pax_global_header�����������������������������������������������������������������������������������0000666�0000000�0000000�00000000064�12556365562�0014531�g����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������52 comment=831e9c5e41f79885f89d88a012fe44c28301d750
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/���������������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12556365562�0013015�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/.gitignore�����������������������������������������������������������������������������0000664�0000000�0000000�00000000110�12556365562�0014775�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������*.pyc
#*#
.*~
*~
Thumbs.db
.DS_Store
tags
build/
dist/
percol.egg-info/
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/README.md������������������������������������������������������������������������������0000664�0000000�0000000�00000032605�12556365562�0014302�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# percol
__
____ ___ ______________ / /
/ __ \/ _ \/ ___/ ___/ __ \/ /
/ /_/ / __/ / / /__/ /_/ / /
/ .___/\___/_/ \___/\____/_/
/_/
percol adds flavor of interactive selection to the traditional pipe concept on UNIX.
- [What's this](#whats-this)
- [Features](#features)
- [Related projects](#related-projects)
- [Installation](#installation)
- [PyPI](#pypi)
- [Manual](#manual)
- [Usage](#usage)
- [Example](#example)
- [Interactive pgrep / pkill](#interactive-pgrep--pkill)
- [zsh history search](#zsh-history-search)
- [tmux](#tmux)
- [Configuration](#configuration)
- [Customizing prompt](#customizing-prompt)
- [Dynamic prompt](#dynamic-prompt)
- [Custom format specifiers](#custom-format-specifiers)
- [Customizing styles](#customizing-styles)
- [Foreground Colors](#foreground-colors)
- [Background Color](#background-color)
- [Attributes](#attributes)
- [Matching Method](#matching-method)
- [Migemo support](#migemo-support)
- [Dictionary settings](#dictionary-settings)
- [Minimum query length](#minimum-query-length)
- [Pinyin support](#pinyin-support)
- [Switching matching method dynamically](#switching-matching-method-dynamically)
- [Tips](#tips)
- [Selecting multiple candidates](#selecting-multiple-candidates)
- [Z Shell support](#z-shell-support)
## What's this
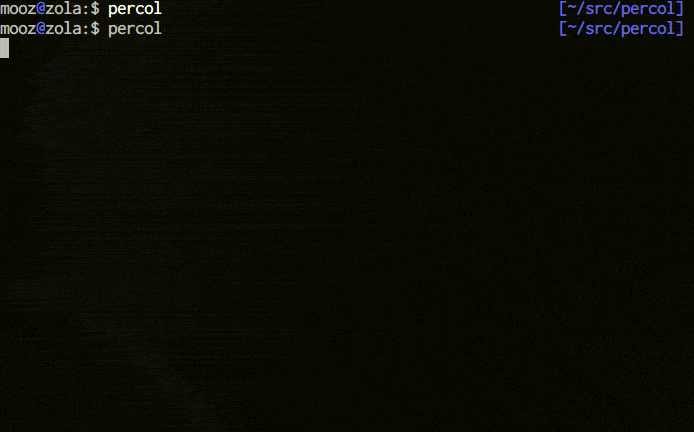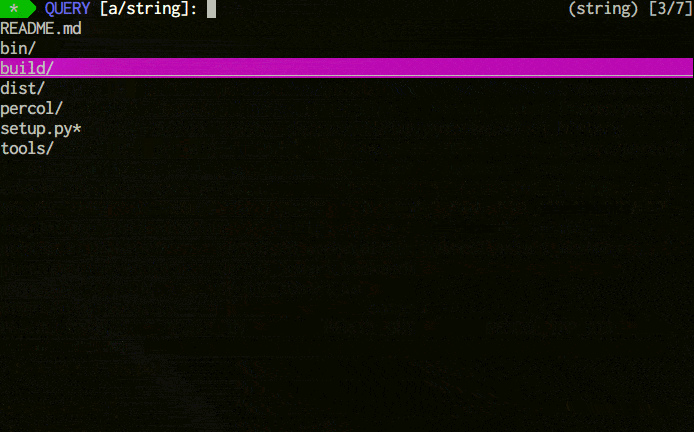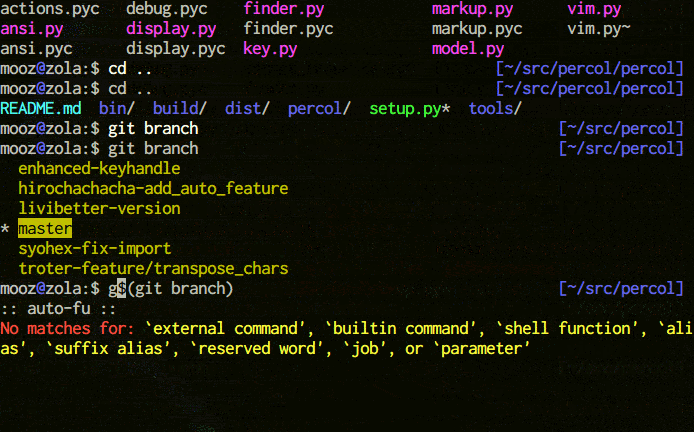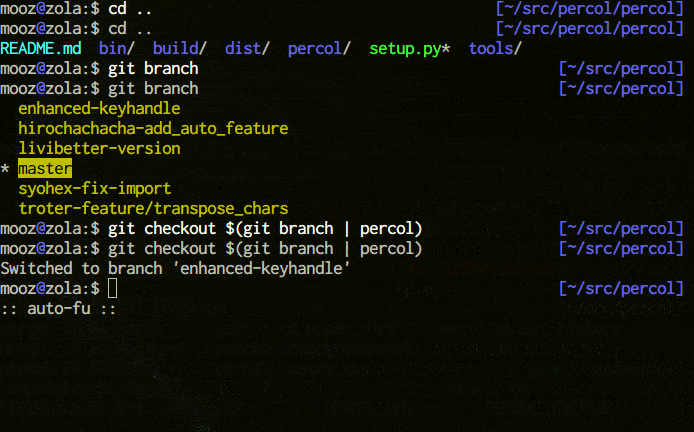
percol is an **interactive grep tool** in your terminal. percol
1. receives input lines from `stdin` or a file,
2. lists up the input lines,
3. waits for your input that filter/select the line(s),
4. and finally outputs the selected line(s) to `stdout`.
