pax_global_header�����������������������������������������������������������������������������������0000666�0000000�0000000�00000000064�12412610011�0014476�g����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������52 comment=25bd677f20c0b964d33e8cce1299287f872619f5
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/������������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0013400�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/.gitignore��������������������������������������������������������������������������0000664�0000000�0000000�00000000014�12412610011�0015363�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Make.helper
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/CMakeLists.txt����������������������������������������������������������������������0000664�0000000�0000000�00000006603�12412610011�0016145�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������cmake_minimum_required(VERSION 2.8.7)
set(CMAKE_MODULE_PATH "${CMAKE_CURRENT_SOURCE_DIR}/CMakeModules")
include(AppendCompilerFlags)
## Project information ##
project(sdsl CXX C)
set(PROJECT_VENDOR "Simon Gog")
set(PROJECT_CONTACT "simon.gog@gmail.com")
set(PROJECT_URL "https://github.com/simongog/sdsl-lite")
set(PROJECT_DESCRIPTION "SDSL: Succinct Data Structure Library")
set(CMAKE_BUILD_TYPE "Release")
file(READ "${CMAKE_CURRENT_SOURCE_DIR}/VERSION" PROJECT_VERSION_FULL)
string(REGEX REPLACE "[\n\r]" "" PROJECT_VERSION_FULL "${PROJECT_VERSION_FULL}")
string(REGEX REPLACE "^([0-9]+)\\.[0-9]+\\.[0-9]+$" "\\1" PROJECT_VERSION_MAJOR "${PROJECT_VERSION_FULL}")
string(REGEX REPLACE "^[0-9]+\\.([0-9]+)\\.[0-9]+$" "\\1" PROJECT_VERSION_MINOR "${PROJECT_VERSION_FULL}")
string(REGEX REPLACE "^[0-9]+\\.[0-9]+\\.([0-9]+)$" "\\1" PROJECT_VERSION_PATCH "${PROJECT_VERSION_FULL}")
set(PROJECT_VERSION "${PROJECT_VERSION_MAJOR}.${PROJECT_VERSION_MINOR}")
math(EXPR LIBRARY_VERSION_MAJOR "1 + ${PROJECT_VERSION_MAJOR}")
set(LIBRARY_VERSION_MINOR "${PROJECT_VERSION_MINOR}")
set(LIBRARY_VERSION_PATCH "${PROJECT_VERSION_PATCH}")
set(LIBRARY_VERSION "${LIBRARY_VERSION_MAJOR}.${LIBRARY_VERSION_MINOR}")
set(LIBRARY_VERSION_FULL "${LIBRARY_VERSION}.${LIBRARY_VERSION_PATCH}")
option(CODE_COVERAGE "Set ON to add code coverage compile options" OFF)
# C++11 compiler Check
if(NOT CMAKE_CXX_COMPILER_VERSION) # work around for cmake versions smaller than 2.8.10
execute_process(COMMAND ${CMAKE_CXX_COMPILER} -dumpversion OUTPUT_VARIABLE CMAKE_CXX_COMPILER_VERSION)
endif()
if(CMAKE_CXX_COMPILER MATCHES ".*clang" OR CMAKE_CXX_COMPILER_ID STREQUAL "Clang")
set(CMAKE_COMPILER_IS_CLANGXX 1)
endif()
if( (CMAKE_COMPILER_IS_GNUCXX AND ${CMAKE_CXX_COMPILER_VERSION} VERSION_LESS 4.7) OR
(CMAKE_COMPILER_IS_CLANGXX AND ${CMAKE_CXX_COMPILER_VERSION} VERSION_LESS 3.2))
message(FATAL_ERROR "Your C++ compiler does not support C++11. Please install g++ 4.7 (or greater) or clang 3.2 (or greater)")
else()
message(STATUS "Compiler is recent enough to support C++11.")
endif()
if( CMAKE_COMPILER_IS_GNUCXX )
append_cxx_compiler_flags("-std=c++11 -Wall -Wextra -DNDEBUG" "GCC" CMAKE_CXX_FLAGS)
append_cxx_compiler_flags("-O3 -ffast-math -funroll-loops" "GCC" CMAKE_CXX_OPT_FLAGS)
if ( CODE_COVERAGE )
append_cxx_compiler_flags("-g -fprofile-arcs -ftest-coverage -lgcov" "GCC" CMAKE_CXX_FLAGS)
endif()
else()
append_cxx_compiler_flags("-std=c++11 -DNDEBUG" "CLANG" CMAKE_CXX_FLAGS)
append_cxx_compiler_flags("-stdlib=libc++" "CLANG" CMAKE_CXX_FLAGS)
append_cxx_compiler_flags("-O3 -ffast-math -funroll-loops" "CLANG" CMAKE_CXX_OPT_FLAGS)
endif()
include(CheckSSE4_2)
if( BUILTIN_POPCNT )
if( CMAKE_COMPILER_IS_GNUCXX )
append_cxx_compiler_flags("-msse4.2" "GCC" CMAKE_CXX_OPT_FLAGS)
else()
append_cxx_compiler_flags("-msse4.2" "CLANG" CMAKE_CXX_OPT_FLAGS)
endif()
endif()
add_subdirectory(external)
add_subdirectory(include)
add_subdirectory(lib)
configure_file("${CMAKE_CURRENT_SOURCE_DIR}/Make.helper.cmake"
"${CMAKE_CURRENT_SOURCE_DIR}/Make.helper" @ONLY)
## Add 'uninstall' target ##
CONFIGURE_FILE(
"${CMAKE_CURRENT_SOURCE_DIR}/CMakeModules/cmake_uninstall.cmake.in"
"${CMAKE_CURRENT_BINARY_DIR}/CMakeModules/cmake_uninstall.cmake"
IMMEDIATE @ONLY)
ADD_CUSTOM_TARGET(uninstall
"${CMAKE_COMMAND}" -P "${CMAKE_CURRENT_BINARY_DIR}/CMakeModules/cmake_uninstall.cmake")
�����������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/CMakeModules/�����������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0015711�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/CMakeModules/AppendCompilerFlags.cmake����������������������������������������������0000664�0000000�0000000�00000003066�12412610011�0022577�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include(CheckCSourceCompiles)
include(CheckCXXSourceCompiles)
macro(append_c_compiler_flags _flags _name _result)
set(SAFE_CMAKE_REQUIRED_FLAGS ${CMAKE_REQUIRED_FLAGS})
string(REGEX REPLACE "[-+/ ]" "_" cname "${_name}")
string(TOUPPER "${cname}" cname)
foreach(flag ${_flags})
string(REGEX REPLACE "^[-+/ ]+(.*)[-+/ ]*$" "\\1" flagname "${flag}")
string(REGEX REPLACE "[-+/ ]" "_" flagname "${flagname}")
string(TOUPPER "${flagname}" flagname)
set(have_flag "HAVE_${cname}_${flagname}")
set(CMAKE_REQUIRED_FLAGS "${flag}")
check_c_source_compiles("int main() { return 0; }" ${have_flag})
if(${have_flag})
set(${_result} "${${_result}} ${flag}")
endif(${have_flag})
endforeach(flag)
set(CMAKE_REQUIRED_FLAGS ${SAFE_CMAKE_REQUIRED_FLAGS})
endmacro(append_c_compiler_flags)
macro(append_cxx_compiler_flags _flags _name _result)
set(SAFE_CMAKE_REQUIRED_FLAGS ${CMAKE_REQUIRED_FLAGS})
string(REGEX REPLACE "[-+/ ]" "_" cname "${_name}")
string(TOUPPER "${cname}" cname)
foreach(flag ${_flags})
string(REGEX REPLACE "^[-+/ ]+(.*)[-+/ ]*$" "\\1" flagname "${flag}")
string(REGEX REPLACE "[-+/ ]" "_" flagname "${flagname}")
string(TOUPPER "${flagname}" flagname)
set(have_flag "HAVE_${cname}_${flagname}")
set(CMAKE_REQUIRED_FLAGS "${flag}")
check_cxx_source_compiles("int main() { return 0; }" ${have_flag})
if(${have_flag})
set(${_result} "${${_result}} ${flag}")
endif(${have_flag})
endforeach(flag)
set(CMAKE_REQUIRED_FLAGS ${SAFE_CMAKE_REQUIRED_FLAGS})
endmacro(append_cxx_compiler_flags)
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/CMakeModules/CheckSSE4_2.cmake������������������������������������������������������0000664�0000000�0000000�00000001657�12412610011�0020621�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Check if the CPU provides fast operations
# for popcount, leftmost and rightmost bit
set(BUILTIN_POPCNT 0)
# Check if we are on a Linux system
if(CMAKE_SYSTEM_NAME STREQUAL "Linux")
# Use /proc/cpuinfo to get the information
file(STRINGS "/proc/cpuinfo" _cpuinfo)
if(_cpuinfo MATCHES "(sse4_2)|(sse4a)")
set(BUILTIN_POPCNT 1)
endif()
elseif(CMAKE_SYSTEM_NAME STREQUAL "Windows")
# handle windows
# get_filename_component(_vendor_id "[HKEY_LOCAL_MACHINE\\Hardware\\Description\\System\\CentralProcessor\\0;VendorIdentifier]" NAME CACHE)
# get_filename_component(_cpu_id "[HKEY_LOCAL_MACHINE\\Hardware\\Description\\System\\CentralProcessor\\0;Identifier]" NAME CACHE)
elseif(CMAKE_SYSTEM_NAME STREQUAL "Darwin")
# handle MacOs
execute_process(COMMAND sysctl -n machdep.cpu.features
OUTPUT_VARIABLE _cpuinfo OUTPUT_STRIP_TRAILING_WHITESPACE)
if(_cpuinfo MATCHES "SSE4.2")
set(BUILTIN_POPCNT 1)
endif()
endif()
���������������������������������������������������������������������������������sdsl-lite-2.0.3/CMakeModules/cmake_uninstall.cmake.in�����������������������������������������������0000664�0000000�0000000�00000002467�12412610011�0022502�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������IF(NOT EXISTS "@CMAKE_CURRENT_BINARY_DIR@/install_manifest.txt")
MESSAGE(FATAL_ERROR "Cannot find install manifest: \"@CMAKE_CURRENT_BINARY_DIR@/install_manifest.txt\"")
ENDIF(NOT EXISTS "@CMAKE_CURRENT_BINARY_DIR@/install_manifest.txt")
FILE(READ "@CMAKE_CURRENT_BINARY_DIR@/install_manifest.txt" files)
STRING(REGEX REPLACE "\n" ";" files "${files}")
SET(NUM 0)
FOREACH(file ${files})
IF(EXISTS "$ENV{DESTDIR}${file}")
MESSAGE(STATUS "Looking for \"$ENV{DESTDIR}${file}\" - found")
SET(UNINSTALL_CHECK_${NUM} 1)
ELSE(EXISTS "$ENV{DESTDIR}${file}")
MESSAGE(STATUS "Looking for \"$ENV{DESTDIR}${file}\" - not found")
SET(UNINSTALL_CHECK_${NUM} 0)
ENDIF(EXISTS "$ENV{DESTDIR}${file}")
MATH(EXPR NUM "1 + ${NUM}")
ENDFOREACH(file)
SET(NUM 0)
FOREACH(file ${files})
IF(${UNINSTALL_CHECK_${NUM}})
MESSAGE(STATUS "Uninstalling \"$ENV{DESTDIR}${file}\"")
EXEC_PROGRAM(
"@CMAKE_COMMAND@" ARGS "-E remove \"$ENV{DESTDIR}${file}\""
OUTPUT_VARIABLE rm_out
RETURN_VALUE rm_retval
)
IF(NOT "${rm_retval}" STREQUAL 0)
MESSAGE(FATAL_ERROR "Problem when removing \"$ENV{DESTDIR}${file}\"")
ENDIF(NOT "${rm_retval}" STREQUAL 0)
ENDIF(${UNINSTALL_CHECK_${NUM}})
MATH(EXPR NUM "1 + ${NUM}")
ENDFOREACH(file)
FILE(REMOVE "@CMAKE_CURRENT_BINARY_DIR@/install_manifest.txt")
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/COPYING�����������������������������������������������������������������������������0000664�0000000�0000000�00000001276�12412610011�0014441�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������The sdsl copyright is as follows:
Copyright (C) 2007-2014 Simon Gog All Right Reserved.
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see http://www.gnu.org/licenses/ .
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/Make.helper.cmake�������������������������������������������������������������������0000664�0000000�0000000�00000001565�12412610011�0016544�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������LIB_DIR = @CMAKE_INSTALL_PREFIX@/lib
INC_DIR = @CMAKE_INSTALL_PREFIX@/include
MY_CXX_FLAGS=@CMAKE_CXX_FLAGS@ $(CODE_COVER)
MY_CXX_OPT_FLAGS=@CMAKE_CXX_OPT_FLAGS@
MY_CXX=@CMAKE_CXX_COMPILER@
MY_CC=@CMAKE_C_COMPILER@
# Returns $1-th .-separated part of string $2.
dim = $(word $1, $(subst ., ,$2))
# Returns value stored in column $3 for item with ID $2 in
# config file $1
config_select=$(shell cat $1 | grep -v "^\#" | grep "$2;" | cut -f $3 -d';' )
# Returns value stored in column $3 for a line matching $2
# in config file $1
config_filter=$(shell cat $1 | grep -v "^\#" | fgrep "$2" | cut -f $3 -d';' )
# Get all IDs from a config file $1
config_ids=$(shell cat $1 | grep -v "^\#" | cut -f 1 -d';')
# Get column $2 from a config file $1
config_column=$(shell cat $1 | grep -v "^\#" | cut -f $2 -d';')
# Get size of file $1 in bytes
file_size=$(shell wc -c < $1 | tr -d ' ')
�������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/README.md���������������������������������������������������������������������������0000664�0000000�0000000�00000025146�12412610011�0014667�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������SDSL - Succinct Data Structure Library
=========
What is it?
-----------
The Succinct Data Structure Library (SDSL) is a powerful and flexible C++11
library implementing succinct data structures. In total, the library contains
the highlights of 40 [research publications][SDSLLIT]. Succinct data structures
can represent an object (such as a bitvector or a tree) in space close the
information-theoretic lower bound of the object while supporting operations
of the original object efficiently. The theoretical time complexity of an
operations performed on the classical data structure and the equivalent
succinct data structure are (most of the time) identical.
Why SDSL?
--------
Succinct data structures have very attractive theoretical properties. However,
in practice implementing succinct data structures is non-trivial as they are
often composed of complex operations on bitvectors. The SDSL Library provides
high quality, open source implementations of many succinct data structures
proposed in literature.
Specifically, the aim of the library is to provide basic and complex succinct
data structure which are
* Easy and intuitive to use (like the [STL][STL], which provides classical data structures),
* Faithful to the original theoretical results,
* Capable of handling large inputs (yes, we support 64-bit),
* Provide efficient construction of all implemented succinct data structures,
while at the same time enable good run-time performance.
 In addition we provide additional functionality which can help you use succinct
data structure to their full potential.
* Each data structure can easily be serialized and loaded to/from disk.
* We provide functionality which helps you analyze the storage requirements of any
SDSL based data structure (see right)
* We support features such as hugepages and tracking the memory usage of each
SDSL data structure.
* Complex structures can be configured by template parameters and therefore
easily be composed. There exists one simple method which constructs
all complex structures.
* We maintain an extensive collection of examples which help you use the different
features provided by the library.
* All data structures are tested for correctness using a unit-testing framework.
* We provide a large collection of supporting documentation consisting of examples,
[cheat sheet][SDSLCS], [tutorial slides and walk-through][TUT].
The library contains many succinct data structures from the following categories:
* Bitvectors supporting Rank and Select
* Integer Vectors
* Wavelet Trees
* Compressed Suffix Arrays (CSA)
* Balanced Parentheses Representations
* Longest Common Prefix (LCP) Arrays
* Compressed Suffix Trees (CST)
* Range Minimum/Maximum Query (RMQ) Structures
For a complete overview including theoretical bounds see the
[cheat sheet][SDSLCS] or the
[wiki](https://github.com/simongog/sdsl-lite/wiki/List-of-Implemented-Data-Structures).
Documentation
-------------
We provide an extensive set of documentation describing all data structures
and features provided by the library. Specifically we provide
* A [cheat sheet][SDSLCS] which succinctly
describes the usage of the library.
* A set of [example](examples/) programs demonstrating how different features
of the library are used.
* A tutorial [presentation][TUT] with the [example code](tutorial/) using in the
sides demonstrating all features of the library in a step-by-step walk-through.
* [Unit Tests](test/) which contain small code snippets used to test each
library feature.
Requirements
------------
The SDSL library requires:
* A modern, C++11 ready compiler such as `g++` version 4.7 or higher or `clang` version 3.2 or higher.
* The [cmake][cmake] build system.
* A 64-bit operating system. Either Mac OS X or Linux are currently supported.
* For increased performance the processor of the system should support fast bit operations available in `SSE4.2`
Installation
------------
To download and install the library use the following commands.
```sh
git clone https://github.com/simongog/sdsl-lite.git
cd sdsl-lite
./install.sh
```
This installs the sdsl library into the `include` and `lib` directories in your
home directory. A different location prefix can be specified as a parameter of
the `install.sh` script:
```sh
./install /usr/local/
```
To remove the library from your system use the provided uninstall script:
```sh
./uninstall.sh
```
Getting Started
------------
To get you started with the library you can start by compiling the following
sample program which constructs a compressed suffix array (a FM-Index) over the
text `mississippi!`, counts the number of occurrences of pattern `si` and
stores the data structure, and a space usage visualization to the
files `fm_index-file.sdsl` and `fm_index-file.sdsl.html`:
```cpp
#include
#include
using namespace sdsl;
int main() {
csa_wt<> fm_index;
construct_im(fm_index, "mississippi!", 1);
std::cout << "'si' occurs " << count(fm_index,"si") << " times.\n";
store_to_file(fm_index,"fm_index-file.sdsl");
std::ofstream out("fm_index-file.sdsl.html");
write_structure(fm_index,out);
}
```
To compile the program using `g++` run:
```sh
g++ -std=c++11 -O3 -DNDEBUG -I ~/include -L ~/lib program.cpp -o program -lsdsl -ldivsufsort -ldivsufsort64
```
Next we suggest you look at the comprehensive [tutorial][TUT] which describes
all major features of the library or look at some of the provided [examples](examples).
Test
----
Implementing succinct data structures can be tricky. To ensure that all data
structures behave as expected, we created a large collection of unit tests
which can be used to check the correctness of the library on your computer.
The [test](./test) directory contains test code. We use [googletest][GTEST]
framework and [make][MAKE] to run the tests. See the README file in the
directory for details.
To simply run all unit tests type
```sh
cd sdsl-lite/test
make
```
Note: Running the tests requires several sample files to be downloaded from the web
and can take up to 2 hours on slow machines.
Benchmarks
----------
To ensure the library runs efficiently on your system we suggest you run our
[benchmark suite](benchmark). The benchmark suite recreates a
popular [experimental study](http://arxiv.org/abs/0712.3360) which you can
directly compare to the results of your benchmark run.
Bug Reporting
------------
While we use an extensive set of unit tests and test coverage tools you might
still find bugs in the library. We encourage you to report any problems with
the library via the [github issue tracking system](https://github.com/simongog/sdsl-lite/issues)
of the project.
The Latest Version
------------------
The latest version can be found on the SDSL github project page https://github.com/simongog/sdsl-lite .
If you are running experiments in an academic settings we suggest you use the
most recent [released](https://github.com/simongog/sdsl-lite/releases) version
of the library. This allows others to reproduce your experiments exactly.
Licensing
---------
The SDSL library is free software provided under the GNU General Public License
(GPLv3). For more information see the [COPYING file][CF] in the library
directory.
We distribute this library freely to foster the use and development of advanced
data structure. If you use the library in an academic setting please cite the
following paper:
@inproceedings{gbmp2014sea,
title = {From Theory to Practice: Plug and Play with Succinct Data Structures},
author = {Gog, Simon and Beller, Timo and Moffat, Alistair and Petri, Matthias},
booktitle = {13th International Symposium on Experimental Algorithms, (SEA 2014)},
year = {2014},
pages = {326-337},
ee = {http://dx.doi.org/10.1007/978-3-319-07959-2_28}
}
A preliminary version if available [here on arxiv][SEAPAPER].
## External Resources used in SDSL
We have included the code of two excellent suffix array
construction algorithms.
* Yuta Mori's incredible fast suffix [libdivsufsort][DIVSUF]
algorithm (version 2.0.1) for byte-alphabets.
* An adapted version of [Jesper Larsson's][JESL] [implementation][QSUFIMPL] of
suffix array sorting on integer-alphabets (description of [Larsson and Sadakane][LS]).
Additionally, we use the [googletest][GTEST] framework to provide unit tests.
Our visualizations are implemented using the [d3js][d3js]-library.
Authors
--------
The main contributors to the library are:
* [Timo Beller](https://github.com/tb38)
* [Simon Gog](https://github.com/simongog) (Creator)
* [Matthias Petri](https://github.com/mpetri)
This project further profited from excellent input of our students
Markus Brenner, Alexander Diehm, and Maike Zwerger. Stefan
Arnold helped us with tricky template questions. We are also grateful to
[Travis Gagie](https://github.com/TravisGagie),
Kalle Karhu,
[Dominik Kempa](https://github.com/dkempa),
[Bruce Kuo](https://github.com/bruce3557),
[Shanika Kuruppu](https://github.com/skuruppu),
and [Julio Vizcaino](https://github.com/garviz)
for bug reports.
Contribute
----------
Are you working on a new or improved implementation of a succinct data structure?
We encourage you to contribute your implementation to the SDSL library to make
your work accessible to the community within the existing library framework.
Feel free to contact any of the authors or create an issue on the
[issue tracking system](https://github.com/simongog/sdsl-lite/issues).
[STL]: http://www.sgi.com/tech/stl/ "Standard Template Library"
[pz]: http://pizzachili.di.unipi.it/ "Pizza&Chli"
[d3js]: http://d3js.org "D3JS library"
[cmake]: http://www.cmake.org/ "CMake tool"
[MAKE]: http://www.gnu.org/software/make/ "GNU Make"
[gcc]: http://gcc.gnu.org/ "GNU Compiler Collection"
[DIVSUF]: http://code.google.com/p/libdivsufsort/ "libdivsufsort"
[LS]: http://www.sciencedirect.com/science/article/pii/S0304397507005257 "Larson & Sadakane Algorithm"
[GTEST]: https://code.google.com/p/googletest/ "Google C++ Testing Framework"
[SDSLCS]: http://simongog.github.io/assets/data/sdsl-cheatsheet.pdf "SDSL Cheat Sheet"
[SDSLLIT]: https://github.com/simongog/sdsl-lite/wiki/Literature "Succinct Data Structure Literature"
[TUT]: http://simongog.github.io/assets/data/sdsl-slides/tutorial "Tutorial"
[QSUFIMPL]: http://www.larsson.dogma.net/qsufsort.c "Original Qsufsort Implementation"
[JESL]: http://www.itu.dk/people/jesl/ "Homepage of Jesper Larsson"
[CF]: https://github.com/simongog/sdsl-lite/blob/master/COPYING "Licence"
[SEAPAPER]: http://arxiv.org/pdf/1311.1249v1.pdf "SDSL paper"
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/VERSION�����������������������������������������������������������������������������0000664�0000000�0000000�00000000006�12412610011�0014444�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������2.0.1
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/��������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0015332�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/Make.download�������������������������������������������������������������0000664�0000000�0000000�00000000675�12412610011�0017750�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������../data/%:
$(eval URL:=$(firstword $(call config_filter,test_case.config,$@,4)))
@$(if $(URL),,\
$(error "No download link nor generation program specified for test case $@") )
@echo "Download input from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
�������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/Make.helper���������������������������������������������������������������0000664�0000000�0000000�00000001241�12412610011�0017406�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../Make.helper
../data/%.z.info:
$(eval TC:=../data/$*)
@echo "Get xz-compression ratio for $(TC)"
$(eval TC_XZ:=$(TC).xz)
$(shell xz -9 -z -k -c $(TC) > $(TC_XZ))
$(eval XZ_SIZE:=$(call file_size,$(TC_XZ)))
$(shell rm $(TC_XZ))
@echo "Get gzip-compression ratio for $(TC)"
$(eval TC_GZ:=$(TC).gz)
$(shell gzip -9 -c $(TC) > $(TC_GZ))
$(eval GZ_SIZE:=$(call file_size,$(TC_GZ)))
$(shell rm $(TC_GZ))
$(eval SIZE:=$(call file_size,$(TC)))
$(eval XZ_RATIO:=$(shell echo "scale=2;100*$(XZ_SIZE)/$(SIZE)" | bc -q))
$(eval GZ_RATIO:=$(shell echo "scale=2;100*$(GZ_SIZE)/$(SIZE)" | bc -q))
@echo "xz;$(XZ_RATIO);xz -9\ngzip;$(GZ_RATIO);gzip -9" > $@
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/README.md�����������������������������������������������������������������0000664�0000000�0000000�00000004403�12412610011�0016612�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarks for sdsl data structures
This directory contains a set of benchmarks for [sdsl][sdsl]
data structures. Each benchmark is in its own subdirectory and
so far we have:
* [indexing_count](./indexing_count): Evaluates the performance
of count queries on different FM-Indexes/CSAs. Count query
means _How many times occurs my pattern P in the text T?_
* [indexing_extract](./indexing_extract): Evaluates the performance
of extracting continues sequences of text out of FM-Indexes/CSAs.
* [indexing_locate](./indexing_locate): Evaluates the performance
of _locate queries_ on different FM-Indexes/CSAs. Locate query
means _At which positions does pattern P occure in T?_
* [rrr_vector](./rrr_vector): Evaluates the performance of
the -compressed
bitvector [rrr_vector](../include/sdsl/rrr_vector.hpp).
Operations `access`, `rank`, and `select` are benchmarked on
different inputs.
* [wavelet_trees](./wavelet_trees): Evaluates the performance of wavelet trees.
You can executed the benchmarks by calling `make timing`
in the specific subdirectory.
Test inputs will be automatically generated or downloaded
from internet sources, such as the excellent [Pizza&Chili][pz]
website, and stored in the [data](./data) directory.
Directory [tmp](./tmp) is used to store temporary files (like
plain suffix arrays) which are used to generate compressed
structures.
## Prerequisites
The following tools, which are available as packages for Mac OS X and
most Linux distributions, are required:
* [cURL][CURL] is required by the test input download script.
* [gzip][GZIP] is required to extract compressed files.
## Literature
The benchmark code originates from the following article and can be used
to easily reproduce the results presented in the paper.
Simon Gog, Matthias Petri: _Optimized Succinct Data Structures for Massive Data_. 2013.
Accepted for publication in Software, Practice and Experience.
