is set to YES.
OBFUSCATE_EMAILS = YES
# If the HTML_FORMULA_FORMAT option is set to svg, doxygen will use the pdf2svg
# tool (see https://github.com/dawbarton/pdf2svg) or inkscape (see
# https://inkscape.org) to generate formulas as SVG images instead of PNGs for
# the HTML output. These images will generally look nicer at scaled resolutions.
# Possible values are: png (the default) and svg (looks nicer but requires the
# pdf2svg or inkscape tool).
# The default value is: png.
# This tag requires that the tag GENERATE_HTML is set to YES.
HTML_FORMULA_FORMAT = png
# Use this tag to change the font size of LaTeX formulas included as images in
# the HTML documentation. When you change the font size after a successful
# doxygen run you need to manually remove any form_*.png images from the HTML
# output directory to force them to be regenerated.
# Minimum value: 8, maximum value: 50, default value: 10.
# This tag requires that the tag GENERATE_HTML is set to YES.
FORMULA_FONTSIZE = 10
# The FORMULA_MACROFILE can contain LaTeX \newcommand and \renewcommand commands
# to create new LaTeX commands to be used in formulas as building blocks. See
# the section "Including formulas" for details.
FORMULA_MACROFILE =
# Enable the USE_MATHJAX option to render LaTeX formulas using MathJax (see
# https://www.mathjax.org) which uses client side JavaScript for the rendering
# instead of using pre-rendered bitmaps. Use this if you do not have LaTeX
# installed or if you want to formulas look prettier in the HTML output. When
# enabled you may also need to install MathJax separately and configure the path
# to it using the MATHJAX_RELPATH option.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
USE_MATHJAX = NO
# With MATHJAX_VERSION it is possible to specify the MathJax version to be used.
# Note that the different versions of MathJax have different requirements with
# regards to the different settings, so it is possible that also other MathJax
# settings have to be changed when switching between the different MathJax
# versions.
# Possible values are: MathJax_2 and MathJax_3.
# The default value is: MathJax_2.
# This tag requires that the tag USE_MATHJAX is set to YES.
MATHJAX_VERSION = MathJax_2
# When MathJax is enabled you can set the default output format to be used for
# the MathJax output. For more details about the output format see MathJax
# version 2 (see:
# http://docs.mathjax.org/en/v2.7-latest/output.html) and MathJax version 3
# (see:
# http://docs.mathjax.org/en/latest/web/components/output.html).
# Possible values are: HTML-CSS (which is slower, but has the best
# compatibility. This is the name for Mathjax version 2, for MathJax version 3
# this will be translated into chtml), NativeMML (i.e. MathML. Only supported
# for NathJax 2. For MathJax version 3 chtml will be used instead.), chtml (This
# is the name for Mathjax version 3, for MathJax version 2 this will be
# translated into HTML-CSS) and SVG.
# The default value is: HTML-CSS.
# This tag requires that the tag USE_MATHJAX is set to YES.
MATHJAX_FORMAT = HTML-CSS
# When MathJax is enabled you need to specify the location relative to the HTML
# output directory using the MATHJAX_RELPATH option. The destination directory
# should contain the MathJax.js script. For instance, if the mathjax directory
# is located at the same level as the HTML output directory, then
# MATHJAX_RELPATH should be ../mathjax. The default value points to the MathJax
# Content Delivery Network so you can quickly see the result without installing
# MathJax. However, it is strongly recommended to install a local copy of
# MathJax from https://www.mathjax.org before deployment. The default value is:
# - in case of MathJax version 2: https://cdn.jsdelivr.net/npm/mathjax@2
# - in case of MathJax version 3: https://cdn.jsdelivr.net/npm/mathjax@3
# This tag requires that the tag USE_MATHJAX is set to YES.
MATHJAX_RELPATH = http://cdn.mathjax.org/mathjax/latest
# The MATHJAX_EXTENSIONS tag can be used to specify one or more MathJax
# extension names that should be enabled during MathJax rendering. For example
# for MathJax version 2 (see
# https://docs.mathjax.org/en/v2.7-latest/tex.html#tex-and-latex-extensions):
# MATHJAX_EXTENSIONS = TeX/AMSmath TeX/AMSsymbols
# For example for MathJax version 3 (see
# http://docs.mathjax.org/en/latest/input/tex/extensions/index.html):
# MATHJAX_EXTENSIONS = ams
# This tag requires that the tag USE_MATHJAX is set to YES.
MATHJAX_EXTENSIONS =
# The MATHJAX_CODEFILE tag can be used to specify a file with javascript pieces
# of code that will be used on startup of the MathJax code. See the MathJax site
# (see:
# http://docs.mathjax.org/en/v2.7-latest/output.html) for more details. For an
# example see the documentation.
# This tag requires that the tag USE_MATHJAX is set to YES.
MATHJAX_CODEFILE =
# When the SEARCHENGINE tag is enabled doxygen will generate a search box for
# the HTML output. The underlying search engine uses javascript and DHTML and
# should work on any modern browser. Note that when using HTML help
# (GENERATE_HTMLHELP), Qt help (GENERATE_QHP), or docsets (GENERATE_DOCSET)
# there is already a search function so this one should typically be disabled.
# For large projects the javascript based search engine can be slow, then
# enabling SERVER_BASED_SEARCH may provide a better solution. It is possible to
# search using the keyboard; to jump to the search box use + S
# (what the is depends on the OS and browser, but it is typically
# , /