Since percol just filters the input and output the result to stdout,
it can be used in command-chains with `|` in your shell (**UNIX philosophy!**).
### Features
- **Efficient**: With **lazy loads** of input lines and **query caching**, percol handles huge inputs efficiently.
- **Customizable**: Through configuration file (`rc.py`), percol's behavior including prompts, keymaps, and color schemes can be **heavily customizable**.
- See [configuration](https://github.com/mooz/percol#configuration) for details.
- **Migemo support**: By supporting [C/Migemo](http://code.google.com/p/cmigemo/), **percol filters Japanese inputs blazingly fast**.
- See [matching method](https://github.com/mooz/percol#matching-method) for details.
### Related projects
- [canything by @keiji0](https://github.com/keiji0/canything)
- A seminal work in interactive grep tools.
- [zaw by @nakamuray](https://github.com/zsh-users/zaw)
- A zsh-friendly interactive grep tool.
- [peco by @lestrrat](https://github.com/lestrrat/peco)
- An interactive grep tool written in Go language.
- [fzf by @junegunn](https://github.com/junegunn/fzf)
- An interactive grep tool written in Go language.
## Installation
percol currently supports only Python 2.x.
### PyPI
$ sudo pip install percol
### Manual
First, clone percol repository and go into the directory.
$ git clone git://github.com/mooz/percol.git
$ cd percol
Then, run a command below.
$ sudo python setup.py install
If you don't have a root permission (or don't wanna install percol with sudo), try next one.
$ python setup.py install --prefix=~/.local
$ export PATH=~/.local/bin:$PATH
## Usage
Specifying a filename.
$ percol /var/log/syslog
Specifying a redirection.
$ ps aux | percol
## Example
### Interactive pgrep / pkill
Here is an interactive version of pgrep,
$ ps aux | percol | awk '{ print $2 }'
and here is an interactive version of pkill.
$ ps aux | percol | awk '{ print $2 }' | xargs kill
For zsh users, command versions are here (`ppkill` accepts options like `-9`).
```sh
function ppgrep() {
if [[ $1 == "" ]]; then
PERCOL=percol
else
PERCOL="percol --query $1"
fi
ps aux | eval $PERCOL | awk '{ print $2 }'
}
function ppkill() {
if [[ $1 =~ "^-" ]]; then
QUERY="" # options only
else
QUERY=$1 # with a query
[[ $# > 0 ]] && shift
fi
ppgrep $QUERY | xargs kill $*
}
```
### zsh history search
In your `.zshrc`, put the lines below.
```sh
function exists { which $1 &> /dev/null }
if exists percol; then
function percol_select_history() {
local tac
exists gtac && tac="gtac" || { exists tac && tac="tac" || { tac="tail -r" } }
BUFFER=$(fc -l -n 1 | eval $tac | percol --query "$LBUFFER")
CURSOR=$#BUFFER # move cursor
zle -R -c # refresh
}
zle -N percol_select_history
bindkey '^R' percol_select_history
fi
```
Then, you can display and search your zsh histories incrementally by pressing `Ctrl + r` key.
### tmux
Here are some examples of tmux and percol integration.
bind b split-window "tmux lsw | percol --initial-index $(tmux lsw | awk '/active.$/ {print NR-1}') | cut -d':' -f 1 | tr -d '\n' | xargs -0 tmux select-window -t"
bind B split-window "tmux ls | percol --initial-index $(tmux ls | awk \"/^$(tmux display-message -p '#{session_name}'):/ {print NR-1}\") | cut -d':' -f 1 | tr -d '\n' | xargs -0 tmux switch-client -t"
By putting above 2 settings into `tmux.conf`, you can select a tmux window with `${TMUX_PREFIX} b` keys and session with `${TMUX_PREFIX} B` keys.
Attaching to running tmux sessions can also be made easier with percol with this function(tested to work in bash and zsh)
```sh
function pattach() {
if [[ $1 == "" ]]; then
PERCOL=percol
else
PERCOL="percol --query $1"
fi
sessions=$(tmux ls)
[ $? -ne 0 ] && return
session=$(echo $sessions | eval $PERCOL | cut -d : -f 1)
if [[ -n "$session" ]]; then
tmux att -t $session
fi
}
```
## Configuration
Configuration file for percol should be placed under `${HOME}/.percol.d/` and named `rc.py`.
Here is an example `~/.percol.d/rc.py`.
```python
# X / _ / X
percol.view.PROMPT = ur"X / _ / X %q"
# Emacs like
percol.import_keymap({
"C-h" : lambda percol: percol.command.delete_backward_char(),
"C-d" : lambda percol: percol.command.delete_forward_char(),
"C-k" : lambda percol: percol.command.kill_end_of_line(),
"C-y" : lambda percol: percol.command.yank(),
"C-t" : lambda percol: percol.command.transpose_chars(),
"C-a" : lambda percol: percol.command.beginning_of_line(),
"C-e" : lambda percol: percol.command.end_of_line(),
"C-b" : lambda percol: percol.command.backward_char(),
"C-f" : lambda percol: percol.command.forward_char(),
"M-f" : lambda percol: percol.command.forward_word(),
"M-b" : lambda percol: percol.command.backward_word(),
"M-d" : lambda percol: percol.command.delete_forward_word(),
"M-h" : lambda percol: percol.command.delete_backward_word(),
"C-n" : lambda percol: percol.command.select_next(),
"C-p" : lambda percol: percol.command.select_previous(),
"C-v" : lambda percol: percol.command.select_next_page(),
"M-v" : lambda percol: percol.command.select_previous_page(),
"M-<" : lambda percol: percol.command.select_top(),
"M->" : lambda percol: percol.command.select_bottom(),
"C-m" : lambda percol: percol.finish(),
"C-j" : lambda percol: percol.finish(),
"C-g" : lambda percol: percol.cancel(),
})
```
### Customizing prompt
In percol, a prompt consists of two part: _PROMPT_ and _RPROMPT_, like zsh. As the following example shows, each part appearance can be customized by specifying a prompt format into `percol.view.PROMPT` and `percol.view.RPROMPT` respectively.