[Preprint][PP]
## Author
Simon Gog (simon.gog@gmail.com)
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[PP]: http://people.eng.unimelb.edu.au/sgog/optimized.pdf "Preprint"
[CURL]: http://curl.haxx.se/ "cURL"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/basic_functions.R���������������������������������������������������������0000664�0000000�0000000�00000013017�12412610011�0020630�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Read a file called file_name and create a data frame the following way
# (1) Parse all the lines of the form
# '# key = value'
# (2) Each unique key gets a column
data_frame_from_key_value_pairs <- function(file_name){
lines <- readLines(file_name)
lines <- lines[grep("^#.*=.*",lines)]
d <- gsub("^#","",gsub("[[:space:]]","",unlist(strsplit(lines,split="="))))
keys <- unique(d[seq(1,length(d),2)])
keynr <- length(keys)
dd <- d[seq(2,length(d),2)]
dim(dd) <- c( keynr, length(dd)/keynr )
data <- data.frame(t(dd))
names(data) <- keys
for (col in keys){
t <- as.character(data[[col]])
suppressWarnings( tt <- as.numeric(t) )
if ( length( tt[is.na(tt)] ) == 0 ){ # if there are not NA in tt
data[[col]] <- tt
}
}
data
}
# Takes a vector v=(v1,v2,v3,....)
# and returns a vector which repeats
# each element x times. So for two we get
# (v1,v1,v2,v2,v3,v3....)
expand_vec <- function( v, x ){
v <- rep(v,x)
dim(v) <- c(length(v)/x,x)
v <- t(v)
dim(v) <- c(1,nrow(v)*ncol(v))
v
}
# Takes a vector v=(v1,v2,v3,....)
# and returns a vector which appends x-1
# NA after each value. So for x=2 we get
# (v1,NA,v2,NA,v3,NA....)
expand_vec_by_NA <- function( v, x ){
v <- c(v, rep(NA,length(v)*(x-1)))
dim(v) <- c(length(v)/x,x)
v <- t(v)
dim(v) <- c(1,nrow(v)*ncol(v))
v
}
format_str_fixed_width <- function(x, width=4){
sx <- as.character(x)
if ( nchar(sx) < width ){
for (i in 1:(width-nchar(sx))){
sx <- paste("\\D",sx, sep="")
}
}
sx
}
# Check if package is installed
# found at: http://r.789695.n4.nabble.com/test-if-a-package-is-installed-td1750671.html#a1750674
is.installed <- function(mypkg) is.element(mypkg, installed.packages()[,1])
sanitize_column <- function(column){
column <- gsub("_","\\\\_",column)
column <- gsub(" >",">",column)
column <- gsub("<","{\\\\textless}",column)
column <- gsub(">","{\\\\textgreater}",column)
column <- gsub(",",", ",column)
}
# tranforms a vector of index ids to a vector which contains the
# corresponding latex names.
# Note: each id should only appear once in the input vector
mapids <- function(ids, mapit){
as.character(unlist(mapit[ids]))
}
id2latex <- function(config_file, latexcol, idcol=1){
index_info <- read.csv(config_file, sep=";",header=F, comment.char="#")
res <- data.frame( t(as.character(index_info[[latexcol]])), stringsAsFactors=F )
names(res) <- as.character(index_info[[idcol]])
res
}
idAndValue <- function(config_file, valuecol, idcol=1){
res <- read.csv(config_file, sep=";",header=F, comment.char="#")
res[c(idcol, valuecol)]
}
readConfig <- function(config_file, mycolnames){
config <- read.csv(config_file, sep=";",header=F, comment.char="#",stringsAsFactors=F)
rownames(config) <- config[[1]]
colnames(config) <- mycolnames
config
}
# Creates a LaTeX table containing index names and sdsl type
# config_file The index.config storing the type information
# index_ids Filter the index.config entires with this index ids
# id_col Column `id_col` contains the IDs
# name_col Column `name_col` contains the latex names
# type_col Column `type_col` contains the type
typeInfoTable <- function(config_file, index_ids, id_col=1, name_col=3, type_col=2){
x <- read.csv(config_file, sep=";", header=F, comment.char="#",stringsAsFactors=F)
rownames(x) <- x[[id_col]]
x <- x[index_ids,] # filter
sdsl_type <- sanitize_column(x[[type_col]])
sdsl_name <- x[[name_col]]
res <- "
\\renewcommand{\\arraystretch}{1.3}
\\begin{tabular}{@{}llp{10cm}@{}}
\\toprule
Identifier&&sdsl type\\\\ \\cmidrule{1-1}\\cmidrule{3-3}"
res <- paste(res, paste(sdsl_name,"&&\\footnotesize\\RaggedRight\\texttt{",sdsl_type,"}\\\\",sep="",collapse=" "))
res <- paste(res,"
\\bottomrule
\\end{tabular}")
}
# returns x concatenated with x reversed
x_for_polygon <- function(x){
c( x, rev(x) )
}
# return y concatenated with rep(0, length(y))
y_for_polygon <- function(y){
c( y, rep(0, length(y)) )
}
# ncols Number of columns in the figure
# nrows Number of rows in the figure
multi_figure_style <- function(nrows, ncols){
par(mfrow=c(nrows, ncols))
par(las=1) # axis labels always horizontal
par(yaxs="i") # don't add +- 4% to the yaxis
par(xaxs="i") # don't add +- 4% to the xaxis
# distance (x1,x2,x3) of axis parts from the axis. x1=axis labels or titles
# x2=tick marks, x3=tick marks symbol
par(mgp=c(2,0.5,0))
# length of tick mark as a fraction of the height of a line of text, default=-0.5
par(tcl=-0.2)
par(oma=c(2.5,2.7,0,0.2)) # outer margin (bottom,left,top,right)
par(mar=c(1,1,1.5,0.5)) # inner margin (bottom,left,top,right)
}
# Draw the heading of diagrams
# text Text which should be displayed in the heading
draw_figure_heading <- function(text){
# scale Y
SY <- function(val){ if( par("ylog") ){ 10^val } else { val } }
SX <- function(val){ if( par("xlog") ){ 10^val } else { val } }
rect(xleft=SX(par("usr")[1]), xright=SX(par("usr")[2]),
ybottom=SY(par("usr")[4]), ytop=SY(par("usr")[4]*1.1) ,xpd=NA,
col="grey80", border="grey80" )
text(labels=text,y=SY(par("usr")[4]*1.02), adj=c(0.5, 0),x=SX((par("usr")[1]+par("usr")[2])/2),xpd=NA,cex=1.4)
}
print_info <- function(){
Sys.info("release")
Sys.info("sysname")
Sys.info("version")
Sys.info("nodename")
Sys.info("machine")
Sys.info("login")
Sys.info("user")
Sys.info("effective_user")
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/data/���������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0016243�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/data/.gitignore�����������������������������������������������������������0000664�0000000�0000000�00000000035�12412610011�0020231�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!get_corpus.sh
!.gitignore
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/�������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021225�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/Makefile�����������������������������������������������0000664�0000000�0000000�00000027464�12412610011�0022702�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../Make.helper
CXX_FLAGS = $(MY_CXX_FLAGS) $(MY_CXX_OPT_FLAGS) -I$(INC_DIR) -L$(LIB_DIR)
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
SRC_DIR = src
TMP_DIR = ../tmp
PAT_DIR = pattern
BIN_DIR = bin
TC_PATHS:=$(call config_column,test_case.config,2)
TC_PATHS_INT:=$(call config_column,test_case_int.config,2)
TC_DICT_PATHS:=$(call config_column,dic.config,2)
TC_IDS:=$(call config_ids,test_case.config)
TC_IDS_INT:=$(call config_ids,test_case_int.config)
IDX_IDS:=$(call config_ids,index.config)
IDX_IDS_INT:=$(call config_ids,index_int.config)
PAT_LENS:=$(call config_column,pattern_length.config,1)
PAT_LENS_INT:=$(call config_column,pattern_length_int.config,1)
RESULT_FILE=results/all.txt
RESULT_FILE_INT=results/all_int.txt
QUERY_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/query_idx_$(IDX_ID))
QUERY_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/query_int_idx_$(IDX_ID))
BUILD_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/build_idx_$(IDX_ID))
BUILD_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/build_int_idx_$(IDX_ID))
SIZES_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/size_of_idx_$(IDX_ID))
SIZES_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/size_of_int_idx_$(IDX_ID))
PATTERNS = $(foreach TC_ID,$(TC_IDS),\
$(foreach PAT_LEN,$(PAT_LENS),$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern))
PATTERNS_INT = $(foreach TC_ID,$(TC_IDS_INT),\
$(foreach PAT_LEN,$(PAT_LENS_INT),$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern.int))
INDEXES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),indexes/$(TC_ID).$(IDX_ID).byte))
INDEXES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),indexes/$(TC_ID).$(IDX_ID).int))
SIZES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),info/$(TC_ID).$(IDX_ID).size))
SIZES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),info/$(TC_ID).$(IDX_ID).size.int))
HTML = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),info/$(TC_ID).$(IDX_ID).byte.html))
HTML_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),info/$(TC_ID).$(IDX_ID).int.html))
TIME_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach PAT_LEN,$(PAT_LENS),results/$(TC_ID).$(IDX_ID).$(PAT_LEN).byte)))
TIME_FILES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),\
$(foreach PAT_LEN,$(PAT_LENS_INT),results/$(TC_ID).$(IDX_ID).$(PAT_LEN).int)))
COMP_FILES = $(addsuffix .z.info,$(TC_PATHS) $(TC_PATHS_INT))
HELPER_BINS = $(BIN_DIR)/gen_pattern $(BIN_DIR)/gen_pattern_int \
$(BIN_DIR)/word_pat2char_pat
all: $(BUILD_EXECS) $(BUILD_EXECS_INT) \
$(QUERY_EXECS) $(QUERY_EXECS_INT) \
$(SIZES_EXECS) $(SIZES_EXECS_INT) \
$(HELPER_BINS)
info: $(SIZES_EXECS) $(SIZES_EXECS_INT) $(SIZES) \
$(SIZES_INT) $(HTML_INT) $(HTML) \
info/sizes.txt \
info/sizes_int.txt
info/sizes.txt: $(SIZES)
@cat $(SIZES) > $@
info/sizes_int.txt: $(SIZES)
@cat $(SIZES_INT) > $@
indexes: $(INDEXES) $(INDEXES_INT)
input: $(TC_PATHS) $(TC_PATHS_INT) $(TC_DICT_PATHS)
pattern: input $(PATTERNS) $(BIN_DIR)/gen_pattern $(PATTERNS_INT) $(BIN_DIR)/gen_pattern_int
compression: input $(COMP_FILES)
timing: input indexes pattern $(TIME_FILES) $(TIME_FILES_INT) compression info
@cat $(TIME_FILES) > $(RESULT_FILE)
@cat $(TIME_FILES_INT) > $(RESULT_FILE_INT)
@cd visualize; make
# results/[TC_ID].[IDX_ID].[PAT_LEN].byte
results/%.byte: $(BUILD_EXECS) $(QUERY_EXECS) $(INDEXES) $(PATTERNS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval PAT_LEN:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "Run timing for $(IDX_ID) on $(TC_ID) with patterns of length $(PAT_LEN)"
@$(BIN_DIR)/query_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte \
$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern >> $@
# results/[TC_ID].[IDX_ID].[PAT_LEN].byte
results/%.int: $(BUILD_EXECS) $(QUERY_EXECS_INT) $(INDEXES_INT) $(PATTERNS_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval PAT_LEN:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case_int.config,$(TC_ID),3))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "Run timing for $(IDX_ID) on $(TC_ID) with patterns of length $(PAT_LEN)"
@$(BIN_DIR)/query_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int \
$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern.int >> $@
# indexes/[TC_ID].[IDX_ID].byte
indexes/%.byte: $(BUILD_EXECS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
@echo "Building index $(IDX_ID) on $(TC)"
@$(BIN_DIR)/build_idx_$(IDX_ID) $(TC) $(TMP_DIR) $@
# indexes/[TC_ID].[IDX_ID].int
indexes/%.int: $(BUILD_EXECS_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
@echo "Building index $(IDX_ID) on $(TC)"
@$(BIN_DIR)/build_int_idx_$(IDX_ID) $(TC) $(TMP_DIR) $@
# info/[TC_ID].[IDX_ID]
info/%.size: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get size of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte >> $@
# info/[TC_ID].[IDX_ID]
info/%.size.int: $(INDEXES_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get size of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int >> $@
# info/[TC_ID].[IDX_ID]
info/%.byte.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get html of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte $@
# info/[TC_ID].[IDX_ID]
info/%.int.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get html of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int $@
# $(PAT_DIR)/[TC_ID].[PAT_LEN].pattern.int
$(PAT_DIR)/%.pattern.int: $(BIN_DIR)/gen_pattern_int $(BIN_DIR)/word_pat2char_pat
@echo $*
$(eval TC_ID:=$(call dim,1,$*))
$(eval PAT_LEN:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(BIN_DIR)/gen_pattern_int $(TC) $(TMP_DIR)/$(TC_ID).pat.csa $(TMP_DIR) $(PAT_LEN) 200 $@
$(eval DIC_PATH:=$(call config_select,dic.config,$(TC_ID),2))
$(BIN_DIR)/word_pat2char_pat $@ $(DIC_PATH) > $@.txt
# $(PAT_DIR)/[TC_ID].[PAT_LEN].pattern
$(PAT_DIR)/%.pattern: $(BIN_DIR)/gen_pattern
@echo $*
$(eval TC_ID:=$(call dim,1,$*))
$(eval PAT_LEN:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(BIN_DIR)/gen_pattern $(TC) $(TMP_DIR)/$(TC_ID).pat.csa $(TMP_DIR) $(PAT_LEN) 200 $@
$(BIN_DIR)/gen_pattern: $(SRC_DIR)/gen_pattern.cpp
@echo "Build pattern generation program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/gen_pattern.cpp \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/gen_pattern_int: $(SRC_DIR)/gen_pattern.cpp
@echo "Build pattern generation program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/gen_pattern.cpp \
-DINT_ALPHABET \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/size_of_idx_%: $(SRC_DIR)/size_of_idx.cpp
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Build size info program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/size_of_idx.cpp \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/size_of_int_idx_%: $(SRC_DIR)/size_of_idx.cpp
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Build size info program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/size_of_idx.cpp \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
# $(BIN_DIR)/build_idx_[IDX_ID]
$(BIN_DIR)/build_idx_%: $(SRC_DIR)/build_idx.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling build_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/build_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# $(BIN_DIR)/build_idx_[IDX_ID]
$(BIN_DIR)/build_int_idx_%: $(SRC_DIR)/build_idx.cpp index_int.config
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Compiling build_int_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/build_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/query_idx_[IDX_ID]
$(BIN_DIR)/query_idx_%: $(SRC_DIR)/query_idx.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling query_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_ID=\"$*\" -DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/query_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/query_idx_[IDX_ID]
$(BIN_DIR)/query_int_idx_%: $(SRC_DIR)/query_idx.cpp index_int.config
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Compiling query_int_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_ID=\"$*\" -DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/query_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/word_pat2char_pat: $(SRC_DIR)/word_pat2char_pat.cpp
@echo "Compiling word_pat2char_pat.cpp"
$(MY_CXX) $(CXX_FLAGS) \
$(SRC_DIR)/word_pat2char_pat.cpp \
-o $@
dic/%:
$(eval URL:=$(call config_filter,dic.config,$@,4))
@$(if $(URL),,\
$(error "No download link for dictionary $@") )
@echo "Download dictionary from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
../data/%.int.sdsl:
$(eval URL:=$(call config_filter,test_case_int.config,$@,4))
@$(if $(URL),,\
$(error "No download link nor generation program specified for test case $@") )
@echo "Download input from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
include ../Make.download
clean-build:
@echo "Remove executables"
rm -f $(QUERY_EXECS) $(SIZES_EXECS) $(BUILD_EXECS) \
$(QUERY_EXECS_INT) $(SIZES_EXECS_INT) $(BUILD_EXECS_INT) \
$(HELPER_BINS)
clean: clean-build
@echo "Remove info files and indexes"
rm -f $(INDEXES) $(INDEXES_INT)
cleanresults:
@echo "Remove result files and pattern"
rm -f $(TIME_FILES) \
$(RESULT_FILE) \
$(TIME_FILES_INT) \
$(RESULT_FILE_INT) \
$(SIZES) $(SIZES_INT) \
$(HTML) $(HTML_INT)
rm -f $(PATTERNS) $(PATTERNS_INT)
cleanall: clean cleanresults
@echo "Remove all generated files."
rm -f $(TMP_DIR)/*
rm -f $(PAT_DIR)/*
cd visualize; make clean
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/README.md����������������������������������������������0000664�0000000�0000000�00000011145�12412610011�0022506�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking top-k search on simple document search implementations
## Methodology
The benchmark setup is close to the one used in the ESA 2010 article
of Culpepper, Navarro, Puglisi and Turpin.
Explored dimensions:
* text type
* instance size (just adjust the `test_case.config` file for this)
* index implementations
- [Sadakane's method](src/doc_list_index_sada.hpp)
- [Wavelet tree greedy traversal](src/doc_list_index_greedy.hpp)
- [Wavelet tree quantile probing](src/doc_list_index_qprobing.hpp)
## Directory structure
* [bin](./bin): Contains the executables of the project.
- `build_*` index build executables
- `gen_pattern*` executable to generate pattern sets
- `query_*` index query executables
- `size_of_*` generate size and space breakdowns
* [dic](./dic): Contains dictionaries for integer inputs.
* [indexes](./indexes): Contains the generated indexes.
* [info](./info): Contains space breakdowns.
* [pattern](./pattern): Contains generated pattern.
* [results](./results): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which generates
a report.
## Test data
* ENWIKISML was generated by
- downloading a dump of a prefix of the English wikipedia (at the 5th of August 2013)
- applying the `WikiExtractor.py` program Version 2.5
from Giuesppe Attardi and Antonio Fuschetto (Univserity of Pisa).
- Removing the ``-tag and replacing the ``
take by `\1`
* ENWIKIBIG was generated the same way but for the complete
English wikipedia (retrieved at the 8th of July 2013).
* The integer version, ENWIKISMLINT and ENWIKIBIGINT, were
generated from ENWIKISML and ENWIKIBIG by
- applying the [stanford-parser.jar][SP] from the NL group
at Stanford to tokenize the input (options
`untokenizable=allKeep,normalizeParentheses=false,normalizeOtherBrackets=false`)
- assign the document seperator the ID `1`, and the ID of the other
tokens is their rank in the reverse sorting of frequency (starting at `2`).
- The resulting sequence of integers is stored in a bit-compressed
`int_vector`.
- The generated dictionaries containing on each line
a `(word, ID, occurrences)`-tuple.
* PROTEINS is the concatenation of 143,244 Human and Mouse
proteins sequences from the swissport database.
* Availability: ENWIKIBIG (character and integer version)
are available on request. The other files are downloaded
automatically during the execution of the benchmark.
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with package `tikzDevice`. You can install the
package by calling
`install.packages("filehash", repos="http://cran.r-project.org")`
and
`install.packages("tikzDevice", repos="http://R-Forge.R-project.org")`
in `R`.
- Compressors [xz][XZ] and [gzip][GZIP] are used to get
compression baselines.
- [pdflatex][LT] to generate the pdf reports.
## Usage
Command `make timing` will download the small test cases, compile executables,
build the indexes, run the queries, and generate a report. The
benchmark run 5 minutes and 40 seconds (without downloading the files)
and generated [this report on my machine][RES].
## Customization of the benchmark
The project contains several configuration files:
* [index.config](./index.config): Specify character
based indexes' ID, sdsl-class and LaTeX-name for the report.
* [index_int.config](./index_int.config): Specify word
based indexes' ID, sdsl-class and LaTeX-name for the report.
* [test_case.config](./test_case.config): Specify character based collections'
ID, path, LaTeX-name for the report, and download URL.
* [test_case_int.config](./test_case_int.config): Specify word based collections'
ID, path, LaTeX-name for the report, and download URL.
* [pattern_length.config](./pattern_length.config): Specify the
lengths of queried pattern for character based indexes.
* [pattern_length_int.config](./pattern_length_int.config): Specify
lengths of queried pattern for word based indexes.
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[RPJ]: http://www.r-project.org/ "R"
[XZ]: http://tukaani.org/xz/ "XZ Compressor"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
[SP]: http://nlp.stanford.edu/software/tokenizer.shtml
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/doc_re_time.pdf "doc_re_time.pdf"
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/bin/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021775�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/bin/.gitignore�����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023762�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic.config���������������������������������������������0000664�0000000�0000000�00000000622�12412610011�0023153�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration file for dictionary files
# for integer based inputs
#
# (1) Identifier for test integer test file
# (has to exist in test_case_int.config)
# (2) Path to dictionary
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENWIKISMLINT;dic/enwiki-20130805-pages-articles1.dic;enwiki-dic;http://people.eng.unimelb.edu.au/sgog/data/enwiki-20130805-pages-articles1.dic.gz
��������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021764�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic/.gitignore�����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023751�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/index.config�������������������������������������������0000664�0000000�0000000�00000001310�12412610011�0023516�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specified sdsl index structures that are used in the benchmark.
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATEX_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in INDEX_ID.
# * TYPE : Corresponding type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
GREEDY;doc_list_index_greedy<>;GREEDY
#GREEDY-RRR;doc_list_index_greedy>,1000000,1000000>,wt_int>>;GREEDY-RRR
#QPROBING;doc_list_index_qprobing<>;QPROBING
SADA;doc_list_index_sada, 32, 1000000, text_order_sa_sampling>>>;SADA
SORT;doc_list_index_sort<>;SORT
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/index_int.config���������������������������������������0000664�0000000�0000000�00000001263�12412610011�0024377�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specified sdsl index structures that are used in the benchmark.
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATEX_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in INDEX_ID.
# * TYPE : Corresponding type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
GREEDYINT;doc_list_index_greedy>,1000000,1000000>>;GREEDY-I
SADAINT;doc_list_index_sada, 32, 1000000, text_order_sa_sampling>>>;SADA-I
SORTINT;doc_list_index_sort, 32, 1000000, text_order_sa_sampling>>>;SORT-I
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/indexes/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022664�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/indexes/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024651�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/info/��������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022160�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/info/.gitignore����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024145�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022702�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024667�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern_length.config����������������������������������0000664�0000000�0000000�00000000122�12412610011�0025425�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# pattern length
3;
4;
5;
6;
7;
8;
9;
10;
11;
12;
13;
14;
15;
16;
17;
18;
19;
20;
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern_length_int.config������������������������������0000664�0000000�0000000�00000000055�12412610011�0026304�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# pattern length
2;
3;
4;
5;
6;
7;
8;
9;
10;
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/results/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022726�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/results/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024713�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022014�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/build_idx.cpp��������������������������������������0000664�0000000�0000000�00000002114�12412610011�0024461�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include "doc_list_index.hpp"
#include
#include
#include
using namespace std;
using namespace sdsl;
using idx_type = IDX_TYPE;
int main(int argc, char* argv[])
{
if (argc < 4) {
cout << "Usage: " << argv[0] << " collection_file tmp_dir index_file" << endl;
cout << " Generates an index and stores result in index_file" << endl;
cout << " Temporary files are stored in tmp_dir." << endl;
return 1;
}
string collection_file = argv[1];
string id = util::basename(collection_file);
string tmp_dir = argv[2];
string idx_file = argv[3];
using timer = std::chrono::high_resolution_clock;
auto start = timer::now();
idx_type idx;
cache_config cconfig(false, tmp_dir, id);
construct(idx, collection_file, cconfig, idx_type::WIDTH==8 ? 1 : 0);
auto stop = timer::now();
auto elapsed = stop-start;
std::cout << "construction time = " << std::chrono::duration_cast(elapsed).count() << std::endl;
store_to_file(idx, idx_file);
}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index.hpp���������������������������������0000664�0000000�0000000�00000000750�12412610011�0025516�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#ifndef DOC_LIST_INDEX
#define DOC_LIST_INDEX
#include
#include
struct doc_list_tag {};
template
void
construct(t_index& idx, const std::string& file, sdsl::cache_config& config, uint8_t num_bytes, doc_list_tag)
{
t_index tmp_idx(file, config, num_bytes);
idx.swap(tmp_idx);
}
#include "doc_list_index_sada.hpp"
#include "doc_list_index_greedy.hpp"
#include "doc_list_index_qprobing.hpp"
#include "doc_list_index_sort.hpp"
#endif
������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index_greedy.hpp��������������������������0000664�0000000�0000000�00000015603�12412610011�0027060�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*!
* This file contains a document listing class, which implements
* strategy GREEDY in the article:
* J. S. Culpepper, G. Navarro, S. J. Puglisi and A. Turpin:
* ,,Top-k Ranked Document Search in General Text Databases''
* Proceedings Part II of the 18th Annual European Symposium on
* Algorithms (ESA 2010)
*/
#ifndef DOCUMENT_LISING_GREEDY_INCLUDED
#define DOCUMENT_LISING_GREEDY_INCLUDED
#include
#include
#include
#include
#include
#include
In addition we provide additional functionality which can help you use succinct
data structure to their full potential.
* Each data structure can easily be serialized and loaded to/from disk.
* We provide functionality which helps you analyze the storage requirements of any
SDSL based data structure (see right)
* We support features such as hugepages and tracking the memory usage of each
SDSL data structure.
* Complex structures can be configured by template parameters and therefore
easily be composed. There exists one simple method which constructs
all complex structures.
* We maintain an extensive collection of examples which help you use the different
features provided by the library.
* All data structures are tested for correctness using a unit-testing framework.
* We provide a large collection of supporting documentation consisting of examples,
[cheat sheet][SDSLCS], [tutorial slides and walk-through][TUT].
The library contains many succinct data structures from the following categories:
* Bitvectors supporting Rank and Select
* Integer Vectors
* Wavelet Trees
* Compressed Suffix Arrays (CSA)
* Balanced Parentheses Representations
* Longest Common Prefix (LCP) Arrays
* Compressed Suffix Trees (CST)
* Range Minimum/Maximum Query (RMQ) Structures
For a complete overview including theoretical bounds see the
[cheat sheet][SDSLCS] or the
[wiki](https://github.com/simongog/sdsl-lite/wiki/List-of-Implemented-Data-Structures).
Documentation
-------------
We provide an extensive set of documentation describing all data structures
and features provided by the library. Specifically we provide
* A [cheat sheet][SDSLCS] which succinctly
describes the usage of the library.
* A set of [example](examples/) programs demonstrating how different features
of the library are used.
* A tutorial [presentation][TUT] with the [example code](tutorial/) using in the
sides demonstrating all features of the library in a step-by-step walk-through.
* [Unit Tests](test/) which contain small code snippets used to test each
library feature.
Requirements
------------
The SDSL library requires:
* A modern, C++11 ready compiler such as `g++` version 4.7 or higher or `clang` version 3.2 or higher.
* The [cmake][cmake] build system.
* A 64-bit operating system. Either Mac OS X or Linux are currently supported.
* For increased performance the processor of the system should support fast bit operations available in `SSE4.2`
Installation
------------
To download and install the library use the following commands.
```sh
git clone https://github.com/simongog/sdsl-lite.git
cd sdsl-lite
./install.sh
```
This installs the sdsl library into the `include` and `lib` directories in your
home directory. A different location prefix can be specified as a parameter of
the `install.sh` script:
```sh
./install /usr/local/
```
To remove the library from your system use the provided uninstall script:
```sh
./uninstall.sh
```
Getting Started
------------
To get you started with the library you can start by compiling the following
sample program which constructs a compressed suffix array (a FM-Index) over the
text `mississippi!`, counts the number of occurrences of pattern `si` and
stores the data structure, and a space usage visualization to the
files `fm_index-file.sdsl` and `fm_index-file.sdsl.html`:
```cpp
#include
#include
using namespace sdsl;
int main() {
csa_wt<> fm_index;
construct_im(fm_index, "mississippi!", 1);
std::cout << "'si' occurs " << count(fm_index,"si") << " times.\n";
store_to_file(fm_index,"fm_index-file.sdsl");
std::ofstream out("fm_index-file.sdsl.html");
write_structure(fm_index,out);
}
```
To compile the program using `g++` run:
```sh
g++ -std=c++11 -O3 -DNDEBUG -I ~/include -L ~/lib program.cpp -o program -lsdsl -ldivsufsort -ldivsufsort64
```
Next we suggest you look at the comprehensive [tutorial][TUT] which describes
all major features of the library or look at some of the provided [examples](examples).
Test
----
Implementing succinct data structures can be tricky. To ensure that all data
structures behave as expected, we created a large collection of unit tests
which can be used to check the correctness of the library on your computer.
The [test](./test) directory contains test code. We use [googletest][GTEST]
framework and [make][MAKE] to run the tests. See the README file in the
directory for details.
To simply run all unit tests type
```sh
cd sdsl-lite/test
make
```
Note: Running the tests requires several sample files to be downloaded from the web
and can take up to 2 hours on slow machines.
Benchmarks
----------
To ensure the library runs efficiently on your system we suggest you run our
[benchmark suite](benchmark). The benchmark suite recreates a
popular [experimental study](http://arxiv.org/abs/0712.3360) which you can
directly compare to the results of your benchmark run.
Bug Reporting
------------
While we use an extensive set of unit tests and test coverage tools you might
still find bugs in the library. We encourage you to report any problems with
the library via the [github issue tracking system](https://github.com/simongog/sdsl-lite/issues)
of the project.
The Latest Version
------------------
The latest version can be found on the SDSL github project page https://github.com/simongog/sdsl-lite .
If you are running experiments in an academic settings we suggest you use the
most recent [released](https://github.com/simongog/sdsl-lite/releases) version
of the library. This allows others to reproduce your experiments exactly.
Licensing
---------
The SDSL library is free software provided under the GNU General Public License
(GPLv3). For more information see the [COPYING file][CF] in the library
directory.
We distribute this library freely to foster the use and development of advanced
data structure. If you use the library in an academic setting please cite the
following paper:
@inproceedings{gbmp2014sea,
title = {From Theory to Practice: Plug and Play with Succinct Data Structures},
author = {Gog, Simon and Beller, Timo and Moffat, Alistair and Petri, Matthias},
booktitle = {13th International Symposium on Experimental Algorithms, (SEA 2014)},
year = {2014},
pages = {326-337},
ee = {http://dx.doi.org/10.1007/978-3-319-07959-2_28}
}
A preliminary version if available [here on arxiv][SEAPAPER].
## External Resources used in SDSL
We have included the code of two excellent suffix array
construction algorithms.
* Yuta Mori's incredible fast suffix [libdivsufsort][DIVSUF]
algorithm (version 2.0.1) for byte-alphabets.
* An adapted version of [Jesper Larsson's][JESL] [implementation][QSUFIMPL] of
suffix array sorting on integer-alphabets (description of [Larsson and Sadakane][LS]).
Additionally, we use the [googletest][GTEST] framework to provide unit tests.
Our visualizations are implemented using the [d3js][d3js]-library.
Authors
--------
The main contributors to the library are:
* [Timo Beller](https://github.com/tb38)
* [Simon Gog](https://github.com/simongog) (Creator)
* [Matthias Petri](https://github.com/mpetri)
This project further profited from excellent input of our students
Markus Brenner, Alexander Diehm, and Maike Zwerger. Stefan
Arnold helped us with tricky template questions. We are also grateful to
[Travis Gagie](https://github.com/TravisGagie),
Kalle Karhu,
[Dominik Kempa](https://github.com/dkempa),
[Bruce Kuo](https://github.com/bruce3557),
[Shanika Kuruppu](https://github.com/skuruppu),
and [Julio Vizcaino](https://github.com/garviz)
for bug reports.
Contribute
----------
Are you working on a new or improved implementation of a succinct data structure?
We encourage you to contribute your implementation to the SDSL library to make
your work accessible to the community within the existing library framework.
Feel free to contact any of the authors or create an issue on the
[issue tracking system](https://github.com/simongog/sdsl-lite/issues).
[STL]: http://www.sgi.com/tech/stl/ "Standard Template Library"
[pz]: http://pizzachili.di.unipi.it/ "Pizza&Chli"
[d3js]: http://d3js.org "D3JS library"
[cmake]: http://www.cmake.org/ "CMake tool"
[MAKE]: http://www.gnu.org/software/make/ "GNU Make"
[gcc]: http://gcc.gnu.org/ "GNU Compiler Collection"
[DIVSUF]: http://code.google.com/p/libdivsufsort/ "libdivsufsort"
[LS]: http://www.sciencedirect.com/science/article/pii/S0304397507005257 "Larson & Sadakane Algorithm"
[GTEST]: https://code.google.com/p/googletest/ "Google C++ Testing Framework"
[SDSLCS]: http://simongog.github.io/assets/data/sdsl-cheatsheet.pdf "SDSL Cheat Sheet"
[SDSLLIT]: https://github.com/simongog/sdsl-lite/wiki/Literature "Succinct Data Structure Literature"
[TUT]: http://simongog.github.io/assets/data/sdsl-slides/tutorial "Tutorial"
[QSUFIMPL]: http://www.larsson.dogma.net/qsufsort.c "Original Qsufsort Implementation"
[JESL]: http://www.itu.dk/people/jesl/ "Homepage of Jesper Larsson"
[CF]: https://github.com/simongog/sdsl-lite/blob/master/COPYING "Licence"
[SEAPAPER]: http://arxiv.org/pdf/1311.1249v1.pdf "SDSL paper"
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/VERSION�����������������������������������������������������������������������������0000664�0000000�0000000�00000000006�12412610011�0014444�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������2.0.1
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/��������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0015332�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/Make.download�������������������������������������������������������������0000664�0000000�0000000�00000000675�12412610011�0017750�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������../data/%:
$(eval URL:=$(firstword $(call config_filter,test_case.config,$@,4)))
@$(if $(URL),,\
$(error "No download link nor generation program specified for test case $@") )
@echo "Download input from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
�������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/Make.helper���������������������������������������������������������������0000664�0000000�0000000�00000001241�12412610011�0017406�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../Make.helper
../data/%.z.info:
$(eval TC:=../data/$*)
@echo "Get xz-compression ratio for $(TC)"
$(eval TC_XZ:=$(TC).xz)
$(shell xz -9 -z -k -c $(TC) > $(TC_XZ))
$(eval XZ_SIZE:=$(call file_size,$(TC_XZ)))
$(shell rm $(TC_XZ))
@echo "Get gzip-compression ratio for $(TC)"
$(eval TC_GZ:=$(TC).gz)
$(shell gzip -9 -c $(TC) > $(TC_GZ))
$(eval GZ_SIZE:=$(call file_size,$(TC_GZ)))
$(shell rm $(TC_GZ))
$(eval SIZE:=$(call file_size,$(TC)))
$(eval XZ_RATIO:=$(shell echo "scale=2;100*$(XZ_SIZE)/$(SIZE)" | bc -q))
$(eval GZ_RATIO:=$(shell echo "scale=2;100*$(GZ_SIZE)/$(SIZE)" | bc -q))
@echo "xz;$(XZ_RATIO);xz -9\ngzip;$(GZ_RATIO);gzip -9" > $@
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/README.md�����������������������������������������������������������������0000664�0000000�0000000�00000004403�12412610011�0016612�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarks for sdsl data structures
This directory contains a set of benchmarks for [sdsl][sdsl]
data structures. Each benchmark is in its own subdirectory and
so far we have:
* [indexing_count](./indexing_count): Evaluates the performance
of count queries on different FM-Indexes/CSAs. Count query
means _How many times occurs my pattern P in the text T?_
* [indexing_extract](./indexing_extract): Evaluates the performance
of extracting continues sequences of text out of FM-Indexes/CSAs.
