pax_global_header�����������������������������������������������������������������������������������0000666�0000000�0000000�00000000064�14470675724�0014532�g����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������52 comment=7b3692c79555e981e3cdc6da1fdfabf5e7b0a4ea
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/�������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0014402�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/.github/�����������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0015742�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/.github/workflows/�������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0017777�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/.github/workflows/release.yml��������������������������������������������������0000664�0000000�0000000�00000001372�14470675724�0022145�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������name: Release Package
on:
push:
tags: ["release-*"]
permissions:
contents: read
jobs:
build_package:
name: Build Package
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build sdist and wheel
run: pipx run build --sdist --wheel
- uses: actions/upload-artifact@v3
with:
path: dist
pypi-publish:
needs: [build_package]
name: Upload release to PyPI
runs-on: ubuntu-latest
environment:
name: pypi
permissions:
id-token: write
steps:
- uses: actions/download-artifact@v3
with:
name: artifact
path: dist
- name: Publish package distributions to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/.gitignore���������������������������������������������������������������������0000664�0000000�0000000�00000000007�14470675724�0016367�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/venv/
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/.travis.yml��������������������������������������������������������������������0000664�0000000�0000000�00000000327�14470675724�0016515�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������language: python
sudo: required
dist: xenial
python:
- "3.4"
- "3.5"
- "3.6"
- "3.7"
- "3.8"
- "3.9"
- "nightly"
script:
- pip install -r requirements-dev.txt
- ./test.sh python
git:
depth: false���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/ChangeLog����������������������������������������������������������������������0000664�0000000�0000000�00000006351�14470675724�0016161�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������2.0.7
Add --show-no-spaces #173
2.0.6
Fix process exit code for non-file inputs #205
Make fullwidth characters take two columns #202
Add -x/--exclude optin to to exclude files matching patterns #199
2.0.5
Set process exit code to indicate differences #195
Support -P/--permissions option #197
2.0.4
Include LICENSE in package
2.0.3
Attempts to publisher 2.0.1 and 2.0.2 to pypi gave broken packages
2.0.1
Add -t/--truncate option #184
2.0.0
Drop support for Python 2
Clearer error on unknown encodings #145
Stop printing an error on closed pipes #156
Fix displayed filed names with git #159
Fix testcase that assumed a git repo #166
Implement --report-identical-files #168
Improved handling of very long lines #180
1.9.4
Allow {path} and {basename} in --label #139
Properly implement git difftool protocol #140
1.9.3
Properly set the version number
1.9.2
Add --exclude-lines (-E) which can exclude comments
Add --color-map so you can choose which colors to use for what #121 #117
Allow highlighted characters to be bold #122
Support configuring git-icdiff with gitconfig
Don't choke on bad terminal sizes #113
Print proper error messages instead of raising exceptions
Allow the line numbers to be colorized
Add a LICENSE file
1.9.1
Handle files with CR characters better and add --strip-trailing-cr
1.9.0
Fix setup.py by symlinking icdiff to icdiff.py
1.8.2
Add short flags for --highlight (-H), --line-numbers (-N), and --whole-file (-W).
Fix use with bash process substitution and other special files
1.8.1
Updated remaining copy of unicode test file (b/1)
1.8.0
Updated unicode test file (input-3)
Allow testing installed version
Allow importing as a module
Minor deduplication tweak to git-icdiff
Add pip instructions to readme
Allow using --tabsize
Allow non-recursive directory diffing
1.7.6
Fixed copyright.
1.7.3
Fix git-icdiff to handle filenames with spaces as arguments.
1.7.2
Don't stop diffing recursively when encountering a binary file.
1.7.1
Don't treat files with identical (mode, size, mtime) as equal.
1.7.0
Add tests
1.6.4
Unbreak --recursive again
1.6.3
Stop setting LESS_IS_MORE with git-icdiff, fixing #33.
1.6.2
Add support for setting the output encoding and default to utf8
1.6.1
Unbreak --recursive
1.6.0
Add support for setting the encoding, and handle fullwidth chars
in python2
1.5.3
Support use as an svn difftool.
Support -U and -L, and allow but ignore -u.
1.5.2
Various pager improvements in git-icdiff.
1.5.1
Make --highlight and --no-bold play nice.
1.5.0
Pass arguments through to icdiff when using git-icdiff.
1.4.0
Use less with "git icdiff" by default.
1.3.2
Fix linewrapping with unicode.
1.3.1
1.3.0 was completely borked.
1.3.0
Use setup.py to support standard python installation.
1.2.2
Start printing output as soon as its ready instead of waiting for
the whole file to complete.
1.2.1
Space fullwidth characters properly when treating input as unicode.
1.2.0
Add --recursive to support diffing directory trees.
1.1.2
Flush stdout when done.
1.1.1
Don't print stack traces on Ctrl+C or when piping into something
that quits.
1.1.0
Add --no-bold option useful with the solarized colorscheme and for
people who just don't like bold.
1.0.0
First Release
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/LICENSE������������������������������������������������������������������������0000664�0000000�0000000�00000030733�14470675724�0015415�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������A. HISTORY OF THE SOFTWARE
==========================
Python was created in the early 1990s by Guido van Rossum at Stichting
Mathematisch Centrum (CWI, see http://www.cwi.nl) in the Netherlands
as a successor of a language called ABC. Guido remains Python's
principal author, although it includes many contributions from others.
In 1995, Guido continued his work on Python at the Corporation for
National Research Initiatives (CNRI, see http://www.cnri.reston.va.us)
in Reston, Virginia where he released several versions of the
software.
In May 2000, Guido and the Python core development team moved to
BeOpen.com to form the BeOpen PythonLabs team. In October of the same
year, the PythonLabs team moved to Digital Creations, which became
Zope Corporation. In 2001, the Python Software Foundation (PSF, see
https://www.python.org/psf/) was formed, a non-profit organization
created specifically to own Python-related Intellectual Property.
Zope Corporation was a sponsoring member of the PSF.
All Python releases are Open Source (see http://www.opensource.org for
the Open Source Definition). Historically, most, but not all, Python
releases have also been GPL-compatible; the table below summarizes
the various releases.
Release Derived Year Owner GPL-
from compatible? (1)
0.9.0 thru 1.2 1991-1995 CWI yes
1.3 thru 1.5.2 1.2 1995-1999 CNRI yes
1.6 1.5.2 2000 CNRI no
2.0 1.6 2000 BeOpen.com no
1.6.1 1.6 2001 CNRI yes (2)
2.1 2.0+1.6.1 2001 PSF no
2.0.1 2.0+1.6.1 2001 PSF yes
2.1.1 2.1+2.0.1 2001 PSF yes
2.1.2 2.1.1 2002 PSF yes
2.1.3 2.1.2 2002 PSF yes
2.2 and above 2.1.1 2001-now PSF yes
Footnotes:
(1) GPL-compatible doesn't mean that we're distributing Python under
the GPL. All Python licenses, unlike the GPL, let you distribute
a modified version without making your changes open source. The
GPL-compatible licenses make it possible to combine Python with
other software that is released under the GPL; the others don't.
(2) According to Richard Stallman, 1.6.1 is not GPL-compatible,
because its license has a choice of law clause. According to
CNRI, however, Stallman's lawyer has told CNRI's lawyer that 1.6.1
is "not incompatible" with the GPL.
Thanks to the many outside volunteers who have worked under Guido's
direction to make these releases possible.
B. TERMS AND CONDITIONS FOR ACCESSING OR OTHERWISE USING PYTHON
===============================================================
PYTHON SOFTWARE FOUNDATION LICENSE VERSION 2
--------------------------------------------
1. This LICENSE AGREEMENT is between the Python Software Foundation
("PSF"), and the Individual or Organization ("Licensee") accessing and
otherwise using this software ("Python") in source or binary form and
its associated documentation.
2. Subject to the terms and conditions of this License Agreement, PSF hereby
grants Licensee a nonexclusive, royalty-free, world-wide license to reproduce,
analyze, test, perform and/or display publicly, prepare derivative works,
distribute, and otherwise use Python alone or in any derivative version,
provided, however, that PSF's License Agreement and PSF's notice of copyright,
i.e., "Copyright (c) 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010,
2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018 Python Software Foundation; All
Rights Reserved" are retained in Python alone or in any derivative version
prepared by Licensee.
3. In the event Licensee prepares a derivative work that is based on
or incorporates Python or any part thereof, and wants to make
the derivative work available to others as provided herein, then
Licensee hereby agrees to include in any such work a brief summary of
the changes made to Python.
4. PSF is making Python available to Licensee on an "AS IS"
basis. PSF MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR
IMPLIED. BY WAY OF EXAMPLE, BUT NOT LIMITATION, PSF MAKES NO AND
DISCLAIMS ANY REPRESENTATION OR WARRANTY OF MERCHANTABILITY OR FITNESS
FOR ANY PARTICULAR PURPOSE OR THAT THE USE OF PYTHON WILL NOT
INFRINGE ANY THIRD PARTY RIGHTS.
5. PSF SHALL NOT BE LIABLE TO LICENSEE OR ANY OTHER USERS OF PYTHON
FOR ANY INCIDENTAL, SPECIAL, OR CONSEQUENTIAL DAMAGES OR LOSS AS
A RESULT OF MODIFYING, DISTRIBUTING, OR OTHERWISE USING PYTHON,
OR ANY DERIVATIVE THEREOF, EVEN IF ADVISED OF THE POSSIBILITY THEREOF.
6. This License Agreement will automatically terminate upon a material
breach of its terms and conditions.
7. Nothing in this License Agreement shall be deemed to create any
relationship of agency, partnership, or joint venture between PSF and
Licensee. This License Agreement does not grant permission to use PSF
trademarks or trade name in a trademark sense to endorse or promote
products or services of Licensee, or any third party.
8. By copying, installing or otherwise using Python, Licensee
agrees to be bound by the terms and conditions of this License
Agreement.
BEOPEN.COM LICENSE AGREEMENT FOR PYTHON 2.0
-------------------------------------------
BEOPEN PYTHON OPEN SOURCE LICENSE AGREEMENT VERSION 1
1. This LICENSE AGREEMENT is between BeOpen.com ("BeOpen"), having an
office at 160 Saratoga Avenue, Santa Clara, CA 95051, and the
Individual or Organization ("Licensee") accessing and otherwise using
this software in source or binary form and its associated
documentation ("the Software").
2. Subject to the terms and conditions of this BeOpen Python License
Agreement, BeOpen hereby grants Licensee a non-exclusive,
royalty-free, world-wide license to reproduce, analyze, test, perform
and/or display publicly, prepare derivative works, distribute, and
otherwise use the Software alone or in any derivative version,
provided, however, that the BeOpen Python License is retained in the
Software, alone or in any derivative version prepared by Licensee.
3. BeOpen is making the Software available to Licensee on an "AS IS"
basis. BEOPEN MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR
IMPLIED. BY WAY OF EXAMPLE, BUT NOT LIMITATION, BEOPEN MAKES NO AND
DISCLAIMS ANY REPRESENTATION OR WARRANTY OF MERCHANTABILITY OR FITNESS
FOR ANY PARTICULAR PURPOSE OR THAT THE USE OF THE SOFTWARE WILL NOT
INFRINGE ANY THIRD PARTY RIGHTS.
4. BEOPEN SHALL NOT BE LIABLE TO LICENSEE OR ANY OTHER USERS OF THE
SOFTWARE FOR ANY INCIDENTAL, SPECIAL, OR CONSEQUENTIAL DAMAGES OR LOSS
AS A RESULT OF USING, MODIFYING OR DISTRIBUTING THE SOFTWARE, OR ANY
DERIVATIVE THEREOF, EVEN IF ADVISED OF THE POSSIBILITY THEREOF.
5. This License Agreement will automatically terminate upon a material
breach of its terms and conditions.
6. This License Agreement shall be governed by and interpreted in all
respects by the law of the State of California, excluding conflict of
law provisions. Nothing in this License Agreement shall be deemed to
create any relationship of agency, partnership, or joint venture
between BeOpen and Licensee. This License Agreement does not grant
permission to use BeOpen trademarks or trade names in a trademark
sense to endorse or promote products or services of Licensee, or any
third party. As an exception, the "BeOpen Python" logos available at
http://www.pythonlabs.com/logos.html may be used according to the
permissions granted on that web page.
7. By copying, installing or otherwise using the software, Licensee
agrees to be bound by the terms and conditions of this License
Agreement.
CNRI LICENSE AGREEMENT FOR PYTHON 1.6.1
---------------------------------------
1. This LICENSE AGREEMENT is between the Corporation for National
Research Initiatives, having an office at 1895 Preston White Drive,
Reston, VA 20191 ("CNRI"), and the Individual or Organization
("Licensee") accessing and otherwise using Python 1.6.1 software in
source or binary form and its associated documentation.
2. Subject to the terms and conditions of this License Agreement, CNRI
hereby grants Licensee a nonexclusive, royalty-free, world-wide
license to reproduce, analyze, test, perform and/or display publicly,
prepare derivative works, distribute, and otherwise use Python 1.6.1
alone or in any derivative version, provided, however, that CNRI's
License Agreement and CNRI's notice of copyright, i.e., "Copyright (c)
1995-2001 Corporation for National Research Initiatives; All Rights
Reserved" are retained in Python 1.6.1 alone or in any derivative
version prepared by Licensee. Alternately, in lieu of CNRI's License
Agreement, Licensee may substitute the following text (omitting the
quotes): "Python 1.6.1 is made available subject to the terms and
conditions in CNRI's License Agreement. This Agreement together with
Python 1.6.1 may be located on the Internet using the following
unique, persistent identifier (known as a handle): 1895.22/1013. This
Agreement may also be obtained from a proxy server on the Internet
using the following URL: http://hdl.handle.net/1895.22/1013".
3. In the event Licensee prepares a derivative work that is based on
or incorporates Python 1.6.1 or any part thereof, and wants to make
the derivative work available to others as provided herein, then
Licensee hereby agrees to include in any such work a brief summary of
the changes made to Python 1.6.1.
4. CNRI is making Python 1.6.1 available to Licensee on an "AS IS"
basis. CNRI MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR
IMPLIED. BY WAY OF EXAMPLE, BUT NOT LIMITATION, CNRI MAKES NO AND
DISCLAIMS ANY REPRESENTATION OR WARRANTY OF MERCHANTABILITY OR FITNESS
FOR ANY PARTICULAR PURPOSE OR THAT THE USE OF PYTHON 1.6.1 WILL NOT
INFRINGE ANY THIRD PARTY RIGHTS.
5. CNRI SHALL NOT BE LIABLE TO LICENSEE OR ANY OTHER USERS OF PYTHON
1.6.1 FOR ANY INCIDENTAL, SPECIAL, OR CONSEQUENTIAL DAMAGES OR LOSS AS
A RESULT OF MODIFYING, DISTRIBUTING, OR OTHERWISE USING PYTHON 1.6.1,
OR ANY DERIVATIVE THEREOF, EVEN IF ADVISED OF THE POSSIBILITY THEREOF.
6. This License Agreement will automatically terminate upon a material
breach of its terms and conditions.
7. This License Agreement shall be governed by the federal
intellectual property law of the United States, including without
limitation the federal copyright law, and, to the extent such
U.S. federal law does not apply, by the law of the Commonwealth of
Virginia, excluding Virginia's conflict of law provisions.