```python
percol.view.PROMPT = ur"Input: %q"
percol.view.RPROMPT = ur"(%F) [%i/%I]"
```
In prompt formats, a character preceded by `%` indicates a _prompt format specifier_ and is expanded into a corresponding system value.
- `%%`
- Display `%` itself
- `%q`
- Display query and caret
- `%Q`
- Display query without caret
- `%n`
- Page number
- `%N`
- Total page number
- `%i`
- Current line number
- `%I`
- Total line number
- `%c`
- Caret position
- `%k`
- Last input key
#### Dynamic prompt
By changing percol.view.PROMPT into a getter, percol prompts becomes more fancy.
```python
# Change prompt in response to the status of case sensitivity
percol.view.__class__.PROMPT = property(
lambda self:
ur"QUERY [a]: %q" if percol.model.finder.case_insensitive
else ur"QUERY [A]: %q"
)
```
#### Custom format specifiers
```python
# Display finder name in RPROMPT
percol.view.prompt_replacees["F"] = lambda self, **args: self.model.finder.get_name()
percol.view.RPROMPT = ur"(%F) [%i/%I]"
```
### Customizing styles
For now, styles of following 4 items can be customized in `rc.py`.
```python
percol.view.CANDIDATES_LINE_BASIC = ("on_default", "default")
percol.view.CANDIDATES_LINE_SELECTED = ("underline", "on_yellow", "white")
percol.view.CANDIDATES_LINE_MARKED = ("bold", "on_cyan", "black")
percol.view.CANDIDATES_LINE_QUERY = ("yellow", "bold")
```
Each RHS is a tuple of style specifiers listed below.
#### Foreground Colors
- `"black"` for `curses.COLOR_BLACK`
- `"red"` for `curses.COLOR_RED`
- `"green"` for `curses.COLOR_GREEN`
- `"yellow"` for `curses.COLOR_YELLOW`
- `"blue"` for `curses.COLOR_BLUE`
- `"magenta"` for `curses.COLOR_MAGENTA`
- `"cyan"` for `curses.COLOR_CYAN`
- `"white"` for `curses.COLOR_WHITE`
#### Background Color
- `"on_black"` for `curses.COLOR_BLACK`
- `"on_red"` for `curses.COLOR_RED`
- `"on_green"` for `curses.COLOR_GREEN`
- `"on_yellow"` for `curses.COLOR_YELLOW`
- `"on_blue"` for `curses.COLOR_BLUE`
- `"on_magenta"` for `curses.COLOR_MAGENTA`
- `"on_cyan"` for `curses.COLOR_CYAN`
- `"on_white"` for `curses.COLOR_WHITE`
#### Attributes
- `"altcharset"` for `curses.A_ALTCHARSET`
- `"blink"` for `curses.A_BLINK`
- `"bold"` for `curses.A_BOLD`
- `"dim"` for `curses.A_DIM`
- `"normal"` for `curses.A_NORMAL`
- `"standout"` for `curses.A_STANDOUT`
- `"underline"` for `curses.A_UNDERLINE`
- `"reverse"` for `curses.A_REVERSE`
## Matching Method
By default, percol interprets input queries by users as **string**. If you prefer **regular expression**, try `--match-method` command line option.
$ percol --match-method regex
### Migemo support
percol supports **migemo** (http://0xcc.net/migemo/) matching, which allows us to search Japanese documents with ASCII characters.
$ percol --match-method migemo
To use this feature, you need to install C/Migemo (https://github.com/koron/cmigemo). In Ubuntu, it's simple:
$ sudo apt-get install cmigemo
After that, by specifying a command line argument `--match-method migemo`, you can use migemo in percol.
NOTE: This feature uses `python-cmigemo` package (https://github.com/mooz/python-cmigemo). Doing `pip install percol` also installs this package too.
#### Dictionary settings
By default, percol assumes the path of a dictionary for migemo is `/usr/local/share/migemo/utf-8/migemo-dict`. If the dictionary is located in a different place, you should tell the location via `rc.py`.
For example, if the path of the dictionary is `/path/to/a/migemo-dict`, put lines below into your `rc.py`.
```python
from percol.finder import FinderMultiQueryMigemo
FinderMultiQueryMigemo.dictionary_path = "/path/to/a/migemo-dict"
```
#### Minimum query length
If the query length is **too short**, migemo generates **very long** regular expression. To deal with this problem, percol does not pass a query if the length of the query is shorter than **2** and treat the query as raw regular expression.
To change this behavior, change the value of `FinderMultiQueryMigemo.minimum_query_length` like following settings.
```python
from percol.finder import FinderMultiQueryMigemo
FinderMultiQueryMigemo.minimum_query_length = 1
```
### Pinyin support
Now percol supports **pinyin** (http://en.wikipedia.org/wiki/Pinyin) for matching Chinese characters.
$ percol --match-method pinyin
In this matching method, first char of each Chinese character's pinyin sequence is used for matching.
For example, 'zw' matches '中文' (ZhongWen), '中午'(ZhongWu), '作为' (ZuoWei) etc.
Extra package pinin(https://pypi.python.org/pypi/pinyin/0.2.5) needed.
### Switching matching method dynamically
Matching method can be switched dynamically (at run time) by executing `percol.command.specify_finder(FinderClass)` or `percol.command.toggle_finder(FinderClass)`. In addition, `percol.command.specify_case_sensitive(case_sensitive)` and `percol.command.toggle_case_sensitive()` change the matching status of case sensitivity.
```python
from percol.finder import FinderMultiQueryMigemo, FinderMultiQueryRegex
percol.import_keymap({
"M-c" : lambda percol: percol.command.toggle_case_sensitive(),
"M-m" : lambda percol: percol.command.toggle_finder(FinderMultiQueryMigemo),
"M-r" : lambda percol: percol.command.toggle_finder(FinderMultiQueryRegex)
})
```
## Tips
### Selecting multiple candidates
You can select and let percol to output multiple candidates by `percol.command.toggle_mark_and_next()` (which is bound to `C-SPC` by default).
`percol.command.mark_all()`, `percol.command.unmark_all()` and `percol.command.toggle_mark_all()` are useful to mark / unmark all candidates at once.