* [indexing_locate](./indexing_locate): Evaluates the performance
of _locate queries_ on different FM-Indexes/CSAs. Locate query
means _At which positions does pattern P occure in T?_
* [rrr_vector](./rrr_vector): Evaluates the performance of
the 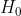-compressed
bitvector [rrr_vector](../include/sdsl/rrr_vector.hpp).
Operations `access`, `rank`, and `select` are benchmarked on
different inputs.
* [wavelet_trees](./wavelet_trees): Evaluates the performance of wavelet trees.
You can executed the benchmarks by calling `make timing`
in the specific subdirectory.
Test inputs will be automatically generated or downloaded
from internet sources, such as the excellent [Pizza&Chili][pz]
website, and stored in the [data](./data) directory.
Directory [tmp](./tmp) is used to store temporary files (like
plain suffix arrays) which are used to generate compressed
structures.
## Prerequisites
The following tools, which are available as packages for Mac OS X and
most Linux distributions, are required:
* [cURL][CURL] is required by the test input download script.
* [gzip][GZIP] is required to extract compressed files.
## Literature
The benchmark code originates from the following article and can be used
to easily reproduce the results presented in the paper.
Simon Gog, Matthias Petri: _Optimized Succinct Data Structures for Massive Data_. 2013.
Accepted for publication in Software, Practice and Experience.
[Preprint][PP]
## Author
Simon Gog (simon.gog@gmail.com)
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[PP]: http://people.eng.unimelb.edu.au/sgog/optimized.pdf "Preprint"
[CURL]: http://curl.haxx.se/ "cURL"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/basic_functions.R���������������������������������������������������������0000664�0000000�0000000�00000013017�12412610011�0020630�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Read a file called file_name and create a data frame the following way
# (1) Parse all the lines of the form
# '# key = value'
# (2) Each unique key gets a column
data_frame_from_key_value_pairs <- function(file_name){
lines <- readLines(file_name)
lines <- lines[grep("^#.*=.*",lines)]
d <- gsub("^#","",gsub("[[:space:]]","",unlist(strsplit(lines,split="="))))
keys <- unique(d[seq(1,length(d),2)])
keynr <- length(keys)
dd <- d[seq(2,length(d),2)]
dim(dd) <- c( keynr, length(dd)/keynr )
data <- data.frame(t(dd))
names(data) <- keys
for (col in keys){
t <- as.character(data[[col]])
suppressWarnings( tt <- as.numeric(t) )
if ( length( tt[is.na(tt)] ) == 0 ){ # if there are not NA in tt
data[[col]] <- tt
}
}
data
}
# Takes a vector v=(v1,v2,v3,....)
# and returns a vector which repeats
# each element x times. So for two we get
# (v1,v1,v2,v2,v3,v3....)
expand_vec <- function( v, x ){
v <- rep(v,x)
dim(v) <- c(length(v)/x,x)
v <- t(v)
dim(v) <- c(1,nrow(v)*ncol(v))
v
}
# Takes a vector v=(v1,v2,v3,....)
# and returns a vector which appends x-1
# NA after each value. So for x=2 we get
# (v1,NA,v2,NA,v3,NA....)
expand_vec_by_NA <- function( v, x ){
v <- c(v, rep(NA,length(v)*(x-1)))
dim(v) <- c(length(v)/x,x)
v <- t(v)
dim(v) <- c(1,nrow(v)*ncol(v))
v
}
format_str_fixed_width <- function(x, width=4){
sx <- as.character(x)
if ( nchar(sx) < width ){
for (i in 1:(width-nchar(sx))){
sx <- paste("\\D",sx, sep="")
}
}
sx
}
# Check if package is installed
# found at: http://r.789695.n4.nabble.com/test-if-a-package-is-installed-td1750671.html#a1750674
is.installed <- function(mypkg) is.element(mypkg, installed.packages()[,1])
sanitize_column <- function(column){
column <- gsub("_","\\\\_",column)
column <- gsub(" >",">",column)
column <- gsub("<","{\\\\textless}",column)
column <- gsub(">","{\\\\textgreater}",column)
column <- gsub(",",", ",column)
}
# tranforms a vector of index ids to a vector which contains the
# corresponding latex names.
# Note: each id should only appear once in the input vector
mapids <- function(ids, mapit){
as.character(unlist(mapit[ids]))
}
id2latex <- function(config_file, latexcol, idcol=1){
index_info <- read.csv(config_file, sep=";",header=F, comment.char="#")
res <- data.frame( t(as.character(index_info[[latexcol]])), stringsAsFactors=F )
names(res) <- as.character(index_info[[idcol]])
res
}
idAndValue <- function(config_file, valuecol, idcol=1){
res <- read.csv(config_file, sep=";",header=F, comment.char="#")
res[c(idcol, valuecol)]
}
readConfig <- function(config_file, mycolnames){
config <- read.csv(config_file, sep=";",header=F, comment.char="#",stringsAsFactors=F)
rownames(config) <- config[[1]]
colnames(config) <- mycolnames
config
}
# Creates a LaTeX table containing index names and sdsl type
# config_file The index.config storing the type information
# index_ids Filter the index.config entires with this index ids
# id_col Column `id_col` contains the IDs
# name_col Column `name_col` contains the latex names
# type_col Column `type_col` contains the type
typeInfoTable <- function(config_file, index_ids, id_col=1, name_col=3, type_col=2){
x <- read.csv(config_file, sep=";", header=F, comment.char="#",stringsAsFactors=F)
rownames(x) <- x[[id_col]]
x <- x[index_ids,] # filter
sdsl_type <- sanitize_column(x[[type_col]])
sdsl_name <- x[[name_col]]
res <- "
\\renewcommand{\\arraystretch}{1.3}
\\begin{tabular}{@{}llp{10cm}@{}}
\\toprule
Identifier&&sdsl type\\\\ \\cmidrule{1-1}\\cmidrule{3-3}"
res <- paste(res, paste(sdsl_name,"&&\\footnotesize\\RaggedRight\\texttt{",sdsl_type,"}\\\\",sep="",collapse=" "))
res <- paste(res,"
\\bottomrule
\\end{tabular}")
}
# returns x concatenated with x reversed
x_for_polygon <- function(x){
c( x, rev(x) )
}
# return y concatenated with rep(0, length(y))
y_for_polygon <- function(y){
c( y, rep(0, length(y)) )
}
# ncols Number of columns in the figure
# nrows Number of rows in the figure
multi_figure_style <- function(nrows, ncols){
par(mfrow=c(nrows, ncols))
par(las=1) # axis labels always horizontal
par(yaxs="i") # don't add +- 4% to the yaxis
par(xaxs="i") # don't add +- 4% to the xaxis
# distance (x1,x2,x3) of axis parts from the axis. x1=axis labels or titles
# x2=tick marks, x3=tick marks symbol
par(mgp=c(2,0.5,0))
# length of tick mark as a fraction of the height of a line of text, default=-0.5
par(tcl=-0.2)
par(oma=c(2.5,2.7,0,0.2)) # outer margin (bottom,left,top,right)
par(mar=c(1,1,1.5,0.5)) # inner margin (bottom,left,top,right)
}
# Draw the heading of diagrams
# text Text which should be displayed in the heading
draw_figure_heading <- function(text){
# scale Y
SY <- function(val){ if( par("ylog") ){ 10^val } else { val } }
SX <- function(val){ if( par("xlog") ){ 10^val } else { val } }
rect(xleft=SX(par("usr")[1]), xright=SX(par("usr")[2]),
ybottom=SY(par("usr")[4]), ytop=SY(par("usr")[4]*1.1) ,xpd=NA,
col="grey80", border="grey80" )
text(labels=text,y=SY(par("usr")[4]*1.02), adj=c(0.5, 0),x=SX((par("usr")[1]+par("usr")[2])/2),xpd=NA,cex=1.4)
}
print_info <- function(){
Sys.info("release")
Sys.info("sysname")
Sys.info("version")
Sys.info("nodename")
Sys.info("machine")
Sys.info("login")
Sys.info("user")
Sys.info("effective_user")
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/data/���������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0016243�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/data/.gitignore�����������������������������������������������������������0000664�0000000�0000000�00000000035�12412610011�0020231�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!get_corpus.sh
!.gitignore
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/�������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021225�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/Makefile�����������������������������������������������0000664�0000000�0000000�00000027464�12412610011�0022702�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../Make.helper
CXX_FLAGS = $(MY_CXX_FLAGS) $(MY_CXX_OPT_FLAGS) -I$(INC_DIR) -L$(LIB_DIR)
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
SRC_DIR = src
TMP_DIR = ../tmp
PAT_DIR = pattern
BIN_DIR = bin
TC_PATHS:=$(call config_column,test_case.config,2)
TC_PATHS_INT:=$(call config_column,test_case_int.config,2)
TC_DICT_PATHS:=$(call config_column,dic.config,2)
TC_IDS:=$(call config_ids,test_case.config)
TC_IDS_INT:=$(call config_ids,test_case_int.config)
IDX_IDS:=$(call config_ids,index.config)
IDX_IDS_INT:=$(call config_ids,index_int.config)
PAT_LENS:=$(call config_column,pattern_length.config,1)
PAT_LENS_INT:=$(call config_column,pattern_length_int.config,1)
RESULT_FILE=results/all.txt
RESULT_FILE_INT=results/all_int.txt
QUERY_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/query_idx_$(IDX_ID))
QUERY_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/query_int_idx_$(IDX_ID))
BUILD_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/build_idx_$(IDX_ID))
BUILD_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/build_int_idx_$(IDX_ID))
SIZES_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/size_of_idx_$(IDX_ID))
SIZES_EXECS_INT = $(foreach IDX_ID,$(IDX_IDS_INT),$(BIN_DIR)/size_of_int_idx_$(IDX_ID))
PATTERNS = $(foreach TC_ID,$(TC_IDS),\
$(foreach PAT_LEN,$(PAT_LENS),$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern))
PATTERNS_INT = $(foreach TC_ID,$(TC_IDS_INT),\
$(foreach PAT_LEN,$(PAT_LENS_INT),$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern.int))
INDEXES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),indexes/$(TC_ID).$(IDX_ID).byte))
INDEXES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),indexes/$(TC_ID).$(IDX_ID).int))
SIZES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),info/$(TC_ID).$(IDX_ID).size))
SIZES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),info/$(TC_ID).$(IDX_ID).size.int))
HTML = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),info/$(TC_ID).$(IDX_ID).byte.html))
HTML_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),info/$(TC_ID).$(IDX_ID).int.html))
TIME_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach PAT_LEN,$(PAT_LENS),results/$(TC_ID).$(IDX_ID).$(PAT_LEN).byte)))
TIME_FILES_INT = $(foreach IDX_ID,$(IDX_IDS_INT),\
$(foreach TC_ID,$(TC_IDS_INT),\
$(foreach PAT_LEN,$(PAT_LENS_INT),results/$(TC_ID).$(IDX_ID).$(PAT_LEN).int)))
COMP_FILES = $(addsuffix .z.info,$(TC_PATHS) $(TC_PATHS_INT))
HELPER_BINS = $(BIN_DIR)/gen_pattern $(BIN_DIR)/gen_pattern_int \
$(BIN_DIR)/word_pat2char_pat
all: $(BUILD_EXECS) $(BUILD_EXECS_INT) \
$(QUERY_EXECS) $(QUERY_EXECS_INT) \
$(SIZES_EXECS) $(SIZES_EXECS_INT) \
$(HELPER_BINS)
info: $(SIZES_EXECS) $(SIZES_EXECS_INT) $(SIZES) \
$(SIZES_INT) $(HTML_INT) $(HTML) \
info/sizes.txt \
info/sizes_int.txt
info/sizes.txt: $(SIZES)
@cat $(SIZES) > $@
info/sizes_int.txt: $(SIZES)
@cat $(SIZES_INT) > $@
indexes: $(INDEXES) $(INDEXES_INT)
input: $(TC_PATHS) $(TC_PATHS_INT) $(TC_DICT_PATHS)
pattern: input $(PATTERNS) $(BIN_DIR)/gen_pattern $(PATTERNS_INT) $(BIN_DIR)/gen_pattern_int
compression: input $(COMP_FILES)
timing: input indexes pattern $(TIME_FILES) $(TIME_FILES_INT) compression info
@cat $(TIME_FILES) > $(RESULT_FILE)
@cat $(TIME_FILES_INT) > $(RESULT_FILE_INT)
@cd visualize; make
# results/[TC_ID].[IDX_ID].[PAT_LEN].byte
results/%.byte: $(BUILD_EXECS) $(QUERY_EXECS) $(INDEXES) $(PATTERNS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval PAT_LEN:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "Run timing for $(IDX_ID) on $(TC_ID) with patterns of length $(PAT_LEN)"
@$(BIN_DIR)/query_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte \
$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern >> $@
# results/[TC_ID].[IDX_ID].[PAT_LEN].byte
results/%.int: $(BUILD_EXECS) $(QUERY_EXECS_INT) $(INDEXES_INT) $(PATTERNS_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval PAT_LEN:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case_int.config,$(TC_ID),3))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "Run timing for $(IDX_ID) on $(TC_ID) with patterns of length $(PAT_LEN)"
@$(BIN_DIR)/query_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int \
$(PAT_DIR)/$(TC_ID).$(PAT_LEN).pattern.int >> $@
# indexes/[TC_ID].[IDX_ID].byte
indexes/%.byte: $(BUILD_EXECS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
@echo "Building index $(IDX_ID) on $(TC)"
@$(BIN_DIR)/build_idx_$(IDX_ID) $(TC) $(TMP_DIR) $@
# indexes/[TC_ID].[IDX_ID].int
indexes/%.int: $(BUILD_EXECS_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
@echo "Building index $(IDX_ID) on $(TC)"
@$(BIN_DIR)/build_int_idx_$(IDX_ID) $(TC) $(TMP_DIR) $@
# info/[TC_ID].[IDX_ID]
info/%.size: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get size of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte >> $@
# info/[TC_ID].[IDX_ID]
info/%.size.int: $(INDEXES_INT)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get size of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int >> $@
# info/[TC_ID].[IDX_ID]
info/%.byte.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get html of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).byte $@
# info/[TC_ID].[IDX_ID]
info/%.int.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(eval SIZE:=$(call file_size,$(TC)))
@echo "# TC_ID = $(TC_ID)" > $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# text_size = $(SIZE)" >> $@
@echo "Get html of index for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/size_of_int_idx_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID).int $@
# $(PAT_DIR)/[TC_ID].[PAT_LEN].pattern.int
$(PAT_DIR)/%.pattern.int: $(BIN_DIR)/gen_pattern_int $(BIN_DIR)/word_pat2char_pat
@echo $*
$(eval TC_ID:=$(call dim,1,$*))
$(eval PAT_LEN:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case_int.config,$(TC_ID),2))
$(BIN_DIR)/gen_pattern_int $(TC) $(TMP_DIR)/$(TC_ID).pat.csa $(TMP_DIR) $(PAT_LEN) 200 $@
$(eval DIC_PATH:=$(call config_select,dic.config,$(TC_ID),2))
$(BIN_DIR)/word_pat2char_pat $@ $(DIC_PATH) > $@.txt
# $(PAT_DIR)/[TC_ID].[PAT_LEN].pattern
$(PAT_DIR)/%.pattern: $(BIN_DIR)/gen_pattern
@echo $*
$(eval TC_ID:=$(call dim,1,$*))
$(eval PAT_LEN:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
$(BIN_DIR)/gen_pattern $(TC) $(TMP_DIR)/$(TC_ID).pat.csa $(TMP_DIR) $(PAT_LEN) 200 $@
$(BIN_DIR)/gen_pattern: $(SRC_DIR)/gen_pattern.cpp
@echo "Build pattern generation program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/gen_pattern.cpp \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/gen_pattern_int: $(SRC_DIR)/gen_pattern.cpp
@echo "Build pattern generation program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/gen_pattern.cpp \
-DINT_ALPHABET \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/size_of_idx_%: $(SRC_DIR)/size_of_idx.cpp
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Build size info program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/size_of_idx.cpp \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/size_of_int_idx_%: $(SRC_DIR)/size_of_idx.cpp
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Build size info program"
$(MY_CXX) $(CXX_FLAGS) $(SRC_DIR)/size_of_idx.cpp \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) -I$(INC_DIR) -o $@ $(LIBS)
# $(BIN_DIR)/build_idx_[IDX_ID]
$(BIN_DIR)/build_idx_%: $(SRC_DIR)/build_idx.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling build_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/build_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# $(BIN_DIR)/build_idx_[IDX_ID]
$(BIN_DIR)/build_int_idx_%: $(SRC_DIR)/build_idx.cpp index_int.config
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Compiling build_int_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/build_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/query_idx_[IDX_ID]
$(BIN_DIR)/query_idx_%: $(SRC_DIR)/query_idx.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling query_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_ID=\"$*\" -DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/query_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/query_idx_[IDX_ID]
$(BIN_DIR)/query_int_idx_%: $(SRC_DIR)/query_idx.cpp index_int.config
$(eval IDX_TYPE:=$(call config_select,index_int.config,$*,2))
@echo "Compiling query_int_idx_$*"
$(MY_CXX) $(CXX_FLAGS) \
-DIDX_ID=\"$*\" -DIDX_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/query_idx.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
$(BIN_DIR)/word_pat2char_pat: $(SRC_DIR)/word_pat2char_pat.cpp
@echo "Compiling word_pat2char_pat.cpp"
$(MY_CXX) $(CXX_FLAGS) \
$(SRC_DIR)/word_pat2char_pat.cpp \
-o $@
dic/%:
$(eval URL:=$(call config_filter,dic.config,$@,4))
@$(if $(URL),,\
$(error "No download link for dictionary $@") )
@echo "Download dictionary from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
../data/%.int.sdsl:
$(eval URL:=$(call config_filter,test_case_int.config,$@,4))
@$(if $(URL),,\
$(error "No download link nor generation program specified for test case $@") )
@echo "Download input from $(URL) using curl"
$(eval DEST_DIR:=$(shell dirname $@))
cd $(DEST_DIR); curl -O $(URL)
$(eval FILE:=$(DEST_DIR)/$(notdir $(URL)))
@$(if $(filter-out ".gz",$(FILE)),\
echo "Extract file $(FILE) using gunzip";\
gunzip $(FILE))
include ../Make.download
clean-build:
@echo "Remove executables"
rm -f $(QUERY_EXECS) $(SIZES_EXECS) $(BUILD_EXECS) \
$(QUERY_EXECS_INT) $(SIZES_EXECS_INT) $(BUILD_EXECS_INT) \
$(HELPER_BINS)
clean: clean-build
@echo "Remove info files and indexes"
rm -f $(INDEXES) $(INDEXES_INT)
cleanresults:
@echo "Remove result files and pattern"
rm -f $(TIME_FILES) \
$(RESULT_FILE) \
$(TIME_FILES_INT) \
$(RESULT_FILE_INT) \
$(SIZES) $(SIZES_INT) \
$(HTML) $(HTML_INT)
rm -f $(PATTERNS) $(PATTERNS_INT)
cleanall: clean cleanresults
@echo "Remove all generated files."
rm -f $(TMP_DIR)/*
rm -f $(PAT_DIR)/*
cd visualize; make clean
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/README.md����������������������������������������������0000664�0000000�0000000�00000011145�12412610011�0022506�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking top-k search on simple document search implementations
## Methodology
The benchmark setup is close to the one used in the ESA 2010 article
of Culpepper, Navarro, Puglisi and Turpin.
Explored dimensions:
* text type
* instance size (just adjust the `test_case.config` file for this)
* index implementations
- [Sadakane's method](src/doc_list_index_sada.hpp)
- [Wavelet tree greedy traversal](src/doc_list_index_greedy.hpp)
- [Wavelet tree quantile probing](src/doc_list_index_qprobing.hpp)
## Directory structure
* [bin](./bin): Contains the executables of the project.
- `build_*` index build executables
- `gen_pattern*` executable to generate pattern sets
- `query_*` index query executables
- `size_of_*` generate size and space breakdowns
* [dic](./dic): Contains dictionaries for integer inputs.
* [indexes](./indexes): Contains the generated indexes.
* [info](./info): Contains space breakdowns.
* [pattern](./pattern): Contains generated pattern.
* [results](./results): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which generates
a report.
## Test data
* ENWIKISML was generated by
- downloading a dump of a prefix of the English wikipedia (at the 5th of August 2013)
- applying the `WikiExtractor.py` program Version 2.5
from Giuesppe Attardi and Antonio Fuschetto (Univserity of Pisa).
- Removing the ``-tag and replacing the ``
take by `\1`
* ENWIKIBIG was generated the same way but for the complete
English wikipedia (retrieved at the 8th of July 2013).
* The integer version, ENWIKISMLINT and ENWIKIBIGINT, were
generated from ENWIKISML and ENWIKIBIG by
- applying the [stanford-parser.jar][SP] from the NL group
at Stanford to tokenize the input (options
`untokenizable=allKeep,normalizeParentheses=false,normalizeOtherBrackets=false`)
- assign the document seperator the ID `1`, and the ID of the other
tokens is their rank in the reverse sorting of frequency (starting at `2`).
- The resulting sequence of integers is stored in a bit-compressed
`int_vector`.
- The generated dictionaries containing on each line
a `(word, ID, occurrences)`-tuple.
* PROTEINS is the concatenation of 143,244 Human and Mouse
proteins sequences from the swissport database.
* Availability: ENWIKIBIG (character and integer version)
are available on request. The other files are downloaded
automatically during the execution of the benchmark.
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with package `tikzDevice`. You can install the
package by calling
`install.packages("filehash", repos="http://cran.r-project.org")`
and
`install.packages("tikzDevice", repos="http://R-Forge.R-project.org")`
in `R`.
- Compressors [xz][XZ] and [gzip][GZIP] are used to get
compression baselines.
- [pdflatex][LT] to generate the pdf reports.
## Usage
Command `make timing` will download the small test cases, compile executables,
build the indexes, run the queries, and generate a report. The
benchmark run 5 minutes and 40 seconds (without downloading the files)
and generated [this report on my machine][RES].
## Customization of the benchmark
The project contains several configuration files:
* [index.config](./index.config): Specify character
based indexes' ID, sdsl-class and LaTeX-name for the report.
* [index_int.config](./index_int.config): Specify word
based indexes' ID, sdsl-class and LaTeX-name for the report.
* [test_case.config](./test_case.config): Specify character based collections'
ID, path, LaTeX-name for the report, and download URL.
* [test_case_int.config](./test_case_int.config): Specify word based collections'
ID, path, LaTeX-name for the report, and download URL.
* [pattern_length.config](./pattern_length.config): Specify the
lengths of queried pattern for character based indexes.
* [pattern_length_int.config](./pattern_length_int.config): Specify
lengths of queried pattern for word based indexes.
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[RPJ]: http://www.r-project.org/ "R"
[XZ]: http://tukaani.org/xz/ "XZ Compressor"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
[SP]: http://nlp.stanford.edu/software/tokenizer.shtml
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/doc_re_time.pdf "doc_re_time.pdf"
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/bin/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021775�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/bin/.gitignore�����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023762�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic.config���������������������������������������������0000664�0000000�0000000�00000000622�12412610011�0023153�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration file for dictionary files
# for integer based inputs
#
# (1) Identifier for test integer test file
# (has to exist in test_case_int.config)
# (2) Path to dictionary
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENWIKISMLINT;dic/enwiki-20130805-pages-articles1.dic;enwiki-dic;http://people.eng.unimelb.edu.au/sgog/data/enwiki-20130805-pages-articles1.dic.gz
��������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021764�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/dic/.gitignore�����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023751�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/index.config�������������������������������������������0000664�0000000�0000000�00000001310�12412610011�0023516�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specified sdsl index structures that are used in the benchmark.
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATEX_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in INDEX_ID.
# * TYPE : Corresponding type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
GREEDY;doc_list_index_greedy<>;GREEDY
#GREEDY-RRR;doc_list_index_greedy>,1000000,1000000>,wt_int>>;GREEDY-RRR
#QPROBING;doc_list_index_qprobing<>;QPROBING
SADA;doc_list_index_sada, 32, 1000000, text_order_sa_sampling>>>;SADA
SORT;doc_list_index_sort<>;SORT
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/index_int.config���������������������������������������0000664�0000000�0000000�00000001263�12412610011�0024377�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specified sdsl index structures that are used in the benchmark.
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATEX_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in INDEX_ID.
# * TYPE : Corresponding type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
GREEDYINT;doc_list_index_greedy>,1000000,1000000>>;GREEDY-I
SADAINT;doc_list_index_sada, 32, 1000000, text_order_sa_sampling>>>;SADA-I
SORTINT;doc_list_index_sort, 32, 1000000, text_order_sa_sampling>>>;SORT-I
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/indexes/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022664�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/indexes/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024651�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/info/��������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022160�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/info/.gitignore����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024145�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022702�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024667�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern_length.config����������������������������������0000664�0000000�0000000�00000000122�12412610011�0025425�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# pattern length
3;
4;
5;
6;
7;
8;
9;
10;
11;
12;
13;
14;
15;
16;
17;
18;
19;
20;
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/pattern_length_int.config������������������������������0000664�0000000�0000000�00000000055�12412610011�0026304�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# pattern length
2;
3;
4;
5;
6;
7;
8;
9;
10;
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/results/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022726�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/results/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024713�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022014�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/build_idx.cpp��������������������������������������0000664�0000000�0000000�00000002114�12412610011�0024461�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include "doc_list_index.hpp"
#include
#include
#include
using namespace std;
using namespace sdsl;
using idx_type = IDX_TYPE;
int main(int argc, char* argv[])
{
if (argc < 4) {
cout << "Usage: " << argv[0] << " collection_file tmp_dir index_file" << endl;
cout << " Generates an index and stores result in index_file" << endl;
cout << " Temporary files are stored in tmp_dir." << endl;
return 1;
}
string collection_file = argv[1];
string id = util::basename(collection_file);
string tmp_dir = argv[2];
string idx_file = argv[3];
using timer = std::chrono::high_resolution_clock;
auto start = timer::now();
idx_type idx;
cache_config cconfig(false, tmp_dir, id);
construct(idx, collection_file, cconfig, idx_type::WIDTH==8 ? 1 : 0);
auto stop = timer::now();
auto elapsed = stop-start;
std::cout << "construction time = " << std::chrono::duration_cast(elapsed).count() << std::endl;
store_to_file(idx, idx_file);
}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index.hpp���������������������������������0000664�0000000�0000000�00000000750�12412610011�0025516�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#ifndef DOC_LIST_INDEX
#define DOC_LIST_INDEX
#include
#include
struct doc_list_tag {};
template
void
construct(t_index& idx, const std::string& file, sdsl::cache_config& config, uint8_t num_bytes, doc_list_tag)
{
t_index tmp_idx(file, config, num_bytes);
idx.swap(tmp_idx);
}
#include "doc_list_index_sada.hpp"
#include "doc_list_index_greedy.hpp"
#include "doc_list_index_qprobing.hpp"
#include "doc_list_index_sort.hpp"
#endif
������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index_greedy.hpp��������������������������0000664�0000000�0000000�00000015603�12412610011�0027060�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*!