Notwithstanding the foregoing, with regard to derivative works based
on Python 1.6.1 that incorporate non-separable material that was
previously distributed under the GNU General Public License (GPL), the
law of the Commonwealth of Virginia shall govern this License
Agreement only as to issues arising under or with respect to
Paragraphs 4, 5, and 7 of this License Agreement. Nothing in this
License Agreement shall be deemed to create any relationship of
agency, partnership, or joint venture between CNRI and Licensee. This
License Agreement does not grant permission to use CNRI trademarks or
trade name in a trademark sense to endorse or promote products or
services of Licensee, or any third party.
8. By clicking on the "ACCEPT" button where indicated, or by copying,
installing or otherwise using Python 1.6.1, Licensee agrees to be
bound by the terms and conditions of this License Agreement.
ACCEPT
CWI LICENSE AGREEMENT FOR PYTHON 0.9.0 THROUGH 1.2
--------------------------------------------------
Copyright (c) 1991 - 1995, Stichting Mathematisch Centrum Amsterdam,
The Netherlands. All rights reserved.
Permission to use, copy, modify, and distribute this software and its
documentation for any purpose and without fee is hereby granted,
provided that the above copyright notice appear in all copies and that
both that copyright notice and this permission notice appear in
supporting documentation, and that the name of Stichting Mathematisch
Centrum or CWI not be used in advertising or publicity pertaining to
distribution of the software without specific, written prior
permission.
STICHTING MATHEMATISCH CENTRUM DISCLAIMS ALL WARRANTIES WITH REGARD TO
THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND
FITNESS, IN NO EVENT SHALL STICHTING MATHEMATISCH CENTRUM BE LIABLE
FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT
OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
�������������������������������������icdiff-release-2.0.7/MANIFEST.in��������������������������������������������������������������������0000664�0000000�0000000�00000000042�14470675724�0016134�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include README.md
include LICENSE
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/README.md����������������������������������������������������������������������0000664�0000000�0000000�00000011223�14470675724�0015660�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Icdiff
Improved colored diff
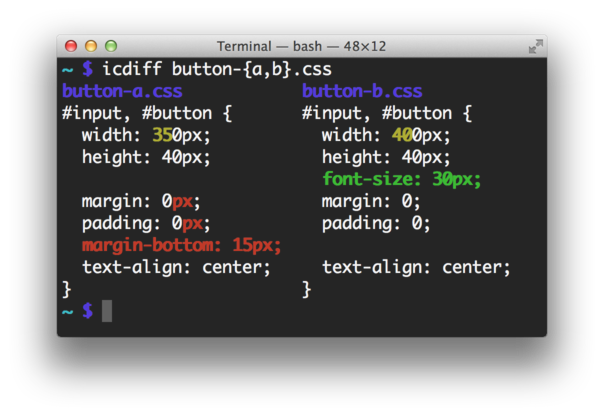
## Installation
Download the [latest](https://github.com/jeffkaufman/icdiff/tags) `icdiff` and put it on your PATH.
Alternatively, install with packaging tools:
```
# pip
pip install icdiff
# apt
sudo apt install icdiff
# homebrew
brew install icdiff
# aur
yay -S icdiff
# nix
nix-env -i icdiff
```
## Usage
```sh
icdiff [options] left_file right_file
```
Show differences between files in a two column view.
### Options
```
--version show program's version number and exit
-h, --help show this help message and exit
--cols=COLS specify the width of the screen. Autodetection is Unix
only
--encoding=ENCODING specify the file encoding; defaults to utf8
-E MATCHER, --exclude-lines=MATCHER
Do not diff lines that match this regex. Not
compatible with the 'line-numbers' option
--head=HEAD consider only the first N lines of each file
-H, --highlight color by changing the background color instead of the
foreground color. Very fast, ugly, displays all
changes
-L LABELS, --label=LABELS
override file labels with arbitrary tags. Use twice,
one for each file
-N, --line-numbers generate output with line numbers. Not compatible with
the 'exclude-lines' option.
--no-bold use non-bold colors; recommended for solarized
--no-headers don't label the left and right sides with their file
names
--output-encoding=OUTPUT_ENCODING
specify the output encoding; defaults to utf8
-r, --recursive recursively compare subdirectories
-s, --report-identical-files
report when two files are the same
--show-all-spaces color all non-matching whitespace including that which
is not needed for drawing the eye to changes. Slow,
ugly, displays all changes
--tabsize=TABSIZE tab stop spacing
-t, --truncate truncate long lines instead of wrapping them
-u, --patch generate patch. This is always true, and only exists
for compatibility
-U NUM, --unified=NUM, --numlines=NUM
how many lines of context to print; can't be combined
with --whole-file
-W, --whole-file show the whole file instead of just changed lines and
context
--strip-trailing-cr strip any trailing carriage return at the end of an
input line
--color-map=COLOR_MAP
choose which colors are used for which items. Default
is --color-map='add:green_bold,change:yellow_bold,desc
ription:blue,meta:magenta,separator:blue,subtract:red_
bold'. You don't have to override all of them:
'--color-map=separator:white,description:cyan
```
## Using with Git
To see what it looks like, try:
```sh
git difftool --extcmd icdiff
```
To install this as a tool you can use with Git, copy
`git-icdiff` into your PATH and run:
```sh
git icdiff
```
You can configure `git-icdiff` in Git's config:
```
git config --global icdiff.options '--highlight --line-numbers'
```
## Using with subversion
To try it out, run:
```sh
svn diff --diff-cmd icdiff
```
## Using with Mercurial
Add the following to your `~/.hgrc`:
```sh
[extensions]
extdiff=
[extdiff]
cmd.icdiff=icdiff
opts.icdiff=--recursive --line-numbers
```
Or check more [in-depth setup instructions](https://ianobermiller.com/blog/2016/07/14/side-by-side-diffs-for-mercurial-hg-icdiff-revisited/).
## Setting up a dev environment
Create a virtualenv and install the dev dependencies.
This is not needed for normal usage.
```sh
virtualenv venv
source venv/bin/activate
pip install -r requirements-dev.txt
```
## Running tests
```sh
./test.sh python3
```
## Making a release
- Update ChangeLog with all the changes since the last release
- Update `__version__` in `icdiff`
- Run tests, make sure they pass
- `git commit -a -m "release ${version}"`
- `git push`
- `git tag release-${version}`
- `git push origin release-${version}`
- A GitHub Action should be triggered due to the release tag being pushed, and will upload to PyPI.
## License
This file is derived from `difflib.HtmlDiff` which is under [license](https://www.python.org/download/releases/2.6.2/license/).
I release my changes here under the same license. This is GPL compatible.
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/git-icdiff���������������������������������������������������������������������0000775�0000000�0000000�00000000722�14470675724�0016336�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/bin/sh
ICDIFF_OPTIONS=$(git config --get icdiff.options)
ICDIFF_OPTIONS="${ICDIFF_OPTIONS} --is-git-diff"
GITPAGER=$(git config --get icdiff.pager)
if [ -z "$GITPAGER" ]; then
GITPAGER=$(git config --get core.pager)
fi
if [ -z "$GITPAGER" ]; then
GITPAGER="${PAGER:-less}"
fi
if [ "${GITPAGER%% *}" = "more" ] || [ "${GITPAGER%% *}" = "less" ]; then
GITPAGER="$GITPAGER -R"
fi
git difftool --no-prompt --extcmd="icdiff $ICDIFF_OPTIONS" "$@" | $GITPAGER
����������������������������������������������icdiff-release-2.0.7/icdiff�������������������������������������������������������������������������0000775�0000000�0000000�00000076446�14470675724�0015575�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
""" icdiff.py
Author: Jeff Kaufman, derived from difflib.HtmlDiff
License: This code is usable under the same open terms as the rest of
python. See: http://www.python.org/psf/license/
Copyright (c) 2001, 2002, 2003, 2004, 2005, 2006 Python Software Foundation;
All Rights Reserved
Based on Python's difflib.HtmlDiff,
with changes to provide console output instead of html output. """
import os
import stat
import sys
import errno
import difflib
from optparse import Option, OptionParser
import re
import filecmp
import unicodedata
import codecs
import fnmatch
__version__ = "2.0.7"
# Exit code constants
EXIT_CODE_SUCCESS = 0
EXIT_CODE_DIFF = 1
EXIT_CODE_ERROR = 2
color_codes = {
"black": "\033[0;30m",
"red": "\033[0;31m",
"green": "\033[0;32m",
"yellow": "\033[0;33m",
"blue": "\033[0;34m",
"magenta": "\033[0;35m",
"cyan": "\033[0;36m",
"white": "\033[0;37m",
"none": "\033[m",
"black_bold": "\033[1;30m",
"red_bold": "\033[1;31m",
"green_bold": "\033[1;32m",
"yellow_bold": "\033[1;33m",
"blue_bold": "\033[1;34m",
"magenta_bold": "\033[1;35m",
"cyan_bold": "\033[1;36m",
"white_bold": "\033[1;37m",
}
color_mapping = {
"add": "green_bold",
"subtract": "red_bold",
"change": "yellow_bold",
"separator": "blue",
"description": "blue",
"permissions": "yellow",
"meta": "magenta",
"line-numbers": "white",
}
class ConsoleDiff(object):
"""Console colored side by side comparison with change highlights.
Based on difflib.HtmlDiff
This class can be used to create a text-mode table showing a side
by side, line by line comparison of text with inter-line and
intra-line change highlights in ansi color escape sequences as
intra-line change highlights in ansi color escape sequences as
read by xterm. The table can be generated in either full or
contextual difference mode.
To generate the table, call make_table.
Usage is the almost the same as HtmlDiff except only make_table is
implemented and the file can be invoked on the command line.
Run::
python icdiff.py --help
for command line usage information.
"""
def __init__(
self,
tabsize=8,
wrapcolumn=None,
linejunk=None,
charjunk=difflib.IS_CHARACTER_JUNK,
cols=80,
line_numbers=False,
show_all_spaces=False,
show_no_spaces=False,
highlight=False,
truncate=False,
strip_trailing_cr=False,
):
"""ConsoleDiff instance initializer
Arguments:
tabsize -- tab stop spacing, defaults to 8.
wrapcolumn -- column number where lines are broken and wrapped,
defaults to None where lines are not wrapped.
linejunk, charjunk -- keyword arguments passed into ndiff() (used by
ConsoleDiff() to generate the side by side differences). See
ndiff() documentation for argument default values and descriptions.
"""
self._tabsize = tabsize
self.line_numbers = line_numbers
self.cols = cols
self.show_all_spaces = show_all_spaces
self.show_no_spaces = show_no_spaces
self.highlight = highlight
self.strip_trailing_cr = strip_trailing_cr
self.truncate = truncate
if wrapcolumn is None:
if not line_numbers:
wrapcolumn = self.cols // 2 - 2
else:
wrapcolumn = self.cols // 2 - 10
self._wrapcolumn = wrapcolumn
self._linejunk = linejunk
self._charjunk = charjunk
def _tab_newline_replace(self, fromlines, tolines):
"""Returns from/to line lists with tabs expanded and newlines removed.
Instead of tab characters being replaced by the number of spaces
needed to fill in to the next tab stop, this function will fill
the space with tab characters. This is done so that the difference
algorithms can identify changes in a file when tabs are replaced by
spaces and vice versa. At the end of the table generation, the tab
characters will be replaced with a space.
"""
def expand_tabs(line):
# hide real spaces
line = line.replace(" ", "\0")
# expand tabs into spaces
line = line.expandtabs(self._tabsize)
# replace spaces from expanded tabs back into tab characters
# (we'll replace them with markup after we do differencing)
line = line.replace(" ", "\t")
return line.replace("\0", " ").rstrip("\n")
fromlines = [expand_tabs(line) for line in fromlines]
tolines = [expand_tabs(line) for line in tolines]
return fromlines, tolines
def _strip_trailing_cr(self, lines):
"""Remove windows return carriage"""
lines = [line.rstrip("\r") for line in lines]
return lines
def _all_cr_nl(self, lines):
"""Whether a file is entirely \r\n line endings"""
return all(line.endswith("\r") for line in lines)
def _display_len(self, s):
# Handle wide characters like Chinese.
def width(c):
if isinstance(c, type("")) and unicodedata.east_asian_width(c) in [
"F",
"W",
]:
return 2
elif c == "\r":
return 2
return 1
return sum(width(c) for c in s)
def _split_line(self, data_list, line_num, text):
"""Builds list of text lines by splitting text lines at wrap point
This function will determine if the input text line needs to be
wrapped (split) into separate lines. If so, the first wrap point
will be determined and the first line appended to the output
text line list. This function is used recursively to handle
the second part of the split line to further split it.
"""
while True:
# if blank line or context separator, just add it to the output
# list
if not line_num:
data_list.append((line_num, text))
return
# if line text doesn't need wrapping, just add it to the output
# list
if (
self._display_len(text) - (text.count("\0") * 3)
<= self._wrapcolumn
):
data_list.append((line_num, text))
return
# scan text looking for the wrap point, keeping track if the wrap
# point is inside markers
i = 0
n = 0
mark = ""
while n < self._wrapcolumn and i < len(text):
if text[i] == "\0":
i += 1
mark = text[i]
i += 1
elif text[i] == "\1":
i += 1
mark = ""
else:
n += self._display_len(text[i])
i += 1
# wrap point is inside text, break it up into separate lines
line1 = text[:i]
line2 = text[i:]
# if wrap point is inside markers, place end marker at end of first
# line and start marker at beginning of second line because each
# line will have its own table tag markup around it.
if mark:
line1 = line1 + "\1"
line2 = "\0" + mark + line2
# tack on first line onto the output list
data_list.append((line_num, line1))
# use this routine again to wrap the remaining text
# unless truncate is set
if self.truncate:
return
line_num = ">"
text = line2
def _line_wrapper(self, diffs):
"""Returns iterator that splits (wraps) mdiff text lines"""
# pull from/to data and flags from mdiff iterator
for fromdata, todata, flag in diffs:
# check for context separators and pass them through
if flag is None:
yield fromdata, todata, flag
continue
(fromline, fromtext), (toline, totext) = fromdata, todata
# for each from/to line split it at the wrap column to form
# list of text lines.
fromlist, tolist = [], []
self._split_line(fromlist, fromline, fromtext)
self._split_line(tolist, toline, totext)
# yield from/to line in pairs inserting blank lines as
# necessary when one side has more wrapped lines
while fromlist or tolist:
if fromlist:
fromdata = fromlist.pop(0)
else:
fromdata = ("", " ")
if tolist:
todata = tolist.pop(0)
else:
todata = ("", " ")
yield fromdata, todata, flag
def _collect_lines(self, diffs):
"""Collects mdiff output into separate lists
Before storing the mdiff from/to data into a list, it is converted
into a single line of text with console markup.