## Z Shell support
A zsh completing-function for percol is available in https://github.com/mooz/percol/blob/master/tools/zsh/_percol .
���������������������������������������������������������������������������������������������������������������������������percol-0.2.1/bin/�����������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12556365562�0013565�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/bin/percol�����������������������������������������������������������������������������0000775�0000000�0000000�00000000463�12556365562�0015002�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os, sys
# add load path
if __name__ == '__main__':
libdir = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
if os.path.exists(os.path.join(libdir, "percol")):
sys.path.insert(0, libdir)
from percol.cli import main
main()
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/bin/sample/����������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12556365562�0015046�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/bin/sample/open_dropbox_pdf.sh���������������������������������������������������������0000775�0000000�0000000�00000000234�12556365562�0020733�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/bin/sh
gnome-terminal --title "Find PDF files" --hide-menubar \
-x sh -c "find ~/Dropbox/ -name \"*.pdf\" -type f | percol --quote | xargs evince"
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/debian/��������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12556365562�0014237�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/debian/changelog�����������������������������������������������������������������������0000664�0000000�0000000�00000000223�12556365562�0016106�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������python-percol (0.1-1) unstable; urgency=low
* Initial public release
-- Kozo Nishida Sun, 23 Aug 2014 4:15:00 +0200
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/debian/compat��������������������������������������������������������������������������0000664�0000000�0000000�00000000002�12556365562�0015435�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������9
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/debian/control�������������������������������������������������������������������������0000664�0000000�0000000�00000001300�12556365562�0015634�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Source: python-percol
Section: python
Priority: extra
Maintainer: Kozo Nishida
Build-Depends: debhelper (>= 9), python
Standards-Version: 3.9.5
Package: python-percol
Architecture: all
Description: percol adds flavor of interactive selection to the traditional pipe concept on UNIX.
percol is an interactive grep tool in your terminal. percol
1. receives input lines from stdin or a file,
2. lists up the input lines,
3. waits for your input that filter/select the line(s),
4. and finally outputs the selected line(s) to stdout.
Since percol just filters the input and output the result to stdout, it can be used in command-chains with | in your shell (UNIX philosophy!).
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/debian/rules���������������������������������������������������������������������������0000775�0000000�0000000�00000000055�12556365562�0015317�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/make -f
%:
dh $@ --with python2
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/��������������������������������������������������������������������������������0000775�0000000�0000000�00000000000�12556365562�0014301�5����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/__init__.py���������������������������������������������������������������������0000664�0000000�0000000�00000022155�12556365562�0016417�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import percol.info
__doc__ = info.__doc__
__version__ = info.__version__
__logo__ = info.__logo__
import sys
import signal
import curses
import threading
import six
from percol import debug, action
from percol.display import Display
from percol.finder import FinderMultiQueryString
from percol.key import KeyHandler
from percol.model import SelectorModel
from percol.view import SelectorView
from percol.command import SelectorCommand
class TerminateLoop(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
class Percol(object):
def __init__(self, descriptors = None, encoding = "utf-8",
finder = None, action_finder = None,
candidates = None, actions = None,
query = None, caret = None, index = None):
# initialization
self.global_lock = threading.Lock()
self.encoding = encoding
if descriptors is None:
self.stdin = sys.stdin
self.stdout = sys.stdout
self.stderr = sys.stderr
else:
self.stdin = descriptors["stdin"]
self.stdout = descriptors["stdout"]
self.stderr = descriptors["stderr"]
if finder is None:
finder = FinderMultiQueryString
if action_finder is None:
action_finder = FinderMultiQueryString
self.actions = actions
# wraps candidates (iterator)
from percol.lazyarray import LazyArray
self.candidates = LazyArray(candidates or [])
# create model
self.model_candidate = SelectorModel(percol = self,
collection = self.candidates,
finder = finder,
query = query, caret = caret, index = index)
self.model_action = SelectorModel(percol = self,
collection = [action.desc for action in actions],
finder = action_finder)
self.model = self.model_candidate
def has_no_candidate(self):
return not self.candidates.has_nth_value(0)
def has_only_one_candidate(self):
return self.candidates.has_nth_value(0) and not self.candidates.has_nth_value(1)
def __enter__(self):
# init curses and it's wrapper
self.screen = curses.initscr()
self.display = Display(self.screen, self.encoding)
# create keyhandler
self.keyhandler = key.KeyHandler(self.screen)
# create view
self.view = SelectorView(percol = self)
# create command
self.command_candidate = SelectorCommand(self.model_candidate, self.view)
self.command_action = SelectorCommand(self.model_action, self.view)
# suppress SIGINT termination
signal.signal(signal.SIGINT, lambda signum, frame: None)
# handle special keys like , , ...
self.screen.keypad(True)
curses.raw()
curses.noecho()
curses.cbreak()
curses.nonl()
return self
def __exit__(self, exc_type, exc_value, traceback):
curses.endwin()
self.execute_action()
args_for_action = None
def execute_action(self):
selected_actions = self.model_action.get_selected_results_with_index()
if selected_actions and self.args_for_action:
for name, _, act_idx in selected_actions:
try:
action = self.actions[act_idx]
if action:
action.act([arg for arg, _, _ in self.args_for_action], self)
except Exception as e:
debug.log("execute_action", e)
# ============================================================ #
# Statuses
# ============================================================ #
@property
def opposite_model(self):
"""
Returns opposite model for self.model
"""
if self.model is self.model_action:
return self.model_candidate
else:
return self.model_action
def switch_model(self):
self.model = self.opposite_model
@property
def command(self):
"""
Returns corresponding model wrapper which provides advanced commands
"""
if self.model is self.model_action:
return self.command_action
else:
return self.command_candidate
# ============================================================ #
# Main Loop
# ============================================================ #
SEARCH_DELAY = 0.05
def loop(self):
self.view.refresh_display()
self.result_updating_timer = None
def search_and_refresh_display():
self.model.do_search(self.model.query)
self.view.refresh_display()
while True:
try:
self.handle_key(self.screen.getch())
if self.model.should_search_again():
# search again
with self.global_lock:
# critical section
if not self.result_updating_timer is None:
# clear timer
self.result_updating_timer.cancel()
self.result_updating_timer = None
# with bounce
t = threading.Timer(self.SEARCH_DELAY, search_and_refresh_display)
self.result_updating_timer = t
t.start()
self.view.refresh_display()
except TerminateLoop as e:
return e.value
# ============================================================ #
# Key Handling
# ============================================================ #
keymap = {
"C-i" : lambda percol: percol.switch_model(),
# text
"C-h" : lambda percol: percol.command.delete_backward_char(),
"" : lambda percol: percol.command.delete_backward_char(),
"C-w" : lambda percol: percol.command.delete_backward_word(),
"C-u" : lambda percol: percol.command.clear_query(),
"" : lambda percol: percol.command.delete_forward_char(),
# caret
"" : lambda percol: percol.command.backward_char(),
"" : lambda percol: percol.command.forward_char(),
# line
"" : lambda percol: percol.command.select_next(),
"" : lambda percol: percol.command.select_previous(),
# page
"" : lambda percol: percol.command.select_next_page(),
"" : lambda percol: percol.command.select_previous_page(),
# top / bottom
"" : lambda percol: percol.command.select_top(),
"" : lambda percol: percol.command.select_bottom(),
# mark
"C-SPC" : lambda percol: percol.command.toggle_mark_and_next(),
# finish
"RET" : lambda percol: percol.finish(), # Is RET never sent?