* This file contains a document listing class, which implements
* strategy GREEDY in the article:
* J. S. Culpepper, G. Navarro, S. J. Puglisi and A. Turpin:
* ,,Top-k Ranked Document Search in General Text Databases''
* Proceedings Part II of the 18th Annual European Symposium on
* Algorithms (ESA 2010)
*/
#ifndef DOCUMENT_LISING_GREEDY_INCLUDED
#define DOCUMENT_LISING_GREEDY_INCLUDED
#include
#include
#include
#include
#include
#include
#include
#include "doc_list_index.hpp"
using std::vector;
namespace sdsl
{
template<
class t_csa = csa_wt>, 1000000, 1000000>,
class t_wtd = wt_int,select_support_scan<1>,select_support_scan<0>>,
typename t_csa::char_type t_doc_delim = 1
>
class doc_list_index_greedy
{
public:
using size_type = typename t_wtd::size_type;
using value_type = typename t_wtd::value_type;
typedef t_csa csa_type;
typedef t_wtd wtd_type;
typedef std::vector> list_type;
typedef doc_list_tag index_category;
enum { WIDTH = t_csa::alphabet_category::WIDTH };
class result : public list_type
{
private:
size_type m_sp, m_ep;
public:
// Number of occurrences
size_type count() {
return m_ep-m_sp+1;
}
// Constructors for an empty result and for a result in the interval [sp, ep]:
result(size_type sp, size_type ep,list_type&& l) : list_type(l), m_sp(sp), m_ep(ep) {}
result() : m_sp(1), m_ep(0) {}
result(size_type sp, size_type ep) : m_sp(sp), m_ep(ep) {}
result& operator=(const result& res) {
if (this != &res) {
list_type::operator=(res);
m_sp = res.m_sp;
m_ep = res.m_ep;
}
return *this;
}
};
struct wt_range_t {
using node_type = typename wtd_type::node_type;
node_type v;
range_type r;
size_t size() const {
return r.second - r.first + 1;
}
bool operator<(const wt_range_t& x) const {
if (x.size() != size())
return size() < x.size();
return v.sym > x.v.sym;
}
wt_range_t() {}
wt_range_t(const node_type& _v, const range_type& _r):
v(_v), r(_r) {}
};
protected:
size_type m_doc_cnt; // number of documents in the collection
csa_type m_csa_full; // CSA built from the collection text
wtd_type m_wtd; // wtd build from the collection text
public:
//! Default constructor
doc_list_index_greedy() { }
doc_list_index_greedy(std::string file_name, sdsl::cache_config& cconfig, uint8_t num_bytes) {
construct(m_csa_full, file_name, cconfig, num_bytes);
const char* KEY_TEXT = key_text_trait::KEY_TEXT;
std::string text_file = cache_file_name(KEY_TEXT, cconfig);
bit_vector doc_border;
construct_doc_border(text_file,doc_border);
bit_vector::rank_1_type doc_border_rank(&doc_border);
m_doc_cnt = doc_border_rank(doc_border.size());
int_vector_buffer<0> sa_buf(cache_file_name(conf::KEY_SA, cconfig));
{
int_vector<> D;
construct_D_array(sa_buf, doc_border_rank, m_doc_cnt, D);
std::string d_file = cache_file_name("DARRAY", cconfig);
store_to_file(D, d_file);
util::clear(D);
construct(m_wtd, d_file);
sdsl::remove(d_file);
}
}
size_type doc_cnt()const {
return m_wtd.sigma-1; // subtract one, since zero does not count
}
size_type word_cnt()const {
return m_wtd.size()-doc_cnt();
}
size_type serialize(std::ostream& out, structure_tree_node* v=NULL, std::string name="")const {
structure_tree_node* child = structure_tree::add_child(v, name, util::class_name(*this));
size_type written_bytes = 0;
written_bytes += write_member(m_doc_cnt, out, child, "doc_cnt");
written_bytes += m_csa_full.serialize(out, child, "csa_full");
written_bytes += m_wtd.serialize(out, child, "wtd");
structure_tree::add_size(child, written_bytes);
return written_bytes;
}
void load(std::istream& in) {
read_member(m_doc_cnt, in);
m_csa_full.load(in);
m_wtd.load(in);
}
void swap(doc_list_index_greedy& dr) {
if (this != &dr) {
std::swap(m_doc_cnt, dr.m_doc_cnt);
m_csa_full.swap(dr.m_csa_full);
m_wtd.swap(dr.m_wtd);
}
}
//! Search for the k documents which contain the search term most frequent
template
size_type search(t_pat_iter begin, t_pat_iter end, result& res, size_t k) const {
size_type sp=1, ep=0;
if (0 == backward_search(m_csa_full, 0, m_csa_full.size()-1, begin, end, sp, ep)) {
res = result();
return 0;
} else {
auto tmp_res = topk_greedy(sp, ep, k);
res = result(sp, ep, std::move(tmp_res));
return ep-sp+1;
}
}
private:
//! Construct the doc_border bitvector by streaming the text file
void
construct_doc_border(const std::string& text_file, bit_vector& doc_border) {
int_vector_buffer text_buf(text_file);
doc_border = bit_vector(text_buf.size(), 0);
for (size_type i = 0; i < text_buf.size(); ++i) {
if (t_doc_delim == text_buf[i]) {
doc_border[i] = 1;
}
}
}
void
construct_D_array(int_vector_buffer<0>& sa_buf,
bit_vector::rank_1_type& doc_border_rank,
const size_type doc_cnt,
int_vector<>& D) {
D = int_vector<>(sa_buf.size(), 0, bits::hi(doc_cnt+1)+1);
for (size_type i = 0; i < sa_buf.size(); ++i) {
uint64_t d = doc_border_rank(sa_buf[i]+1);
D[i] = d;
}
}
//! Returns the top k most frequent documents in D[lb..rb]
/*!
* \param lb Left array border in D.
* \param rb Right array border in D.
* \param k The number of documents to return.
* \returns the top-k items in ascending order.
*/
std::vector< std::pair >
topk_greedy(size_type lb, size_type rb, size_type k) const {
std::vector< std::pair > results;
std::priority_queue heap;
heap.emplace(wt_range_t(m_wtd.root(), {lb, rb}));
while (! heap.empty()) {
wt_range_t e = heap.top(); heap.pop();
if (m_wtd.is_leaf(e.v)) {
results.emplace_back(e.v.sym, e.size());
if (results.size()==k) {
break;
}
continue;
}
auto child = m_wtd.expand(e.v);
auto child_ranges = m_wtd.expand(e.v, e.r);
auto left_range = std::get<0>(child_ranges);
auto right_range = std::get<1>(child_ranges);
if (!empty(left_range)) {
heap.emplace(wt_range_t(std::get<0>(child), left_range));
}
if (!empty(right_range)) {
heap.emplace(wt_range_t(std::get<1>(child), right_range));
}
}
return results;
};
};
} // end namespace
#endif
�����������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index_qprobing.hpp������������������������0000664�0000000�0000000�00000010101�12412610011�0027406�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*!
* This file contains a document listing class, which implements
* strategy QUANTILE in the article:
* J. S. Culpepper, G. Navarro, S. J. Puglisi and A. Turpin:
* ,,Top-k Ranked Document Search in General Text Databases''
* Proceedings Part II of the 18th Annual European Symposium on
* Algorithms (ESA 2010)
*/
#ifndef DOCUMENT_LISING_QPROBING_INCLUDED
#define DOCUMENT_LISING_QPROBING_INCLUDED
#include "doc_list_index_greedy.hpp"
#include
#include
#include
#include
#include
using std::vector;
namespace sdsl
{
template<
class t_csa = csa_wt>, 1000000, 1000000>,
class t_wtd = wt_int,select_support_scan<1>,select_support_scan<0>>,
typename t_csa::char_type t_doc_delim = 1
>
class doc_list_index_qprobing : public doc_list_index_greedy
{
private:
using base_type = doc_list_index_greedy;
using base_type::m_csa_full;
using base_type::m_wtd;
public:
using size_type = typename base_type::size_type;
using value_type = typename t_wtd::value_type;
using result = typename base_type::result;
doc_list_index_qprobing() : base_type() {}
doc_list_index_qprobing(std::string file_name, sdsl::cache_config& cconfig, uint8_t num_bytes) : base_type(file_name, cconfig, num_bytes) {}
//! Search for the k documents which contains the search term most frequent
template
size_type search(t_pat_iter begin, t_pat_iter end, result& res, size_t k) const {
size_type sp=1, ep=0;
if (0 == backward_search(m_csa_full, 0, m_csa_full.size()-1, begin, end, sp, ep)) {
res = result();
return 0;
} else {
auto tmp_res = topk_qprobing(sp, ep ,k);
res = result(sp, ep, std::move(tmp_res));
return ep-sp+1;
}
}
//! Returns the top-k most frequent documents in m_wtd[lb..rb]
/*!
* \param lb left array bound in T
* \param rb right array bound in T
* \param k the number of documents to return
* \returns the top-k items in ascending order.
*/
std::vector< std::pair >
topk_qprobing(size_type lb, size_type rb,size_type k) const {
using p_t = std::pair;
std::vector results;
auto comp = [](p_t& a,p_t& b) { return a.second > b.second; };
std::priority_queue,decltype(comp)> heap(comp);
bit_vector seen(1ULL << m_wtd.max_level); // TODO: better idea?
/* we start probing using the largest power smaller than len */
size_type len = rb-lb+1;
size_type power2greaterlen = 1 << (bits::hi(len)+1);
size_type probe_interval = power2greaterlen >> 1;
/* we probe the smallest elem (pos 0 in sorted array) only once */
auto qf = quantile_freq(m_wtd,lb,rb,0);
heap.push(qf);
seen[qf.first] = 1;
qf = quantile_freq(m_wtd,lb,rb,probe_interval);
if (!seen[qf.first]) heap.push(qf);
seen[qf.first] = 1;
while (probe_interval > 1) {
size_type probe_pos = probe_interval >> 1;
while (probe_pos < len) {
qf = quantile_freq(m_wtd,lb,rb,probe_pos);
if (!seen[qf.first]) { /* not in heap */
if (heap.size()>= 1;
/* we have enough or can't find anything better */
if (heap.size() == k && probe_interval-1 <= heap.top().second) break;
}
/* populate results */
while (!heap.empty()) {
results.emplace(results.begin() , heap.top());
heap.pop();
}
return results;
};
};
} // end namespace
#endif
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index_sada.hpp����������������������������0000664�0000000�0000000�00000034512�12412610011�0026511�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*! How to code a parametrizable document listing data structure
*
* This file contains a document listing class implemented as
* suggested in Kunihiko Sadakane's article:
* ,,Succinct Data Structures for Flexible Text Retrieval Systems''
* Journal of Discrete Algorithms, 2007.
*
*/
#ifndef DOCUMENT_LISING_SADA_INCLUDED
#define DOCUMENT_LISING_SADA_INCLUDED
#include
#include
#include
#include
#include
#include
#include
#include "doc_list_index.hpp"
using std::vector;
namespace sdsl
{
template
struct sa_trait {
typedef uint64_t value_type;
typedef std::vector vec_type;
enum { num_bytes = 0 };
template
static void calc_sa(t_sa& sa, vec_type& text) {
qsufsort::construct_sa(sa, text);
}
};
template<>
struct sa_trait<8> {
typedef uint8_t value_type;
typedef std::vector vec_type;
enum { num_bytes = 1 };
template
static void calc_sa(t_sa& sa, vec_type& text) {
algorithm::calculate_sa(text.data(), text.size(), sa);
}
};
template<
class t_csa_full = csa_wt>, 30, 1000000, text_order_sa_sampling<> >,
class t_range_min = rmq_succinct_sct,
class t_range_max = rmq_succinct_sct,
class t_doc_border = sd_vector<>,
class t_doc_border_rank = typename t_doc_border::rank_1_type,
class t_doc_border_select = typename t_doc_border::select_1_type,
typename t_csa_full::char_type t_doc_delim = 1
>
class doc_list_index_sada
{
public:
typedef t_csa_full csa_full_type;
typedef t_range_min range_min_type;
typedef t_range_max range_max_type;
typedef t_doc_border doc_border_type;
typedef t_doc_border_rank doc_border_rank_type;
typedef t_doc_border_select doc_border_select_type;
typedef int_vector<>::size_type size_type;
typedef std::vector> list_type;
typedef doc_list_tag index_category;
enum { WIDTH = t_csa_full::alphabet_category::WIDTH };
typedef sa_trait sa_tt;
class result : public list_type
{
private:
size_type m_sp, m_ep;
public:
// Number of occurrences
size_type count() {
return m_ep-m_sp+1;
}
// Constructors for an empty result and for a result in the interval [sp, ep]:
result() : m_sp(1), m_ep(0) {}
result(size_type sp, size_type ep) : m_sp(sp), m_ep(ep) {}
result& operator=(const result& res) {
if (this != &res) {
list_type::operator=(res);
m_sp = res.m_sp;
m_ep = res.m_ep;
}
return *this;
}
};
private:
size_type m_doc_cnt; // number of documents in the collection
csa_full_type m_csa_full; // CSA build from the collection text
vector> m_doc_isa; // array of inverse SAs. m_doc_isa[i] contains the ISA of document i
range_min_type m_rminq; // range minimum data structure build over an array Cprev
range_max_type m_rmaxq; // range maximum data structure build over an array Cnext
doc_border_type m_doc_border; // bitvector indicating the positions of the separators in the collection text
doc_border_rank_type m_doc_border_rank; // rank data structure on m_doc_border
doc_border_select_type m_doc_border_select; // select data structure on m_doc_border
size_type m_doc_max_len; // maximal length of a document in the collection
mutable bit_vector m_doc_rmin_marked; // helper bitvector for search process
mutable bit_vector m_doc_rmax_marked; // helper bitvector for search process
public:
//! Default constructor
doc_list_index_sada() { }
doc_list_index_sada(std::string file_name, sdsl::cache_config& cconfig, uint8_t num_bytes) {
construct(m_csa_full, file_name, cconfig, num_bytes);
const char* KEY_TEXT = key_text_trait::KEY_TEXT;
std::string text_file = cache_file_name(KEY_TEXT, cconfig);
construct_doc_border(text_file, m_doc_border, m_doc_max_len);
m_doc_border_rank = doc_border_rank_type(&m_doc_border);
m_doc_border_select = doc_border_select_type(&m_doc_border);
m_doc_cnt = m_doc_border_rank(m_doc_border.size());
construct_doc_isa(text_file, m_doc_cnt, m_doc_max_len, m_doc_isa);
int_vector_buffer<0> sa_buf(cache_file_name(conf::KEY_SA, cconfig));
{
int_vector<> D;
construct_D_array(sa_buf, m_doc_border_rank, m_doc_cnt, D);
{
int_vector<> Cprev;
construct_Cprev_array(D, m_doc_cnt, Cprev);
range_min_type rminq(&Cprev);
m_rminq = rminq;
}
{
int_vector<> Cnext;
construct_Cnext_array(D, m_doc_cnt, Cnext);
range_max_type rmaxq(&Cnext);
m_rmaxq = rmaxq;
}
}
m_doc_rmin_marked = bit_vector(m_doc_cnt, 0);
m_doc_rmax_marked = bit_vector(m_doc_cnt, 0);
}
size_type doc_cnt()const {
return m_doc_cnt;
}
size_type word_cnt()const {
return m_csa_full.size()-doc_cnt();
}
size_type serialize(std::ostream& out, structure_tree_node* v=NULL, std::string name="")const {
structure_tree_node* child = structure_tree::add_child(v, name, util::class_name(*this));
size_type written_bytes = 0;
written_bytes += write_member(m_doc_cnt, out, child, "doc_cnt");
written_bytes += m_csa_full.serialize(out, child, "csa_full");
written_bytes += serialize_vector(m_doc_isa, out, child, "doc_isa");
written_bytes += m_rminq.serialize(out, child, "rminq");
written_bytes += m_rmaxq.serialize(out, child, "rmaxq");
written_bytes += m_doc_border.serialize(out, child, "doc_border");
written_bytes += m_doc_border_rank.serialize(out, child, "doc_border_rank");
written_bytes += m_doc_border_select.serialize(out, child, "doc_border_select");
written_bytes += write_member(m_doc_max_len, out, child, "doc_max_len");
// helper bitvector m_doc_rmin_marked and m_doc_rmax_marked are not serialize
structure_tree::add_size(child, written_bytes);
return written_bytes;
}
void load(std::istream& in) {
read_member(m_doc_cnt, in);
m_csa_full.load(in);
m_doc_isa.resize(m_doc_cnt);
load_vector(m_doc_isa, in);
m_rminq.load(in);
m_rmaxq.load(in);
m_doc_border.load(in);
m_doc_border_rank.load(in);
m_doc_border_rank.set_vector(&m_doc_border);
m_doc_border_select.load(in);
m_doc_border_select.set_vector(&m_doc_border);
read_member(m_doc_max_len, in);
// also initialize the helper bitvectors
m_doc_rmin_marked = bit_vector(m_doc_cnt);
m_doc_rmax_marked = bit_vector(m_doc_cnt);
}
void swap(doc_list_index_sada& dr) {
if (this != &dr) {
std::swap(m_doc_cnt, dr.m_doc_cnt);
m_csa_full.swap(dr.m_csa_full);
m_doc_isa.swap(dr.m_doc_isa);
m_rminq.swap(dr.m_rminq);
m_rmaxq.swap(dr.m_rmaxq);
m_doc_border.swap(dr.m_doc_border);
util::swap_support(m_doc_border_rank, dr.m_doc_border_rank,
&m_doc_border, &(dr.m_doc_border));
util::swap_support(m_doc_border_select, dr.m_doc_border_select,
&m_doc_border, &(dr.m_doc_border));
std::swap(m_doc_max_len, dr.m_doc_max_len);
m_doc_rmin_marked.swap(dr.m_doc_rmin_marked);
m_doc_rmax_marked.swap(dr.m_doc_rmax_marked);
}
}
//! Search for the k documents which contains the search term most frequent
template
size_t
search(t_pat_iter begin,
t_pat_iter end,
result& res,
size_t k) const {
size_type sp=1, ep=0;
if (0 == backward_search(m_csa_full, 0, m_csa_full.size()-1, begin, end, sp, ep)) {
res = result();
return 0;
} else {
res = result(sp, ep);
compute_tf_idf(sp, ep, res);
size_t kprime = std::min(res.size(), k);
auto comp = [](std::pair& a,std::pair& b) {
return (a.second != b.second) ? a.second > b.second : a.first < b.first;
};
partial_sort(res.begin(),res.begin()+kprime, res.end(), comp);
res.resize(kprime);
return ep-sp+1;
}
}
private:
void compute_tf_idf(const size_type& sp, const size_type& ep, result& res)const {
vector suffixes;
get_lex_smallest_suffixes(sp, ep, suffixes);
get_lex_largest_suffixes(sp, ep, suffixes);
sort(suffixes.begin(), suffixes.end());
for (size_type i=0; i < suffixes.size(); i+=2) {
size_type suffix_1 = suffixes[i];
size_type suffix_2 = suffixes[i+1];
size_type doc = m_doc_border_rank(suffix_1+1);
m_doc_rmin_marked[doc] = 0; // reset marking, which was set in get_lex_smallest_suffixes
m_doc_rmax_marked[doc] = 0; // get_lex_largest_suffixes
if (suffix_1 == suffix_2) { // if pattern occurs exactly once
res.push_back( {doc,1}); // add the #occurrence
} else {
size_type doc_begin = doc ? m_doc_border_select(doc) + 1 : 0;
size_type doc_sp = m_doc_isa[doc][ suffix_1 - doc_begin ];
size_type doc_ep = m_doc_isa[doc][ suffix_2 - doc_begin ];
if (doc_sp > doc_ep) {
std::swap(doc_sp, doc_ep);
}
res.push_back( {doc, doc_ep - doc_sp + 1});
}
}
}
void get_lex_smallest_suffixes(size_type sp, size_type ep, vector& suffixes) const {
using lex_range_t = std::pair;
std::stack stack;
stack.emplace(sp,ep);
while (!stack.empty()) {
auto range = stack.top();
stack.pop();
size_type rsp = std::get<0>(range);
size_type rep = std::get<1>(range);
if (rsp <= rep) {
size_type min_idx = m_rminq(rsp,rep);
size_type suffix = m_csa_full[min_idx];
size_type doc = m_doc_border_rank(suffix+1);
if (!m_doc_rmin_marked[doc]) {
suffixes.push_back(suffix);
m_doc_rmin_marked[doc] = 1;
stack.emplace(min_idx+1,rep);
stack.emplace(rsp,min_idx-1); // min_idx != 0, since `\0` is appended to string
}
}
}
}
void get_lex_largest_suffixes(size_type sp, size_type ep, vector& suffixes) const {
using lex_range_t = std::pair;
std::stack stack;
stack.emplace(sp,ep);
while (!stack.empty()) {
auto range = stack.top();
stack.pop();
size_type rsp = std::get<0>(range);
size_type rep = std::get<1>(range);
if (rsp <= rep) {
size_type max_idx = m_rmaxq(rsp,rep);
size_type suffix = m_csa_full[max_idx];
size_type doc = m_doc_border_rank(suffix+1);
if (!m_doc_rmax_marked[doc]) {
suffixes.push_back(suffix);
m_doc_rmax_marked[doc] = 1;
stack.emplace(rsp,max_idx - 1); // max_idx != 0, since `\0` is appended to string
stack.emplace(max_idx+1,rep);
}
}
}
}
//! Construct the doc_border bitvector by streaming the text file
void
construct_doc_border(const std::string& text_file,
doc_border_type& doc_border,
size_type& doc_max_len) {
int_vector_buffer text_buf(text_file);
bit_vector tmp_doc_border(text_buf.size(), 0); // create temporary uncompressed vector
doc_max_len = 0;
size_type len = 0;
for (size_type i = 0; i < text_buf.size(); ++i) {
if (t_doc_delim == text_buf[i]) {
tmp_doc_border[i] = 1;
doc_max_len = std::max(doc_max_len, len);
len = 0;
} else {
++len;
}
}
doc_border = doc_border_type(tmp_doc_border);
}
void
construct_doc_isa(const std::string& text_file,
const size_type doc_cnt,
SDSL_UNUSED const size_type doc_max_len,
vector >& doc_isa) {
doc_isa.resize(doc_cnt);
typename sa_tt::vec_type doc_buffer;
int_vector_buffer text_buf(text_file);
size_type doc_id = 0;
for (size_type i = 0; i < text_buf.size(); ++i) {
if (t_doc_delim == text_buf[i]) {
if (doc_buffer.size() > 0) {
doc_buffer.push_back(0);
construct_doc_isa(doc_buffer, doc_isa[doc_id]);
++doc_id;
}
doc_buffer.clear();
} else {
doc_buffer.push_back(text_buf[i]);
}
}
}
void
construct_doc_isa(typename sa_tt::vec_type& doc_buffer,
int_vector<>& doc_isa) {
int_vector<> sa(doc_buffer.size(), 0, bits::hi(doc_buffer.size())+1);
sa_tt::calc_sa(sa, doc_buffer);
util::bit_compress(sa);
doc_isa = sa;
for (size_type i = 0; i < doc_buffer.size(); ++i) {
doc_isa[sa[i]] = i;
}
}
void
construct_D_array(int_vector_buffer<0>& sa_buf,
const doc_border_rank_type& doc_border_rank,
const size_type doc_cnt,
int_vector<>& D) {
D = int_vector<>(sa_buf.size(), 0, bits::hi(doc_cnt+1)+1);
for (size_type i = 0; i < sa_buf.size(); ++i) {
D[i] = doc_border_rank(sa_buf[i]+1);
}
}
void
construct_Cprev_array(const int_vector<>& D,
size_type doc_cnt,
int_vector<>& Cprev) {
Cprev = int_vector<>(D.size(), 0, bits::hi(D.size())+1);
int_vector<> last_occ(doc_cnt+1, 0, bits::hi(D.size())+1);
for (size_type i = 0; i < D.size(); ++i) {
size_type doc = D[i];
Cprev[i] = last_occ[doc];
last_occ[doc] = i;
}
}
void
construct_Cnext_array(const int_vector<>& D,
size_type doc_cnt,
int_vector<>& Cnext) {
Cnext = int_vector<>(D.size(), 0, bits::hi(D.size())+1);
int_vector<> last_occ(doc_cnt+1, D.size(), bits::hi(D.size())+1);
for (size_type i = 0, j = D.size()-1; i < D.size(); ++i, --j) {
size_type doc = D[j];
Cnext[j] = last_occ[doc];
last_occ[doc] = j;
}
}
};
} // end namespace
#endif
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/doc_list_index_sort.hpp����������������������������0000664�0000000�0000000�00000014520�12412610011�0026565�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*!
* this file contains a simple SORT baseline
*/
#ifndef DOCUMENT_LISING_SORT
#define DOCUMENT_LISING_SORT
#include
#include
#include
#include
#include
#include
#include
#include "doc_list_index.hpp"
using std::vector;
namespace sdsl
{
template<
class t_csa = csa_wt>, 1000000, 1000000>,
typename t_csa::char_type t_doc_delim = 1
>
class doc_list_index_sort
{
public:
typedef t_csa csa_type;
typedef int_vector<> d_type;
typedef int_vector<>::size_type size_type;
typedef std::vector> list_type;
typedef doc_list_tag index_category;
enum { WIDTH = t_csa::alphabet_category::WIDTH };
class result : public list_type
{
private:
size_type m_sp, m_ep;
public:
// Number of occurrences
size_type count() {
return m_ep-m_sp+1;
}
result(size_type sp, size_type ep,list_type&& l) : list_type(l), m_sp(1), m_ep(0) {}
result() : m_sp(1), m_ep(0) {}
result(size_type sp, size_type ep) : m_sp(sp), m_ep(ep) {}
result& operator=(const result& res) {
if (this != &res) {
list_type::operator=(res);
m_sp = res.m_sp;
m_ep = res.m_ep;
}
return *this;
}
};
protected:
size_type m_doc_cnt; // number of documents in the collection
csa_type m_csa_full; // CSA built from the collection text
d_type m_d; // wtd build from the collection text
public:
//! Default constructor
doc_list_index_sort() { }
doc_list_index_sort(std::string file_name, sdsl::cache_config& cconfig, uint8_t num_bytes) {
construct(m_csa_full, file_name, cconfig, num_bytes);
const char* KEY_TEXT = key_text_trait::KEY_TEXT;
std::string text_file = cache_file_name(KEY_TEXT, cconfig);
bit_vector doc_border;
construct_doc_border(text_file,doc_border);
bit_vector::rank_1_type doc_border_rank(&doc_border);
m_doc_cnt = doc_border_rank(doc_border.size());
int_vector_buffer<0> sa_buf(cache_file_name(conf::KEY_SA, cconfig));
construct_D_array(sa_buf, doc_border_rank, m_doc_cnt, m_d);
}
size_type doc_cnt()const {
return m_doc_cnt; // subtract one, since zero does not count
}
size_type word_cnt()const {
return m_d.size()-doc_cnt();
}
size_type sigma()const {
return m_csa_full.sigma;
}
size_type serialize(std::ostream& out, structure_tree_node* v=NULL, std::string name="")const {
structure_tree_node* child = structure_tree::add_child(v, name, util::class_name(*this));
size_type written_bytes = 0;
written_bytes += write_member(m_doc_cnt, out, child, "doc_cnt");
written_bytes += m_csa_full.serialize(out, child, "csa_full");
written_bytes += m_d.serialize(out, child, "D");
structure_tree::add_size(child, written_bytes);
return written_bytes;
}
void load(std::istream& in) {
read_member(m_doc_cnt, in);
m_csa_full.load(in);
m_d.load(in);
}
void swap(doc_list_index_sort& dr) {
if (this != &dr) {
std::swap(m_doc_cnt, dr.m_doc_cnt);
m_csa_full.swap(dr.m_csa_full);
m_d.swap(dr.m_d);
}
}
//! Search for the k documents which contain the search term most frequent
template
size_type search(t_pat_iter begin, t_pat_iter end, result& res, size_t k) const {
size_type sp=1, ep=0;
if (0 == backward_search(m_csa_full, 0, m_csa_full.size()-1, begin, end, sp, ep)) {
res = result();
return 0;
} else {
res = result(sp, ep);
size_t n = ep-sp+1;
std::vector tmp(n);
std::copy(m_d.begin()+sp,m_d.begin()+ep+1,tmp.begin());
std::sort(tmp.begin(),tmp.end());
size_t last = tmp[0];
size_t f_dt = 1;
for (size_t i=1; i& a,
const std::pair& b) {
return a.second > b.second;
};
std::partial_sort(res.begin(),res.begin()+k,res.end(),freq_cmp);
res.resize(k);
return ep-sp+1;
}
}
private:
//! Construct the doc_border bitvector by streaming the text file
void
construct_doc_border(const std::string& text_file, bit_vector& doc_border) {
int_vector_buffer text_buf(text_file);
doc_border = bit_vector(text_buf.size(), 0);
for (size_type i = 0; i < text_buf.size(); ++i) {
if (t_doc_delim == text_buf[i]) {
doc_border[i] = 1;
}
}
}
void
construct_D_array(int_vector_buffer<0>& sa_buf,
bit_vector::rank_1_type& doc_border_rank,
const size_type doc_cnt,
int_vector<>& D) {
D = int_vector<>(sa_buf.size(), 0, bits::hi(doc_cnt+1)+1);
for (size_type i = 0; i < sa_buf.size(); ++i) {
uint64_t d = doc_border_rank(sa_buf[i]+1);
D[i] = d;
}
}
};
} // end namespace
#endif
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/gen_pattern.cpp������������������������������������0000664�0000000�0000000�00000005116�12412610011�0025031�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include
#include
#include
#include
using namespace std;
using namespace sdsl;
#ifndef INT_ALPHABET
using csa_t = csa_wt>>;
uint8_t num_bytes = 1;
#else
using csa_t = csa_wt>>;
uint8_t num_bytes = 0;
#endif
int main(int argc, char* argv[])
{
if (argc < 7) {
cout << "Usage: " << argv[0] << " collection_file collection_csa tmp_dir pattern_length pattern_number pattern_file" << endl;
cout << " Generates an index and stores result in index_file" << endl;
cout << " Temporary files are stored in tmp_dir." << endl;
return 1;
}
string collection_file = argv[1];
string id = util::basename(collection_file);
string collection_csa = argv[2];
string tmp_dir = argv[3];
uint64_t pat_len = stoull(argv[4]);
uint64_t pat_num = stoull(argv[5]);
string pattern_file = argv[6];
csa_t csa;
cache_config cconfig(false, tmp_dir, id);
if (!load_from_file(csa, collection_csa)) {
if (num_bytes == 0) {
int_vector<> v;
load_from_file(v, collection_file);
std::cout<<"v.size()="< csa.size() - csa.bwt.rank(csa.size(), 1)) {
std::cerr<<"pat_len > " << " length of the documents" << std::endl;
return 1;
}
std::mt19937_64 rng;
std::uniform_int_distribution distribution(0, csa.size()-pat_len);
auto dice = bind(distribution, rng);
ofstream out(pattern_file);
if (!out) {
std::cerr<<"Could not open file "<= 5) {
out << pat << "\n";
++pat_cnt;
}
}
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/src/query_idx.cpp��������������������������������������0000664�0000000�0000000�00000005251�12412610011�0024534�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include "doc_list_index.hpp"
#include
#include
#include
#include
using namespace std;
using namespace sdsl;
using idx_type = IDX_TYPE;
const size_t buf_size=1024*128;
char buffer[buf_size];
template
struct myline {
static string parse(char* str) {
return string(str);
}
};
template<>
struct myline<0> {
static vector parse(char* str) {
vector res;
stringstream ss(str);
uint64_t x;
while (ss >> x) {
res.push_back(x);
}
return res;
}
};
int main(int argc, char* argv[])
{
if (argc < 3) {
cout << "Usage: " << argv[0] << " index_file pattern_file" << endl;
cout << " Process all queries with the index." << endl;
return 1;
}
string index_file = string(argv[1]);
string pattern_file = string(argv[2]);
idx_type idx;
using timer = std::chrono::high_resolution_clock;
std::cout<<"# index_file = "<::parse(buffer);
q_len += query.size();
++q_cnt;
size_t x = idx.search(query.begin(), query.end(), res, 10);
sum += x;
for (auto& r : res) {
sum_fdt += r.second;
}
auto q_time = timer::now()-q_start;
// single query should not take more then 5 seconds
if (std::chrono::duration_cast(q_time).count() > 5) {
tle = true;
}
}
auto stop = timer::now();
auto elapsed = stop-start;
std::cout<<"# TLE = " << tle << endl;
std::cout<<"# query_len = "<
#include
using namespace std;
using namespace sdsl;
using idx_type = IDX_TYPE;
int main(int argc, char* argv[])
{
if (argc < 2) {
cout << "Usage: " << argv[0] << " index_file [html_file]" << endl;
return 1;
}
string index_file = string(argv[1]);
idx_type idx;
if (!load_from_file(idx, index_file)) {
std::cerr << "Could not load index file" << std::endl;
return 1;
}
if (argc > 2) {
ofstream out(argv[2]);
write_structure(idx, out);
} else {
cout<<"# index_file = "< i2w;
string word;
while (dic_in >> word) {
uint64_t nr, occ;
dic_in >> nr >> occ;
i2w[nr] = word;
}
while (pat_in.getline(buffer, buf_size)) {
stringstream ss;
ss << string(buffer);
uint64_t w;
while (ss >> w) {
cout << i2w[w] << " ";
}
cout << "\n";
}
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/test_case.config���������������������������������������0000664�0000000�0000000�00000000666�12412610011�0024376�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration for test files
# (1) Identifier for test file
# (2) Path to the test file
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENWIKISML;../data/enwiki-20130805-pages-articles1.txt;enwiki-sml;http://people.eng.unimelb.edu.au/sgog/data/enwiki-20130805-pages-articles1.txt.gz
PROTEINS;../data/proteins.txt;proteins;http://people.eng.unimelb.edu.au/sgog/data/proteins.txt.gz
#WSJ;../data/wsj.char.100MB;WSJ
��������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/test_case_int.config�����������������������������������0000664�0000000�0000000�00000000515�12412610011�0025241�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration for integer test files
# (1) Identifier for test file
# (2) Path to the test file
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENWIKISMLINT;../data/enwiki-20130805-pages-articles1.int.sdsl;enwiki-sml-int;http://people.eng.unimelb.edu.au/sgog/data/enwiki-20130805-pages-articles1.int.sdsl.gz
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/���������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0023240�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/.gitignore�����������������������������������0000664�0000000�0000000�00000000250�12412610011�0025225�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������doc_re_time.aux
doc_re_time.log
doc_re_time.pdf
fig-runtime.tex
fig-runtime_int.tex
tbl-indexes.tex
tbl-indexes_int.tex
tbl-sizes_int.tex
tbl-sizes.tex
LaTeX.log
R.log
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/Makefile�������������������������������������0000664�0000000�0000000�00000002410�12412610011�0024675�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../../Make.helper
CONFIG_FILES=../index.config ../test_case.config ../pattern_length.config \
../index_int.config ../test_case_int.config ../pattern_length_int.config
all: doc_re_time.pdf
doc_re_time.pdf: doc_re_time.tex \
fig-runtime.tex fig-runtime_int.tex \
tbl-sizes.tex tbl-sizes_int.tex \
tbl-indexes.tex tbl-indexes_int.tex \
tbl-collections.tex tbl-collections_int.tex
@echo "Use pdflatex to generate doc_re_time.pdf"
@pdflatex doc_re_time.tex >> LaTeX.log 2>&1
#tbl-locate.tex fig-locate.tex: ../../basic_functions.R locate.R $(CONFIG_FILES) ../results/all.txt
# @echo "Use R to generate tbl-locate.tex and fig-locate.tex"
fig-runtime.tex fig-runtime_int.tex tbl-indexes.tex tbl-indexes_int.tex tbl-sizes.tex tbl-sizes_int.tex tbl-collections.tex tbl-collections_int.tex: ../../basic_functions.R runtime.R \
$(CONFIG_FILES) ../results/all.txt \
../info/sizes.txt ../info/sizes_int.txt
@R --vanilla < runtime.R > R.log 2>&1
clean:
rm -f doc_re_time.pdf doc_re_time.aux \
fig-runtime.tex tbl-indexes.tex \
fig-runtime_int.tex tbl-indexes_int.tex \
tbl-sizes.tex tbl-sizes_int.tex \
tbl-collections.tex tbl-collections_int.tex \
doc_re_time.log R.log LaTeX.log
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/doc_re_time.tex������������������������������0000664�0000000�0000000�00000002524�12412610011�0026236�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������\documentclass[9pt,a4paper]{scrartcl}
\usepackage{array}
\usepackage{booktabs}
\usepackage{ragged2e}
\usepackage{tikz}
\begin{document}
\pagestyle{empty}
\begin{table}
\centering
\input{tbl-collections.tex}
\caption{Statistics of the character based collections.}
\end{table}
\begin{figure}
\input{fig-runtime.tex}
\caption{Average query time to find the top-$10$ documents (frequency measure)
for different pattern length using character based indexes. For each query length, $200$ pattern were
queried.}
\end{figure}
\begin{table}
\centering
\input{tbl-indexes.tex}
\caption{Class definition of character indexes used in the experiment.}
\end{table}
\begin{table}
\centering
\input{tbl-sizes.tex}
\caption{Size of character indexes.}
\end{table}
\begin{table}
\centering
\input{tbl-collections_int.tex}
\caption{Statistics of the word based collections.}
\end{table}
\begin{figure}
\input{fig-runtime_int.tex}
\caption{Average query time to find the top-$10$ documents (frequency measure)
for different pattern length using word bases indexes. For each query length, $200$ pattern were
queried.}
\end{figure}
\begin{table}
\centering
\input{tbl-indexes_int.tex}
\caption{Class definition of word indexes used in the experiment.}
\end{table}
\begin{table}
\centering
\input{tbl-sizes_int.tex}
\caption{Size of word indexes.}
\end{table}
\end{document}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/index-filter.config��������������������������0000664�0000000�0000000�00000000723�12412610011�0027023�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Use this file to specify which indexes are listed in the report doc_re_time.pdf