"""
# pull from/to data and flags from mdiff style iterator
for fromdata, todata, flag in diffs:
if (fromdata, todata, flag) == (None, None, None):
yield None
else:
yield (
self._format_line(*fromdata),
self._format_line(*todata),
)
def _format_line(self, linenum, text):
text = text.rstrip()
if not self.line_numbers:
return text
return self._add_line_numbers(linenum, text)
def _add_line_numbers(self, linenum, text):
try:
lid = "%d" % linenum
except TypeError:
# handle blank lines where linenum is '>' or ''
lid = ""
return text
return "%s %s" % (
self._rpad(simple_colorize(str(lid), "line-numbers"), 8),
text,
)
def _real_len(self, s):
s_len = 0
in_esc = False
prev = " "
for c in replace_all(
{"\0+": "", "\0-": "", "\0^": "", "\1": "", "\t": " "}, s
):
if in_esc:
if c == "m":
in_esc = False
else:
if c == "[" and prev == "\033":
in_esc = True
s_len -= 1 # we counted prev when we shouldn't have
else:
s_len += self._display_len(c)
prev = c
return s_len
def _rpad(self, s, field_width):
return self._pad(s, field_width) + s
def _pad(self, s, field_width):
return " " * (field_width - self._real_len(s))
def _lpad(self, s, field_width):
return s + self._pad(s, field_width)
def make_table(
self,
fromlines,
tolines,
fromdesc="",
todesc="",
fromperms=None,
toperms=None,
context=False,
numlines=5,
):
"""Generates table of side by side comparison with change highlights
Arguments:
fromlines -- list of "from" lines
tolines -- list of "to" lines
fromdesc -- "from" file column header string
todesc -- "to" file column header string
fromperms -- "from" file permissions
toperms -- "to" file permissions
context -- set to True for contextual differences (defaults to False
which shows full differences).
numlines -- number of context lines. When context is set True,
controls number of lines displayed before and after the change.
When context is False, controls the number of lines to place
the "next" link anchors before the next change (so click of
"next" link jumps to just before the change).
"""
if context:
context_lines = numlines
else:
context_lines = None
# change tabs to spaces before it gets more difficult after we insert
# markup
fromlines, tolines = self._tab_newline_replace(fromlines, tolines)
if self.strip_trailing_cr or (
self._all_cr_nl(fromlines) and self._all_cr_nl(tolines)
):
fromlines = self._strip_trailing_cr(fromlines)
tolines = self._strip_trailing_cr(tolines)
# create diffs iterator which generates side by side from/to data
diffs = difflib._mdiff(
fromlines,
tolines,
context_lines,
linejunk=self._linejunk,
charjunk=self._charjunk,
)
# set up iterator to wrap lines that exceed desired width
if self._wrapcolumn:
diffs = self._line_wrapper(diffs)
diffs = self._collect_lines(diffs)
for left, right in self._generate_table(
fromdesc, todesc, fromperms, toperms, diffs
):
yield self.colorize(
"%s %s"
% (
self._lpad(left, self.cols // 2 - 1),
self._lpad(right, self.cols // 2 - 1),
)
)
def _generate_table(self, fromdesc, todesc, fromperms, toperms, diffs):
if fromdesc or todesc:
yield (
simple_colorize(fromdesc, "description"),
simple_colorize(todesc, "description"),
)
if fromperms != toperms:
yield (
simple_colorize(
f"{stat.filemode(fromperms)} ({fromperms:o})",
"permissions",
),
simple_colorize(
f"{stat.filemode(toperms)} ({toperms:o})", "permissions"
),
)
for i, line in enumerate(diffs):
if line is None:
# mdiff yields None on separator lines; skip the bogus ones
# generated for the first line
if i > 0:
yield (
simple_colorize("---", "separator"),
simple_colorize("---", "separator"),
)
else:
yield line
def colorize(self, s):
def background(color):
return replace_all(
{"\033[1;": "\033[7;1;", "\033[0;": "\033[7;"}, color
)
C_ADD = color_codes[color_mapping["add"]]
C_SUB = color_codes[color_mapping["subtract"]]
C_CHG = color_codes[color_mapping["change"]]
if self.highlight:
C_ADD, C_SUB, C_CHG = (
background(C_ADD),
background(C_SUB),
background(C_CHG),
)
C_NONE = color_codes["none"]
colors = (C_ADD, C_SUB, C_CHG, C_NONE)
s = replace_all(
{
"\0+": C_ADD,
"\0-": C_SUB,
"\0^": C_CHG,
"\1": C_NONE,
"\t": " ",
"\r": "\\r",
},
s,
)
if self.highlight:
return s
if self.show_no_spaces:
# Don't show whitespace even if it's a whitespace-only line.
return re.sub(
"\033\\[[01];3([01234567])m(\\s+)(\033\\[)",
"\033[0;3\\1m\\2\\3",
s,
)
elif not self.show_all_spaces:
# If there's a change consisting entirely of whitespace,
# don't color it.
return re.sub(
"\033\\[[01];3([01234567])m(\\s+)(\033\\[)",
"\033[7;3\\1m\\2\\3",
s,
)
def will_see_coloredspace(i, s):
while i < len(s) and s[i].isspace():
i += 1
if i < len(s) and s[i] == "\033":
return False
return True
n_s = []
in_color = False
seen_coloredspace = False
for i, c in enumerate(s):
if len(n_s) > 6 and n_s[-1] == "m":
ns_end = "".join(n_s[-7:])
for color in colors:
if ns_end.endswith(color):
if color != in_color:
seen_coloredspace = False
in_color = color
if ns_end.endswith(C_NONE):
in_color = False
if (
c.isspace()
and in_color
and (
self.show_all_spaces
or not (seen_coloredspace or will_see_coloredspace(i, s))
)
):
n_s.extend([C_NONE, background(in_color), c, C_NONE, in_color])
else:
if in_color:
seen_coloredspace = True
n_s.append(c)
joined = "".join(n_s)
return joined
def raw_colorize(s, color):
return "%s%s%s" % (color_codes[color], s, color_codes["none"])
def simple_colorize(s, category):
return raw_colorize(s, color_mapping[category])
def replace_all(replacements, string):
for search, replace in replacements.items():
string = string.replace(search, replace)
return string
class MultipleOption(Option):
ACTIONS = Option.ACTIONS + ("extend",)
STORE_ACTIONS = Option.STORE_ACTIONS + ("extend",)
TYPED_ACTIONS = Option.TYPED_ACTIONS + ("extend",)
ALWAYS_TYPED_ACTIONS = Option.ALWAYS_TYPED_ACTIONS + ("extend",)
def take_action(self, action, dest, opt, value, values, parser):
if action == "extend":
values.ensure_value(dest, []).append(value)
else:
Option.take_action(self, action, dest, opt, value, values, parser)
def create_option_parser():
# If you change any of these, also update README.
parser = OptionParser(
usage="usage: %prog [options] left_file right_file",
version="icdiff version %s" % __version__,
description="Show differences between files in a " "two column view.",
option_class=MultipleOption,
)
parser.add_option(
"--cols",
default=None,
help="specify the width of the screen. Autodetection is " "Unix only",
)
parser.add_option(
"--encoding",
default="utf-8",
help="specify the file encoding; defaults to utf8",
)
parser.add_option(
"-E",
"--exclude-lines",
action="store",
type="string",
dest="matcher",
help="Do not diff lines that match this regex. Not "
"compatible with the 'line-numbers' option",
)
parser.add_option(
"--head",
default=0,
help="consider only the first N lines of each file",
)
parser.add_option(
"-H",
"--highlight",
default=False,
action="store_true",
help="color by changing the background color instead of "
"the foreground color. Very fast, ugly, displays all "
"changes",
)
parser.add_option(
"-L",
"--label",
action="extend",
type="string",
dest="labels",
help="override file labels with arbitrary tags. "
"Use twice, one for each file. You may include the "
"formatting strings '{path}' and '{basename}'",
)
parser.add_option(
"-N",
"--line-numbers",
default=False,
action="store_true",
help="generate output with line numbers. Not compatible "
"with the 'exclude-lines' option.",
)
parser.add_option(
"--no-bold",
default=False,
action="store_true",
help="use non-bold colors; recommended for solarized",
)
parser.add_option(
"--no-headers",
default=False,
action="store_true",
help="don't label the left and right sides " "with their file names",
)
parser.add_option(
"--output-encoding",
default="utf-8",
help="specify the output encoding; defaults to utf8",
)
parser.add_option(
"-r",
"--recursive",
default=False,
action="store_true",
help="recursively compare subdirectories",
)
parser.add_option(
"-s",
"--report-identical-files",
default=False,
action="store_true",
help="report when two files are the same",
)
parser.add_option(
"--show-all-spaces",
default=False,
action="store_true",
help="color all non-matching whitespace including "
"that which is not needed for drawing the eye to "
"changes. Slow, ugly, displays all changes",
)
parser.add_option(
"--show-no-spaces",
default=False,
action="store_true",
help="don't color whitespace-only changes",
)
parser.add_option("--tabsize", default=8, help="tab stop spacing")
parser.add_option(
"-t",
"--truncate",
default=False,
action="store_true",
help="truncate long lines instead of wrapping them",
)
parser.add_option(
"-u",
"--patch",
default=True,
action="store_true",
help="generate patch. This is always true, "
"and only exists for compatibility",
)
parser.add_option(
"-U",
"--unified",
"--numlines",
default=5,
metavar="NUM",
help="how many lines of context to print; "
"can't be combined with --whole-file",
)
parser.add_option(
"-W",
"--whole-file",
default=False,
action="store_true",
help="show the whole file instead of just changed "
"lines and context",
)
parser.add_option(
"-P",
"--permissions",
default=False,
action="store_true",
help="compare the file permissions as well as the "
"content of the file",
)
parser.add_option(
"--strip-trailing-cr",
default=False,
action="store_true",
help="strip any trailing carriage return at the end of "
"an input line",
)
parser.add_option(
"--color-map",
default=None,
help="choose which colors are used for which items. "
"Default is --color-map='"
+ ",".join("%s:%s" % x for x in sorted(color_mapping.items()))
+ "'"
". You don't have to override all of them: "
"'--color-map=separator:white,description:cyan",
)
parser.add_option(
"--is-git-diff",
default=False,
action="store_true",
help="Show the real file name when displaying " "git-diff result",
)
parser.add_option(
"-x",
"--exclude",
metavar="PAT",
action="append",
default=[],
help="exclude files that match PAT",
)
return parser
def set_cols_option(options):
if os.name == "nt":
try:
import struct
from ctypes import windll, create_string_buffer
fh = windll.kernel32.GetStdHandle(-12) # stderr is -12
csbi = create_string_buffer(22)
windll.kernel32.GetConsoleScreenBufferInfo(fh, csbi)
res = struct.unpack("hhhhHhhhhhh", csbi.raw)
options.cols = res[7] - res[5] + 1 # right - left + 1
return
except Exception:
pass
else:
def ioctl_GWINSZ(fd):
try:
import fcntl
import termios
import struct
cr = struct.unpack(
"hh", fcntl.ioctl(fd, termios.TIOCGWINSZ, "1234")
)
except Exception:
return None
return cr
cr = ioctl_GWINSZ(0) or ioctl_GWINSZ(1) or ioctl_GWINSZ(2)
if cr and cr[1] > 0:
options.cols = cr[1]
return
options.cols = 80
def validate_has_two_arguments(parser, args):
if len(args) != 2:
parser.print_help()
sys.exit(EXIT_CODE_DIFF)
def start():
diffs_found = False
parser = create_option_parser()
options, args = parser.parse_args()
validate_has_two_arguments(parser, args)
if not options.cols:
set_cols_option(options)
try:
diffs_found = diff(options, *args)
except KeyboardInterrupt:
pass
except IOError as e:
if e.errno == errno.EPIPE:
pass
else:
raise
# Close stderr to prevent printing errors when icdiff is piped to
# something that closes before icdiff is done writing
#
# See: https://stackoverflow.com/questions/26692284/...
# ...how-to-prevent-brokenpipeerror-when-doing-a-flush-in-python
sys.stderr.close()
sys.exit(EXIT_CODE_DIFF if diffs_found else EXIT_CODE_SUCCESS)
def codec_print(s, options):
s = "%s\n" % s
if hasattr(sys.stdout, "buffer"):
sys.stdout.buffer.write(s.encode(options.output_encoding))
else:
sys.stdout.write(s.encode(options.output_encoding))
def cmp_perms(options, a, b):
return not options.permissions or (
os.lstat(a).st_mode == os.lstat(b).st_mode
)
def should_be_excluded(name, pats):
return any(fnmatch.fnmatchcase(name, pat) for pat in pats)
def diff(options, a, b):
def print_meta(s):
codec_print(simple_colorize(s, "meta"), options)
# We start out and assume that no diffs have been found (so far)
diffs_found = False
# Don't use os.path.isfile; it returns False for file-like entities like
# bash's process substitution (/dev/fd/N).
is_a_file = not os.path.isdir(a)
is_b_file = not os.path.isdir(b)
if is_a_file and is_b_file:
try:
if not (
filecmp.cmp(a, b, shallow=False) and cmp_perms(options, a, b)
):
diffs_found = diffs_found | diff_files(options, a, b)
elif options.report_identical_files:
print("Files %s and %s are identical." % (a, b))
except OSError as e:
if e.errno == errno.ENOENT:
print_meta("error: file '%s' was not found" % e.filename)
sys.exit(EXIT_CODE_ERROR)
else:
raise (e)
elif not is_a_file and not is_b_file:
a_contents = set(os.listdir(a))
b_contents = set(os.listdir(b))
for child in sorted(a_contents.union(b_contents)):
if should_be_excluded(child, options.exclude):
continue
if child not in b_contents:
print_meta("Only in %s: %s" % (a, child))
elif child not in a_contents:
print_meta("Only in %s: %s" % (b, child))
elif options.recursive:
diffs_found = diffs_found | diff(
options, os.path.join(a, child), os.path.join(b, child)
)
elif not is_a_file and is_b_file:
print_meta("File %s is a directory while %s is a file" % (a, b))
diffs_found = True
elif is_a_file and not is_b_file:
print_meta("File %s is a file while %s is a directory" % (a, b))
diffs_found = True
return diffs_found
def read_file(fname, options):
try:
with codecs.open(fname, encoding=options.encoding, mode="rb") as inf:
return inf.readlines()
except UnicodeDecodeError as e:
codec_print(
"error: file '%s' not valid with encoding '%s': <%s> at %s-%s."
% (fname, options.encoding, e.reason, e.start, e.end),
options,
)
raise
except LookupError:
codec_print(
"error: encoding '%s' was not found." % (options.encoding), options
)
sys.exit(EXIT_CODE_ERROR)
def format_label(path, label="{path}"):
"""Format a label using a file's path and basename.
Example:
For file `/foo/bar.py` and label "Yours: {basename}" -
The output is "Yours: bar.py"
"""
return label.format(path=path, basename=os.path.basename(path))
def diff_files(options, a, b):
diff_found = False
if options.is_git_diff is True:
# Use $BASE as label when displaying git-diff result
base = os.getenv("BASE")
headers = [format_label(a, base), format_label(b, base)]
else:
if options.labels:
if len(options.labels) == 2:
headers = [
format_label(a, options.labels[0]),
format_label(b, options.labels[1]),
]
else:
codec_print(
"error: to use arbitrary file labels, "
"specify -L twice.",
options,
)
sys.exit(EXIT_CODE_ERROR)
else:
headers = a, b
if options.no_headers:
headers = None, None
head = int(options.head)
assert not os.path.isdir(a)
assert not os.path.isdir(b)
try:
lines_a = read_file(a, options)
lines_b = read_file(b, options)
except UnicodeDecodeError:
return diff_found
if head != 0:
lines_a = lines_a[:head]
lines_b = lines_b[:head]
if options.matcher:
lines_a = [
line_a
for line_a in lines_a
if not re.search(options.matcher, line_a)
]
lines_b = [
line_b
for line_b in lines_b
if not re.search(options.matcher, line_b)
]
# Determine if a difference has been detected
diff_found = lines_a != lines_b or not cmp_perms(options, a, b)
if options.no_bold:
for key in color_mapping:
color_mapping[key] = color_mapping[key].replace("_bold", "")
if options.color_map:
command_for_errors = '--color-map="%s"' % (options.color_map)
for mapping in options.color_map.split(","):
category, color = mapping.split(":", 1)
if category not in color_mapping:
print(
"Invalid category '%s' in '%s'. Valid categories are: %s."