"C-m" : lambda percol: percol.finish(),
"C-j" : lambda percol: percol.finish(),
"C-c" : lambda percol: percol.cancel()
}
def import_keymap(self, keymap, reset = False):
if reset:
self.keymap = {}
else:
self.keymap = dict(self.keymap)
for key, cmd in six.iteritems(keymap):
self.keymap[key] = cmd
# default
last_key = None
def handle_key(self, ch):
if ch == curses.KEY_RESIZE:
self.last_key = self.handle_resize(ch)
elif ch != -1 and self.keyhandler.is_utf8_multibyte_key(ch):
self.last_key = self.handle_utf8(ch)
else:
self.last_key = self.handle_normal_key(ch)
def handle_resize(self, ch):
self.display.update_screen_size()
# XXX: trash -1 (it seems that resize key sends -1)
self.keyhandler.get_key_for(self.screen.getch())
return key.SPECIAL_KEYS[ch]
def handle_utf8(self, ch):
ukey = self.keyhandler.get_utf8_key_for(ch)
self.model.insert_string(ukey)
return ukey.encode(self.encoding)
def handle_normal_key(self, ch):
k = self.keyhandler.get_key_for(ch)
if k in self.keymap:
self.keymap[k](self)
elif self.keyhandler.is_displayable_key(ch):
self.model.insert_char(ch)
return k
# ------------------------------------------------------------ #
# Finish / Cancel
# ------------------------------------------------------------ #
def finish(self):
# save selected candidates and use them later (in execute_action)
raise TerminateLoop(self.finish_with_exit_code()) # success
def cancel(self):
raise TerminateLoop(self.cancel_with_exit_code()) # failure
def finish_with_exit_code(self):
self.args_for_action = self.model_candidate.get_selected_results_with_index()
return 0
def cancel_with_exit_code(self):
return 1
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/action.py�����������������������������������������������������������������������0000664�0000000�0000000�00000000642�12556365562�0016132�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
# ============================================================ #
# Action
# ============================================================ #
class Action(object):
def __init__(self, desc, act, args):
self.act = act
self.desc = desc
self.args = args
def action(**args):
def act_handler(act):
return Action(act.__doc__, act, args)
return act_handler
����������������������������������������������������������������������������������������������percol-0.2.1/percol/actions.py����������������������������������������������������������������������0000664�0000000�0000000�00000001462�12556365562�0016316�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import sys, six
from percol.action import action
def double_quote_string(string):
return '"' + string.replace('"', r'\"') + '"'
def get_raw_stream(stream):
if six.PY2:
return stream
else:
return stream.buffer
@action()
def output_to_stdout(lines, percol):
"output marked (selected) items to stdout"
stdout = get_raw_stream(sys.stdout)
for line in lines:
stdout.write(percol.display.get_raw_string(line))
stdout.write(six.b("\n"))
@action()
def output_to_stdout_double_quote(lines, percol):
"output marked (selected) items to stdout with double quotes"
stdout = get_raw_stream(sys.stdout)
for line in lines:
stdout.write(percol.display.get_raw_string(double_quote_string(line)))
stdout.write(six.b("\n"))
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/ansi.py�������������������������������������������������������������������������0000664�0000000�0000000�00000004471�12556365562�0015613�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
from percol.markup import MarkupParser
import sys
import re
# http://graphcomp.com/info/specs/ansi_col.html
DISPLAY_ATTRIBUTES = {
"reset" : 0,
"bold" : 1,
"bright" : 1,
"dim" : 2,
"underline" : 4,
"underscore" : 4,
"blink" : 5,
"reverse" : 7,
"hidden" : 8,
# Colors
"black" : 30,
"red" : 31,
"green" : 32,
"yellow" : 33,
"blue" : 34,
"magenta" : 35,
"cyan" : 36,
"white" : 37,
"on_black" : 40,
"on_red" : 41,
"on_green" : 42,
"on_yellow" : 43,
"on_blue" : 44,
"on_magenta" : 45,
"on_cyan" : 46,
"on_white" : 47,
}
markup_parser = MarkupParser()
def markup(string):
return decorate_parse_result(markup_parser.parse(string))
def remove_escapes(string):
return re.sub(r"\x1B\[(?:[0-9]{1,2}(?:;[0-9]{1,2})?)?[m|K]", "", string)
def decorate_parse_result(parse_result):
decorated_string = ""
for (fragment_string, attributes) in parse_result:
decorated_string += decorate_string_with_attributes(fragment_string, attributes)
return decorated_string
def decorate_string_with_attributes(string, attributes):
attribute_numbers = attribute_names_to_numbers(attributes)
attribute_format = ";".join(attribute_numbers)
return "\033[{0}m{1}\033[0m".format(attribute_format, string)
def attribute_names_to_numbers(attribute_names):
return [str(DISPLAY_ATTRIBUTES[name])
for name in attribute_names
if name in DISPLAY_ATTRIBUTES]
if __name__ == "__main__":
tests = (
"hello",
"hello red normal",
"hello with background green this is underline and red then, normal",
"baaaaaaaaaaaaaaaa", # unmatch
"baaaaaaaaaaaaaaaa",
"hello \\red\\ normal", # escape
u"マルチバイト文字のテスト", # multibyte
)
for test in tests:
try:
print("----------------------------------------------------------")
print(markup(test))
except Exception as e:
print("fail: " + str(e))
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/cli.py��������������������������������������������������������������������������0000664�0000000�0000000�00000026350�12556365562�0015430�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import sys
import os
import locale
import six
from optparse import OptionParser
import percol
from percol import Percol
from percol import tty
from percol import debug
from percol import ansi
INSTRUCTION_TEXT = ansi.markup("""{logo}
{version}
You did not give any inputs to percol. Check following typical usages and try again.