# and how they look like in the report.
#
# List all the index ids which should be included in the report. Note that
# the listed index ids must also be present in the file `../index.config`.
# Eeach INDEX_ID should be listed on a separate line followed by the style:
# [pch];[lty];[col] (point type, line type, and color).
GREEDY;1;solid;black
QPROBING; 2;solid;blue
SADA;3;solid;red
���������������������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/index-filter_int.config����������������������0000664�0000000�0000000�00000000740�12412610011�0027674�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Use this file to specify which indexes are listed in the report doc_re_time.pdf
# and how they look like in the report.
#
# List all the index ids which should be included in the report. Note that
# the listed index ids must also be present in the file `../index_int.config`.
# Eeach INDEX_ID should be listed on a separate line followed by the style:
# [pch];[lty];[col] (point type, line type, and color).
GREEDYINT;1;solid;black
QPROBINGINT; 2;solid;blue
SADAINT;3;solid;red
��������������������������������sdsl-lite-2.0.3/benchmark/document_retrieval/visualize/runtime.R������������������������������������0000664�0000000�0000000�00000012555�12412610011�0025056�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������require(tikzDevice)
source("../../basic_functions.R")
mypaste <- function(...){
paste(...,sep="")
}
my_format2 <- function(...){
format(..., nsmall=2,digits=2, big.mark=",")
}
process_data <- function(suf){
# Files
f_idxfilterconfig = mypaste("index-filter",suf,".config")
f_idxconfig = mypaste("../index",suf,".config")
f_tcconfig = mypaste("../test_case",suf,".config")
f_results = mypaste("../results/all",suf,".txt")
f_sizes = mypaste("../info/sizes",suf,".txt")
f_fig_runtime = mypaste("fig-runtime",suf,".tex")
f_tbl_indexes = mypaste("tbl-indexes",suf,".tex")
f_tbl_sizes = mypaste("tbl-sizes",suf,".tex")
f_tbl_collections = mypaste("tbl-collections",suf,".tex")
# Load filter information
config <- readConfig(f_idxfilterconfig,c("IDX_ID","PCH","LTY","COL"))
# Load index and test case data
idx_config <- readConfig(f_idxconfig,c("IDX_ID","SDSL_TYPE","LATEX-NAME"))
tc_config <- readConfig(f_tcconfig,c("TC_ID","PATH","LATEX-NAME","URL"))
# Load data
raw <- data_frame_from_key_value_pairs(f_results)
raw <- raw[c("TC_ID","IDX_ID","time_per_query","query_len","TLE","doc_cnt","word_cnt")]
raw["time_per_query"] <- raw["time_per_query"]/1000.0
# Filter indexes
raw <- raw[raw[["IDX_ID"]]%in%config[["IDX_ID"]],]
raw[["IDX_ID"]] <- factor(raw[["IDX_ID"]])
# Split by TC_ID
d <- split(raw,raw["TC_ID"])
tikz(f_fig_runtime, width = 5.5, height = 6, standAlone = F)
multi_figure_style( length(d)/2+1, 2 )
count <- 0
nr <- 0
xlabnr <- (2*(length(d)/2)-1)
for( tc_id in names(d) ){
plot( c(1e-9), c(1e-9), xlim=c(min(raw["query_len"]),max(raw["query_len"])),
ylim=c(0.01,1000),
ylab="", xlab="", xaxt="n", log="y" )
box(col="gray")
abline(h=c(seq(1,10)*0.1,seq(2,10)*1,seq(2,10)*10, seq(2,10)*100), col="lightgray")
grid(lty="solid")
if ( nr %% 2 == 0 ){
ylable <- "Time per query (milliseconds)"
axis( 2, at = axTicks(2) )
mtext(ylable, side=2, line=2, las=0)
}
axis( 1, at = axTicks(1), labels=(nr>=xlabnr) )
if ( nr >= xlabnr ){
xlable <- "Pattern length"
mtext(xlable, side=1, line=2, las=0)
}
# Split by IDX_ID
dd <- split(d[[tc_id]],d[[tc_id]]["IDX_ID"])
for( idx_id in names(dd) ){
ddd <- dd[[idx_id]]
ddd <- subset(ddd, ddd[["TLE"]]==0)
lines(ddd[["query_len"]], ddd[["time_per_query"]],
lwd=1, type="b", pch=config[idx_id, "PCH"],
lty=config[idx_id, "LTY"],
col=config[idx_id, "COL"])
}
draw_figure_heading( sprintf("instance = \\textsc{%s}",tc_config[tc_id,"LATEX-NAME"]) )
nr <- nr+1
if ( nr == 1 ){ # plot legend
plot(NA, NA, xlim=c(0,1),ylim=c(0,1),ylab="", xlab="", bty="n", type="n", yaxt="n", xaxt="n")
idx_ids <- as.character(unique(raw[["IDX_ID"]]))
legend( "top", legend=idx_config[idx_ids,"LATEX-NAME"], pch=config[idx_ids,"PCH"], col=config[idx_ids,"COL"],
lty=config[idx_ids,"LTY"], bty="n", y.intersp=1.5, ncol=2, title="Index", cex=1.2)
nr <- nr+1
}
}
dev.off()
sink(f_tbl_indexes)
cat(typeInfoTable(f_idxconfig, config[["IDX_ID"]], 1, 3, 2))
sink(NULL)
sink(f_tbl_sizes)
raw <- data_frame_from_key_value_pairs(f_sizes)
# Filter indexes
raw <- raw[raw[["IDX_ID"]]%in%config[["IDX_ID"]],]
raw[["IDX_ID"]] <- factor(raw[["IDX_ID"]])
d <- split(raw,raw[["IDX_ID"]])
cat(paste("\\begin{tabular}{@{}l*{",length(names(d)) ,"}{rr@{\ }l}@{}}",sep=""))
cat("\\toprule\n")
cat(paste("Collection& & \\multicolumn{",length(names(d))*3-1,"}{c}{Index size in MiB (fraction of original collection)}\\\\\n",sep=""))
cat(paste("\\cmidrule{1-1}\\cmidrule{3-",length(names(d))*3+1,"}\n",sep=""))
for( idx_id in names(d) ){
cat(paste("&\\ &\\multicolumn{2}{c}{",idx_config[idx_id,"LATEX-NAME"],"}",sep=""))
}
cat("\\\\[2ex]\n")
dd <- split(raw,raw[["TC_ID"]])
for ( tc_id in names(dd) ){
cat("{\\sc ",tc_config[tc_id,"LATEX-NAME"],"}")
ddd <- split(dd[[tc_id]],dd[[tc_id]][["IDX_ID"]])
for ( idx_id in names(d) ){
row <- ddd[[idx_id]]
cat(paste("&&",my_format2(row["size"]/1024**2),"&",sprintf("(%.2f)",row["size"]/row["text_size"])))
}
cat("\\\\\n")
}
cat("\\bottomrule\n")
cat("\\end{tabular}")
sink(NULL)
sink(f_tbl_collections)
raw <- data_frame_from_key_value_pairs(f_results)
cat(paste("\\begin{tabular}{@{}l*{5}{r}@{}}\n",sep=""))
cat("\\toprule\n")
elem = "Characters"
if ( suf=="_int" ) {
elem = "Words"
}
cat(paste("Collection & ",elem," & Documents & ","Avg. doc. len.& gzip-compr.& xz-compr.\\\\[1ex]\n",sep=""))
d <- split(raw,raw["TC_ID"])
for ( tc_id in names(d) ){
zfile = paste("../",tc_config[tc_id,"PATH"],".z.info",sep="")
gzipcomp = NA
xzcomp = NA
if ( file.exists(zfile) ){
comp_info <- readConfig(zfile,c("NAME","RATIO","COMMAND"))
gzipcomp = my_format2(comp_info["gzip","RATIO"])
xzcomp = my_format2(comp_info["xz","RATIO"])
}
doc_cnt_i <- unique(d[[tc_id]][["doc_cnt"]])
word_cnt_i <- unique(d[[tc_id]][["word_cnt"]])
doc_cnt <- format(doc_cnt_i, big.mark=",")
word_cnt <- format(word_cnt_i, big.mark=",")
avg_doc_len <- my_format2(word_cnt_i/doc_cnt_i)
cat("{\\sc ",tc_config[tc_id,"LATEX-NAME"],"}")
cat("&",word_cnt,"&",doc_cnt,"&",avg_doc_len,"&",
gzipcomp, "&", xzcomp,"\\\\\n")
}
cat("\\bottomrule\n")
cat("\\end{tabular}")
sink(NULL)
}
process_data("")
process_data("_int")
���������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/�����������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0020347�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/Makefile���������������������������������������������������0000664�0000000�0000000�00000011172�12412610011�0022011�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../Make.helper
CFLAGS = $(MY_CXX_FLAGS) # in compile_options.config
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
SRC_DIR = src
TMP_DIR = ../tmp
PAT_DIR = pattern
BIN_DIR = bin
TC_PATHS:=$(call config_column,test_case.config,2)
TC_IDS:=$(call config_ids,test_case.config)
IDX_IDS:=$(call config_ids,index.config)
COMPILE_IDS:=$(call config_ids,compile_options.config)
RESULT_FILE=results/all.txt
QUERY_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach COMPILE_ID,$(COMPILE_IDS),$(BIN_DIR)/query_idx_$(IDX_ID).$(COMPILE_ID)))
BUILD_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/build_idx_$(IDX_ID))
INFO_EXECS = $(foreach IDX_ID,$(IDX_IDS),$(BIN_DIR)/info_$(IDX_ID))
PATTERNS = $(foreach TC_ID,$(TC_IDS),$(PAT_DIR)/$(TC_ID).pattern)
INDEXES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),indexes/$(TC_ID).$(IDX_ID)))
INFO_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),info/$(TC_ID).$(IDX_ID).html))
TIME_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach COMPILE_ID,$(COMPILE_IDS),results/$(TC_ID).$(IDX_ID).$(COMPILE_ID))))
COMP_FILES = $(addsuffix .z.info,$(TC_PATHS))
all: $(BUILD_EXECS) $(QUERY_EXECS) $(INFO_EXECS)
info: $(INFO_EXECS) $(INFO_FILES)
indexes: $(INDEXES)
input: $(TC_PATHS)
pattern: input $(PATTERNS) $(BIN_DIR)/genpatterns
compression: input $(COMP_FILES)
timing: input $(INDEXES) pattern $(TIME_FILES) compression info
@cat $(TIME_FILES) > $(RESULT_FILE)
@cd visualize; make
# results/[TC_ID].[IDX_ID].[COMPILE_ID]
results/%: $(BUILD_EXECS) $(QUERY_EXECS) $(PATTERNS) $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval COMPILE_ID:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
@echo "# TC_ID = $(TC_ID)" >> $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# COMPILE_ID = $(COMPILE_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "Run timing for $(IDX_ID).$(COMPILE_ID) on $(TC_ID)"
$(BIN_DIR)/query_idx_$(IDX_ID).$(COMPILE_ID) \
indexes/$(TC_ID) C < $(PAT_DIR)/$(TC_ID).pattern 2>> $@
# indexes/[TC_ID].[IDX_ID]
indexes/%: $(BUILD_EXECS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
@echo "Building index $(IDX_ID) on $(TC)"
$(BIN_DIR)/build_idx_$(IDX_ID) $(TC) $(TMP_DIR) $@
# info/[TC_ID].[IDX_ID]
info/%.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
@echo "Generating info for $(IDX_ID) on $(TC_ID)"
@$(BIN_DIR)/info_$(IDX_ID) indexes/$(TC_ID).$(IDX_ID) > $@
$(PAT_DIR)/%.pattern: $(BIN_DIR)/genpatterns
@echo $*
$(eval TC:=$(call config_select,test_case.config,$*,2))
$(BIN_DIR)/genpatterns $(TC) 20 50000 $@
$(BIN_DIR)/genpatterns: $(SRC_DIR)/genpatterns.c
@echo "Build pattern generation program"
@$(MY_CC) -O3 -o $@ $(SRC_DIR)/genpatterns.c
# $(BIN_DIR)/build_idx_[IDX_ID]
$(BIN_DIR)/build_idx_%: $(SRC_DIR)/build_index_sdsl.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling build_idx_$*"
@$(MY_CXX) $(CFLAGS) -O3 -DNDEBUG \
-DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/build_index_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/count_queries_[IDX_ID].[COMPILE_ID]
$(BIN_DIR)/query_idx_%: $(SRC_DIR)/run_queries_sdsl.cpp index.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval COMPILE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval COMPILE_OPTIONS:=$(call config_select,compile_options.config,$(COMPILE_ID),2))
@echo "Compiling query_idx_$*"
@$(MY_CXX) $(CFLAGS) $(COMPILE_OPTIONS) \
-DSUF=\"$(IDX_ID)\" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/run_queries_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the executables which output the indexes structure.
$(BIN_DIR)/info_%: $(SRC_DIR)/info.cpp index.config
$(eval IDX_TYPE:=$(call config_select,index.config,$*,2))
@echo "Compiling info_$*"
@$(MY_CXX) $(CFLAGS) -O3 -DNDEBUG \
-DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/info.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
include ../Make.download
clean-build:
@echo "Remove executables"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS)
clean:
@echo "Remove executables and indexes"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS) \
$(INFO_FILES) $(INDEXES) $(BIN_DIR)/genpatterns
cleanresults:
@echo "Remove result files"
@rm -f $(TIME_FILES) $(RESULT_FILE) $(INFO_FILES)
@rm -f $(PATTERNS)
cleanall: clean cleanresults
@echo "Remove all generated files."
@rm -f $(TMP_DIR)/*
@rm -f $(PAT_DIR)/*
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/README.md��������������������������������������������������0000664�0000000�0000000�00000006356�12412610011�0021640�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking operation `count` on FM-indexes
## Methodology
Explored dimensions:
* text type
* instance size (just adjust the test_case.config file for this)
* compile options
* index implementations
Pattern selection:
We use the benchmark code including the random pattern selection
and test cases from the [Pizza&Chili][pz] website.
## Directory structure
* [bin](./bin): Contains the executables of the project.
* `build_idx_*` generates indexes
* `query_idx_*` executes the count experiments
* `info_*` outputs the space breakdown of an index.
* `genpattern` pattern generation from [Pizza&Chili][pz] website.
* [indexes](./indexes): Contains the generated indexes.
* [results](./visualize): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which generates
a report.
Files included in this archive from the Pizza&Chili website:
* [src/genpatterns.c](./src/genpatterns.c)
* [src/run_quries_sdsl.cpp](./src/run_quries_sdsl.cpp)
is a customized version of the Pizza&Chili file run_queries.c .
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with packages `xtable`,`plyr`. You can install the
package by calling `install.packages("xtable", "plyr")` in R.
- [pdflatex][LT] to generate the pdf reports.
* The construction of the 200MB indexes requires about 1GB
of RAM.
## Usage
* `make timing` compiles the programs, downloads test the
200MB [Pizza&Chili][pz] test cases, builds the indexes,
runs the performance tests, and generated a report located at
`visualize/count.pdf`. The raw numbers of the timings
can be found in `results/all.txt`.
Indexes and temporary files are stored in the
directory `indexes` and `tmp`. For the 5 x 200 MB of
[Pizza&Chili][pz] data the project will produce about
7.2 GB of additional data. On my machine (MacBookPro Retina
2.6GHz Intel Core i7, 16GB 1600 Mhz DDR3, SSD) the
benchmark, invoced by `make timing`, took about 11 minutes
(excluding the time to download the test instances).
Have a look at the [generated report][RES].
* All created indexes and test results can be deleted
by calling `make cleanall`.
## Customization of the benchmark
The project contains several configuration files:
* [index.config](./index.config): Specify data structures'
ID, sdsl-class, and LaTeX-name for the report.
* [test_case.config](./test_case.config): Specify test cases'
ID, path, LaTeX-name for the report, and download URL.
* [compile_options.config](./compile_options.config): Specify
compile options' ID and string.
Note that the benchmark will execute every combination of your choices.
Finally, the visualization can also be configured:
* [visualize/index-filter.config](./visualize/index-filter.config):
Specify which indexes should be listed in the report.
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/count.pdf "count.pdf"
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/bin/�������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021117�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/bin/.gitignore���������������������������������������������0000664�0000000�0000000�00000000040�12412610011�0023101�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/compile_options.config�������������������������������������0000664�0000000�0000000�00000001032�12412610011�0024735�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Compile configurations
# Column description (columns are separated by semicolon):
# (1) Identifier for compile configuration (consisting of letters)
# (2) Compile options
NOOPT;-std=c++11 -DPOPCOUNT_TL -O3 -g -funroll-loops -fomit-frame-pointer -ffast-math
NOSSE;-std=c++11 -O3 -g -funroll-loops -fomit-frame-pointer -ffast-math
SSE;-std=c++11 -msse4.2 -O3 -g -funroll-loops -fomit-frame-pointer -ffast-math
HP;-std=c++11 -DUSE_HP -msse4.2 -O3 -g -funroll-loops -fomit-frame-pointer -ffast-math
O1;-std=c++11 -O1
O0;-std=c++11 -O0
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/index.config�����������������������������������������������0000664�0000000�0000000�00000001643�12412610011�0022651�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specified sdsl index structures that are used in the benchmark.
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATEX_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in INDEX_ID.
# * SDSL_TYPE : Corresponding sdsl type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
FM_HUFF;csa_wt,select_support_scan<>,select_support_scan<0> >,1<<20,1<<20>;FM-HF-BV
FM_HUFF_RRR15;csa_wt >,1<<20,1<<20>;FM-HF-R$^{3}$-15
FM_HUFF_RRR63;csa_wt >,1<<20,1<<20>;FM-HF-R$^{3}$-63
#FM_HUFF_RRR127;csa_wt >,1<<20,1<<20>;FM-HF-R$^{3}$-127
#FM_HUFF_RRR255;csa_wt >,1<<20,1<<20>;FM-HF-R$^{3}$-255
#CSA_SADA;csa_sada,1<<20,1<<20>;CSA
FM_RLMN;csa_wt,1<<20,1<<20>;FM-RLMN
���������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/indexes/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022006�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/indexes/.gitignore�����������������������������������������0000664�0000000�0000000�00000000040�12412610011�0023770�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/info/������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021302�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/info/.gitignore��������������������������������������������0000664�0000000�0000000�00000000040�12412610011�0023264�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/pattern/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022024�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/pattern/.gitignore�����������������������������������������0000664�0000000�0000000�00000000040�12412610011�0024006�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/results/���������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022050�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/results/.gitignore�����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024035�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/�������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021136�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/build_index_sdsl.cpp�����������������������������������0000664�0000000�0000000�00000001131�12412610011�0025151�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include
#include
using namespace sdsl;
using namespace std;
int main(int argc, char** argv)
{
if (argc < 4) {
cout << "Usage ./" << argv[0] << " input_file tmp_dir output_file" << endl;
return 0;
}
CSA_TYPE csa;
if (argc < 3) {
construct(csa, argv[1], 1);
} else {
// config: do not delete files, tmp_dir=argv[2], id=basename(argv[1])
cache_config cconfig(false, argv[2], util::basename(argv[1]));
construct(csa, argv[1], cconfig, 1);
}
store_to_file(csa, argv[3]);
}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/genpatterns.c������������������������������������������0000664�0000000�0000000�00000014367�12412610011�0023647�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
// Extracts random patterns from a file
#include
#include
#include
#include
#include
#include
#include
static int Seed;
#define ACMa 16807
#define ACMm 2147483647
#define ACMq 127773
#define ACMr 2836
#define hi (Seed / ACMq)
#define lo (Seed % ACMq)
static int fst = 1;
/*
* returns a random integer in 0..top-1
*/
int
aleat(top)
{
long test;
struct timeval t;
if (fst) {
gettimeofday(&t, NULL);
Seed = t.tv_sec * t.tv_usec;
fst = 0;
}
{
Seed = ((test =
ACMa * lo - ACMr * hi) > 0) ? test : test + ACMm;
return ((double) Seed) * top / ACMm;
}
}
void parse_forbid(unsigned char* forbid, unsigned char** forbide)
{
int len, i, j;
len = strlen(forbid);
*forbide = (unsigned char*) malloc((len+1)*sizeof(unsigned char));
if (*forbide == NULL) {
fprintf(stderr, "Error: cannot allocate %i bytes\n", len+1);
fprintf(stderr, "errno = %i\n", errno);
exit(1);
}
for (i = 0, j = 0; i < len; i++) {
if (forbid[i] != '\\') {
if (forbid[i] != '\n')
(*forbide)[j++] = forbid[i];
} else {
i++;
if (i == len) {
forbid[i-1] = '\0';
(*forbide)[j] = '\0';
fprintf(stderr, "Not correct forbidden string: only one \\\n");
return;
}
switch (forbid[i]) {
case'n': (*forbide)[j++] = '\n'; break;
case'\\': (*forbide)[j++] = '\\'; break;
case'b': (*forbide)[j++] = '\b'; break;
case'e': (*forbide)[j++] = '\e'; break;
case'f': (*forbide)[j++] = '\f'; break;
case'r': (*forbide)[j++] = '\r'; break;
case't': (*forbide)[j++] = '\t'; break;
case'v': (*forbide)[j++] = '\v'; break;
case'a': (*forbide)[j++] = '\a'; break;
case'c':
if (i+3 >= len) {
forbid[i-1] = '\0';
(*forbide)[j] = '\0';
fprintf(stderr, "Not correct forbidden string: 3 digits after \\c\n");
return;
}
(*forbide)[j++] = (forbid[i+1]-48)*100 +
(forbid[i+2]-48)*10 + (forbid[i+3]-48);
i+=3;
break;
default:
fprintf(stdout, "Unknown escape sequence '\\%c'in forbidden string\n", forbid[i]);
break;
}
}
}
(*forbide)[j] = '\0';
}
main(int argc, char** argv)
{
int n, m, J, t;
struct stat sdata;
FILE* ifile, *ofile;
unsigned char* buff;
unsigned char* forbid, *forbide = NULL;
if (argc < 5) {
fprintf(stderr,
"Usage: genpatterns \n"
" randomly extracts substrings of length from ,\n"
" avoiding substrings containing characters in .\n"
" The output file, has a first line of the form:\n"
" # number= length= file= forbidden=\n"
" and then the patterns come successively without any separator.\n"
" uses \\n, \\t, etc. for nonprintable chracters or \\cC\n"
" where C is the ASCII code of the character written using 3 digits.\n\n");
exit(1);
}
if (stat(argv[1], &sdata) != 0) {
fprintf(stderr, "Error: cannot stat file %s\n", argv[1]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
n = sdata.st_size;
m = atoi(argv[2]);
if ((m <= 0) || (m > n)) {
fprintf(stderr,
"Error: length must be >= 1 and <= file length"
" (%i)\n", n);
exit(1);
}
J = atoi(argv[3]);
if (J < 1) {
fprintf(stderr, "Error: number of patterns must be >= 1\n");
exit(1);
}
if (argc > 5) {
forbid = argv[5];
parse_forbid(forbid, &forbide);
} else
forbid = NULL;
ifile = fopen(argv[1], "r");
if (ifile == NULL) {
fprintf(stderr, "Error: cannot open file %s for reading\n", argv[1]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
buff = (unsigned char*) malloc(n);
if (buff == NULL) {
fprintf(stderr, "Error: cannot allocate %i bytes\n", n);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
if (fread(buff, n, 1, ifile) != 1) {
fprintf(stderr, "Error: cannot read file %s\n", argv[1]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
fclose(ifile);
ofile = fopen(argv[4], "w");
if (ofile == NULL) {
fprintf(stderr, "Error: cannot open file %s for writing\n",
argv[4]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
if (fprintf(ofile, "# number=%i length=%i file=%s forbidden=%s\n",
J, m, argv[1],
forbid == NULL ? "" : (char*) forbid) <= 0) {
fprintf(stderr, "Error: cannot write file %s\n", argv[4]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
for (t = 0; t < J; t++) {
int j, l;
if (!forbide)
j = aleat(n - m + 1);
else {
do {
j = aleat(n - m + 1);
for (l = 0; l < m; l++)
if (strchr(forbide, buff[j + l]))
break;
} while (l < m);
}
for (l = 0; l < m; l++)
if (putc(buff[j + l], ofile) != buff[j + l]) {
fprintf(stderr,
"Error: cannot write file %s\n",
argv[4]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
}
if (fclose(ofile) != 0) {
fprintf(stderr, "Error: cannot write file %s\n", argv[4]);
fprintf(stderr, " errno = %i\n", errno);
exit(1);
}
fprintf(stderr, "File %s successfully generated\n", argv[4]);
free(forbide);
exit(0);
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/info.cpp�����������������������������������������������0000664�0000000�0000000�00000000635�12412610011�0022601�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* This program outputs the structure of an index.