% (
category,
command_for_errors,
", ".join(sorted(color_mapping.keys())),
)
)
sys.exit(EXIT_CODE_ERROR)
if color not in color_codes:
print(
"Invalid color '%s' in '%s'. Valid colors are: %s."
% (
color,
command_for_errors,
", ".join(
[
raw_colorize(x, x)
for x in sorted(color_codes.keys())
]
),
)
)
sys.exit(EXIT_CODE_ERROR)
color_mapping[category] = color
if options.permissions:
mode_a = os.lstat(a).st_mode
mode_b = os.lstat(b).st_mode
else:
mode_a = None
mode_b = None
cd = ConsoleDiff(
cols=int(options.cols),
show_all_spaces=options.show_all_spaces,
show_no_spaces=options.show_no_spaces,
highlight=options.highlight,
line_numbers=options.line_numbers,
tabsize=int(options.tabsize),
truncate=options.truncate,
strip_trailing_cr=options.strip_trailing_cr,
)
for line in cd.make_table(
lines_a,
lines_b,
headers[0],
headers[1],
mode_a,
mode_b,
context=(not options.whole_file),
numlines=int(options.unified),
):
codec_print(line, options)
sys.stdout.flush()
return diff_found
if __name__ == "__main__":
start()
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/icdiff.py����������������������������������������������������������������������0000777�0000000�0000000�00000000000�14470675724�0017342�2icdiff����������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/requirements-dev.txt�����������������������������������������������������������0000664�0000000�0000000�00000000104�14470675724�0020435�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������flake8==2.4.0
mccabe==0.3
pep8==1.5.7
pyflakes==0.8.1
black==22.3.0
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/setup.py�����������������������������������������������������������������������0000664�0000000�0000000�00000001267�14470675724�0016122�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������from setuptools import setup
from icdiff import __version__
setup(
name="icdiff",
version=__version__,
url="https://www.jefftk.com/icdiff",
project_urls={
"Source": "https://github.com/jeffkaufman/icdiff",
},
classifiers=[
"License :: OSI Approved :: Python Software Foundation License"
],
author="Jeff Kaufman",
author_email="jeff@jefftk.com",
description="improved colored diff",
long_description=open('README.md').read(),
long_description_content_type='text/markdown',
scripts=['git-icdiff'],
py_modules=['icdiff'],
entry_points={
'console_scripts': [
'icdiff=icdiff:start',
],
},
)
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/test.sh������������������������������������������������������������������������0000775�0000000�0000000�00000020225�14470675724�0015721�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/bin/bash
# Usage: ./test.sh [--regold] [test-name] python[3]
# Example:
# Run all tests:
# ./test.sh python3
# Regold all tests:
# ./test.sh --regold python3
# Run one test:
# ./test.sh tests/gold-45-sas-h-nb.txt python3
# Regold one test:
# ./test.sh --regold tests/gold-45-sas-h-nb.txt python3
if [ "$#" -gt 1 -a "$1" = "--regold" ]; then
REGOLD=true
shift
else
REGOLD=false
fi
TEST_NAME=all
if [ "$#" -gt 1 ]; then
TEST_NAME=$1
shift
fi
if [ "$#" != 1 ]; then
echo "Usage: '$0 [--regold] [test-name] python[3]'"
exit 1
fi
PYTHON="$1"
ICDIFF="icdiff"
if [ ! -z "$INSTALLED" ]; then
INVOCATION="$ICDIFF"
else
INVOCATION="$PYTHON $ICDIFF"
fi
function fail() {
echo "FAIL"
exit 1
}
function check_gold() {
local error_code
local expect=$1
local gold=tests/$2
shift
shift
if [ $TEST_NAME != "all" -a $TEST_NAME != $gold ]; then
return
fi
echo " check_gold $gold matches $@"
local tmp=/tmp/icdiff.output
$INVOCATION "$@" &> $tmp
error_code=$?
if $REGOLD; then
if [ -e $gold ] && diff $tmp $gold > /dev/null; then
echo "Did not need to regold $gold"
else
cat $tmp
read -p "Is this correct? y/n > " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
mv $tmp $gold
echo "Regolded $gold."
else
echo "Did not regold $gold."
fi
fi
return
fi
if ! diff $gold $tmp; then
echo "Got: ($tmp)"
cat $tmp
echo "Expected: ($gold)"
cat $gold
fail
fi
if [[ $error_code != $expect ]]; then
echo "Got error code: $error_code"
echo "Expected error code: $expect"
fail
fi
}
FIRST_TIME_CHECK_GIT_DIFF=true
function check_git_diff() {
local gitdiff=tests/$1
shift
echo " check_gitdiff $gitdiff matches git icdiff $@"
# Check when using icdiff in git
if $FIRST_TIME_CHECK_GIT_DIFF; then
FIRST_TIME_CHECK_GIT_DIFF=false
# Set default args when first time check git diff
yes | git difftool --extcmd icdiff > /dev/null
git config --global icdiff.options '--cols=80'
export PATH="$(pwd)":$PATH
fi
local tmp=/tmp/git-icdiff.output
git icdiff $1 $2 &> $tmp
if ! diff $tmp $gitdiff; then
echo "Got: ($tmp)"
cat $tmp
echo "Expected: ($gitdiff)"
fail
fi
}
check_gold 1 gold-recursive.txt --recursive tests/{a,b} --cols=80
check_gold 1 gold-exclude.txt --exclude-lines '^#| pad' tests/input-4-cr.txt tests/input-4-partial-cr.txt --cols=80
check_gold 0 gold-dir.txt tests/{a,b} --cols=80
check_gold 1 gold-12.txt tests/input-{1,2}.txt --cols=80
check_gold 1 gold-12-t.txt tests/input-{1,2}.txt --cols=80 --truncate
check_gold 0 gold-3.txt tests/input-{3,3}.txt
check_gold 1 gold-45.txt tests/input-{4,5}.txt --cols=80
check_gold 1 gold-45-95.txt tests/input-{4,5}.txt --cols=95
check_gold 1 gold-45-sas.txt tests/input-{4,5}.txt --cols=80 --show-all-spaces
check_gold 1 gold-45-h.txt tests/input-{4,5}.txt --cols=80 --highlight
check_gold 1 gold-45-nb.txt tests/input-{4,5}.txt --cols=80 --no-bold
check_gold 1 gold-45-sas-h.txt tests/input-{4,5}.txt --cols=80 --show-all-spaces --highlight
check_gold 1 gold-45-sas-h-nb.txt tests/input-{4,5}.txt --cols=80 --show-all-spaces --highlight --no-bold
check_gold 1 gold-sas.txt tests/input-{10,11}.txt --cols=80 --show-all-spaces
check_gold 1 gold-sns.txt tests/input-{10,11}.txt --cols=80 --show-no-spaces
check_gold 1 gold-show-spaces.txt tests/input-{10,11}.txt --cols=80
check_gold 1 gold-45-h-nb.txt tests/input-{4,5}.txt --cols=80 --highlight --no-bold
check_gold 1 gold-45-ln.txt tests/input-{4,5}.txt --cols=80 --line-numbers
check_gold 1 gold-45-ln-color.txt tests/input-{4,5}.txt --cols=80 --line-numbers --color-map='line-numbers:cyan'
check_gold 1 gold-45-nh.txt tests/input-{4,5}.txt --cols=80 --no-headers
check_gold 1 gold-45-h3.txt tests/input-{4,5}.txt --cols=80 --head=3
check_gold 2 gold-45-l.txt tests/input-{4,5}.txt --cols=80 -L left
check_gold 1 gold-45-lr.txt tests/input-{4,5}.txt --cols=80 -L left -L right
check_gold 1 gold-45-lbrb.txt tests/input-{4,5}.txt --cols=80 -L "L {basename}" -L "R {basename}"
check_gold 1 gold-45-pipe.txt tests/input-4.txt <(cat tests/input-5.txt) --cols=80 --no-headers
check_gold 1 gold-4dn.txt tests/input-4.txt /dev/null --cols=80 -L left -L right
check_gold 1 gold-dn5.txt /dev/null tests/input-5.txt --cols=80 -L left -L right
check_gold 1 gold-67.txt tests/input-{6,7}.txt --cols=80
check_gold 1 gold-67-wf.txt tests/input-{6,7}.txt --cols=80 --whole-file
check_gold 1 gold-67-ln.txt tests/input-{6,7}.txt --cols=80 --line-numbers
check_gold 1 gold-67-u3.txt tests/input-{6,7}.txt --cols=80 -U 3
check_gold 1 gold-tabs-default.txt tests/input-{8,9}.txt --cols=80
check_gold 1 gold-tabs-4.txt tests/input-{8,9}.txt --cols=80 --tabsize=4
check_gold 2 gold-file-not-found.txt tests/input-4.txt nonexistent_file
check_gold 1 gold-strip-cr-off.txt tests/input-4.txt tests/input-4-cr.txt --cols=80
check_gold 1 gold-strip-cr-on.txt tests/input-4.txt tests/input-4-cr.txt --cols=80 --strip-trailing-cr
check_gold 1 gold-no-cr-indent tests/input-4-cr.txt tests/input-4-partial-cr.txt --cols=80
check_gold 1 gold-hide-cr-if-dos tests/input-4-cr.txt tests/input-5-cr.txt --cols=80
check_gold 1 gold-12-subcolors.txt tests/input-{1,2}.txt --cols=80 --color-map='change:magenta,description:cyan_bold'
check_gold 2 gold-subcolors-bad-color tests/input-{1,2}.txt --cols=80 --color-map='change:mageta,description:cyan_bold'
check_gold 2 gold-subcolors-bad-cat tests/input-{1,2}.txt --cols=80 --color-map='chnge:magenta,description:cyan_bold'
check_gold 2 gold-subcolors-bad-fmt tests/input-{1,2}.txt --cols=80 --color-map='change:magenta:gold,description:cyan_bold'
check_gold 0 gold-identical-on.txt tests/input-{1,1}.txt -s
check_gold 2 gold-bad-encoding.txt tests/input-{1,2}.txt --encoding=nonexistend_encoding
check_gold 0 gold-recursive-with-exclude.txt --recursive -x c tests/{a,b} --cols=80
check_gold 1 gold-recursive-with-exclude2.txt --recursive -x 'excl*' tests/test-with-exclude/{a,b} --cols=80
check_gold 0 gold-exit-process-sub tests/input-1.txt <(cat tests/input-1.txt) --no-headers --cols=80
rm -f tests/permissions-{a,b}
touch tests/permissions-{a,b}
check_gold 0 gold-permissions-same.txt tests/permissions-{a,b} -P --cols=80
chmod 666 tests/permissions-a
chmod 665 tests/permissions-b
check_gold 1 gold-permissions-diff.txt tests/permissions-{a,b} -P --cols=80
echo "some text" >> tests/permissions-a
check_gold 1 gold-permissions-diff-text.txt tests/permissions-{a,b} -P --cols=80
echo -e "\04" >> tests/permissions-b
check_gold 1 gold-permissions-diff-binary.txt tests/permissions-{a,b} -P --cols=80
rm -f tests/permissions-{a,b}
if git show 4e86205629 &> /dev/null; then
# We're in the repo, so test git.
check_git_diff gitdiff-only-newlines.txt 4e86205629~1 4e86205629
else
echo "Not in icdiff repo; skipping git test"
fi
# Testing pipe behavior doesn't fit well with the check_gold system
$INVOCATION tests/input-{4,5}.txt 2>/tmp/icdiff-pipe-error-output | head -n 1
if [ -s /tmp/icdiff-pipe-error-output ]; then
echo 'emitting errors on early pipe closure'
fail
fi
VERSION=$($INVOCATION --version | awk '{print $NF}')
if [ "$VERSION" != $(head -n 1 ChangeLog) ]; then
echo "Version mismatch between ChangeLog and icdiff source."
fail
fi
function ensure_installed() {
if ! command -v "$1" >/dev/null 2>&1; then
echo "Could not find $1."
echo 'Ensure it is installed and on your $PATH.'
if [ -z "$VIRTUAL_ENV" ]; then
echo 'It appears you have have forgotten to activate your virtualenv.'
fi
echo 'See README.md for details on setting up your environment.'
fail
fi
}
ensure_installed "black"
echo 'Running black formatter...'
if ! black icdiff --quiet --line-length 79 --check; then
echo ""
echo 'Consider running `black icdiff --line-length 79`'
fail
fi
ensure_installed "flake8"
echo 'Running flake8 linter...'
if ! flake8 icdiff; then
fail
fi
if ! $REGOLD; then
echo PASS
fi
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/�������������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0015544�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/�����������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0015764�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/1����������������������������������������������������������������������0000664�0000000�0000000�00000000000�14470675724�0016035�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/c/���������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0016206�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/c/e��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016345�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������1
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/c/f��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016346�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������2
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/a/j����������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016130�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������7
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/�����������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0015765�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/1����������������������������������������������������������������������0000664�0000000�0000000�00000054375�14470675724�0016066�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������UTF-8 decoder capability and stress test
----------------------------------------
Markus Kuhn - 2015-08-28 - CC BY 4.0
This test file can help you examine, how your UTF-8 decoder handles
various types of correct, malformed, or otherwise interesting UTF-8
sequences. This file is not meant to be a conformance test. It does
not prescribe any particular outcome. Therefore, there is no way to
"pass" or "fail" this test file, even though the text does suggest a
preferable decoder behaviour at some places. Its aim is, instead, to
help you think about, and test, the behaviour of your UTF-8 decoder on a
systematic collection of unusual inputs. Experience so far suggests
that most first-time authors of UTF-8 decoders find at least one
serious problem in their decoder using this file.
The test lines below cover boundary conditions, malformed UTF-8
sequences, as well as correctly encoded UTF-8 sequences of Unicode code
points that should never occur in a correct UTF-8 file.
According to ISO 10646-1:2000, sections D.7 and 2.3c, a device
receiving UTF-8 shall interpret a "malformed sequence in the same way
that it interprets a character that is outside the adopted subset" and
"characters that are not within the adopted subset shall be indicated
to the user" by a receiving device. One commonly used approach in
UTF-8 decoders is to replace any malformed UTF-8 sequence by a
replacement character (U+FFFD), which looks a bit like an inverted
question mark, or a similar symbol. It might be a good idea to
visually distinguish a malformed UTF-8 sequence from a correctly
encoded Unicode character that is just not available in the current
font but otherwise fully legal, even though ISO 10646-1 doesn't
mandate this. In any case, just ignoring malformed sequences or
unavailable characters does not conform to ISO 10646, will make
debugging more difficult, and can lead to user confusion.