(1) Giving a filename,
$ percol /var/log/syslog
(2) or specifying a redirection.
$ ps aux | percol
""").format(logo = percol.__logo__,
version = percol.__version__)
class LoadRunCommandFileError(Exception):
def __init__(self, error):
self.error = error
def __str__(self):
return "Error in rc.py: " + str(self.error)
CONF_ROOT_DIR = os.path.expanduser("~/.percol.d/")
DEFAULT_CONF_PATH = CONF_ROOT_DIR + "rc.py"
def create_default_rc_file():
if not os.path.exists(CONF_ROOT_DIR):
os.makedirs(CONF_ROOT_DIR)
with open(DEFAULT_CONF_PATH, "w+") as file:
file.write("# Run command file for percol\n")
def load_rc(percol, path = None, encoding = 'utf-8'):
if path is None:
if not os.path.exists(DEFAULT_CONF_PATH):
create_default_rc_file()
path = DEFAULT_CONF_PATH
try:
with open(path, "rb") as file:
exec(compile(file.read(), path, 'exec'), locals())
except Exception as e:
raise LoadRunCommandFileError(e)
def eval_string(percol, string_to_eval, encoding = 'utf-8'):
try:
import six
if not isinstance(string_to_eval, six.text_type):
string_to_eval = string_to_eval.decode(encoding)
exec(string_to_eval, locals())
except Exception as e:
debug.log("Exception in eval_string", e)
def error_message(message):
return ansi.markup("[Error] " + message)
def setup_options(parser):
parser.add_option("--tty", dest = "tty",
help = "path to the TTY (usually, the value of $TTY)")
parser.add_option("--rcfile", dest = "rcfile",
help = "path to the settings file")
parser.add_option("--output-encoding", dest = "output_encoding",
help = "encoding for output")
parser.add_option("--input-encoding", dest = "input_encoding", default = "utf8",
help = "encoding for input and output (default 'utf8')")
parser.add_option("-v", "--invert-match", action="store_true", dest = "invert_match", default = False,
help = "select non-matching lines")
parser.add_option("--query", dest = "query",
help = "pre-input query")
parser.add_option("--eager", action = "store_true", dest = "eager", default = False,
help = "suppress lazy matching (slower, but display correct candidates count)")
parser.add_option("--eval", dest = "string_to_eval",
help = "eval given string after loading the rc file")
parser.add_option("--prompt", dest = "prompt", default = None,
help = "specify prompt (percol.view.PROMPT)")
parser.add_option("--right-prompt", dest = "right_prompt", default = None,
help = "specify right prompt (percol.view.RPROMPT)")
parser.add_option("--match-method", dest = "match_method", default = "",
help = "specify matching method for query. `string` (default) and `regex` are currently supported")
parser.add_option("--caret-position", dest = "caret",
help = "position of the caret (default length of the `query`)")
parser.add_option("--initial-index", dest = "index",
help = "position of the initial index of the selection (numeric, \"first\" or \"last\")")
parser.add_option("--case-sensitive", dest = "case_sensitive", default = False, action="store_true",
help = "whether distinguish the case of query or not")
parser.add_option("--reverse", dest = "reverse", default = False, action="store_true",
help = "whether reverse the order of candidates or not")
parser.add_option("--auto-fail", dest = "auto_fail", default = False, action="store_true",
help = "auto fail if no candidates")
parser.add_option("--auto-match", dest = "auto_match", default = False, action="store_true",
help = "auto matching if only one candidate")
parser.add_option("--prompt-top", dest = "prompt_on_top", default = None, action="store_true",
help = "display prompt top of the screen (default)")
parser.add_option("--prompt-bottom", dest = "prompt_on_top", default = None, action="store_false",
help = "display prompt bottom of the screen")
parser.add_option("--result-top-down", dest = "results_top_down", default = None, action="store_true",
help = "display results top down (default)")
parser.add_option("--result-bottom-up", dest = "results_top_down", default = None, action="store_false",
help = "display results bottom up instead of top down")
parser.add_option("--quote", dest = "quote", default = False, action="store_true",
help = "whether quote the output line")
parser.add_option("--peep", action = "store_true", dest = "peep", default = False,
help = "exit immediately with doing nothing to cache module files and speed up start-up time")
def set_proper_locale(options):
locale.setlocale(locale.LC_ALL, '')
output_encoding = locale.getpreferredencoding()
if options.output_encoding:
output_encoding = options.output_encoding
return output_encoding
def read_input(filename, encoding, reverse=False):
import codecs
if filename:
if six.PY2:
stream = codecs.getreader(encoding)(open(filename, "r"), "replace")
else:
stream = open(filename, "r", encoding=encoding)
else:
if six.PY2:
stream = codecs.getreader(encoding)(sys.stdin, "replace")
else:
import io
stream = io.TextIOWrapper(sys.stdin.buffer, encoding=encoding)
if reverse:
lines = reversed(stream.readlines())
else:
lines = stream
for line in lines:
yield ansi.remove_escapes(line.rstrip("\r\n"))
stream.close()
def decide_match_method(options):
if options.match_method == "regex":
from percol.finder import FinderMultiQueryRegex
return FinderMultiQueryRegex
elif options.match_method == "migemo":
from percol.finder import FinderMultiQueryMigemo
return FinderMultiQueryMigemo
elif options.match_method == "pinyin":
from percol.finder import FinderMultiQueryPinyin
return FinderMultiQueryPinyin
else:
from percol.finder import FinderMultiQueryString
return FinderMultiQueryString
def main():
from percol import __version__
parser = OptionParser(usage = "Usage: %prog [options] [FILE]", version = "%prog {0}".format(__version__))
setup_options(parser)
options, args = parser.parse_args()
if options.peep:
exit(1)
def exit_program(msg = None, show_help = True):
if not msg is None:
print(msg)
if show_help:
parser.print_help()
exit(1)
# get ttyname
ttyname = options.tty or tty.get_ttyname()
if not ttyname:
exit_program(error_message("""No tty name is given and failed to guess it from descriptors.