*/
#include
#include
#include
using namespace sdsl;
using namespace std;
int main(int argc, char* argv[])
{
if (argc < 2) {
cout << "./" << argv[0] << " index_file " << endl;
return 1;
}
CSA_TYPE csa;
load_from_file(csa, argv[1]);
write_structure(csa, cout);
}
���������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/interface.h��������������������������������������������0000664�0000000�0000000�00000006275�12412610011�0023261�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
/* General interface for using the compressed index libraries */
#ifndef uchar
#define uchar unsigned char
#endif
#ifndef uint
#define uint unsigned int
#endif
#ifndef ulong
#define ulong unsigned long
#endif
/* Error management */
/* Returns a string describing the error associated with error number
e. The string must not be freed, and it will be overwritten with
subsequent calls. */
char* error_index(int e);
/* Building the index */
/* Creates index from text[0..length-1]. Note that the index is an
opaque data type. Any build option must be passed in string
build_options, whose syntax depends on the index. The index must
always work with some default parameters if build_options is NULL.
The returned index is ready to be queried. */
int build_index(uchar* text, ulong length, char* build_options, void** index);
/* Saves index on disk by using single or multiple files, having
proper extensions. */
int save_index(void* index, char* filename);
/* Loads index from one or more file(s) named filename, possibly
adding the proper extensions. */
int load_index(char* filename, void** index);
/* Frees the memory occupied by index. */
int free_index(void* index);
/* Gives the memory occupied by index in bytes. */
int index_size(void* index, ulong* size);
/* Querying the index */
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] found in the text indexed by index. */
int count(void* index, uchar* pattern, ulong length, ulong* numocc);
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] in the text indexed by index. It also allocates
occ (which must be freed by the caller) and writes the locations of
the numocc occurrences in occ, in arbitrary order. */
int locate(void* index, uchar* pattern, ulong length, ulong** occ,
ulong* numocc);
/* Gives the length of the text indexed */
int get_length(void* index, ulong* length);
/* Accessing the indexed text */
/* Allocates snippet (which must be freed by the caller) and writes
the substring text[from..to] into it. Returns in snippet_length the
length of the text snippet actually extracted (that could be less
than to-from+1 if to is larger than the text size). */
int extract(void* index, ulong from, ulong to, uchar** snippet,
ulong* snippet_length);
/* Displays the text (snippet) surrounding any occurrence of the
substring pattern[0..length-1] within the text indexed by index.
The snippet must include numc characters before and after the
pattern occurrence, totalizing length+2*numc characters, or less if
the text boundaries are reached. Writes in numocc the number of
occurrences, and allocates the arrays snippet_text and
snippet_lengths (which must be freed by the caller). The first is a
character array of numocc*(length+2*numc) characters, with a new
snippet starting at every multiple of length+2*numc. The second
gives the real length of each of the numocc snippets. */
int display(void* index, uchar* pattern, ulong length, ulong numc,
ulong* numocc, uchar** snippet_text, ulong** snippet_lengths);
/* Obtains the length of the text indexed by index. */
int length(void* index, ulong* length);
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/src/run_queries_sdsl.cpp�����������������������������������0000664�0000000�0000000�00000020530�12412610011�0025230�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Run Queries
*/
#include
#include
#include
#include "interface.h"
#include
#include
#include
/* only for getTime() */
#include
#include
#define COUNT ('C')
#define LOCATE ('L')
#define EXTRACT ('E')
#define DISPLAY ('D')
#define VERBOSE ('V')
using namespace sdsl;
using namespace std;
/* local headers */
void do_count(const CSA_TYPE&);
void do_locate(const CSA_TYPE&);
void pfile_info(ulong* length, ulong* numpatt);
double getTime(void);
void usage(char* progname);
static int Verbose = 0;
static ulong Index_size, Text_length;
static double Load_time;
/*
* Temporary usage: run_queries [length] [V]
*/
int main(int argc, char* argv[])
{
char* filename;
char querytype;
if (argc < 2) {
usage(argv[0]);
exit(1);
}
filename = argv[1];
querytype = *argv[2];
string index_file = string(argv[1]) + "." + string(SUF);
bool mapped = false;
#ifdef USE_HP
uint64_t index_size = util::file_size(index_file);
// allocate hugepages, add 10 MiB + 3% overhead
uint64_t alloc_size = (uint64_t)(index_size*1.03+(1ULL<<20)*10);
try {
memory_manager::use_hugepages(alloc_size);
mapped = true;
} catch (...) {
std::cout<<"Unable to allocate "< 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", COUNT);
}
do_count(csa);
break;
case LOCATE:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", LOCATE);
}
do_locate(csa);
break;
default:
fprintf(stderr, "Unknow option: main ru\n");
exit(1);
}
return 0;
}
void
do_count(const CSA_TYPE& csa)
{
ulong numocc, length, tot_numocc = 0, numpatt, res_patt;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
res_patt = numpatt;
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
while (res_patt) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
exit(1);
}
/* Count */
time = getTime();
numocc = sdsl::count(csa, pattern, pattern+length);
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
tot_time += (getTime() - time);
tot_numocc += numocc;
res_patt--;
}
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Count_time_in_milli_sec = %.4f\n", tot_time*1000);
fprintf(stderr, "# Count_time/Pattern_chars = %.4f\n",
(tot_time * 1000) / (length * numpatt));
fprintf(stderr, "# Count_time/Num_patterns = %.4f\n\n",
(tot_time * 1000) / numpatt);
fprintf(stderr, "# (Load_time+Count_time)/Pattern_chars = %.4f\n",
((Load_time+tot_time) * 1000) / (length * numpatt));
fprintf(stderr, "# (Load_time+Count_time)/Num_patterns = %.4f\n\n",
((Load_time+tot_time) * 1000) / numpatt);
free(pattern);
}
void
do_locate(const CSA_TYPE& csa)
{
ulong numocc, length;
ulong tot_numocc = 0, numpatt;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
while (numpatt) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
perror("run_queries");
exit(1);
}
// Locate
time = getTime();
auto occ = sdsl::locate(csa, (char*)pattern, (char*)pattern+length);
numocc = occ.size();
tot_time += (getTime() - time);
tot_numocc += numocc;
numpatt--;
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
}
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Locate_time_in_secs = %.2f\n", tot_time);
fprintf(stderr, "# Locate_time/Num_occs = %.4f\n\n", (tot_time * 1000) / tot_numocc);
fprintf(stderr, "# (Load_time+Locate_time)/Num_occs = %.4f\n\n", ((tot_time+Load_time) * 1000) / tot_numocc);
free(pattern);
}
/* Open patterns file and read header */
void
pfile_info(ulong* length, ulong* numpatt)
{
int error;
uchar c;
uchar origfilename[257];
error = fscanf(stdin, "# number=%lu length=%lu file=%s forbidden=", numpatt,
length, origfilename);
if (error != 3) {
fprintf(stderr, "Error: Patterns file header not correct\n");
perror("run_queries");
exit(1);
}
fprintf(stderr, "# pat_cnt = %lu\n", *numpatt);
fprintf(stderr, "# pat_length = %lu\n", *length);
fprintf(stderr, "# forbidden_chars = ");
while ((c = fgetc(stdin)) != 0) {
if (c == '\n') break;
fprintf(stderr, "%d",c);
}
fprintf(stderr, "\n");
}
double
getTime(void)
{
double usertime, systime;
struct rusage usage;
getrusage(RUSAGE_SELF, &usage);
usertime = (double) usage.ru_utime.tv_sec +
(double) usage.ru_utime.tv_usec / 1000000.0;
systime = (double) usage.ru_stime.tv_sec +
(double) usage.ru_stime.tv_usec / 1000000.0;
return (usertime + systime);
}
void usage(char* progname)
{
fprintf(stderr, "\nThe program loads and then executes over it the\n");
fprintf(stderr, "queries it receives from the standard input. The standard\n");
fprintf(stderr, "input comes in the format of the files written by \n");
fprintf(stderr, "genpatterns or genintervals.\n");
fprintf(stderr, "%s reports on the standard error time statistics\n", progname);
fprintf(stderr, "regarding to running the queries.\n\n");
fprintf(stderr, "Usage: %s [length] [V]\n", progname);
fprintf(stderr, "\n\t denotes the type of queries:\n");
fprintf(stderr, "\t %c counting queries;\n", COUNT);
fprintf(stderr, "\t %c locating queries;\n", LOCATE);
fprintf(stderr, "\t %c displaying queries;\n", DISPLAY);
fprintf(stderr, "\t %c extracting queries.\n\n", EXTRACT);
fprintf(stderr, "\n\t[length] must be provided in case of displaying queries (D)\n");
fprintf(stderr, "\t and denotes the number of characters to display\n");
fprintf(stderr, "\t before and after each pattern occurrence.\n");
fprintf(stderr, "\n\t[V] with this options it reports on the standard output\n");
fprintf(stderr, "\t the results of the queries. The results file should be\n");
fprintf(stderr, "\t compared with trusted one by compare program.\n\n");
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/test_case.config�������������������������������������������0000664�0000000�0000000�00000002454�12412610011�0023515�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration for test files
# (1) Identifier for test file (consisting of letters, no `.`)
# (2) Path to the test file
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENGLISH;../data/english.200MB;english.200MB;http://pizzachili.di.unipi.it/texts/nlang/english.200MB.gz
DBLPXML;../data/dblp.xml.200MB;dblp.xml.200MB;http://pizzachili.di.unipi.it/texts/xml/dblp.xml.200MB.gz
DNA;../data/dna.200MB;dna.200MB;http://pizzachili.di.unipi.it/texts/dna/dna.200MB.gz
PROTEINS;../data/proteins.200MB;proteins.200MB;http://pizzachili.di.unipi.it/texts/protein/proteins.200MB.gz
SOURCES;../data/sources.200MB;sources.200MB;http://pizzachili.di.unipi.it/texts/code/sources.200MB.gz
#INFLUENZA;../data/influenza;influenza;http://pizzachili.dcc.uchile.cl/repcorpus/real/influenza.gz
#EINSTEIN-de;../data/einstein.de.txt;einstein-de;http://pizzachili.dcc.uchile.cl/repcorpus/real/einstein.de.txt.gz
#EINSTEIN-en;../data/einstein.en.txt;einstein-en;http://pizzachili.dcc.uchile.cl/repcorpus/real/einstein.en.txt.gz
#PARA;../data/para;para;http://pizzachili.dcc.uchile.cl/repcorpus/real/para.gz
#WORLDLEADER;../data/world_leaders;world-leaders;http://pizzachili.dcc.uchile.cl/repcorpus/real/world_leaders.gz
#E-COLI;../data/Escherichia_Coli;E.coli;http://pizzachili.dcc.uchile.cl/repcorpus/real/Escherichia_Coli.gz
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/�������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022362�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/.gitignore���������������������������������������0000664�0000000�0000000�00000000132�12412610011�0024346�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
!Makefile
!count-footer.tex
!count-header.tex
!count.R
!index-filter.config
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/Makefile�����������������������������������������0000664�0000000�0000000�00000001120�12412610011�0024014�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../../Make.helper
COMPILE_IDS:=$(call config_ids,../compile_options.config)
TABLES = $(foreach COMPILE_ID,$(COMPILE_IDS),tbl-count-$(COMPILE_ID).tex)
CONFIG_FILES=index-filter.config ../index.config ../test_case.config
all: count.pdf
count.pdf: count.tex
@echo "Use pdflatex to generate count.pdf"
@pdflatex count.tex >> LaTeX.Log 2>&1
count.tex: ../results/all.txt ../../basic_functions.R count.R $(CONFIG_FILES)
@echo "Use R to generate count.tex"
@R --vanilla < count.R > R.log 2>&1
clean:
rm -f $(TABLES) count.pdf count.aux count.tex \
count.log R.log LaTeX.log
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/count-footer.tex���������������������������������0000664�0000000�0000000�00000000017�12412610011�0025526�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������\end{document}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/count-header.tex���������������������������������0000664�0000000�0000000�00000000167�12412610011�0025466�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������\documentclass[9pt,a4paper]{scrartcl}
\usepackage{booktabs}
\usepackage{array}
\usepackage{ragged2e}
\begin{document}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/count.R������������������������������������������0000664�0000000�0000000�00000011062�12412610011�0023635�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������library(xtable) # if not installed call install.packages("xtable")
library(plyr)
source("../../basic_functions.R")
# Load index information
idx_config <- readConfig("../index.config",c("IDX_ID","SDSL_TYPE","LATEX-NAME"))
tc_config <- readConfig("../test_case.config",c("TC_ID","PATH","LATEX-NAME","URL"))
compile_config <- readConfig("../compile_options.config",c("COMPILE_ID","OPTIONS"))
# Create data frame which maps test cases names to their index in the list
tc_ord <- data.frame("ord"=seq(1,nrow(tc_config)),"LATEX-NAME")
rownames(tc_ord) <- tc_config[["TC_ID"]]
# Load report information
config <- readConfig("index-filter.config",c("IDX_ID"))
# Load data
raw <- data_frame_from_key_value_pairs( "../results/all.txt" )
#
# Filer indexes
raw <- raw[raw[["IDX_ID"]]%in%config[["IDX_ID"]],]
raw[["IDX_ID"]] <- factor(raw[["IDX_ID"]])
# Normalize data
raw[["Time"]] <- raw[["Count_time_in_milli_sec"]]*1000
raw[["Time"]] <- raw[["Time"]]/(raw[["pat_cnt"]]*raw[["pat_length"]])
raw[["Time"]] <- round(raw[["Time"]], 3)
raw[["Space"]] <- raw[["Index_size_in_bytes"]]/raw[["text_size"]]
raw[["Space"]] <- round(raw[["Space"]],2)
raw <- raw[c("TC_ID", "Space", "Time","COMPILE_ID","IDX_ID")]
raw <- raw[order(raw[["TC_ID"]]),]
data <- split(raw, raw[["COMPILE_ID"]])
form_table <- function(d, order=NA){
# calculate the mean time per IDX_ID,TC_ID
d <- aggregate(d[c('Time','Space')],
by=list(IDX_ID=d[['IDX_ID']],
TC_ID=d[['TC_ID']]),
FUN=mean,na.rm=TRUE)
d <- d[ order(tc_ord[as.character(d[["TC_ID"]]),"ord"]), ]
dd <- split(d, d[["IDX_ID"]])
table <- data.frame(dd[[1]]["TC_ID"], stringsAsFactors=F)
names(table) <- c("TC_ID")
table[["TC_ID"]] <- paste("\\textsc{", tc_config[as.character(table[['TC_ID']]), "LATEX-NAME"],"}")
names(table) <- c(" ")
prog_name <- names(dd)
if( !is.na(order) ){
prog_name <- order
}
for( prog in prog_name ){
sel <- dd[[prog]]
table <- cbind(table, " "=rep("", length(sel["Time"])))
table <- cbind(table, round(sel["Time"],3))
table <- cbind(table, sel["Space"]*100)
}
unitrow <- paste(c("", rep(c("&","&($\\mu s$)","&(\\%)"),length(prog_name)), "\\\\[1ex]"),collapse="",sep='')
list("table" = table, "names" = table[["TC_ID"]], "unitrow"=unitrow)
}
make_latex_header <- function(names){
x <- paste("&&\\multicolumn{2}{c}{", names,"}")
x <- paste(x, collapse=" ")
clines=""
for(i in 1:length(names)){
clines <- paste(clines,"\\cmidrule{",3*i,"-",3*i+1,"}",sep="")
}
y <- paste("\\toprule",x, "\\\\",clines,"\n")
gsub("_","\\\\_",y)
}
print_latex <- function( table, names, unitrow ){
ali <- c("l","r", rep(c("@{\\hspace{1ex}}l","c","c"), (ncol(table)-1)/3) )
dig <- c(0, 0, rep(c(0,3,0),(ncol(table)-1)/3 ))
print( xtable( table, align=ali, digits=dig ),
type="latex", hline.after=c(), # TODO replace by bottomrule
floating = F, # don't use table environment
add.to.row=list(pos=list(-1,0,nrow(table)),
command=c(make_latex_header(names),unitrow,"\\bottomrule")),
sanitize.rownames.function = identity,
sanitize.text.function = identity,
include.rownames = FALSE
)
}
generate_table <- function(file, data){
sink(file)
if ( nrow(data) > 0 ){
x <- form_table(data, config[["IDX_ID"]])
print_latex(x[["table"]], idx_config[as.character(config[["IDX_ID"]]), "LATEX-NAME"], x[["unitrow"]])
}else{
cat("\\begin{center}No data for this experiment\\end{center}")
}
sink(NULL)
}
for ( compile_id in names(data) ){
generate_table(paste("tbl-count-",compile_id,".tex",sep=''), data[[compile_id]])
}
sink("count.tex")
cat(paste(readLines("count-header.tex"),"\n",sep=""))
for ( compile_id in names(data) ){
cat("
\\begin{table}
\\centering
\\input{tbl-count-",compile_id,".tex}
\\caption{Time in $\\mu$sec per pattern symbol in a count query.
Index space as fraction of original file size.
Compile options:
\\texttt{",gsub("_","\\\\_",compile_config[compile_id, "OPTIONS"]),"}.
\\label{tbl-count-",compile_id,"}}
\\end{table}",sep="")
}
# output table containing type information
cat("\\begin{table}
\\centering",
typeInfoTable("../index.config", config[["IDX_ID"]], 1, 3, 2)
,"\\caption{Index identifier and corresponding sdsl-type.}
\\end{table}
")
cat(paste(readLines("count-footer.tex"),"\n",sep=""))
sink(NULL)
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_count/visualize/index-filter.config������������������������������0000664�0000000�0000000�00000000551�12412610011�0026144�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Use this file to specify which indexes are listed in the report count.pdf.
#
# List all the index ids which should be included in the report. Note that
# the listed index ids must also be present in the file `../index.config`.
# Each IDX_ID is listed on a separate line. The listing order is used
# in the report.
FM_HUFF
FM_HUFF_RRR15
FM_RLMN
FM_HUFF_RRR63
�������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/���������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0020671�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/Makefile�������������������������������������������������0000664�0000000�0000000�00000014053�12412610011�0022334�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../Make.helper
CFLAGS = $(MY_CXX_FLAGS) $(MY_CXX_OPT_FLAGS)
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
SRC_DIR = src
TMP_DIR = ../tmp
IVL_DIR = intervals
BIN_DIR = bin
TC_PATHS:=$(call config_column,test_case.config,2)
TC_IDS:=$(call config_ids,test_case.config)
IDX_IDS:=$(call config_ids,index.config)
SAMPLE_IDS:=$(call config_ids,sample.config)
RESULT_FILE=results/all.txt
QUERY_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/query_idx_$(IDX_ID).$(SAMPLE_ID)))
BUILD_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/build_idx_$(IDX_ID).$(SAMPLE_ID)))
INFO_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/info_$(IDX_ID).$(SAMPLE_ID)))
INTERVALS = $(foreach TC_ID,$(TC_IDS),$(IVL_DIR)/$(TC_ID).interval)
INDEXES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),indexes/$(TC_ID).$(IDX_ID).$(SAMPLE_ID))))
INFO_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),info/$(TC_ID).$(IDX_ID).$(SAMPLE_ID).json)))
TIME_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),results/$(TC_ID).$(IDX_ID).$(SAMPLE_ID))))
COMP_FILES = $(addsuffix .z.info,$(TC_PATHS))
all: $(BUILD_EXECS) $(QUERY_EXECS) $(INFO_EXECS)
info: $(INFO_EXECS) $(INFO_FILES)
indexes: $(INDEXES)
intervals: input $(INTERVALS) $(BIN_DIR)/genintervals
input: $(TC_PATHS)
compression: input $(COMP_FILES)
timing: input $(INDEXES) intervals $(TIME_FILES) compression info
@cat $(TIME_FILES) > $(RESULT_FILE)
@cd visualize; make
# results/[TC_ID].[IDX_ID].[SAMPLE_ID]
results/%: $(BUILD_EXECS) $(QUERY_EXECS) $(PATTERNS) $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
@echo "# TC_ID = $(TC_ID)" >> $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "# SAMPLE_ID = $(SAMPLE_ID)" >> $@
@echo "# S_SA = $(S_SA)" >> $@
@echo "# S_ISA = $(S_ISA)" >> $@
@echo "Run timing for $(IDX_ID).$(SAMPLE_ID) on $(TC_ID)"
@$(BIN_DIR)/query_idx_$(IDX_ID).$(SAMPLE_ID) \
indexes/$(TC_ID) E < $(IVL_DIR)/$(TC_ID).interval 2>> $@
# indexes/[TC_ID].[IDX_ID].[SAMPLE_ID]
indexes/%: $(BUILD_EXECS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
@echo "Building index $(IDX_ID).$(SAMPLE_ID) on $(TC)"
@$(BIN_DIR)/build_idx_$(IDX_ID).$(SAMPLE_ID) $(TC) $(TMP_DIR) $@
# info/[TC_ID].[IDX_ID].[SAMPLE_ID]
info/%.json: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
@echo "Generating info for $(IDX_ID) on $(TC_ID)"
$(BIN_DIR)/info_$(IDX_ID).$(SAMPLE_ID) indexes/$(TC_ID).$(IDX_ID).$(SAMPLE_ID) > $@
# $(IVL_DIR)/[TC_ID].interval
$(IVL_DIR)/%.interval: $(BIN_DIR)/genintervals
@echo "Generating intervals for $*"
$(eval TC:=$(call config_select,test_case.config,$*,2))
@$(BIN_DIR)/genintervals $(TC) 512 10000 $@ 2> /dev/null
$(BIN_DIR)/genintervals: $(SRC_DIR)/genintervals.c
@echo "Build interval generation program"
@$(MY_CC) -O3 -o $@ $(SRC_DIR)/genintervals.c
# $(BIN_DIR)/build_idx_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/build_idx_%: $(SRC_DIR)/build_index_sdsl.cpp index.config sample.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling build_idx_$*"
@$(MY_CXX) $(CFLAGS) -DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-DS_SA=$(S_SA) -DS_ISA=$(S_ISA) \
-L$(LIB_DIR) $(SRC_DIR)/build_index_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/count_queries_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/query_idx_%: $(SRC_DIR)/run_queries_sdsl.cpp index.config sample.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling query_idx_$*"
@$(MY_CXX) $(CFLAGS) -DSUF="$(IDX_ID).$(SAMPLE_ID)" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/run_queries_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the info executable. $(BIN_DIR)/info_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/info_%: $(SRC_DIR)/info.cpp index.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling info_$*"
@$(MY_CXX) $(CFLAGS) -DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/info.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
include ../Make.download
clean-build:
@echo "Remove executables"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS)
clean:
@echo "Remove executables"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS) \
$(BIN_DIR)/genintervals
cleanresults:
@echo "Remove result files"
@rm -f $(TIME_FILES) $(RESULT_FILE)
cleanall: clean cleanresults
@echo "Remove all generated files."
@rm -f $(INDEXES) $(INFO_FILES) $(PATTERNS)
@rm -f $(TMP_DIR)/*
@rm -f $(INTERVALS)
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/README.md������������������������������������������������0000664�0000000�0000000�00000007661�12412610011�0022162�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking operation `extract` on FM-indexes
## Methodology
Explored dimensions:
* text type
* instance size (just adjust the test_case.config file for this)
* suffix array sampling density
* index implementations
Interval selection:
We use the methodology of [Ferragina et al.][FGNV08] (Section 5.4),
i.e. 10,000 substrings of length 512 starting at random texts positions
are extracted.
## Directory structure
* [bin](./bin): Contains the executables of the project.
* `build_idx_*` generates indexes
* `query_idx_*` executes the extract experiments
* `info_*` outputs the space breakdown of an index.
* `genintervals` intervals generator
* [indexes](./indexes): Contains the generated indexes.
* [intervals](./intervals): Contains the generated intervals.
* [results](./results): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which
generates a report in LaTeX format.
Files included in this archive from the [Pizza&Chili][pz] website:
* [src/run_quries_sdsl.cpp](src/run_queries_sdsl.cpp) is a adapted version of the
Pizza&Chili file run_queries.c .
* [src/genintervals.c](src/genintervals.c) is their interval generation
program.
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with package `tikzDevice`. You can install the
package by calling
`install.packages("filehash", repos="http://cran.r-project.org")`
and
`install.packages("tikzDevice", repos="http://R-Forge.R-project.org")`
in `R`.
- Compressors [xz][XZ] and [gzip][GZIP] are used to get
compression baselines.
- [pdflatex][LT] to generate the pdf reports.
* The construction of the 200MB indexes requires about 1GB
of RAM.
## Usage
* `make timing` compiles the programs, downloads the 200MB
[Pizza&Chili][pz] test cases, builds the indexes,
runs the performance tests, and generated a report located at
`visualize/extract.pdf`. The raw numbers of the timings
can be found in the `results/all.txt`.
Indexes and temporary files are stored in the
directory `indexes` and `tmp`. For the 5 x 200 MB of
[Pizza&Chili][pz] data the project will produce about
36 GB of additional data. On my machine (MacBookPro Retina
2.6GHz Intel Core i7, 16GB 1600 Mhz DDR3, SSD) the
benchmark, triggerd by `make timing`, took about 2 hours
(excluding the time to download the test instances).
Have a look at the [generated report][RES].
* All created indexes and test results can be deleted
by calling `make cleanall`.
## Customization of the benchmark
The project contains several configuration files:
* [index.config][IDXCONFIG]: Specify data structures'
ID, sdsl-class and LaTeX-name for the report.
* [test_case.config][TCCONF]: Specify test cases's
ID, path, LaTeX-name for the report, and download URL.
* [sample.config][SCONF]: Specify samplings' ID,
rate for SA, and rate for ISA.
Note that the benchmark will execute every combination of your
choices.
Finally, the visualization can also be configured:
* [visualize/index-filter.config][VCONF]: Specify which
indexes should be listed in the report and which style should be used.
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/extract.pdf "extract.pdf"
[FGNV08]: http://dl.acm.org/citation.cfm?doid=1412228.1455268 "FGNV08"
[IDXCONFIG]: ./index.config "index.config"
[TCCONF]: ./test_case.config "test_case.config"
[SCONF]: ./sample.config "sample.config"
[VCONF]: ./visualize/index-filter.config "index-filter.config"
[XZ]: http://tukaani.org/xz/ "XZ Compressor"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
�������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/bin/�����������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021441�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/bin/.gitignore�������������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023426�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/index.config���������������������������������������������0000664�0000000�0000000�00000001656�12412610011�0023177�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Specify the extract indexes here. Use S_SA and S_ISA as generic sample parameters.
# S_SA and S_ISA will be replaced by the values in sample.config
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATE_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in the name.
# * SDSL_TYPE : Corresponding sdsl type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
FM_HUFF;csa_wt,select_support_scan<>,select_support_scan<> >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-V5
FM_HUFF_RRR15;csa_wt >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-R$^3$15
CSA_SADA;csa_sada,S_SA,S_ISA,text_order_sa_sampling > >;CSA-SADA
FM_HUFF_RRR63;csa_wt >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-R$^3$63
����������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/indexes/�������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022330�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/indexes/.gitignore���������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024315�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/info/����������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021624�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/info/.gitignore������������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023611�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/intervals/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022700�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/intervals/.gitignore�������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024665�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/results/�������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022372�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/results/.gitignore���������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024357�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/sample.config��������������������������������������������0000664�0000000�0000000�00000000633�12412610011�0023343�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Specify the sample rate for suffix array (SA) and inverse suffix array (ISA).
# You can use the constants SA_MAX and ISA_MAX for the maximal sparse sampling
# for SA and ISA.
# Each sampling pair is specified by a triple: SAMPLING_ID;SA_SAMPLE_RATE;ISA_SAMPLE_RATE
# SAMPLING_ID should consist only of symbols in A-Z,a-z,0-9
4x4;4;4
8x8;8;8
16x16;16;16
32x32;32;32
64x64;64;64
128x128;128;128
256x256;256;256
�����������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/src/�����������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021460�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/src/build_index_sdsl.cpp���������������������������������0000664�0000000�0000000�00000001131�12412610011�0025473�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include
#include
using namespace sdsl;
using namespace std;
int main(int argc, char** argv)
{
if (argc < 4) {
cout << "Usage ./" << argv[0] << " input_file tmp_dir output_file" << endl;
return 0;
}
CSA_TYPE csa;
if (argc < 3) {
construct(csa, argv[1], 1);
} else {
// config: do not delete files, tmp_dir=argv[2], id=basename(argv[1])
cache_config cconfig(false, argv[2], util::basename(argv[1]));
construct(csa, argv[1], cconfig, 1);
}
store_to_file(csa, argv[3]);
}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/src/genintervals.c���������������������������������������0000664�0000000�0000000�00000006434�12412610011�0024334�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
// Chooses random intervals from a file
#include
#include
#include
#include
#include
#include
#include
static int Seed;
#define ACMa 16807
#define ACMm 2147483647
#define ACMq 127773
#define ACMr 2836
#define hi (Seed / ACMq)
#define lo (Seed % ACMq)
static int fst=1;
/* returns a random integer in 0..top-1 */
int aleat(top)
{
long test;
struct timeval t;
if (fst) {
gettimeofday(&t,NULL);
Seed = t.tv_sec*t.tv_usec;
fst=0;
}
{
Seed = ((test = ACMa * lo - ACMr * hi) > 0) ? test : test + ACMm;
return ((double)Seed) * top/ACMm;
}
}
main(int argc, char** argv)
{
int n,m,J,t;
struct stat sdata;
FILE* ifile,*ofile;
unsigned char* buff;
if (argc < 5) {
fprintf(stderr,
"Usage: %s \n"
" randomly extracts intervals of length from .\n"
" The output file, has a first line of the form:\n"
" # number= length= file=\n"
" and then lines of the form ,.\n",argv[0]
);
exit(1);
}
if (stat(argv[1],&sdata) != 0) {
fprintf(stderr,"Error: cannot stat file %s\n",argv[1]);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
n = sdata.st_size;
m = atoi(argv[2]);
if ((m <= 0) || (m > n)) {
fprintf(stderr,"Error: length must be >= 1 and <= file length"
" (%i)\n",n);
exit(1);
}
J = atoi(argv[3]);
if (J < 1) {
fprintf(stderr,"Error: number of intervals must be >= 1\n");
exit(1);
}
ifile = fopen(argv[1],"r");
if (ifile == NULL) {
fprintf(stderr,"Error: cannot open file %s for reading\n",argv[1]);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
buff = (unsigned char*) malloc(n);
if (buff == NULL) {
fprintf(stderr,"Error: cannot allocate %i bytes\n",n);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
if (fread(buff,n,1,ifile) != 1) {
fprintf(stderr,"Error: cannot read file %s\n",argv[1]);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
fclose(ifile);
ofile = fopen(argv[4],"w");
if (ofile == NULL) {
fprintf(stderr,"Error: cannot open file %s for writing\n",argv[4]);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
if (fprintf(ofile,"# number=%i length=%i file=%s\n", J,m,argv[1]) <= 0) {
fprintf(stderr,"Error: cannot write file %s\n",argv[4]);
fprintf(stderr," errno = %i\n",errno);
exit(1);
}
for (t=0; t
#include
using namespace sdsl;
using namespace std;
int main(int argc, char* argv[])
{
if (argc < 2) {
cout << "./" << argv[0] << " index_file " << endl;
return 1;
}
CSA_TYPE csa;
load_from_file(csa, argv[1]);
write_structure(csa, cout);
}
�����������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/src/interface.h������������������������������������������0000664�0000000�0000000�00000006275�12412610011�0023603�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
/* General interface for using the compressed index libraries */
#ifndef uchar
#define uchar unsigned char
#endif
#ifndef uint
#define uint unsigned int
#endif
#ifndef ulong
#define ulong unsigned long
#endif
/* Error management */
/* Returns a string describing the error associated with error number
e. The string must not be freed, and it will be overwritten with
subsequent calls. */
char* error_index(int e);
/* Building the index */
/* Creates index from text[0..length-1]. Note that the index is an
opaque data type. Any build option must be passed in string
build_options, whose syntax depends on the index. The index must
always work with some default parameters if build_options is NULL.