Please check, whether a malformed UTF-8 sequence is (1) represented at
all, (2) represented by exactly one single replacement character (or
equivalent signal), and (3) the following quotation mark after an
illegal UTF-8 sequence is correctly displayed, i.e. proper
resynchronization takes place immediately after any malformed
sequence. This file says "THE END" in the last line, so if you don't
see that, your decoder crashed somehow before, which should always be
cause for concern.
All lines in this file are exactly 79 characters long (plus the line
feed). In addition, all lines end with "|", except for the two test
lines 2.1.1 and 2.2.1, which contain non-printable ASCII controls
U+0000 and U+007F. If you display this file with a fixed-width font,
these "|" characters should all line up in column 79 (right margin).
This allows you to test quickly, whether your UTF-8 decoder finds the
correct number of characters in every line, that is whether each
malformed sequences is replaced by a single replacement character.
Note that, as an alternative to the notion of malformed sequence used
here, it is also a perfectly acceptable (and in some situations even
preferable) solution to represent each individual byte of a malformed
sequence with a replacement character. If you follow this strategy in
your decoder, then please ignore the "|" column.
Here come the tests: |
|
1 Some correct UTF-8 text |
|
You should see the Greek word 'kosme': "κόσμε" |
|
2 Boundary condition test cases |
|
2.1 First possible sequence of a certain length |
|
2.1.1 1 byte (U-00000000): "�"
2.1.2 2 bytes (U-00000080): "" |
2.1.3 3 bytes (U-00000800): "ࠀ" |
2.1.4 4 bytes (U-00010000): "𐀀" |
2.1.5 5 bytes (U-00200000): "�����" |
2.1.6 6 bytes (U-04000000): "������" |
|
2.2 Last possible sequence of a certain length |
|
2.2.1 1 byte (U-0000007F): ""
2.2.2 2 bytes (U-000007FF): "߿" |
2.2.3 3 bytes (U-0000FFFF): "" |
2.2.4 4 bytes (U-001FFFFF): "����" |
2.2.5 5 bytes (U-03FFFFFF): "�����" |
2.2.6 6 bytes (U-7FFFFFFF): "������" |
|
2.3 Other boundary conditions |
|
2.3.1 U-0000D7FF = ed 9f bf = "" |
2.3.2 U-0000E000 = ee 80 80 = "" |
2.3.3 U-0000FFFD = ef bf bd = "�" |
2.3.4 U-0010FFFF = f4 8f bf bf = "" |
2.3.5 U-00110000 = f4 90 80 80 = "����" |
|
3 Malformed sequences |
|
3.1 Unexpected continuation bytes |
|
Each unexpected continuation byte should be separately signalled as a |
malformed sequence of its own. |
|
3.1.1 First continuation byte 0x80: "�" |
3.1.2 Last continuation byte 0xbf: "�" |
|
3.1.3 2 continuation bytes: "��" |
3.1.4 3 continuation bytes: "���" |
3.1.5 4 continuation bytes: "����" |
3.1.6 5 continuation bytes: "�����" |
3.1.7 6 continuation bytes: "������" |
3.1.8 7 continuation bytes: "�������" |
|
3.1.9 Sequence of all 64 possible continuation bytes (0x80-0xbf): |
|
"���������������� |
���������������� |
���������������� |
����������������" |
|
3.2 Lonely start characters |
|
3.2.1 All 32 first bytes of 2-byte sequences (0xc0-0xdf), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � |
� � � � � � � � � � � � � � � � " |
|
3.2.2 All 16 first bytes of 3-byte sequences (0xe0-0xef), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � " |
|
3.2.3 All 8 first bytes of 4-byte sequences (0xf0-0xf7), |
each followed by a space character: |
|
"� � � � � � � � " |
|
3.2.4 All 4 first bytes of 5-byte sequences (0xf8-0xfb), |
each followed by a space character: |
|
"� � � � " |
|
3.2.5 All 2 first bytes of 6-byte sequences (0xfc-0xfd), |
each followed by a space character: |
|
"� � " |
|
3.3 Sequences with last continuation byte missing |
|
All bytes of an incomplete sequence should be signalled as a single |
malformed sequence, i.e., you should see only a single replacement |
character in each of the next 10 tests. (Characters as in section 2) |
|
3.3.1 2-byte sequence with last byte missing (U+0000): "�" |
3.3.2 3-byte sequence with last byte missing (U+0000): "��" |
3.3.3 4-byte sequence with last byte missing (U+0000): "���" |
3.3.4 5-byte sequence with last byte missing (U+0000): "����" |
3.3.5 6-byte sequence with last byte missing (U+0000): "�����" |
3.3.6 2-byte sequence with last byte missing (U-000007FF): "�" |
3.3.7 3-byte sequence with last byte missing (U-0000FFFF): "�" |
3.3.8 4-byte sequence with last byte missing (U-001FFFFF): "���" |
3.3.9 5-byte sequence with last byte missing (U-03FFFFFF): "����" |
3.3.10 6-byte sequence with last byte missing (U-7FFFFFFF): "�����" |
|
3.4 Concatenation of incomplete sequences |
|
All the 10 sequences of 3.3 concatenated, you should see 10 malformed |
sequences being signalled: |
|
"�����������������������������" |
|
3.5 Impossible bytes |
|
The following two bytes cannot appear in a correct UTF-8 string |
|
3.5.1 fe = "�" |
3.5.2 ff = "�" |
3.5.3 fe fe ff ff = "����" |
|
4 Overlong sequences |
|
The following sequences are not malformed according to the letter of |
the Unicode 2.0 standard. However, they are longer then necessary and |
a correct UTF-8 encoder is not allowed to produce them. A "safe UTF-8 |
decoder" should reject them just like malformed sequences for two |
reasons: (1) It helps to debug applications if overlong sequences are |
not treated as valid representations of characters, because this helps |
to spot problems more quickly. (2) Overlong sequences provide |
alternative representations of characters, that could maliciously be |
used to bypass filters that check only for ASCII characters. For |
instance, a 2-byte encoded line feed (LF) would not be caught by a |
line counter that counts only 0x0a bytes, but it would still be |
processed as a line feed by an unsafe UTF-8 decoder later in the |
pipeline. From a security point of view, ASCII compatibility of UTF-8 |
sequences means also, that ASCII characters are *only* allowed to be |
represented by ASCII bytes in the range 0x00-0x7f. To ensure this |
aspect of ASCII compatibility, use only "safe UTF-8 decoders" that |
reject overlong UTF-8 sequences for which a shorter encoding exists. |
|
4.1 Examples of an overlong ASCII character |
|
With a safe UTF-8 decoder, all of the following five overlong |
representations of the ASCII character slash ("/") should be rejected |
like a malformed UTF-8 sequence, for instance by substituting it with |
a replacement character. If you see a slash below, you do not have a |
safe UTF-8 decoder! |
|
4.1.1 U+002F = c0 af = "��" |
4.1.2 U+002F = e0 80 af = "���" |
4.1.3 U+002F = f0 80 80 af = "����" |
4.1.4 U+002F = f8 80 80 80 af = "�����" |
4.1.5 U+002F = fc 80 80 80 80 af = "������" |
|
4.2 Maximum overlong sequences |
|
Below you see the highest Unicode value that is still resulting in an |
overlong sequence if represented with the given number of bytes. This |
is a boundary test for safe UTF-8 decoders. All five characters should |
be rejected like malformed UTF-8 sequences. |
|
4.2.1 U-0000007F = c1 bf = "��" |
4.2.2 U-000007FF = e0 9f bf = "���" |
4.2.3 U-0000FFFF = f0 8f bf bf = "����" |
4.2.4 U-001FFFFF = f8 87 bf bf bf = "�����" |
4.2.5 U-03FFFFFF = fc 83 bf bf bf bf = "������" |
|
4.3 Overlong representation of the NUL character |
|
The following five sequences should also be rejected like malformed |
UTF-8 sequences and should not be treated like the ASCII NUL |
character. |
|
4.3.1 U+0000 = c0 80 = "��" |
4.3.2 U+0000 = e0 80 80 = "���" |
4.3.3 U+0000 = f0 80 80 80 = "����" |
4.3.4 U+0000 = f8 80 80 80 80 = "�����" |
4.3.5 U+0000 = fc 80 80 80 80 80 = "������" |
|
5 Illegal code positions |
|
The following UTF-8 sequences should be rejected like malformed |
sequences, because they never represent valid ISO 10646 characters and |
a UTF-8 decoder that accepts them might introduce security problems |
comparable to overlong UTF-8 sequences. |
|
5.1 Single UTF-16 surrogates |
|
5.1.1 U+D800 = ed a0 80 = "���" |
5.1.2 U+DB7F = ed ad bf = "���" |
5.1.3 U+DB80 = ed ae 80 = "���" |
5.1.4 U+DBFF = ed af bf = "���" |
5.1.5 U+DC00 = ed b0 80 = "���" |
5.1.6 U+DF80 = ed be 80 = "���" |
5.1.7 U+DFFF = ed bf bf = "���" |
|
5.2 Paired UTF-16 surrogates |
|
5.2.1 U+D800 U+DC00 = ed a0 80 ed b0 80 = "������" |
5.2.2 U+D800 U+DFFF = ed a0 80 ed bf bf = "������" |
5.2.3 U+DB7F U+DC00 = ed ad bf ed b0 80 = "������" |
5.2.4 U+DB7F U+DFFF = ed ad bf ed bf bf = "������" |
5.2.5 U+DB80 U+DC00 = ed ae 80 ed b0 80 = "������" |
5.2.6 U+DB80 U+DFFF = ed ae 80 ed bf bf = "������" |
5.2.7 U+DBFF U+DC00 = ed af bf ed b0 80 = "������" |
5.2.8 U+DBFF U+DFFF = ed af bf ed bf bf = "������" |
|
5.3 Noncharacter code positions |
|
The following "noncharacters" are "reserved for internal use" by |
applications, and according to older versions of the Unicode Standard |
"should never be interchanged". Unicode Corrigendum #9 dropped the |
latter restriction. Nevertheless, their presence in incoming UTF-8 data |
can remain a potential security risk, depending on what use is made of |
these codes subsequently. Examples of such internal use: |
|
- Some file APIs with 16-bit characters may use the integer value -1 |
= U+FFFF to signal an end-of-file (EOF) or error condition. |
|
- In some UTF-16 receivers, code point U+FFFE might trigger a |
byte-swap operation (to convert between UTF-16LE and UTF-16BE). |
|
With such internal use of noncharacters, it may be desirable and safer |
to block those code points in UTF-8 decoders, as they should never |
occur legitimately in incoming UTF-8 data, and could trigger unsafe |
behaviour in subsequent processing. |
|
Particularly problematic noncharacters in 16-bit applications: |
|
5.3.1 U+FFFE = ef bf be = "" |
5.3.2 U+FFFF = ef bf bf = "" |
|
Other noncharacters: |
|
5.3.3 U+FDD0 .. U+FDEF = ""|
|
5.3.4 U+nFFFE U+nFFFF (for n = 1..10) |
|
" |
" |
|
THE END |
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/c/���������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0016207�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/c/e��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016346�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������1
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/c/f��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016347�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������3
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/c/g��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016350�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������4
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/c/h��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016351�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������5
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/d/���������������������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0016210�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/d/q��������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016363�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������9
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/b/i����������������������������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0016130�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������6
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gitdiff-only-newlines.txt������������������������������������������������0000664�0000000�0000000�00000003554�14470675724�0022531�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mREADME�[m �[0;34mREADME�[m
--show-all-spaces color all non-m --show-all-spaces color all non-m
atching whitespace including atching whitespace including
that which is n that which is n
ot needed for drawing the eye to ot needed for drawing the eye to
changes. Slow, changes. Slow,
ugly, displays all changes ugly, displays all changes
--print-headers label the left --print-headers label the left
and right sides with their file and right sides with their file
names names
�[7;32m �[m
�[1;32mLicense:�[m
�[7;32m �[m
�[1;32m This file is derived from difflib.Ht�[m
�[1;32mmlDiff which is under the license:�[m
�[7;32m �[m
�[1;32m http://www.python.org/download/rel�[m
�[1;32meases/2.6.2/license/�[m
�[7;32m �[m
�[1;32m I release my changes here under the �[m
�[1;32msame license. This is GPL compatible.�[m
�[7;32m �[m
����������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-12-subcolors.txt����������������������������������������������������0000664�0000000�0000000�00000001264�14470675724�0021466�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[1;36mtests/input-1.txt�[m �[1;36mtests/input-2.txt�[m
测试行a�[0;35mb�[mc测试测试行a�[0;35mb�[mc,测试测试行a�[0;35mb�[mc测 测试行a�[0;35md�[mc测试测试行a�[0;35md�[mc,测试测试行a�[0;35md�[mc测
试测试行a�[0;35mb�[mc测试测试行a�[0;35mb�[mc测试测试行a�[0;35mb�[mc测 试测试行a�[0;35md�[mc测试测试行a�[0;35md�[mc测试测试行a�[0;35md�[mc测
试测试行a�[0;35mb�[mc测试测试行a�[0;35mb�[mc测试测试行a�[0;35mb�[mc测 试测试行a�[0;35md�[mc测试测试行a�[0;35md�[mc测试测试行a�[0;35md�[mc测
试 试
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-12-t.txt������������������������������������������������������������0000664�0000000�0000000�00000000416�14470675724�0017714�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-1.txt�[m �[0;34mtests/input-2.txt�[m
测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc,测试测试行a�[1;33mb�[mc测 测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc,测试测试行a�[1;33md�[mc测
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-12.txt��������������������������������������������������������������0000664�0000000�0000000�00000001264�14470675724�0017455�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-1.txt�[m �[0;34mtests/input-2.txt�[m
测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc,测试测试行a�[1;33mb�[mc测 测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc,测试测试行a�[1;33md�[mc测
试测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc测 试测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc测
试测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc测试测试行a�[1;33mb�[mc测 试测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc测试测试行a�[1;33md�[mc测
试 试
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-3.txt���������������������������������������������������������������0000664�0000000�0000000�00000000000�14470675724�0017360�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-95.txt�����������������������������������������������������������0000664�0000000�0000000�00000001774�14470675724�0017724�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
����icdiff-release-2.0.7/tests/gold-45-h-nb.txt���������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0020304�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[7;33m35�[m0px; width: �[7;33m40�[m0px;
height: 40px; height: 40px;
�[7;32m font-size: 30px;�[m
margin: 0�[7;31mpx�[m; margin: 0;
padding: 0�[7;31mpx�[m; padding: 0;
�[7;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-h.txt������������������������������������������������������������0000664�0000000�0000000�00000001574�14470675724�0017714�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[7;1;33m35�[m0px; width: �[7;1;33m40�[m0px;
height: 40px; height: 40px;
�[7;1;32m font-size: 30px;�[m
margin: 0�[7;1;31mpx�[m; margin: 0;
padding: 0�[7;1;31mpx�[m; padding: 0;
�[7;1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-h3.txt�����������������������������������������������������������0000664�0000000�0000000�00000000550�14470675724�0017770�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
��������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-l.txt������������������������������������������������������������0000664�0000000�0000000�00000000067�14470675724�0017714�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������error: to use arbitrary file labels, specify -L twice.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-lbrb.txt���������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0020401�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mL input-4.txt�[m �[0;34mR input-5.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-ln-color.txt�����������������������������������������������������0000664�0000000�0000000�00000002020�14470675724�0021175�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
�[0;36m1�[m #input, #button { �[0;36m1�[m #input, #button {
�[0;36m2�[m width: �[1;33m35�[m0px; �[0;36m2�[m width: �[1;33m40�[m0px;
�[0;36m3�[m height: 40px; �[0;36m3�[m height: 40px;
�[0;36m4�[m �[1;32m font-size: 30px;�[m
�[0;36m4�[m margin: 0�[1;31mpx�[m; �[0;36m5�[m margin: 0;
�[0;36m5�[m padding: 0�[1;31mpx�[m; �[0;36m6�[m padding: 0;
�[0;36m6�[m �[1;31m margin-bottom: 15px;�[m
�[0;36m7�[m text-align: center; �[0;36m7�[m text-align: center;
�[0;36m8�[m } �[0;36m8�[m }
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-ln.txt�����������������������������������������������������������0000664�0000000�0000000�00000002020�14470675724�0020061�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
�[0;37m1�[m #input, #button { �[0;37m1�[m #input, #button {
�[0;37m2�[m width: �[1;33m35�[m0px; �[0;37m2�[m width: �[1;33m40�[m0px;
�[0;37m3�[m height: 40px; �[0;37m3�[m height: 40px;
�[0;37m4�[m �[1;32m font-size: 30px;�[m
�[0;37m4�[m margin: 0�[1;31mpx�[m; �[0;37m5�[m margin: 0;
�[0;37m5�[m padding: 0�[1;31mpx�[m; �[0;37m6�[m padding: 0;
�[0;37m6�[m �[1;31m margin-bottom: 15px;�[m
�[0;37m7�[m text-align: center; �[0;37m7�[m text-align: center;
�[0;37m8�[m } �[0;37m8�[m }
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-lr.txt�����������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0020075�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mleft�[m �[0;34mright�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-nb.txt�����������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0020057�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[0;33m35�[m0px; width: �[0;33m40�[m0px;
height: 40px; height: 40px;
�[0;32m font-size: 30px;�[m
margin: 0�[0;31mpx�[m; margin: 0;
padding: 0�[0;31mpx�[m; padding: 0;
�[0;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-nh.txt�����������������������������������������������������������0000664�0000000�0000000�00000001414�14470675724�0020063�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-pipe.txt���������������������������������������������������������0000664�0000000�0000000�00000001414�14470675724�0020413�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-sas-h-nb.txt�����������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0021070�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[7;33m35�[m0px; width: �[7;33m40�[m0px;
height: 40px; height: 40px;
�[7;32m font-size: 30px;�[m
margin: 0�[7;31mpx�[m; margin: 0;
padding: 0�[7;31mpx�[m; padding: 0;
�[7;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-sas-h.txt��������������������������������������������������������0000664�0000000�0000000�00000001574�14470675724�0020500�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[7;1;33m35�[m0px; width: �[7;1;33m40�[m0px;
height: 40px; height: 40px;
�[7;1;32m font-size: 30px;�[m
margin: 0�[7;1;31mpx�[m; margin: 0;
padding: 0�[7;1;31mpx�[m; padding: 0;
�[7;1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-45-sas.txt����������������������������������������������������������0000664�0000000�0000000�00000001764�14470675724�0020254�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m�[m�[7;1;32m �[m�[1;32m�[m�[7;1;32m �[m�[1;32mfont-size:�[m�[7;1;32m �[m�[1;32m30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m�[m�[7;1;31m �[m�[1;31m�[m�[7;1;31m �[m�[1;31mmargin-bottom:�[m�[7;1;31m �[m�[1;31m15px;�[m
text-align: center; text-align: center;
} }
������������icdiff-release-2.0.7/tests/gold-45.txt��������������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0017462�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-5.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-4dn.txt�������������������������������������������������������������0000664�0000000�0000000�00000001464�14470675724�0017722�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mleft�[m �[0;34mright�[m
�[1;31m#input, #button {�[m
�[1;31m width: 350px;�[m
�[1;31m height: 40px;�[m
�[1;31m margin: 0px;�[m
�[1;31m padding: 0px;�[m
�[1;31m margin-bottom: 15px;�[m
�[1;31m text-align: center;�[m
�[1;31m}�[m
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-67-ln.txt�����������������������������������������������������������0000664�0000000�0000000�00000002424�14470675724�0020075�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-6.txt�[m �[0;34mtests/input-7.txt�[m
�[0;37m8�[m h �[0;37m8�[m h
�[0;37m9�[m i �[0;37m9�[m i
�[0;37m10�[m j �[0;37m10�[m j
�[0;37m11�[m k �[0;37m11�[m k
�[0;37m12�[m l �[0;37m12�[m l
�[0;37m13�[m �[1;32mm�[m
�[0;37m14�[m �[1;32mm�[m
�[0;37m13�[m m �[0;37m15�[m m
�[0;37m14�[m n �[0;37m16�[m n
�[0;37m15�[m o �[0;37m17�[m o
�[0;37m16�[m p �[0;37m18�[m p
�[0;37m17�[m q �[0;37m19�[m q
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-67-u3.txt�����������������������������������������������������������0000664�0000000�0000000�00000001370�14470675724�0020012�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-6.txt�[m �[0;34mtests/input-7.txt�[m
j j
k k
l l
�[1;32mm�[m
�[1;32mm�[m
m m
n n
o o
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-67-wf.txt�����������������������������������������������������������0000664�0000000�0000000�00000004470�14470675724�0020103�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-6.txt�[m �[0;34mtests/input-7.txt�[m
a a
b b
c c
d d
e e
f f
g g
h h
i i
j j
k k
l l
�[1;32mm�[m
�[1;32mm�[m
m m
n n
o o
p p
q q
r r
s s
t t
u u
z z
w w
x x
y y
z z
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-67.txt��������������������������������������������������������������0000664�0000000�0000000�00000002070�14470675724�0017463�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-6.txt�[m �[0;34mtests/input-7.txt�[m
h h
i i
j j
k k
l l
�[1;32mm�[m
�[1;32mm�[m
m m
n n
o o
p p
q q
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-bad-encoding.txt����������������������������������������������������0000664�0000000�0000000�00000000066�14470675724�0021544�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������error: encoding 'nonexistend_encoding' was not found.
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-dir.txt�������������������������������������������������������������0000664�0000000�0000000�00000000127�14470675724�0020006�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;35mOnly in tests/b: d�[m
�[0;35mOnly in tests/b: i�[m
�[0;35mOnly in tests/a: j�[m
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-dn5.txt�������������������������������������������������������������0000664�0000000�0000000�00000001464�14470675724�0017723�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mleft�[m �[0;34mright�[m
�[1;32m#input, #button {�[m
�[1;32m width: 400px;�[m
�[1;32m height: 40px;�[m
�[1;32m font-size: 30px;�[m
�[1;32m margin: 0;�[m
�[1;32m padding: 0;�[m
�[1;32m text-align: center;�[m
�[1;32m}�[m
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-exclude.txt���������������������������������������������������������0000664�0000000�0000000�00000001116�14470675724�0020660�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4-cr.txt�[m �[0;34mtests/input-4-partial-cr.txt�[m
width: 350px; width: 350px;
height: 40px; height: 40px;
margin: 0px; margin: 0px;
margin-bottom: 15px; margin-bottom: 15px;
text-align: center;�[1;31m\r�[m text-align: center;
} }
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-exit-process-sub����������������������������������������������������0000664�0000000�0000000�00000000000�14470675724�0021614�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-file-not-found.txt��������������������������������������������������0000664�0000000�0000000�00000000067�14470675724�0022061�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;35merror: file 'nonexistent_file' was not found�[m
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-hide-cr-if-dos������������������������������������������������������0000664�0000000�0000000�00000001560�14470675724�0021106�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4-cr.txt�[m �[0;34mtests/input-5-cr.txt�[m
#input, #button { #input, #button {
width: �[1;33m35�[m0px; width: �[1;33m40�[m0px;
height: 40px; height: 40px;
�[1;32m font-size: 30px;�[m
margin: 0�[1;31mpx�[m; margin: 0;
padding: 0�[1;31mpx�[m; padding: 0;
�[1;31m margin-bottom: 15px;�[m
text-align: center; text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-identical-on.txt����������������������������������������������������0000664�0000000�0000000�00000000075�14470675724�0021600�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Files tests/input-1.txt and tests/input-1.txt are identical.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-no-cr-indent��������������������������������������������������������0000664�0000000�0000000�00000001236�14470675724�0020711�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4-cr.txt�[m �[0;34mtests/input-4-partial-cr.txt�[m
width: 350px; width: 350px;
height: 40px; height: 40px;
margin: 0px; margin: 0px;
padding: 0px; padding: 0px;
margin-bottom: 15px; margin-bottom: 15px;
text-align: center;�[1;31m\r�[m text-align: center;
} }
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-permissions-diff-binary.txt�����������������������������������������0000664�0000000�0000000�00000000454�14470675724�0023776�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/permissions-a�[m �[0;34mtests/permissions-b�[m
�[0;33m-rw-rw-rw- (100666)�[m �[0;33m-rw-rw-r-x (100665)�[m
�[1;31msome text�[m �[1;32m��[m
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-permissions-diff-text.txt�������������������������������������������0000664�0000000�0000000�00000000442�14470675724�0023473�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/permissions-a�[m �[0;34mtests/permissions-b�[m
�[0;33m-rw-rw-rw- (100666)�[m �[0;33m-rw-rw-r-x (100665)�[m
�[1;31msome text�[m
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-permissions-diff.txt������������������������������������������������0000664�0000000�0000000�00000000310�14470675724�0022503�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/permissions-a�[m �[0;34mtests/permissions-b�[m
�[0;33m-rw-rw-rw- (100666)�[m �[0;33m-rw-rw-r-x (100665)�[m
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-permissions-same.txt������������������������������������������������0000664�0000000�0000000�00000000000�14470675724�0022514�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-recursive-with-exclude.txt������������������������������������������0000664�0000000�0000000�00000000263�14470675724�0023640�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������error: file 'tests/b/1' not valid with encoding 'utf-8': at 4461-4462.
�[0;35mOnly in tests/b: d�[m
�[0;35mOnly in tests/b: i�[m
�[0;35mOnly in tests/a: j�[m
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-recursive-with-exclude2.txt�����������������������������������������0000664�0000000�0000000�00000001045�14470675724�0023721�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������error: file 'tests/test-with-exclude/b/1' not valid with encoding 'utf-8': at 4461-4462.
�[0;34mtests/test-with-exclude/a/c/f�[m �[0;34mtests/test-with-exclude/b/c/f�[m
�[1;31m2�[m �[1;32m3�[m
�[0;35mOnly in tests/test-with-exclude/b/c: g�[m
�[0;35mOnly in tests/test-with-exclude/b/c: h�[m
�[0;35mOnly in tests/test-with-exclude/b: d�[m
�[0;35mOnly in tests/test-with-exclude/b: i�[m
�[0;35mOnly in tests/test-with-exclude/a: j�[m
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-recursive.txt�������������������������������������������������������0000664�0000000�0000000�00000000671�14470675724�0021243�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������error: file 'tests/b/1' not valid with encoding 'utf-8': at 4461-4462.
�[0;34mtests/a/c/f�[m �[0;34mtests/b/c/f�[m
�[1;31m2�[m �[1;32m3�[m
�[0;35mOnly in tests/b/c: g�[m
�[0;35mOnly in tests/b/c: h�[m
�[0;35mOnly in tests/b: d�[m
�[0;35mOnly in tests/b: i�[m
�[0;35mOnly in tests/a: j�[m
�����������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-sas.txt�������������������������������������������������������������0000664�0000000�0000000�00000002016�14470675724�0020015�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-10.txt�[m �[0;34mtests/input-11.txt�[m
void main () void main ()
{ {
int x; int x;
int y; int y;
} }
�[1;32m�[m�[7;1;32m �[m�[1;32m�[m
�[1;32mvoid�[m�[7;1;32m �[m�[1;32mfoo�[m�[7;1;32m �[m�[1;32m()�[m
�[1;32m{�[m
�[1;32m�[m�[7;1;32m �[m�[1;32m�[m
�[1;32m}�[m
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-show-spaces.txt�����������������������������������������������������0000664�0000000�0000000�00000001666�14470675724�0021475�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-10.txt�[m �[0;34mtests/input-11.txt�[m
void main () void main ()
{ {
int x; int x;
int y; int y;
} }
�[7;32m �[m
�[1;32mvoid foo ()�[m
�[1;32m{�[m
�[7;32m �[m
�[1;32m}�[m
��������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-sns.txt�������������������������������������������������������������0000664�0000000�0000000�00000001666�14470675724�0020044�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-10.txt�[m �[0;34mtests/input-11.txt�[m
void main () void main ()
{ {
int x; int x;
int y; int y;
} }
�[0;32m �[m
�[1;32mvoid foo ()�[m
�[1;32m{�[m
�[0;32m �[m
�[1;32m}�[m
��������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-strip-cr-off.txt����������������������������������������������������0000664�0000000�0000000�00000001476�14470675724�0021553�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-4-cr.txt�[m
#input, #button { #input, #button {�[1;32m\r�[m
width: 350px; width: 350px;�[1;32m\r�[m
height: 40px; height: 40px;�[1;32m\r�[m
margin: 0px; margin: 0px;�[1;32m\r�[m
padding: 0px; padding: 0px;�[1;32m\r�[m
margin-bottom: 15px; margin-bottom: 15px;�[1;32m\r�[m
text-align: center; text-align: center;�[1;32m\r�[m
�[1;31m}�[m �[1;32m}\r�[m
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-strip-cr-on.txt�����������������������������������������������������0000664�0000000�0000000�00000000144�14470675724�0021404�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-4.txt�[m �[0;34mtests/input-4-cr.txt�[m
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-subcolors-bad-cat���������������������������������������������������0000664�0000000�0000000�00000000270�14470675724�0021715�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Invalid category 'chnge' in '--color-map="chnge:magenta,description:cyan_bold"'. Valid categories are: add, change, description, line-numbers, meta, permissions, separator, subtract.
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-subcolors-bad-color�������������������������������������������������0000664�0000000�0000000�00000000644�14470675724�0022271�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Invalid color 'mageta' in '--color-map="change:mageta,description:cyan_bold"'. Valid colors are: �[0;30mblack�[m, �[1;30mblack_bold�[m, �[0;34mblue�[m, �[1;34mblue_bold�[m, �[0;36mcyan�[m, �[1;36mcyan_bold�[m, �[0;32mgreen�[m, �[1;32mgreen_bold�[m, �[0;35mmagenta�[m, �[1;35mmagenta_bold�[m, �[mnone�[m, �[0;31mred�[m, �[1;31mred_bold�[m, �[0;37mwhite�[m, �[1;37mwhite_bold�[m, �[0;33myellow�[m, �[1;33myellow_bold�[m.
��������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-subcolors-bad-fmt���������������������������������������������������0000664�0000000�0000000�00000000660�14470675724�0021737�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Invalid color 'magenta:gold' in '--color-map="change:magenta:gold,description:cyan_bold"'. Valid colors are: �[0;30mblack�[m, �[1;30mblack_bold�[m, �[0;34mblue�[m, �[1;34mblue_bold�[m, �[0;36mcyan�[m, �[1;36mcyan_bold�[m, �[0;32mgreen�[m, �[1;32mgreen_bold�[m, �[0;35mmagenta�[m, �[1;35mmagenta_bold�[m, �[mnone�[m, �[0;31mred�[m, �[1;31mred_bold�[m, �[0;37mwhite�[m, �[1;37mwhite_bold�[m, �[0;33myellow�[m, �[1;33myellow_bold�[m.
��������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-tabs-4.txt����������������������������������������������������������0000664�0000000�0000000�00000000334�14470675724�0020322�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-8.txt�[m �[0;34mtests/input-9.txt�[m
a�[1;33mb�[mc d�[1;33me�[mf a�[1;33mQ�[mc d�[1;33mQ�[mf
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/gold-tabs-default.txt����������������������������������������������������0000664�0000000�0000000�00000000334�14470675724�0021603�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������[0;34mtests/input-8.txt�[m �[0;34mtests/input-9.txt�[m
a�[1;33mb�[mc d�[1;33me�[mf a�[1;33mQ�[mc d�[1;33mQ�[mf
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-1.txt��������������������������������������������������������������0000664�0000000�0000000�00000000246�14470675724�0017604�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������测试行abc测试测试行abc,测试测试行abc测试测试行abc测试测试行abc测试测试行abc测试测试行abc测试测试行abc测试测试行abc测试
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-10.txt�������������������������������������������������������������0000664�0000000�0000000�00000000043�14470675724�0017657�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������void main ()
{
int x;
int y;
}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-11.txt�������������������������������������������������������������0000664�0000000�0000000�00000000065�14470675724�0017664�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������void main ()
{
int x;
int y;
}
void foo ()
{
}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-2.txt��������������������������������������������������������������0000664�0000000�0000000�00000000246�14470675724�0017605�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������测试行adc测试测试行adc,测试测试行adc测试测试行adc测试测试行adc测试测试行adc测试测试行adc测试测试行adc测试测试行adc测试
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-3.txt��������������������������������������������������������������0000664�0000000�0000000�00000054375�14470675724�0017622�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������UTF-8 decoder capability and stress test
----------------------------------------
Markus Kuhn - 2015-08-28 - CC BY 4.0
This test file can help you examine, how your UTF-8 decoder handles
various types of correct, malformed, or otherwise interesting UTF-8
sequences. This file is not meant to be a conformance test. It does
not prescribe any particular outcome. Therefore, there is no way to
"pass" or "fail" this test file, even though the text does suggest a
preferable decoder behaviour at some places. Its aim is, instead, to
help you think about, and test, the behaviour of your UTF-8 decoder on a
systematic collection of unusual inputs. Experience so far suggests
that most first-time authors of UTF-8 decoders find at least one
serious problem in their decoder using this file.
The test lines below cover boundary conditions, malformed UTF-8
sequences, as well as correctly encoded UTF-8 sequences of Unicode code
points that should never occur in a correct UTF-8 file.
According to ISO 10646-1:2000, sections D.7 and 2.3c, a device
receiving UTF-8 shall interpret a "malformed sequence in the same way
that it interprets a character that is outside the adopted subset" and
"characters that are not within the adopted subset shall be indicated
to the user" by a receiving device. One commonly used approach in
UTF-8 decoders is to replace any malformed UTF-8 sequence by a
replacement character (U+FFFD), which looks a bit like an inverted
question mark, or a similar symbol. It might be a good idea to
visually distinguish a malformed UTF-8 sequence from a correctly
encoded Unicode character that is just not available in the current
font but otherwise fully legal, even though ISO 10646-1 doesn't
mandate this. In any case, just ignoring malformed sequences or
unavailable characters does not conform to ISO 10646, will make
debugging more difficult, and can lead to user confusion.
Please check, whether a malformed UTF-8 sequence is (1) represented at
all, (2) represented by exactly one single replacement character (or
equivalent signal), and (3) the following quotation mark after an
illegal UTF-8 sequence is correctly displayed, i.e. proper
resynchronization takes place immediately after any malformed
sequence. This file says "THE END" in the last line, so if you don't
see that, your decoder crashed somehow before, which should always be
cause for concern.
All lines in this file are exactly 79 characters long (plus the line
feed). In addition, all lines end with "|", except for the two test
lines 2.1.1 and 2.2.1, which contain non-printable ASCII controls
U+0000 and U+007F. If you display this file with a fixed-width font,
these "|" characters should all line up in column 79 (right margin).
This allows you to test quickly, whether your UTF-8 decoder finds the
correct number of characters in every line, that is whether each
malformed sequences is replaced by a single replacement character.
Note that, as an alternative to the notion of malformed sequence used
here, it is also a perfectly acceptable (and in some situations even
preferable) solution to represent each individual byte of a malformed
sequence with a replacement character. If you follow this strategy in
your decoder, then please ignore the "|" column.
Here come the tests: |
|
1 Some correct UTF-8 text |
|
You should see the Greek word 'kosme': "κόσμε" |
|
2 Boundary condition test cases |
|
2.1 First possible sequence of a certain length |
|
2.1.1 1 byte (U-00000000): "�"
2.1.2 2 bytes (U-00000080): "" |
2.1.3 3 bytes (U-00000800): "ࠀ" |
2.1.4 4 bytes (U-00010000): "𐀀" |
2.1.5 5 bytes (U-00200000): "�����" |
2.1.6 6 bytes (U-04000000): "������" |
|
2.2 Last possible sequence of a certain length |
|
2.2.1 1 byte (U-0000007F): ""
2.2.2 2 bytes (U-000007FF): "߿" |
2.2.3 3 bytes (U-0000FFFF): "" |
2.2.4 4 bytes (U-001FFFFF): "����" |
2.2.5 5 bytes (U-03FFFFFF): "�����" |
2.2.6 6 bytes (U-7FFFFFFF): "������" |
|
2.3 Other boundary conditions |
|
2.3.1 U-0000D7FF = ed 9f bf = "" |
2.3.2 U-0000E000 = ee 80 80 = "" |
2.3.3 U-0000FFFD = ef bf bd = "�" |
2.3.4 U-0010FFFF = f4 8f bf bf = "" |
2.3.5 U-00110000 = f4 90 80 80 = "����" |
|
3 Malformed sequences |
|
3.1 Unexpected continuation bytes |
|
Each unexpected continuation byte should be separately signalled as a |
malformed sequence of its own. |
|
3.1.1 First continuation byte 0x80: "�" |
3.1.2 Last continuation byte 0xbf: "�" |
|
3.1.3 2 continuation bytes: "��" |
3.1.4 3 continuation bytes: "���" |
3.1.5 4 continuation bytes: "����" |
3.1.6 5 continuation bytes: "�����" |
3.1.7 6 continuation bytes: "������" |
3.1.8 7 continuation bytes: "�������" |
|
3.1.9 Sequence of all 64 possible continuation bytes (0x80-0xbf): |
|
"���������������� |
���������������� |
���������������� |
����������������" |
|
3.2 Lonely start characters |
|
3.2.1 All 32 first bytes of 2-byte sequences (0xc0-0xdf), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � |
� � � � � � � � � � � � � � � � " |
|
3.2.2 All 16 first bytes of 3-byte sequences (0xe0-0xef), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � " |
|
3.2.3 All 8 first bytes of 4-byte sequences (0xf0-0xf7), |
each followed by a space character: |
|
"� � � � � � � � " |
|
3.2.4 All 4 first bytes of 5-byte sequences (0xf8-0xfb), |
each followed by a space character: |
|
"� � � � " |
|
3.2.5 All 2 first bytes of 6-byte sequences (0xfc-0xfd), |
each followed by a space character: |
|
"� � " |
|
3.3 Sequences with last continuation byte missing |
|
All bytes of an incomplete sequence should be signalled as a single |
malformed sequence, i.e., you should see only a single replacement |
character in each of the next 10 tests. (Characters as in section 2) |
|
3.3.1 2-byte sequence with last byte missing (U+0000): "�" |
3.3.2 3-byte sequence with last byte missing (U+0000): "��" |
3.3.3 4-byte sequence with last byte missing (U+0000): "���" |
3.3.4 5-byte sequence with last byte missing (U+0000): "����" |
3.3.5 6-byte sequence with last byte missing (U+0000): "�����" |
3.3.6 2-byte sequence with last byte missing (U-000007FF): "�" |
3.3.7 3-byte sequence with last byte missing (U-0000FFFF): "�" |
3.3.8 4-byte sequence with last byte missing (U-001FFFFF): "���" |
3.3.9 5-byte sequence with last byte missing (U-03FFFFFF): "����" |
3.3.10 6-byte sequence with last byte missing (U-7FFFFFFF): "�����" |
|
3.4 Concatenation of incomplete sequences |
|
All the 10 sequences of 3.3 concatenated, you should see 10 malformed |
sequences being signalled: |
|
"�����������������������������" |
|
3.5 Impossible bytes |
|
The following two bytes cannot appear in a correct UTF-8 string |
|
3.5.1 fe = "�" |
3.5.2 ff = "�" |
3.5.3 fe fe ff ff = "����" |
|
4 Overlong sequences |
|
The following sequences are not malformed according to the letter of |
the Unicode 2.0 standard. However, they are longer then necessary and |
a correct UTF-8 encoder is not allowed to produce them. A "safe UTF-8 |
decoder" should reject them just like malformed sequences for two |
reasons: (1) It helps to debug applications if overlong sequences are |
not treated as valid representations of characters, because this helps |
to spot problems more quickly. (2) Overlong sequences provide |
alternative representations of characters, that could maliciously be |
used to bypass filters that check only for ASCII characters. For |
instance, a 2-byte encoded line feed (LF) would not be caught by a |
line counter that counts only 0x0a bytes, but it would still be |
processed as a line feed by an unsafe UTF-8 decoder later in the |
pipeline. From a security point of view, ASCII compatibility of UTF-8 |
sequences means also, that ASCII characters are *only* allowed to be |
represented by ASCII bytes in the range 0x00-0x7f. To ensure this |
aspect of ASCII compatibility, use only "safe UTF-8 decoders" that |
reject overlong UTF-8 sequences for which a shorter encoding exists. |
|
4.1 Examples of an overlong ASCII character |
|
With a safe UTF-8 decoder, all of the following five overlong |
representations of the ASCII character slash ("/") should be rejected |
like a malformed UTF-8 sequence, for instance by substituting it with |
a replacement character. If you see a slash below, you do not have a |
safe UTF-8 decoder! |
|
4.1.1 U+002F = c0 af = "��" |
4.1.2 U+002F = e0 80 af = "���" |
4.1.3 U+002F = f0 80 80 af = "����" |
4.1.4 U+002F = f8 80 80 80 af = "�����" |
4.1.5 U+002F = fc 80 80 80 80 af = "������" |
|
4.2 Maximum overlong sequences |
|
Below you see the highest Unicode value that is still resulting in an |
overlong sequence if represented with the given number of bytes. This |
is a boundary test for safe UTF-8 decoders. All five characters should |
be rejected like malformed UTF-8 sequences. |
|
4.2.1 U-0000007F = c1 bf = "��" |
4.2.2 U-000007FF = e0 9f bf = "���" |
4.2.3 U-0000FFFF = f0 8f bf bf = "����" |
4.2.4 U-001FFFFF = f8 87 bf bf bf = "�����" |
4.2.5 U-03FFFFFF = fc 83 bf bf bf bf = "������" |
|
4.3 Overlong representation of the NUL character |
|
The following five sequences should also be rejected like malformed |
UTF-8 sequences and should not be treated like the ASCII NUL |
character. |
|
4.3.1 U+0000 = c0 80 = "��" |
4.3.2 U+0000 = e0 80 80 = "���" |
4.3.3 U+0000 = f0 80 80 80 = "����" |
4.3.4 U+0000 = f8 80 80 80 80 = "�����" |
4.3.5 U+0000 = fc 80 80 80 80 80 = "������" |
|
5 Illegal code positions |
|
The following UTF-8 sequences should be rejected like malformed |
sequences, because they never represent valid ISO 10646 characters and |
a UTF-8 decoder that accepts them might introduce security problems |
comparable to overlong UTF-8 sequences. |
|
5.1 Single UTF-16 surrogates |
|
5.1.1 U+D800 = ed a0 80 = "���" |
5.1.2 U+DB7F = ed ad bf = "���" |
5.1.3 U+DB80 = ed ae 80 = "���" |
5.1.4 U+DBFF = ed af bf = "���" |
5.1.5 U+DC00 = ed b0 80 = "���" |
5.1.6 U+DF80 = ed be 80 = "���" |
5.1.7 U+DFFF = ed bf bf = "���" |
|
5.2 Paired UTF-16 surrogates |
|
5.2.1 U+D800 U+DC00 = ed a0 80 ed b0 80 = "������" |
5.2.2 U+D800 U+DFFF = ed a0 80 ed bf bf = "������" |
5.2.3 U+DB7F U+DC00 = ed ad bf ed b0 80 = "������" |
5.2.4 U+DB7F U+DFFF = ed ad bf ed bf bf = "������" |
5.2.5 U+DB80 U+DC00 = ed ae 80 ed b0 80 = "������" |
5.2.6 U+DB80 U+DFFF = ed ae 80 ed bf bf = "������" |
5.2.7 U+DBFF U+DC00 = ed af bf ed b0 80 = "������" |
5.2.8 U+DBFF U+DFFF = ed af bf ed bf bf = "������" |
|
5.3 Noncharacter code positions |
|
The following "noncharacters" are "reserved for internal use" by |
applications, and according to older versions of the Unicode Standard |
"should never be interchanged". Unicode Corrigendum #9 dropped the |
latter restriction. Nevertheless, their presence in incoming UTF-8 data |
can remain a potential security risk, depending on what use is made of |
these codes subsequently. Examples of such internal use: |
|
- Some file APIs with 16-bit characters may use the integer value -1 |
= U+FFFF to signal an end-of-file (EOF) or error condition. |
|
- In some UTF-16 receivers, code point U+FFFE might trigger a |
byte-swap operation (to convert between UTF-16LE and UTF-16BE). |
|
With such internal use of noncharacters, it may be desirable and safer |
to block those code points in UTF-8 decoders, as they should never |
occur legitimately in incoming UTF-8 data, and could trigger unsafe |
behaviour in subsequent processing. |
|
Particularly problematic noncharacters in 16-bit applications: |
|
5.3.1 U+FFFE = ef bf be = "" |
5.3.2 U+FFFF = ef bf bf = "" |
|
Other noncharacters: |
|
5.3.3 U+FDD0 .. U+FDEF = ""|
|
5.3.4 U+nFFFE U+nFFFF (for n = 1..10) |
|
" |
" |
|
THE END |
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-4-cr.txt�����������������������������������������������������������0000664�0000000�0000000�00000000210�14470675724�0020200�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button {
width: 350px;
height: 40px;
margin: 0px;
padding: 0px;
margin-bottom: 15px;
text-align: center;
}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-4-partial-cr.txt���������������������������������������������������0000664�0000000�0000000�00000000207�14470675724�0021640�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button {
width: 350px;
height: 40px;
margin: 0px;
padding: 0px;
margin-bottom: 15px;
text-align: center;
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-4.txt��������������������������������������������������������������0000664�0000000�0000000�00000000200�14470675724�0017575�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button {
width: 350px;
height: 40px;
margin: 0px;
padding: 0px;
margin-bottom: 15px;
text-align: center;
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-5-cr.txt�����������������������������������������������������������0000664�0000000�0000000�00000000200�14470675724�0020200�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button {
width: 400px;
height: 40px;
font-size: 30px;
margin: 0;
padding: 0;
text-align: center;
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-5.txt��������������������������������������������������������������0000664�0000000�0000000�00000000170�14470675724�0017604�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#input, #button {
width: 400px;
height: 40px;
font-size: 30px;
margin: 0;
padding: 0;
text-align: center;
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-6.txt��������������������������������������������������������������0000664�0000000�0000000�00000000064�14470675724�0017607�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
z
w
x
y
z
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-7.txt��������������������������������������������������������������0000664�0000000�0000000�00000000070�14470675724�0017605�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������a
b
c
d
e
f
g
h
i
j
k
l
m
m
m
n
o
p
q
r
s
t
u
z
w
x
y
z
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-8.txt��������������������������������������������������������������0000664�0000000�0000000�00000000011�14470675724�0017601�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������ abc def
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/input-9.txt��������������������������������������������������������������0000664�0000000�0000000�00000000011�14470675724�0017602�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������ aQc dQf
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/�������������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021123�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/�����������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021343�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/1����������������������������������������������������0000664�0000000�0000000�00000000000�14470675724�0021414�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/c/���������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021565�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/c/e��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021724�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������1
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/c/f��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021725�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������2
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/exclude/���������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0022774�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/exclude/text.txt�������������������������������������0000664�0000000�0000000�00000000013�14470675724�0024513�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������excluded a
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/a/j����������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021507�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������7
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/�����������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021344�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/1����������������������������������������������������0000664�0000000�0000000�00000054375�14470675724�0021445�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������UTF-8 decoder capability and stress test
----------------------------------------
Markus Kuhn - 2015-08-28 - CC BY 4.0
This test file can help you examine, how your UTF-8 decoder handles
various types of correct, malformed, or otherwise interesting UTF-8
sequences. This file is not meant to be a conformance test. It does
not prescribe any particular outcome. Therefore, there is no way to
"pass" or "fail" this test file, even though the text does suggest a
preferable decoder behaviour at some places. Its aim is, instead, to
help you think about, and test, the behaviour of your UTF-8 decoder on a
systematic collection of unusual inputs. Experience so far suggests
that most first-time authors of UTF-8 decoders find at least one
serious problem in their decoder using this file.