Maybe all descriptors are redirecred."""))
# decide which encoding to use
output_encoding = set_proper_locale(options)
input_encoding = options.input_encoding
def open_tty(ttyname):
if six.PY2:
return open(ttyname, "r+w")
else:
# See https://github.com/stefanholek/term/issues/1
return open(ttyname, "wb+", buffering=0)
with open_tty(ttyname) as tty_f:
if not tty_f.isatty():
exit_program(error_message("{0} is not a tty file".format(ttyname)),
show_help = False)
filename = args[0] if len(args) > 0 else None
if filename and not os.access(filename, os.R_OK):
exit_program(error_message("Cannot read a file '" + filename + "'"),
show_help=False)
if filename is None and sys.stdin.isatty():
tty_f.write(INSTRUCTION_TEXT.encode(output_encoding))
exit_program(show_help = False)
# read input
try:
candidates = read_input(filename, input_encoding, reverse=options.reverse)
except KeyboardInterrupt:
exit_program("Canceled", show_help = False)
# setup actions
import percol.actions as actions
if (options.quote):
acts = (actions.output_to_stdout_double_quote, )
else:
acts = (actions.output_to_stdout, actions.output_to_stdout_double_quote)
# arrange finder class
candidate_finder_class = action_finder_class = decide_match_method(options)
def set_finder_attribute_from_option(finder_instance):
finder_instance.lazy_finding = not options.eager
finder_instance.case_insensitive = not options.case_sensitive
finder_instance.invert_match = options.invert_match
def set_if_not_none(src, dest, name):
value = getattr(src, name)
if value is not None:
setattr(dest, name, value)
with Percol(descriptors = tty.reconnect_descriptors(tty_f),
candidates = candidates,
actions = acts,
finder = candidate_finder_class,
action_finder = action_finder_class,
query = options.query,
caret = options.caret,
index = options.index,
encoding = output_encoding) as percol:
# load run-command file
load_rc(percol, options.rcfile)
# override prompts
if options.prompt is not None:
percol.view.__class__.PROMPT = property(lambda self: options.prompt)
if options.right_prompt is not None:
percol.view.__class__.RPROMPT = property(lambda self: options.right_prompt)
# evalutate strings specified by the option argument
if options.string_to_eval is not None:
eval_string(percol, options.string_to_eval, locale.getpreferredencoding())
# finder settings from option values
set_finder_attribute_from_option(percol.model_candidate.finder)
# view settings from option values
set_if_not_none(options, percol.view, 'prompt_on_top')
set_if_not_none(options, percol.view, 'results_top_down')
# enter main loop
if options.auto_fail and percol.has_no_candidate():
exit_code = percol.cancel_with_exit_code()
elif options.auto_match and percol.has_only_one_candidate():
exit_code = percol.finish_with_exit_code()
else:
exit_code = percol.loop()
exit(exit_code)
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/command.py����������������������������������������������������������������������0000664�0000000�0000000�00000017032�12556365562�0016274�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import six
class SelectorCommand(object):
"""
Wraps up SelectorModel and provides advanced commands
"""
def __init__(self, model, view):
self.model = model
self.view = view
# ------------------------------------------------------------ #
# Selection
# ------------------------------------------------------------ #
# Line
def select_successor(self):
self.model.select_index(self.model.index + 1)
def select_predecessor(self):
self.model.select_index(self.model.index - 1)
def select_next(self):
if self.view.results_top_down:
self.select_successor()
else:
self.select_predecessor()
def select_previous(self):
if self.view.results_top_down:
self.select_predecessor()
else:
self.select_successor()
# Top / Bottom
def select_top(self):
if self.view.results_top_down:
self.model.select_top()
else:
self.model.select_bottom()
def select_bottom(self):
if self.view.results_top_down:
self.model.select_bottom()
else:
self.model.select_top()
# Page
def select_successor_page(self):
self.model.select_index(self.model.index + self.view.RESULTS_DISPLAY_MAX)
def select_predecessor_page(self):
self.model.select_index(self.model.index - self.view.RESULTS_DISPLAY_MAX)
def select_next_page(self):
if self.view.results_top_down:
self.select_successor_page()
else:
self.select_predecessor_page()
def select_previous_page(self):
if self.view.results_top_down:
self.select_predecessor_page()
else:
self.select_successor_page()
# ------------------------------------------------------------ #
# Mark
# ------------------------------------------------------------ #
def toggle_mark(self):
self.model.set_is_marked(not self.model.get_is_marked())
def toggle_mark_and_next(self):
self.toggle_mark()
self.select_successor()
def __get_all_mark_indices(self):
return six.moves.range(self.model.results_count)
def mark_all(self):
for mark_index in self.__get_all_mark_indices():
self.model.set_is_marked(True, mark_index)
def unmark_all(self):
for mark_index in self.__get_all_mark_indices():
self.model.set_is_marked(False, mark_index)
def toggle_mark_all(self):
for mark_index in self.__get_all_mark_indices():
self.model.set_is_marked(not self.model.get_is_marked(mark_index), mark_index)
# ------------------------------------------------------------ #
# Caret
# ------------------------------------------------------------ #
def beginning_of_line(self):
self.model.set_caret(0)
def end_of_line(self):
self.model.set_caret(len(self.model.query))
def backward_char(self):
self.model.set_caret(self.model.caret - 1)
def forward_char(self):
self.model.set_caret(self.model.caret + 1)
def _get_backward_word_begin(self):
from re import match
skippable_substring = match(r'\s*\S*', self.model.query[:self.model.caret][::-1])
return self.model.caret - skippable_substring.end()
def _get_forward_word_end(self):
from re import match
skippable_substring = match(r'\s*\S*', self.model.query[self.model.caret:])