The returned index is ready to be queried. */
int build_index(uchar* text, ulong length, char* build_options, void** index);
/* Saves index on disk by using single or multiple files, having
proper extensions. */
int save_index(void* index, char* filename);
/* Loads index from one or more file(s) named filename, possibly
adding the proper extensions. */
int load_index(char* filename, void** index);
/* Frees the memory occupied by index. */
int free_index(void* index);
/* Gives the memory occupied by index in bytes. */
int index_size(void* index, ulong* size);
/* Querying the index */
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] found in the text indexed by index. */
int count(void* index, uchar* pattern, ulong length, ulong* numocc);
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] in the text indexed by index. It also allocates
occ (which must be freed by the caller) and writes the locations of
the numocc occurrences in occ, in arbitrary order. */
int locate(void* index, uchar* pattern, ulong length, ulong** occ,
ulong* numocc);
/* Gives the length of the text indexed */
int get_length(void* index, ulong* length);
/* Accessing the indexed text */
/* Allocates snippet (which must be freed by the caller) and writes
the substring text[from..to] into it. Returns in snippet_length the
length of the text snippet actually extracted (that could be less
than to-from+1 if to is larger than the text size). */
int extract(void* index, ulong from, ulong to, uchar** snippet,
ulong* snippet_length);
/* Displays the text (snippet) surrounding any occurrence of the
substring pattern[0..length-1] within the text indexed by index.
The snippet must include numc characters before and after the
pattern occurrence, totalizing length+2*numc characters, or less if
the text boundaries are reached. Writes in numocc the number of
occurrences, and allocates the arrays snippet_text and
snippet_lengths (which must be freed by the caller). The first is a
character array of numocc*(length+2*numc) characters, with a new
snippet starting at every multiple of length+2*numc. The second
gives the real length of each of the numocc snippets. */
int display(void* index, uchar* pattern, ulong length, ulong numc,
ulong* numocc, uchar** snippet_text, ulong** snippet_lengths);
/* Obtains the length of the text indexed by index. */
int length(void* index, ulong* length);
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/src/run_queries_sdsl.cpp���������������������������������0000664�0000000�0000000�00000023304�12412610011�0025554�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Run Queries
*/
#include
#include
#include
#include "interface.h"
#include
#include
#include
/* only for getTime() */
#include
#include
#define COUNT ('C')
#define LOCATE ('L')
#define EXTRACT ('E')
#define DISPLAY ('D')
#define VERBOSE ('V')
using namespace sdsl;
using namespace std;
/* local headers */
void do_count(const CSA_TYPE&);
void do_locate(const CSA_TYPE&);
void do_extract(const CSA_TYPE&);
//void do_display(ulong length);
void pfile_info(ulong* length, ulong* numpatt);
//void output_char(uchar c, FILE * where);
double getTime(void);
void usage(char* progname);
static int Verbose = 0;
static ulong Index_size, Text_length;
static double Load_time;
/*
* Temporary usage: run_queries [length] [V]
*/
int main(int argc, char* argv[])
{
char* filename;
char querytype;
if (argc < 2) {
usage(argv[0]);
exit(1);
}
filename = argv[1];
querytype = *argv[2];
CSA_TYPE csa;
fprintf(stderr, "Load from file %s\n",(string(filename) + "." + string(SDSL_XSTR(SUF))).c_str());
Load_time = getTime();
load_from_file(csa, (string(argv[1]) + "." + string(SDSL_XSTR(SUF))).c_str());
Load_time = getTime() - Load_time;
fprintf(stderr, "# Load_index_time_in_sec = %.2f\n", Load_time);
std::cerr << "# text_size = " << csa.size()-1 << std::endl;
Index_size = size_in_bytes(csa);
Text_length = csa.size()-1; // -1 since we added a sentinel character
fprintf(stderr, "# Index_size_in_bytes = %lu\n", Index_size);
#ifdef USE_HP
bool mapped = mm::map_hp();
fprintf(stderr, "# hugepages = %i\n", (int)mapped);
#endif
switch (querytype) {
case COUNT:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", COUNT);
}
do_count(csa);
break;
case LOCATE:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", LOCATE);
}
do_locate(csa);
break;
case EXTRACT:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", EXTRACT);
}
do_extract(csa);
break;
default:
fprintf(stderr, "Unknow option: main ru\n");
exit(1);
}
#ifdef USE_HP
if (mapped) {
mm::unmap_hp();
}
#endif
return 0;
}
void
do_count(const CSA_TYPE& csa)
{
ulong numocc, length, tot_numocc = 0, numpatt, res_patt;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
res_patt = numpatt;
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
while (res_patt) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
perror("run_queries");
exit(1);
}
/* Count */
time = getTime();
numocc = count(csa, pattern, pattern+length);
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
tot_time += (getTime() - time);
tot_numocc += numocc;
res_patt--;
}
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Count_time_in_milli_sec = %.4f\n", tot_time*1000);
fprintf(stderr, "# Count_time/Pattern_chars = %.4f\n",
(tot_time * 1000) / (length * numpatt));
fprintf(stderr, "# Count_time/Num_patterns = %.4f\n\n",
(tot_time * 1000) / numpatt);
fprintf(stderr, "# (Load_time+Count_time)/Pattern_chars = %.4f\n",
((Load_time+tot_time) * 1000) / (length * numpatt));
fprintf(stderr, "# (Load_time+Count_time)/Num_patterns = %.4f\n\n",
((Load_time+tot_time) * 1000) / numpatt);
free(pattern);
}
void
do_locate(const CSA_TYPE& csa)
{
ulong numocc, length;
ulong tot_numocc = 0, numpatt = 0, processed_pat = 0;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
/*SG: added timeout of 60 seconds */
while (numpatt and tot_time < 60.0) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
perror("run_queries");
exit(1);
}
// Locate
time = getTime();
auto occ = locate(csa, (char*)pattern, (char*)pattern+length);
numocc = occ.size();
tot_time += (getTime() - time);
++processed_pat;
tot_numocc += numocc;
numpatt--;
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
}
fprintf(stderr, "# processed_pattern = %lu\n", processed_pat);
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Locate_time_in_secs = %.2f\n", tot_time);
fprintf(stderr, "# Locate_time/Num_occs = %.4f\n\n", (tot_time * 1000) / tot_numocc);
fprintf(stderr, "# (Load_time+Locate_time)/Num_occs = %.4f\n\n", ((tot_time+Load_time) * 1000) / tot_numocc);
free(pattern);
}
/* Open patterns file and read header */
void
pfile_info(ulong* length, ulong* numpatt)
{
int error;
uchar c;
uchar origfilename[257];
error = fscanf(stdin, "# number=%lu length=%lu file=%s forbidden=", numpatt,
length, origfilename);
if (error != 3) {
fprintf(stderr, "Error: Patterns file header not correct\n");
perror("run_queries");
exit(1);
}
fprintf(stderr, "# pat_cnt = %lu\n", *numpatt);
fprintf(stderr, "# pat_length = %lu\n", *length);
fprintf(stderr, "# forbidden_chars = ");
while ((c = fgetc(stdin)) != 0) {
if (c == '\n') break;
fprintf(stderr, "%d",c);
}
fprintf(stderr, "\n");
}
void
do_extract(const CSA_TYPE& csa)
{
int error = 0;
uchar* text, orig_file[257];
ulong num_pos, from, to, numchars, tot_ext = 0;
CSA_TYPE::size_type readlen = 0;
double time, tot_time = 0;
error = fscanf(stdin, "# number=%lu length=%lu file=%s\n", &num_pos, &numchars, orig_file);
if (error != 3) {
fprintf(stderr, "Error: Intervals file header is not correct\n");
perror("run_queries");
exit(1);
}
fprintf(stderr, "# number=%lu length=%lu file=%s\n", num_pos, numchars, orig_file);
while (num_pos) {
if (fscanf(stdin,"%lu,%lu\n", &from, &to) != 2) {
fprintf(stderr, "Cannot read correctly intervals file\n");
exit(1);
}
time = getTime();
text = (uchar*)malloc(to-from+2);
readlen = sdsl::extract(csa, from, to, text);
tot_time += (getTime() - time);
tot_ext += readlen;
if (Verbose) {
fwrite(&from,sizeof(ulong),1,stdout);
fwrite(&readlen,sizeof(ulong),1,stdout);
fwrite(text,sizeof(uchar),readlen, stdout);
}
num_pos--;
free(text);
}
fprintf(stderr, "# Total_num_chars_extracted = %lu\n", tot_ext);
fprintf(stderr, "# Extract_time_in_sec = %.2f\n", tot_time);
fprintf(stderr, "# Extract_time/Num_chars_extracted = %.4f\n\n",
(tot_time * 1000) / tot_ext);
fprintf(stderr, "(Load_time+Extract_time)/Num_chars_extracted = %.4f\n\n",
((Load_time+tot_time) * 1000) / tot_ext);
}
double
getTime(void)
{
double usertime, systime;
struct rusage usage;
getrusage(RUSAGE_SELF, &usage);
usertime = (double) usage.ru_utime.tv_sec +
(double) usage.ru_utime.tv_usec / 1000000.0;
systime = (double) usage.ru_stime.tv_sec +
(double) usage.ru_stime.tv_usec / 1000000.0;
return (usertime + systime);
}
void usage(char* progname)
{
fprintf(stderr, "\nThe program loads and then executes over it the\n");
fprintf(stderr, "queries it receives from the standard input. The standard\n");
fprintf(stderr, "input comes in the format of the files written by \n");
fprintf(stderr, "genpatterns or genintervals.\n");
fprintf(stderr, "%s reports on the standard error time statistics\n", progname);
fprintf(stderr, "regarding to running the queries.\n\n");
fprintf(stderr, "Usage: %s [length] [V]\n", progname);
fprintf(stderr, "\n\t denotes the type of queries:\n");
fprintf(stderr, "\t %c counting queries;\n", COUNT);
fprintf(stderr, "\t %c locating queries;\n", LOCATE);
fprintf(stderr, "\t %c displaying queries;\n", DISPLAY);
fprintf(stderr, "\t %c extracting queries.\n\n", EXTRACT);
fprintf(stderr, "\n\t[length] must be provided in case of displaying queries (D)\n");
fprintf(stderr, "\t and denotes the number of characters to display\n");
fprintf(stderr, "\t before and after each pattern occurrence.\n");
fprintf(stderr, "\n\t[V] with this options it reports on the standard output\n");
fprintf(stderr, "\t the results of the queries. The results file should be\n");
fprintf(stderr, "\t compared with trusted one by compare program.\n\n");
}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/test_case.config�����������������������������������������0000664�0000000�0000000�00000001270�12412610011�0024032�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration for test files
# (1) Identifier for test file (consisting of letters, no `.`)
# (2) Path to the test file
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENGLISH;../data/english.200MB;english.200MB;http://pizzachili.di.unipi.it/texts/nlang/english.200MB.gz
DBLPXML;../data/dblp.xml.200MB;dblp.xml.200MB;http://pizzachili.di.unipi.it/texts/xml/dblp.xml.200MB.gz
DNA;../data/dna.200MB;dna.200MB;http://pizzachili.di.unipi.it/texts/dna/dna.200MB.gz
PROTEINS;../data/proteins.200MB;proteins.200MB;http://pizzachili.di.unipi.it/texts/protein/proteins.200MB.gz
SOURCES;../data/sources.200MB;sources.200MB;http://pizzachili.di.unipi.it/texts/code/sources.200MB.gz
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/�����������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022704�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/.gitignore�������������������������������������0000664�0000000�0000000�00000000105�12412610011�0024670�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
!Makefile
!extract.R
!extract.tex
!index-filter.config
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/Makefile���������������������������������������0000664�0000000�0000000�00000001122�12412610011�0024340�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../../Make.helper
CONFIG_FILES=index-filter.config ../index.config ../test_case.config ../sample.config
all: extract.pdf
extract.pdf: extract.tex tbl-extract.tex fig-extract.tex
@echo "Use pdflatex to generate extract.pdf"
@pdflatex extract.tex >> LaTeX.Log 2>&1
tbl-extract.tex fig-extract.tex: ../../basic_functions.R extract.R $(CONFIG_FILES) ../results/all.txt
@echo "Use R to generate fig-extract.tex and tbl-extract.tex"
@R --vanilla < extract.R > R.log 2>&1
clean:
rm -f extract.pdf extract.aux extract.log R.log LaTeX.log \
tbl-extract.tex fig-extract.tex
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/extract.R��������������������������������������0000664�0000000�0000000�00000005616�12412610011�0024511�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������require(tikzDevice)
source("../../basic_functions.R")
# Load filter information
config <- readConfig("index-filter.config",c("IDX_ID","PCH","LTY","COL"))
idx_config <- readConfig("../index.config",c("IDX_ID","SDSL_TYPE","LATEX-NAME"))
tc_config <- readConfig("../test_case.config",c("TC_ID","PATH","LATEX-NAME","URL"))
# Load data
raw <- data_frame_from_key_value_pairs( "../results/all.txt" )
# Filter indexes
raw <- raw[raw[["IDX_ID"]]%in%config[["IDX_ID"]],]
raw[["IDX_ID"]] <- factor(raw[["IDX_ID"]])
# Normalize data
raw[["Time"]] <- 1000000*raw[["Extract_time_in_sec"]]/raw[["Total_num_chars_extracted"]]
raw[["Space"]] <- 100*raw[["Index_size_in_bytes"]]/raw[["text_size"]]
raw <- raw[c("TC_ID", "Space", "Time","IDX_ID","S_SA","S_ISA")]
raw <- raw[order(raw[["TC_ID"]]),]
data <- split(raw, raw[["TC_ID"]])
tikz("fig-extract.tex", width = 5.5, height = 6, standAlone = F)
multi_figure_style( length(data)/2+1, 2 )
max_space <- 100*2.5 #1.3 # 2.5 #1.8
max_time <- max(raw[["Time"]]) # in microseconds
count <- 0
nr <- 0
xlabnr <- (2*(length(data)/2)-1)
for( tc_id in names(data) ){
d <- data[[tc_id]]
plot(c(),c(),xlim=c(0, max_space), ylim=c(0, max_time), xlab="", axes=F, xaxt="n", yaxt="n", ylab="" )
box(col="gray")
grid(lty="solid")
if ( nr %% 2 == 0 ){
ylable <- "Time per character ($\\mu s$)"
axis( 2, at = axTicks(2) )
mtext(ylable, side=2, line=2, las=0)
}
axis( 1, at = axTicks(1), labels=(nr>=xlabnr) )
if ( nr >= xlabnr ){
xlable <- "Index size in (\\%)"
mtext(xlable, side=1, line=2, las=0)
}
dd <- split(d, d[["IDX_ID"]])
for( idx_id in names(dd) ){
ddd <- dd[[idx_id]]
lines(ddd[["Space"]], ddd[["Time"]], type="b", lwd=1, pch=config[idx_id, "PCH"],
lty=config[idx_id, "LTY"],
col=config[idx_id, "COL"]
)
}
draw_figure_heading( sprintf("instance = \\textsc{%s}",tc_config[tc_id,"LATEX-NAME"]) )
comp_info <- readConfig(paste("../",tc_config[tc_id,"PATH"],".z.info",sep=""),c("NAME","RATIO","COMMAND"))
abline(v=comp_info["xz","RATIO"],lty=1);
abline(v=comp_info["gzip","RATIO"],lty=4);
nr <- nr+1
if ( nr == 1 ){ # plot legend
plot(NA, NA, xlim=c(0,1),ylim=c(0,1),ylab="", xlab="", bty="n", type="n", yaxt="n", xaxt="n")
idx_ids <- as.character(unique(raw[["IDX_ID"]]))
legend( "top", legend=idx_config[idx_ids,"LATEX-NAME"], pch=config[idx_ids,"PCH"], col=config[idx_ids,"COL"],
lty=config[idx_ids,"LTY"], bty="n", y.intersp=1.5, ncol=2, title="Index", cex=1.2)
legend( "bottom", legend=c("\\textsc{xz}~(\\texttt{-9})","\\textsc{gzip}~(\\texttt{-9})"),
lty=c(1,4), bty="n", y.intersp=1.5, ncol=2, title="Compression baseline", cex=1.2)
nr <- nr+1
}
}
dev.off()
sink("tbl-extract.tex")
cat(typeInfoTable("../index.config", config[["IDX_ID"]], 1, 3, 2))
sink(NULL)
������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/extract.tex������������������������������������0000664�0000000�0000000�00000000776�12412610011�0025112�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������\documentclass[9pt,a4paper]{scrartcl}
\usepackage{array}
\usepackage{booktabs}
\usepackage{ragged2e}
\usepackage{tikz}
\begin{document}
\pagestyle{empty}
\begin{figure}
\input{fig-extract.tex}
\caption{Time-space trade-offs for operation extract.}
\end{figure}
\begin{table}
\centering
\input{tbl-extract.tex}
\caption{Class definition of the indexes used in the experiment.
The sampling rates \texttt{S\_SA} and \texttt{S\_ISA} for
suffix and inverse suffix values was varied.}
\end{table}
\end{document}
��sdsl-lite-2.0.3/benchmark/indexing_extract/visualize/index-filter.config����������������������������0000664�0000000�0000000�00000001002�12412610011�0026456�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Use this file to specify which indexes are listed in the report extract.pdf
# and how they look like in the report.
#
# List all the index ids which should be included in the report. Note that
# the listed index ids must also be present in the file `../index.config`.
# Eeach INDEX_ID should be listed on a separate line followed by the style:
# [pch];[lty];[col] (point type, line type, and color).
FM_HUFF; 1;solid;black
FM_HUFF_RRR15; 2;solid;blue
CSA_SADA; 3;solid;red
FM_HUFF_RRR63; 4;solid;blue
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/����������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0020466�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/Makefile��������������������������������������������������0000664�0000000�0000000�00000014145�12412610011�0022133�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../Make.helper
CFLAGS = $(MY_CXX_FLAGS) $(MY_CXX_OPT_FLAGS)
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
SRC_DIR = src
TMP_DIR = ../tmp
PAT_DIR = pattern
BIN_DIR = bin
TC_PATHS:=$(call config_column,test_case.config,2)
TC_IDS:=$(call config_ids,test_case.config)
IDX_IDS:=$(call config_ids,index.config)
SAMPLE_IDS:=$(call config_ids,sample.config)
RESULT_FILE=results/all.txt
QUERY_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/query_idx_$(IDX_ID).$(SAMPLE_ID)))
BUILD_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/build_idx_$(IDX_ID).$(SAMPLE_ID)))
INFO_EXECS = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),$(BIN_DIR)/info_$(IDX_ID).$(SAMPLE_ID)))
PATTERNS = $(foreach TC_ID,$(TC_IDS),$(PAT_DIR)/$(TC_ID).pattern)
INDEXES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),indexes/$(TC_ID).$(IDX_ID).$(SAMPLE_ID))))
INFO_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),info/$(TC_ID).$(IDX_ID).$(SAMPLE_ID).html)))
TIME_FILES = $(foreach IDX_ID,$(IDX_IDS),\
$(foreach TC_ID,$(TC_IDS),\
$(foreach SAMPLE_ID,$(SAMPLE_IDS),results/$(TC_ID).$(IDX_ID).$(SAMPLE_ID))))
COMP_FILES = $(addsuffix .z.info,$(TC_PATHS))
all: $(BUILD_EXECS) $(QUERY_EXECS) $(INFO_EXECS)
info: $(INFO_EXECS) $(INFO_FILES)
indexes: $(INDEXES)
input: $(TC_PATHS)
pattern: input $(PATTERNS) $(BIN_DIR)/pattern_random
compression: input $(COMP_FILES)
timing: input $(INDEXES) pattern $(TIME_FILES) compression info
@cat $(TIME_FILES) > $(RESULT_FILE)
@cd visualize; make
# results/[TC_ID].[IDX_ID].[SAMPLE_ID]
results/%: $(BUILD_EXECS) $(QUERY_EXECS) $(PATTERNS) $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
$(eval TC_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
@echo "# TC_ID = $(TC_ID)" >> $@
@echo "# IDX_ID = $(IDX_ID)" >> $@
@echo "# test_case = $(TC_NAME)" >> $@
@echo "# SAMPLE_ID = $(SAMPLE_ID)" >> $@
@echo "# S_SA = $(S_SA)" >> $@
@echo "# S_ISA = $(S_ISA)" >> $@
@echo "Run timing for $(IDX_ID).$(SAMPLE_ID) on $(TC_ID)"
@$(BIN_DIR)/query_idx_$(IDX_ID).$(SAMPLE_ID) \
indexes/$(TC_ID) L < $(PAT_DIR)/$(TC_ID).pattern 2>> $@
# indexes/[TC_ID].[IDX_ID].[SAMPLE_ID]
indexes/%: $(BUILD_EXECS)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
$(eval TC:=$(call config_select,test_case.config,$(TC_ID),2))
@echo "Building index $(IDX_ID).$(SAMPLE_ID) on $(TC)"
@$(BIN_DIR)/build_idx_$(IDX_ID).$(SAMPLE_ID) $(TC) $(TMP_DIR) $@
# info/[TC_ID].[IDX_ID].[SAMPLE_ID]
info/%.html: $(INDEXES)
$(eval TC_ID:=$(call dim,1,$*))
$(eval IDX_ID:=$(call dim,2,$*))
$(eval SAMPLE_ID:=$(call dim,3,$*))
@echo "Generating info for $(IDX_ID) on $(TC_ID)"
$(BIN_DIR)/info_$(IDX_ID).$(SAMPLE_ID) indexes/$(TC_ID).$(IDX_ID).$(SAMPLE_ID) > $@
# $(PAT_DIR)/[TC_ID].pattern
$(PAT_DIR)/%.pattern: $(BIN_DIR)/pattern_random
@echo "Generating pattern for $*"
$(eval TC:=$(call config_select,test_case.config,$*,2))
@$(BIN_DIR)/pattern_random $(TC) $(TMP_DIR) 5 2000000 $@ $@.occ
$(BIN_DIR)/pattern_random: $(SRC_DIR)/pattern_random.cpp
@echo "Build pattern generation program"
@$(MY_CXX) $(CFLAGS) -L$(LIB_DIR) -I$(INC_DIR) \
$(SRC_DIR)/pattern_random.cpp -o $@ $(LIBS)
# $(BIN_DIR)/build_idx_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/build_idx_%: $(SRC_DIR)/build_index_sdsl.cpp index.config sample.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling build_idx_$*"
@$(MY_CXX) $(CFLAGS) -DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-DS_SA=$(S_SA) -DS_ISA=$(S_ISA) \
-L$(LIB_DIR) $(SRC_DIR)/build_index_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the count experiment. $(BIN_DIR)/count_queries_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/query_idx_%: $(SRC_DIR)/run_queries_sdsl.cpp index.config sample.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling query_idx_$*"
@$(MY_CXX) $(CFLAGS) -DSUF="$(IDX_ID).$(SAMPLE_ID)" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/run_queries_sdsl.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
# Targets for the info executable. $(BIN_DIR)/info_[IDX_ID].[SAMPLE_ID]
$(BIN_DIR)/info_%: $(SRC_DIR)/info.cpp index.config
$(eval IDX_ID:=$(call dim,1,$*))
$(eval SAMPLE_ID:=$(call dim,2,$*))
$(eval IDX_TYPE:=$(call config_select,index.config,$(IDX_ID),2))
$(eval S_SA:=$(call config_select,sample.config,$(SAMPLE_ID),2))
$(eval S_ISA:=$(call config_select,sample.config,$(SAMPLE_ID),3))
$(eval IDX_TYPE:=$(subst S_SA,$(S_SA),$(IDX_TYPE)))
$(eval IDX_TYPE:=$(subst S_ISA,$(S_ISA),$(IDX_TYPE)))
@echo "Compiling info_$*"
@$(MY_CXX) $(CFLAGS) -DSUF=\"$*\" -DCSA_TYPE="$(IDX_TYPE)" \
-L$(LIB_DIR) $(SRC_DIR)/info.cpp \
-I$(INC_DIR) -o $@ $(LIBS)
include ../Make.download
clean-build:
@echo "Remove executables"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS)
clean:
@echo "Remove executables"
@rm -f $(QUERY_EXECS) $(BUILD_EXECS) $(INFO_EXECS) \
$(BIN_DIR)/pattern_random
cleanresults:
@echo "Remove result files"
@rm -f $(TIME_FILES) $(RESULT_FILE)
cleanall: clean cleanresults
@echo "Remove all generated files."
@rm -f $(INDEXES) $(INFO_FILES) $(PATTERNS)
@rm -f $(TMP_DIR)/*
@rm -f $(PAT_DIR)/*
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/README.md�������������������������������������������������0000664�0000000�0000000�00000007552�12412610011�0021756�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking operation `locate` on FM-indexes
## Methodology
Explored dimensions:
* text type
* instance size (just adjust the test_case.config file for this)
* suffix array sampling density
* index implementations
Pattern selection:
We use the methodology of [Ferragina et al.][FGNV08] (Section 5.3):
,,Locate sufficient random patterns of length 5 to obtain a total of 2 to
3 million occurrences''.
## Directory structure
* [bin](./bin): Contains the executables of the project.
* `build_idx_*` generates indexes
* `query_idx_*` executes the locate experiments
* `info_*` outputs the space breakdown of an index.
* `pattern_random` pattern generator.
* [indexes](./indexes): Contains the generated indexes.
* [pattern](./pattern): Contains the generated pattern.
* [results](./results): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which
generates a report in LaTeX format.
Files included in this archive from the [Pizza&Chili][pz] website:
* [src/run_quries_sdsl.cpp](src/run_queries_sdsl.cpp) is a adapted version of the
Pizza&Chili file run_queries.c .
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with package `tikzDevice`. You can install the
package by calling
`install.packages("filehash", repos="http://cran.r-project.org")`
and
`install.packages("tikzDevice", repos="http://R-Forge.R-project.org")`
in `R`.
- Compressors [xz][XZ] and [gzip][GZIP] are used to get
compression baselines.
- [pdflatex][LT] to generate the pdf reports.
* The construction of the 200MB indexes requires about 1GB
of RAM.
## Usage
* `make timing` compiles the programs, downloads the 200MB
[Pizza&Chili][pz] test cases, builds the indexes,
runs the performance tests, and generated a report located at
`visualize/locate.pdf`. The raw numbers of the timings
can be found in the `results/all.txt`.
Indexes and temporary files are stored in the
directory `indexes` and `tmp`. For the 5 x 200 MB of
[Pizza&Chili][pz] data the project will produce about
36 GB of additional data. On my machine (MacBookPro Retina
2.6GHz Intel Core i7, 16GB 1600 Mhz DDR3, SSD) the
benchmark, triggerd by `make timing`, took about 2 hours
and 20 minutes (excluding the time to download the test instances).
Have a look at the [generated report][RES].
* All created indexes and test results can be deleted
by calling `make cleanall`.
## Customization of the benchmark
The project contains several configuration files:
* [index.config][IDXCONFIG]: Specify data structures'
ID, sdsl-class and LaTeX-name for the report.
* [test_case.config][TCCONF]: Specify test cases's
ID, path, LaTeX-name for the report, and download URL.
* [sample.config][SCONF]: Specify samplings' ID,
rate for SA, and rate for ISA.
Note that the benchmark will execute every combination of your
choices.
Finally, the visualization can also be configured:
* [visualize/index-filter.config][VCONF]: Specify which
indexes should be listed in the report and which style should be used.
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/locate.pdf "locate.pdf"
[FGNV08]: http://dl.acm.org/citation.cfm?doid=1412228.1455268 "FGNV08"
[IDXCONFIG]: ./index.config "index.config"
[TCCONF]: ./test_case.config "test_case.config"
[SCONF]: ./sample.config "sample.config"
[VCONF]: ./visualize/index-filter.config "index-filter.config"
[XZ]: http://tukaani.org/xz/ "XZ Compressor"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/bin/������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021236�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/bin/.gitignore��������������������������������������������0000664�0000000�0000000�00000000016�12412610011�0023223�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/index.config����������������������������������������������0000664�0000000�0000000�00000001655�12412610011�0022773�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Specify the locate indexes here. Use S_SA and S_ISA as generic sample parameters.
# S_SA and S_ISA will be replaced by the values in sample.config
#
# Each index is specified by a triple: INDEX_ID;SDSL_TYPE;INDEX_LATE_NAME
# * INDEX_ID : An identifier for the index. Only letters and underscores
# are allowed in the name.
# * SDSL_TYPE : Corresponding sdsl type.
# * LATEX_NAME: LaTeX name for output in the benchmark report.
FM_HUFF;csa_wt,select_support_scan<>,select_support_scan<> >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-V5
FM_HUFF_RRR15;csa_wt >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-R$^3$15
CSA_SADA;csa_sada,S_SA,S_ISA,text_order_sa_sampling > >;CSA-SADA
FM_HUFF_RRR63;csa_wt >,S_SA,S_ISA,text_order_sa_sampling > >;FM-HF-R$^3$63
�����������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/indexes/��������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022125�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/indexes/.gitignore����������������������������������������0000664�0000000�0000000�00000000040�12412610011�0024107�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/info/�����������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021421�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/info/.gitignore�������������������������������������������0000664�0000000�0000000�00000000040�12412610011�0023403�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!HP
!NOSSE
!NOOPT
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/pattern/��������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022143�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/pattern/.gitignore����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024130�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/results/��������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022167�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/results/.gitignore����������������������������������������0000664�0000000�0000000�00000000016�12412610011�0024154�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/sample.config���������������������������������������������0000664�0000000�0000000�00000000633�12412610011�0023140�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Specify the sample rate for suffix array (SA) and inverse suffix array (ISA).