The test lines below cover boundary conditions, malformed UTF-8
sequences, as well as correctly encoded UTF-8 sequences of Unicode code
points that should never occur in a correct UTF-8 file.
According to ISO 10646-1:2000, sections D.7 and 2.3c, a device
receiving UTF-8 shall interpret a "malformed sequence in the same way
that it interprets a character that is outside the adopted subset" and
"characters that are not within the adopted subset shall be indicated
to the user" by a receiving device. One commonly used approach in
UTF-8 decoders is to replace any malformed UTF-8 sequence by a
replacement character (U+FFFD), which looks a bit like an inverted
question mark, or a similar symbol. It might be a good idea to
visually distinguish a malformed UTF-8 sequence from a correctly
encoded Unicode character that is just not available in the current
font but otherwise fully legal, even though ISO 10646-1 doesn't
mandate this. In any case, just ignoring malformed sequences or
unavailable characters does not conform to ISO 10646, will make
debugging more difficult, and can lead to user confusion.
Please check, whether a malformed UTF-8 sequence is (1) represented at
all, (2) represented by exactly one single replacement character (or
equivalent signal), and (3) the following quotation mark after an
illegal UTF-8 sequence is correctly displayed, i.e. proper
resynchronization takes place immediately after any malformed
sequence. This file says "THE END" in the last line, so if you don't
see that, your decoder crashed somehow before, which should always be
cause for concern.
All lines in this file are exactly 79 characters long (plus the line
feed). In addition, all lines end with "|", except for the two test
lines 2.1.1 and 2.2.1, which contain non-printable ASCII controls
U+0000 and U+007F. If you display this file with a fixed-width font,
these "|" characters should all line up in column 79 (right margin).
This allows you to test quickly, whether your UTF-8 decoder finds the
correct number of characters in every line, that is whether each
malformed sequences is replaced by a single replacement character.
Note that, as an alternative to the notion of malformed sequence used
here, it is also a perfectly acceptable (and in some situations even
preferable) solution to represent each individual byte of a malformed
sequence with a replacement character. If you follow this strategy in
your decoder, then please ignore the "|" column.
Here come the tests: |
|
1 Some correct UTF-8 text |
|
You should see the Greek word 'kosme': "κόσμε" |
|
2 Boundary condition test cases |
|
2.1 First possible sequence of a certain length |
|
2.1.1 1 byte (U-00000000): "�"
2.1.2 2 bytes (U-00000080): "" |
2.1.3 3 bytes (U-00000800): "ࠀ" |
2.1.4 4 bytes (U-00010000): "𐀀" |
2.1.5 5 bytes (U-00200000): "�����" |
2.1.6 6 bytes (U-04000000): "������" |
|
2.2 Last possible sequence of a certain length |
|
2.2.1 1 byte (U-0000007F): ""
2.2.2 2 bytes (U-000007FF): "߿" |
2.2.3 3 bytes (U-0000FFFF): "" |
2.2.4 4 bytes (U-001FFFFF): "����" |
2.2.5 5 bytes (U-03FFFFFF): "�����" |
2.2.6 6 bytes (U-7FFFFFFF): "������" |
|
2.3 Other boundary conditions |
|
2.3.1 U-0000D7FF = ed 9f bf = "" |
2.3.2 U-0000E000 = ee 80 80 = "" |
2.3.3 U-0000FFFD = ef bf bd = "�" |
2.3.4 U-0010FFFF = f4 8f bf bf = "" |
2.3.5 U-00110000 = f4 90 80 80 = "����" |
|
3 Malformed sequences |
|
3.1 Unexpected continuation bytes |
|
Each unexpected continuation byte should be separately signalled as a |
malformed sequence of its own. |
|
3.1.1 First continuation byte 0x80: "�" |
3.1.2 Last continuation byte 0xbf: "�" |
|
3.1.3 2 continuation bytes: "��" |
3.1.4 3 continuation bytes: "���" |
3.1.5 4 continuation bytes: "����" |
3.1.6 5 continuation bytes: "�����" |
3.1.7 6 continuation bytes: "������" |
3.1.8 7 continuation bytes: "�������" |
|
3.1.9 Sequence of all 64 possible continuation bytes (0x80-0xbf): |
|
"���������������� |
���������������� |
���������������� |
����������������" |
|
3.2 Lonely start characters |
|
3.2.1 All 32 first bytes of 2-byte sequences (0xc0-0xdf), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � |
� � � � � � � � � � � � � � � � " |
|
3.2.2 All 16 first bytes of 3-byte sequences (0xe0-0xef), |
each followed by a space character: |
|
"� � � � � � � � � � � � � � � � " |
|
3.2.3 All 8 first bytes of 4-byte sequences (0xf0-0xf7), |
each followed by a space character: |
|
"� � � � � � � � " |
|
3.2.4 All 4 first bytes of 5-byte sequences (0xf8-0xfb), |
each followed by a space character: |
|
"� � � � " |
|
3.2.5 All 2 first bytes of 6-byte sequences (0xfc-0xfd), |
each followed by a space character: |
|
"� � " |
|
3.3 Sequences with last continuation byte missing |
|
All bytes of an incomplete sequence should be signalled as a single |
malformed sequence, i.e., you should see only a single replacement |
character in each of the next 10 tests. (Characters as in section 2) |
|
3.3.1 2-byte sequence with last byte missing (U+0000): "�" |
3.3.2 3-byte sequence with last byte missing (U+0000): "��" |
3.3.3 4-byte sequence with last byte missing (U+0000): "���" |
3.3.4 5-byte sequence with last byte missing (U+0000): "����" |
3.3.5 6-byte sequence with last byte missing (U+0000): "�����" |
3.3.6 2-byte sequence with last byte missing (U-000007FF): "�" |
3.3.7 3-byte sequence with last byte missing (U-0000FFFF): "�" |
3.3.8 4-byte sequence with last byte missing (U-001FFFFF): "���" |
3.3.9 5-byte sequence with last byte missing (U-03FFFFFF): "����" |
3.3.10 6-byte sequence with last byte missing (U-7FFFFFFF): "�����" |
|
3.4 Concatenation of incomplete sequences |
|
All the 10 sequences of 3.3 concatenated, you should see 10 malformed |
sequences being signalled: |
|
"�����������������������������" |
|
3.5 Impossible bytes |
|
The following two bytes cannot appear in a correct UTF-8 string |
|
3.5.1 fe = "�" |
3.5.2 ff = "�" |
3.5.3 fe fe ff ff = "����" |
|
4 Overlong sequences |
|
The following sequences are not malformed according to the letter of |
the Unicode 2.0 standard. However, they are longer then necessary and |
a correct UTF-8 encoder is not allowed to produce them. A "safe UTF-8 |
decoder" should reject them just like malformed sequences for two |
reasons: (1) It helps to debug applications if overlong sequences are |
not treated as valid representations of characters, because this helps |
to spot problems more quickly. (2) Overlong sequences provide |
alternative representations of characters, that could maliciously be |
used to bypass filters that check only for ASCII characters. For |
instance, a 2-byte encoded line feed (LF) would not be caught by a |
line counter that counts only 0x0a bytes, but it would still be |
processed as a line feed by an unsafe UTF-8 decoder later in the |
pipeline. From a security point of view, ASCII compatibility of UTF-8 |
sequences means also, that ASCII characters are *only* allowed to be |
represented by ASCII bytes in the range 0x00-0x7f. To ensure this |
aspect of ASCII compatibility, use only "safe UTF-8 decoders" that |
reject overlong UTF-8 sequences for which a shorter encoding exists. |
|
4.1 Examples of an overlong ASCII character |
|
With a safe UTF-8 decoder, all of the following five overlong |
representations of the ASCII character slash ("/") should be rejected |
like a malformed UTF-8 sequence, for instance by substituting it with |
a replacement character. If you see a slash below, you do not have a |
safe UTF-8 decoder! |
|
4.1.1 U+002F = c0 af = "��" |
4.1.2 U+002F = e0 80 af = "���" |
4.1.3 U+002F = f0 80 80 af = "����" |
4.1.4 U+002F = f8 80 80 80 af = "�����" |
4.1.5 U+002F = fc 80 80 80 80 af = "������" |
|
4.2 Maximum overlong sequences |
|
Below you see the highest Unicode value that is still resulting in an |
overlong sequence if represented with the given number of bytes. This |
is a boundary test for safe UTF-8 decoders. All five characters should |
be rejected like malformed UTF-8 sequences. |
|
4.2.1 U-0000007F = c1 bf = "��" |
4.2.2 U-000007FF = e0 9f bf = "���" |
4.2.3 U-0000FFFF = f0 8f bf bf = "����" |
4.2.4 U-001FFFFF = f8 87 bf bf bf = "�����" |
4.2.5 U-03FFFFFF = fc 83 bf bf bf bf = "������" |
|
4.3 Overlong representation of the NUL character |
|
The following five sequences should also be rejected like malformed |
UTF-8 sequences and should not be treated like the ASCII NUL |
character. |
|
4.3.1 U+0000 = c0 80 = "��" |
4.3.2 U+0000 = e0 80 80 = "���" |
4.3.3 U+0000 = f0 80 80 80 = "����" |
4.3.4 U+0000 = f8 80 80 80 80 = "�����" |
4.3.5 U+0000 = fc 80 80 80 80 80 = "������" |
|
5 Illegal code positions |
|
The following UTF-8 sequences should be rejected like malformed |
sequences, because they never represent valid ISO 10646 characters and |
a UTF-8 decoder that accepts them might introduce security problems |
comparable to overlong UTF-8 sequences. |
|
5.1 Single UTF-16 surrogates |
|
5.1.1 U+D800 = ed a0 80 = "���" |
5.1.2 U+DB7F = ed ad bf = "���" |
5.1.3 U+DB80 = ed ae 80 = "���" |
5.1.4 U+DBFF = ed af bf = "���" |
5.1.5 U+DC00 = ed b0 80 = "���" |
5.1.6 U+DF80 = ed be 80 = "���" |
5.1.7 U+DFFF = ed bf bf = "���" |
|
5.2 Paired UTF-16 surrogates |
|
5.2.1 U+D800 U+DC00 = ed a0 80 ed b0 80 = "������" |
5.2.2 U+D800 U+DFFF = ed a0 80 ed bf bf = "������" |
5.2.3 U+DB7F U+DC00 = ed ad bf ed b0 80 = "������" |
5.2.4 U+DB7F U+DFFF = ed ad bf ed bf bf = "������" |
5.2.5 U+DB80 U+DC00 = ed ae 80 ed b0 80 = "������" |
5.2.6 U+DB80 U+DFFF = ed ae 80 ed bf bf = "������" |
5.2.7 U+DBFF U+DC00 = ed af bf ed b0 80 = "������" |
5.2.8 U+DBFF U+DFFF = ed af bf ed bf bf = "������" |
|
5.3 Noncharacter code positions |
|
The following "noncharacters" are "reserved for internal use" by |
applications, and according to older versions of the Unicode Standard |
"should never be interchanged". Unicode Corrigendum #9 dropped the |
latter restriction. Nevertheless, their presence in incoming UTF-8 data |
can remain a potential security risk, depending on what use is made of |
these codes subsequently. Examples of such internal use: |
|
- Some file APIs with 16-bit characters may use the integer value -1 |
= U+FFFF to signal an end-of-file (EOF) or error condition. |
|
- In some UTF-16 receivers, code point U+FFFE might trigger a |
byte-swap operation (to convert between UTF-16LE and UTF-16BE). |
|
With such internal use of noncharacters, it may be desirable and safer |
to block those code points in UTF-8 decoders, as they should never |
occur legitimately in incoming UTF-8 data, and could trigger unsafe |
behaviour in subsequent processing. |
|
Particularly problematic noncharacters in 16-bit applications: |
|
5.3.1 U+FFFE = ef bf be = "" |
5.3.2 U+FFFF = ef bf bf = "" |
|
Other noncharacters: |
|
5.3.3 U+FDD0 .. U+FDEF = ""|
|
5.3.4 U+nFFFE U+nFFFF (for n = 1..10) |
|
" |
" |
|
THE END |
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/c/���������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021566�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/c/e��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021725�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������1
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/c/f��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021726�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������3
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/c/g��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021727�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������4
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/c/h��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021730�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������5
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/d/���������������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0021567�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/d/q��������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021742�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������9
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/exclude/���������������������������������������������0000775�0000000�0000000�00000000000�14470675724�0022775�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/exclude/text.txt�������������������������������������0000664�0000000�0000000�00000000013�14470675724�0024514�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������excluded b
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������icdiff-release-2.0.7/tests/test-with-exclude/b/i����������������������������������������������������0000664�0000000�0000000�00000000002�14470675724�0021507�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������6
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������