# You can use the constants SA_MAX and ISA_MAX for the maximal sparse sampling
# for SA and ISA.
# Each sampling pair is specified by a triple: SAMPLING_ID;SA_SAMPLE_RATE;ISA_SAMPLE_RATE
# SAMPLING_ID should consist only of symbols in A-Z,a-z,0-9
4x4;4;4
8x8;8;8
16x16;16;16
32x32;32;32
64x64;64;64
128x128;128;128
256x256;256;256
�����������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/src/������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0021255�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/src/build_index_sdsl.cpp����������������������������������0000664�0000000�0000000�00000001131�12412610011�0025270�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include
#include
using namespace sdsl;
using namespace std;
int main(int argc, char** argv)
{
if (argc < 4) {
cout << "Usage ./" << argv[0] << " input_file tmp_dir output_file" << endl;
return 0;
}
CSA_TYPE csa;
if (argc < 3) {
construct(csa, argv[1], 1);
} else {
// config: do not delete files, tmp_dir=argv[2], id=basename(argv[1])
cache_config cconfig(false, argv[2], util::basename(argv[1]));
construct(csa, argv[1], cconfig, 1);
}
store_to_file(csa, argv[3]);
}
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/src/info.cpp����������������������������������������������0000664�0000000�0000000�00000000635�12412610011�0022720�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* This program outputs the structure of an index.
*/
#include
#include
#include
using namespace sdsl;
using namespace std;
int main(int argc, char* argv[])
{
if (argc < 2) {
cout << "./" << argv[0] << " index_file " << endl;
return 1;
}
CSA_TYPE csa;
load_from_file(csa, argv[1]);
write_structure(csa, cout);
}
���������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/src/interface.h�������������������������������������������0000664�0000000�0000000�00000006275�12412610011�0023400�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
/* General interface for using the compressed index libraries */
#ifndef uchar
#define uchar unsigned char
#endif
#ifndef uint
#define uint unsigned int
#endif
#ifndef ulong
#define ulong unsigned long
#endif
/* Error management */
/* Returns a string describing the error associated with error number
e. The string must not be freed, and it will be overwritten with
subsequent calls. */
char* error_index(int e);
/* Building the index */
/* Creates index from text[0..length-1]. Note that the index is an
opaque data type. Any build option must be passed in string
build_options, whose syntax depends on the index. The index must
always work with some default parameters if build_options is NULL.
The returned index is ready to be queried. */
int build_index(uchar* text, ulong length, char* build_options, void** index);
/* Saves index on disk by using single or multiple files, having
proper extensions. */
int save_index(void* index, char* filename);
/* Loads index from one or more file(s) named filename, possibly
adding the proper extensions. */
int load_index(char* filename, void** index);
/* Frees the memory occupied by index. */
int free_index(void* index);
/* Gives the memory occupied by index in bytes. */
int index_size(void* index, ulong* size);
/* Querying the index */
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] found in the text indexed by index. */
int count(void* index, uchar* pattern, ulong length, ulong* numocc);
/* Writes in numocc the number of occurrences of the substring
pattern[0..length-1] in the text indexed by index. It also allocates
occ (which must be freed by the caller) and writes the locations of
the numocc occurrences in occ, in arbitrary order. */
int locate(void* index, uchar* pattern, ulong length, ulong** occ,
ulong* numocc);
/* Gives the length of the text indexed */
int get_length(void* index, ulong* length);
/* Accessing the indexed text */
/* Allocates snippet (which must be freed by the caller) and writes
the substring text[from..to] into it. Returns in snippet_length the
length of the text snippet actually extracted (that could be less
than to-from+1 if to is larger than the text size). */
int extract(void* index, ulong from, ulong to, uchar** snippet,
ulong* snippet_length);
/* Displays the text (snippet) surrounding any occurrence of the
substring pattern[0..length-1] within the text indexed by index.
The snippet must include numc characters before and after the
pattern occurrence, totalizing length+2*numc characters, or less if
the text boundaries are reached. Writes in numocc the number of
occurrences, and allocates the arrays snippet_text and
snippet_lengths (which must be freed by the caller). The first is a
character array of numocc*(length+2*numc) characters, with a new
snippet starting at every multiple of length+2*numc. The second
gives the real length of each of the numocc snippets. */
int display(void* index, uchar* pattern, ulong length, ulong numc,
ulong* numocc, uchar** snippet_text, ulong** snippet_lengths);
/* Obtains the length of the text indexed by index. */
int length(void* index, ulong* length);
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/src/pattern_random.cpp������������������������������������0000664�0000000�0000000�00000004134�12412610011�0025000�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include
#include
#include
using namespace sdsl;
using namespace std;
uint64_t my_rand64()
{
int_vector<> v(1);
util::set_random_bits(v);
return v[0];
}
int main(int argc, char** argv)
{
if (argc < 7) {
printf("Usage ./%s input_file tmp_dir pat_len min_cum_occ pat_file occ_file\n",argv[0]);
printf(" (1) Build an index for the text T stored in input_file.\n");
printf(" Temporary files are stored in tmp_dir.\n");
printf(" (2) Set cum_occ=0\n");
printf(" (3) Select a random position in T and extracts a pattern P\n");
printf(" of length pat_len from this position.\n");
printf(" (3) Get x, the number of occurrences of P in T.\n");
printf(" (4) cum_occ+=x; if cum_occ>=min_cum_occ exit program.\n");
printf(" Otherwise go to step (3).");
printf(" (5) Write pattern in Pizza&Chili format into pat_file.");
printf(" (6) Write #occurrences in into occ_file.");
return 1;
}
uint64_t min_cum_occ = atoll(argv[4]);
uint64_t pat_len = atoll(argv[3]);
assert(pat_len > 0);
vector pattern;
string file = util::basename(argv[1]);
ofstream out(argv[5]);
ofstream occ_out(argv[6]);
//(1)
csa_wt<> csa;
cache_config cconfig(false, argv[2], file);
construct(csa, argv[1], cconfig, 1);
if (pat_len>=csa.size()) {
std::cout << "pat_len=" << pat_len << " too long." << std::endl;
return 1;
}
// (2)
uint64_t cum_sum = 0;
uint64_t number = 0;
do {
// (3)
uint64_t start_idx = my_rand64()%(csa.size()-pat_len);
auto pat = extract(csa, start_idx, start_idx+pat_len-1);
pattern.push_back(pat);
// (4)
uint64_t x = count(csa, pat.begin(), pat.end());
occ_out<
#include
#include
/* only for getTime() */
#include
#include
#define COUNT ('C')
#define LOCATE ('L')
#define EXTRACT ('E')
#define DISPLAY ('D')
#define VERBOSE ('V')
using namespace sdsl;
using namespace std;
/* local headers */
void do_count(const CSA_TYPE&);
void do_locate(const CSA_TYPE&);
void do_extract(const CSA_TYPE&);
//void do_display(ulong length);
void pfile_info(ulong* length, ulong* numpatt);
//void output_char(uchar c, FILE * where);
double getTime(void);
void usage(char* progname);
static int Verbose = 0;
static ulong Index_size, Text_length;
static double Load_time;
/*
* Temporary usage: run_queries [length] [V]
*/
int main(int argc, char* argv[])
{
char* filename;
char querytype;
if (argc < 2) {
usage(argv[0]);
exit(1);
}
filename = argv[1];
querytype = *argv[2];
CSA_TYPE csa;
fprintf(stderr, "Load from file %s\n",(string(filename) + "." + string(SDSL_XSTR(SUF))).c_str());
Load_time = getTime();
load_from_file(csa, (string(argv[1]) + "." + string(SDSL_XSTR(SUF))).c_str());
Load_time = getTime() - Load_time;
fprintf(stderr, "# Load_index_time_in_sec = %.2f\n", Load_time);
std::cerr<<"# text_size = " << csa.size()-1 << std::endl;
Index_size = size_in_bytes(csa);
Text_length = csa.size()-1; // -1 since we added a sentinel character
/* Index_size /=1024; */
fprintf(stderr, "# Index_size_in_bytes = %lu\n", Index_size);
#ifdef USE_HP
bool mapped = mm::map_hp();
fprintf(stderr, "# hugepages = %i\n", (int)mapped);
#endif
switch (querytype) {
case COUNT:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", COUNT);
}
do_count(csa);
break;
case LOCATE:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", LOCATE);
}
do_locate(csa);
break;
case EXTRACT:
if (argc > 3)
if (*argv[3] == VERBOSE) {
Verbose = 1;
fprintf(stdout,"%c", EXTRACT);
}
do_extract(csa);
break;
default:
fprintf(stderr, "Unknow option: main ru\n");
exit(1);
}
#ifdef USE_HP
if (mapped) {
mm::unmap_hp();
}
#endif
return 0;
}
void
do_count(const CSA_TYPE& csa)
{
ulong numocc, length, tot_numocc = 0, numpatt, res_patt;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
res_patt = numpatt;
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
while (res_patt) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
perror("run_queries");
exit(1);
}
/* Count */
time = getTime();
numocc = count(csa, pattern, pattern+length);
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
tot_time += (getTime() - time);
tot_numocc += numocc;
res_patt--;
}
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Count_time_in_milli_sec = %.4f\n", tot_time*1000);
fprintf(stderr, "# Count_time/Pattern_chars = %.4f\n",
(tot_time * 1000) / (length * numpatt));
fprintf(stderr, "# Count_time/Num_patterns = %.4f\n\n",
(tot_time * 1000) / numpatt);
fprintf(stderr, "# (Load_time+Count_time)/Pattern_chars = %.4f\n",
((Load_time+tot_time) * 1000) / (length * numpatt));
fprintf(stderr, "# (Load_time+Count_time)/Num_patterns = %.4f\n\n",
((Load_time+tot_time) * 1000) / numpatt);
free(pattern);
}
void
do_locate(const CSA_TYPE& csa)
{
ulong numocc, length;
ulong tot_numocc = 0, numpatt = 0, processed_pat = 0;
double time, tot_time = 0;
uchar* pattern;
pfile_info(&length, &numpatt);
pattern = (uchar*) malloc(sizeof(uchar) * (length));
if (pattern == NULL) {
fprintf(stderr, "Error: cannot allocate\n");
exit(1);
}
/*SG: added timeout of 60 seconds */
while (numpatt and tot_time < 60.0) {
if (fread(pattern, sizeof(*pattern), length, stdin) != length) {
fprintf(stderr, "Error: cannot read patterns file\n");
perror("run_queries");
exit(1);
}
// Locate
time = getTime();
auto occs = locate(csa, (char*)pattern, (char*)pattern+length);
numocc = occs.size();
tot_time += (getTime() - time);
++processed_pat;
tot_numocc += numocc;
numpatt--;
if (Verbose) {
fwrite(&length, sizeof(length), 1, stdout);
fwrite(pattern, sizeof(*pattern), length, stdout);
fwrite(&numocc, sizeof(numocc), 1, stdout);
}
}
fprintf(stderr, "# processed_pattern = %lu\n", processed_pat);
fprintf(stderr, "# Total_Num_occs_found = %lu\n", tot_numocc);
fprintf(stderr, "# Locate_time_in_secs = %.2f\n", tot_time);
fprintf(stderr, "# Locate_time/Num_occs = %.4f\n\n", (tot_time * 1000) / tot_numocc);
fprintf(stderr, "# (Load_time+Locate_time)/Num_occs = %.4f\n\n", ((tot_time+Load_time) * 1000) / tot_numocc);
free(pattern);
}
/* Open patterns file and read header */
void
pfile_info(ulong* length, ulong* numpatt)
{
int error;
uchar c;
uchar origfilename[257];
error = fscanf(stdin, "# number=%lu length=%lu file=%s forbidden=", numpatt,
length, origfilename);
if (error != 3) {
fprintf(stderr, "Error: Patterns file header not correct\n");
perror("run_queries");
exit(1);
}
fprintf(stderr, "# pat_cnt = %lu\n", *numpatt);
fprintf(stderr, "# pat_length = %lu\n", *length);
fprintf(stderr, "# forbidden_chars = ");
while ((c = fgetc(stdin)) != 0) {
if (c == '\n') break;
fprintf(stderr, "%d",c);
}
fprintf(stderr, "\n");
}
void
do_extract(const CSA_TYPE& csa)
{
int error = 0;
uchar* text, orig_file[257];
ulong num_pos, from, to, numchars, tot_ext = 0;
CSA_TYPE::size_type readlen = 0;
double time, tot_time = 0;
error = fscanf(stdin, "# number=%lu length=%lu file=%s\n", &num_pos, &numchars, orig_file);
if (error != 3) {
fprintf(stderr, "Error: Intervals file header is not correct\n");
perror("run_queries");
exit(1);
}
fprintf(stderr, "# number=%lu length=%lu file=%s\n", num_pos, numchars, orig_file);
while (num_pos) {
if (fscanf(stdin,"%lu,%lu\n", &from, &to) != 2) {
fprintf(stderr, "Cannot read correctly intervals file\n");
exit(1);
}
time = getTime();
text = (uchar*)malloc(to-from+2);
readlen += extract(csa, from, to, text);
tot_time += (getTime() - time);
tot_ext += readlen;
if (Verbose) {
fwrite(&from,sizeof(ulong),1,stdout);
fwrite(&readlen,sizeof(ulong),1,stdout);
fwrite(text,sizeof(uchar),readlen, stdout);
}
num_pos--;
free(text);
}
fprintf(stderr, "# Total_num_chars_extracted = %lu\n", tot_ext);
fprintf(stderr, "# Extract_time_in_sec = %.2f\n", tot_time);
fprintf(stderr, "# Extract_time/Num_chars_extracted = %.4f\n\n",
(tot_time * 1000) / tot_ext);
fprintf(stderr, "(Load_time+Extract_time)/Num_chars_extracted = %.4f\n\n",
((Load_time+tot_time) * 1000) / tot_ext);
}
double
getTime(void)
{
double usertime, systime;
struct rusage usage;
getrusage(RUSAGE_SELF, &usage);
usertime = (double) usage.ru_utime.tv_sec +
(double) usage.ru_utime.tv_usec / 1000000.0;
systime = (double) usage.ru_stime.tv_sec +
(double) usage.ru_stime.tv_usec / 1000000.0;
return (usertime + systime);
}
void usage(char* progname)
{
fprintf(stderr, "\nThe program loads and then executes over it the\n");
fprintf(stderr, "queries it receives from the standard input. The standard\n");
fprintf(stderr, "input comes in the format of the files written by \n");
fprintf(stderr, "genpatterns or genintervals.\n");
fprintf(stderr, "%s reports on the standard error time statistics\n", progname);
fprintf(stderr, "regarding to running the queries.\n\n");
fprintf(stderr, "Usage: %s [length] [V]\n", progname);
fprintf(stderr, "\n\t denotes the type of queries:\n");
fprintf(stderr, "\t %c counting queries;\n", COUNT);
fprintf(stderr, "\t %c locating queries;\n", LOCATE);
fprintf(stderr, "\t %c displaying queries;\n", DISPLAY);
fprintf(stderr, "\t %c extracting queries.\n\n", EXTRACT);
fprintf(stderr, "\n\t[length] must be provided in case of displaying queries (D)\n");
fprintf(stderr, "\t and denotes the number of characters to display\n");
fprintf(stderr, "\t before and after each pattern occurrence.\n");
fprintf(stderr, "\n\t[V] with this options it reports on the standard output\n");
fprintf(stderr, "\t the results of the queries. The results file should be\n");
fprintf(stderr, "\t compared with trusted one by compare program.\n\n");
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/test_case.config������������������������������������������0000664�0000000�0000000�00000001270�12412610011�0023627�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Configuration for test files
# (1) Identifier for test file (consisting of letters, no `.`)
# (2) Path to the test file
# (3) LaTeX name
# (4) Download link (if the test is available online)
ENGLISH;../data/english.200MB;english.200MB;http://pizzachili.di.unipi.it/texts/nlang/english.200MB.gz
DBLPXML;../data/dblp.xml.200MB;dblp.xml.200MB;http://pizzachili.di.unipi.it/texts/xml/dblp.xml.200MB.gz
DNA;../data/dna.200MB;dna.200MB;http://pizzachili.di.unipi.it/texts/dna/dna.200MB.gz
PROTEINS;../data/proteins.200MB;proteins.200MB;http://pizzachili.di.unipi.it/texts/protein/proteins.200MB.gz
SOURCES;../data/sources.200MB;sources.200MB;http://pizzachili.di.unipi.it/texts/code/sources.200MB.gz
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0022501�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/.gitignore��������������������������������������0000664�0000000�0000000�00000000103�12412610011�0024463�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
!Makefile
!index-filter.config
!locate.R
!locate.tex
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/Makefile����������������������������������������0000664�0000000�0000000�00000001072�12412610011�0024141�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../../Make.helper
CONFIG_FILES=index-filter.config ../index.config ../test_case.config ../sample.config
all: locate.pdf
locate.pdf: locate.tex tbl-locate.tex fig-locate.tex
@echo "Use pdflatex to generate locate.pdf"
@pdflatex locate.tex >> LaTeX.Log 2>&1
tbl-locate.tex fig-locate.tex: ../../basic_functions.R locate.R $(CONFIG_FILES) ../results/all.txt
@echo "Use R to generate tbl-locate.tex and fig-locate.tex"
@R --vanilla < locate.R > R.log 2>&1
clean:
rm -f locate.pdf locate.aux fig-locate.tex tbl-locate.tex \
locate.log R.log LaTeX.log
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/index-filter.config�����������������������������0000664�0000000�0000000�00000001001�12412610011�0026252�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Use this file to specify which indexes are listed in the report locate.pdf
# and how they look like in the report.
#
# List all the index ids which should be included in the report. Note that
# the listed index ids must also be present in the file `../index.config`.
# Eeach INDEX_ID should be listed on a separate line followed by the style:
# [pch];[lty];[col] (point type, line type, and color).
FM_HUFF; 1;solid;black
FM_HUFF_RRR15; 2;solid;blue
CSA_SADA; 3;solid;red
FM_HUFF_RRR63; 4;solid;blue
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/locate.R����������������������������������������0000664�0000000�0000000�00000005520�12412610011�0024075�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������require(tikzDevice)
source("../../basic_functions.R")
# Load filter information
config <- readConfig("index-filter.config",c("IDX_ID","PCH","LTY","COL"))
idx_config <- readConfig("../index.config",c("IDX_ID","SDSL_TYPE","LATEX-NAME"))
tc_config <- readConfig("../test_case.config",c("TC_ID","PATH","LATEX-NAME","URL"))
# Load data
raw <- data_frame_from_key_value_pairs( "../results/all.txt" )
# Filter indexes
raw <- raw[raw[["IDX_ID"]]%in%config[["IDX_ID"]],]
raw[["IDX_ID"]] <- factor(raw[["IDX_ID"]])
# Normalize data
raw[["Time"]] <- 1000000*raw[["Locate_time_in_secs"]]/raw[["Total_Num_occs_found"]]
raw[["Space"]] <- 100*raw[["Index_size_in_bytes"]]/raw[["text_size"]]
raw <- raw[c("TC_ID", "Space", "Time","IDX_ID","S_SA","S_ISA")]
raw <- raw[order(raw[["TC_ID"]]),]
data <- split(raw, raw[["TC_ID"]])
tikz("fig-locate.tex", width = 5.5, height = 6, standAlone = F)
multi_figure_style( length(data)/2+1, 2 )
max_space <- 100*2.5 #1.3 # 2.5 #1.8
max_time <- 25 # in microseconds
count <- 0
nr <- 0
xlabnr <- (2*(length(data)/2)-1)
for( tc_id in names(data) ){
d <- data[[tc_id]]
plot(c(),c(),xlim=c(0, max_space), ylim=c(0, max_time), xlab="", axes=F, xaxt="n", yaxt="n", ylab="" )
box(col="gray")
grid(lty="solid")
if ( nr %% 2 == 0 ){
ylable <- "Time per occurrence ($\\mu s$)"
axis( 2, at = axTicks(2) )
mtext(ylable, side=2, line=2, las=0)
}
axis( 1, at = axTicks(1), labels=(nr>=xlabnr) )
if ( nr >= xlabnr ){
xlable <- "Index size in (\\%)"
mtext(xlable, side=1, line=2, las=0)
}
dd <- split(d, d[["IDX_ID"]])
for( idx_id in names(dd) ){
ddd <- dd[[idx_id]]
lines(ddd[["Space"]], ddd[["Time"]], type="b", lwd=1, pch=config[idx_id, "PCH"],
lty=config[idx_id, "LTY"],
col=config[idx_id, "COL"]
)
}
draw_figure_heading( sprintf("instance = \\textsc{%s}",tc_config[tc_id,"LATEX-NAME"]) )
comp_info <- readConfig(paste("../",tc_config[tc_id,"PATH"],".z.info",sep=""),c("NAME","RATIO","COMMAND"))
abline(v=comp_info["xz","RATIO"],lty=1);
abline(v=comp_info["gzip","RATIO"],lty=4);
nr <- nr+1
if ( nr == 1 ){ # plot legend
plot(NA, NA, xlim=c(0,1),ylim=c(0,1),ylab="", xlab="", bty="n", type="n", yaxt="n", xaxt="n")
idx_ids <- as.character(unique(raw[["IDX_ID"]]))
legend( "top", legend=idx_config[idx_ids,"LATEX-NAME"], pch=config[idx_ids,"PCH"], col=config[idx_ids,"COL"],
lty=config[idx_ids,"LTY"], bty="n", y.intersp=1.5, ncol=2, title="Index", cex=1.2)
legend( "bottom", legend=c("\\textsc{xz}~(\\texttt{-9})","\\textsc{gzip}~(\\texttt{-9})"),
lty=c(1,4), bty="n", y.intersp=1.5, ncol=2, title="Compression baseline", cex=1.2)
nr <- nr+1
}
}
dev.off()
sink("tbl-locate.tex")
cat(typeInfoTable("../index.config", config[["IDX_ID"]], 1, 3, 2))
sink(NULL)
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/indexing_locate/visualize/locate.tex��������������������������������������0000664�0000000�0000000�00000000773�12412610011�0024501�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������\documentclass[9pt,a4paper]{scrartcl}
\usepackage{array}
\usepackage{booktabs}
\usepackage{ragged2e}
\usepackage{tikz}
\begin{document}
\pagestyle{empty}
\begin{figure}
\input{fig-locate.tex}
\caption{Time-space trade-offs for operation locate.}
\end{figure}
\begin{table}
\centering
\input{tbl-locate.tex}
\caption{Class definition of the indexes used in the experiment.
The sampling rates \texttt{S\_SA} and \texttt{S\_ISA} for
suffix and inverse suffix values was varied.}
\end{table}
\end{document}
�����sdsl-lite-2.0.3/benchmark/lcp/����������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0016110�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/.gitignore������������������������������������������������������������0000664�0000000�0000000�00000000173�12412610011�0020101�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
!lcp.config
!README.md
!bin/
!src/
!visualize/
!compile_options.config
!Makefile
!results/
!test_case.config
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/Makefile��������������������������������������������������������������0000664�0000000�0000000�00000004056�12412610011�0017555�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������include ../../Make.helper
CFLAGS = $(MY_CXX_FLAGS)
SRC_DIR = src
BIN_DIR = bin
LIBS = -lsdsl -ldivsufsort -ldivsufsort64
C_OPTIONS:=$(call config_ids,compile_options.config)
TC_IDS:=$(call config_ids,test_case.config)
LCP_IDS:=$(call config_ids,lcp.config)
DL = ${foreach TC_ID,$(TC_IDS),$(call config_select,test_case.config,$(TC_ID),2)}
LCP_EXECS = $(foreach LCP_ID,$(LCP_IDS),$(BIN_DIR)/build_$(LCP_ID))
RES_FILES = $(foreach TC_ID,$(TC_IDS),\
results/$(TC_ID))
RESULT_FILE=results/all.txt
execs: $(BIN_DIR)/prep_sa_bwt $(LCP_EXECS)
timing: execs $(RES_FILES)
@cat $(RES_FILES) > $(RESULT_FILE)
@cd visualize;make
$(BIN_DIR)/prep_sa_bwt: $(SRC_DIR)/create_sa_bwt.cpp
@echo "Compiling prep_sa_bwt"
@$(MY_CXX) $(CFLAGS) $(C_OPTIONS) -L${LIB_DIR}\
$(SRC_DIR)/create_sa_bwt.cpp -I${INC_DIR} -o bin/prep_sa_bwt $(LIBS)
precalc%: test_case.config $(DL) lcp.config
$(eval TC_ID:=$(call dim,1,$*))
$(eval LCP_TEX_NAME:=$(call config_select,lcp.config,$(LCP_ID),3))
$(eval TC_TEX_NAME:=$(call config_select,test_case.config,$(TC_ID),3))
$(eval TC_PATH:=$(call config_select,test_case.config,$(TC_ID),2))
$(eval TC_SIZE:=$(shell wc -c <$(TC_PATH)))
@echo "Running test case: $(TC_ID)"
@echo "# TC_ID = $(TC_ID)" > results/$(TC_ID)
@echo "# TC_TEX_NAME = $(TC_TEX_NAME)">> results/$(TC_ID)
@echo "# TC_SIZE = $(TC_SIZE)">> results/$(TC_ID)
@$(BIN_DIR)/prep_sa_bwt $(TC_PATH) >> results/$(TC_ID)
results/%: precalc%
@$(foreach LCP_EXEC,$(LCP_EXECS),$(shell $(LCP_EXEC) >>$@;rm -f lcp_tmp.sdsl isa_tmp.sdsl))
@rm *.sdsl
$(BIN_DIR)/build_%: $(SRC_DIR)/create_lcp.cpp lcp.config
$(eval LCP_ID:=$(call dim,1,$*))
$(eval LCP_TYPE:=$(call config_select,lcp.config,$(LCP_ID),2))
@echo "Compiling build_$*"
@$(MY_CXX) $(CFLAGS) $(C_OPTIONS) -DLCP_TYPE="$(LCP_TYPE)" -DLCPID="$(LCP_ID)" -L${LIB_DIR}\
$(SRC_DIR)/create_lcp.cpp -I${INC_DIR} -o $@ $(LIBS)
include ../Make.download
clean-build:
@echo "Remove executables"
rm -f $(BIN_DIR)/build*
rm -f $(BIN_DIR)/prep*
clean-result:
@echo "Remove results"
rm -f results/*
cleanall: clean-build clean-result
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/README.md�������������������������������������������������������������0000664�0000000�0000000�00000003656�12412610011�0017401�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Benchmarking LCP algorithms
## Methodology
Explored dimensions:
* lcp algorithms
* test cases
## Directory structure
* [bin](./bin): Contains the executables of the project.
* [results](./results): Contains the results of the experiments.
* [src](./src): Contains the source code of the benchmark.
* [visualize](./visualize): Contains a `R`-script which generates
a report in LaTeX format.
## Prerequisites
* For the visualization you need the following software:
- [R][RPJ] with package `xtable`. You can install the
package by calling `install.packages("xtable")` in R.
- [pdflatex][LT] to generate the pdf reports.
## Usage
* `make timing` compiles the programs, downloads
the test instances, builds the LCP arrays and generates a report located at
`visualize/lcp.pdf`. The raw numbers of the timings
can be found in the `results/all.txt`. The execution of the
default benchmark took 66 minutes on my machine (MacBookPro Retina
2.6GHz Intel Core i7, 16GB 1600 Mhz DDR3, SSD).
Have a look at the [generated report][RES].
* All created binaries and test results can be deleted
by calling `make cleanall`.
## Customization of the benchmark
The project contains several configuration files:
* [wt.config][LCPCONFIG]: Specify different LCP algorithms.
* [test_case.config][TCCONF]: Specify test instances by ID, path, LaTeX-name
for the report, and download URL.
* [compile_options.config][CCONF]: Specify compile options by option string.
Note that the benchmark will execute every combination of lcp algorithms and test cases.
[RPJ]: http://www.r-project.org/ "R"
[LT]: http://www.tug.org/applications/pdftex/ "pdflatex"
[LCPCONFIG]: ./lcp.config "lcp.config"
[TCCONF]: ./test_case.config "test_case.config"
[CCONF]: ./compile_options.config "compile_options.config"
[RES]: https://github.com/simongog/simongog.github.com/raw/master/assets/images/lcp.pdf "lcp.pdf"
����������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/bin/������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0016660�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/bin/.gitignore��������������������������������������������������������0000664�0000000�0000000�00000000016�12412610011�0020645�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/compile_options.config������������������������������������������������0000664�0000000�0000000�00000000117�12412610011�0022501�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Compile options
-O3 -funroll-loops -fomit-frame-pointer -ffast-math -DNDEBUG
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/lcp.config������������������������������������������������������������0000664�0000000�0000000�00000001415�12412610011�0020056�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# This file specifies wavelettrees that are used in the benchmark.
#
# Each LCP algorithm is specified by a 4-tupel: LCP_ID;LCP_ALGORITHM;LCP_LATEX_NAME;BWT_NEEDED
# * LCP_ID : An identifier for the index. Only letters and underscores are allowed in ID.
# * LCP_ALGORITHM : Corresponding lcp alogrithm.
# * LCP_LATEX_NAME: LaTeX name for output in the benchmark report.
# * BWT_NEEDED : T(rue) if lcp algorithm needs bwt as input, otherwise F(alse).
kasai;construct_lcp_kasai<8>;lcp-kasai;F
phi_algorithm;construct_lcp_PHI<8>;lcp-$\Phi$;F
semi_extern_phi;construct_lcp_semi_extern_PHI;lcp-semi-extern-$\Phi$;F
go;construct_lcp_go;lcp-go;T
goPhi;construct_lcp_goPHI;lcp-go-$\Phi$;T
bwtb;construct_lcp_bwt_based;lcp-bwt-based;T
bwtb2;construct_lcp_bwt_based2;lcp-bwt-based2;T
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/results/��������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0017611�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/results/.gitignore����������������������������������������������������0000664�0000000�0000000�00000000016�12412610011�0021576�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/src/������������������������������������������������������������������0000775�0000000�0000000�00000000000�12412610011�0016677�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/src/.gitignore��������������������������������������������������������0000664�0000000�0000000�00000000061�12412610011�0020664�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*
!.gitignore
!create_lcp.cpp
!create_sa_bwt.cpp
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sdsl-lite-2.0.3/benchmark/lcp/src/create_lcp.cpp����������������������������������������������������0000664�0000000�0000000�00000001576�12412610011�0021515�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#include
#include