return self.model.caret + skippable_substring.end()
def backward_word(self):
self.model.set_caret(self._get_backward_word_begin())
def forward_word(self):
self.model.set_caret(self._get_forward_word_end())
# ------------------------------------------------------------ #
# Text
# ------------------------------------------------------------ #
def delete_backward_char(self):
if self.model.caret > 0:
self.backward_char()
self.delete_forward_char()
def delete_forward_char(self):
caret = self.model.caret
self.model.query = self.model.query[:caret] + self.model.query[caret + 1:]
def delete_backward_word(self):
backword_word_begin = self._get_backward_word_begin()
backword_word_end = self.model.caret
self.model.query = self.model.query[:backword_word_begin] + self.model.query[backword_word_end:]
self.model.set_caret(backword_word_begin)
def delete_forward_word(self):
forward_word_begin = self.model.caret
forward_word_end = self._get_forward_word_end()
self.model.query = self.model.query[:forward_word_begin] + self.model.query[forward_word_end:]
self.model.set_caret(forward_word_begin)
def delete_end_of_line(self):
self.model.query = self.model.query[:self.model.caret]
def clear_query(self):
self.model.query = u""
self.model.set_caret(0)
def transpose_chars(self):
caret = self.model.caret
qlen = len(self.model.query)
if qlen <= 1:
self.end_of_line()
elif caret == 0:
self.forward_char()
self.transpose_chars()
elif caret == qlen:
self.backward_char()
self.transpose_chars()
else:
self.model.query = self.model.query[:caret - 1] + \
self.model.query[caret] + \
self.model.query[caret - 1] + \
self.model.query[caret + 1:]
self.forward_char()
def unnarrow(self):
"""
Clears the query, but keeps the current line selected. Useful to
show context around a search match.
"""
try:
original_index = self.model.results[self.model.index][2]
except IndexError:
original_index = 0
self.clear_query()
self.model.do_search("")
self.model.select_index(original_index)
# ------------------------------------------------------------ #
# Text > kill
# ------------------------------------------------------------ #
def kill_end_of_line(self):
self.model.killed = self.model.query[self.model.caret:]
self.model.query = self.model.query[:self.model.caret]
killed = None # default
def yank(self):
if self.model.killed:
self.model.insert_string(self.model.killed)
# ------------------------------------------------------------ #
# Finder
# ------------------------------------------------------------ #
def specify_case_sensitive(self, case_sensitive):
self.model.finder.case_insensitive = not case_sensitive
self.model.force_search()
def toggle_case_sensitive(self):
self.model.finder.case_insensitive = not self.model.finder.case_insensitive
self.model.force_search()
def specify_split_query(self, split_query):
self.model.finder.split_query = split_query
self.model.force_search()
def toggle_split_query(self):
self.model.finder.split_query = not self.model.finder.split_query
self.model.force_search()
def specify_finder(self, preferred_finder_class):
self.model.remake_finder(preferred_finder_class)
self.model.force_search()
def toggle_finder(self, preferred_finder_class):
if self.model.finder.__class__ == preferred_finder_class:
self.model.remake_finder(self.model.original_finder_class)
else:
self.model.remake_finder(preferred_finder_class)
self.model.force_search()
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/debug.py������������������������������������������������������������������������0000664�0000000�0000000�00000000470�12556365562�0015742�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import syslog
syslog.openlog("Percol")
def log(name, s = ""):
syslog.syslog(syslog.LOG_ALERT, str(name) + ": " + str(s))
def dump(obj):
import pprint
pp = pprint.PrettyPrinter(indent=2)
syslog.syslog(syslog.LOG_ALERT, str(name) + ": " + pp.pformat(obj))
return obj
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/display.py����������������������������������������������������������������������0000664�0000000�0000000�00000025052�12556365562�0016324�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import unicodedata
import six
import curses
import re
from percol import markup, debug
FG_COLORS = {
"black" : curses.COLOR_BLACK,
"red" : curses.COLOR_RED,
"green" : curses.COLOR_GREEN,
"yellow" : curses.COLOR_YELLOW,
"blue" : curses.COLOR_BLUE,
"magenta" : curses.COLOR_MAGENTA,
"cyan" : curses.COLOR_CYAN,
"white" : curses.COLOR_WHITE,
}
BG_COLORS = dict(("on_" + name, value) for name, value in six.iteritems(FG_COLORS))
ATTRS = {
"altcharset" : curses.A_ALTCHARSET,
"blink" : curses.A_BLINK,
"bold" : curses.A_BOLD,
"dim" : curses.A_DIM,
"normal" : curses.A_NORMAL,
"standout" : curses.A_STANDOUT,
"underline" : curses.A_UNDERLINE,
"reverse" : curses.A_REVERSE,
}
COLOR_COUNT = len(FG_COLORS)
# ============================================================ #
# Markup
# ============================================================ #
def get_fg_color(attrs):
for attr in attrs:
if attr in FG_COLORS:
return FG_COLORS[attr]
return FG_COLORS["default"]
def get_bg_color(attrs):
for attr in attrs:
if attr in BG_COLORS:
return BG_COLORS[attr]
return BG_COLORS["on_default"]
def get_attributes(attrs):
for attr in attrs:
if attr in ATTRS:
yield ATTRS[attr]
# ============================================================ #
# Unicode
# ============================================================ #
def screen_len(s, beg = None, end = None):
if beg is None:
beg = 0
if end is None:
end = len(s)
if "\t" in s:
# consider tabstop (very naive approach)
beg = len(s[0:beg].expandtabs())
end = len(s[beg:end].expandtabs())
s = s.expandtabs()
if not isinstance(s, six.text_type):
return end - beg
dis_len = end - beg
for i in six.moves.range(beg, end):
if unicodedata.east_asian_width(s[i]) in ("W", "F"):
dis_len += 1
return dis_len
def screen_length_to_bytes_count(string, screen_length_limit, encoding):
bytes_count = 0
screen_length = 0
for unicode_char in string:
screen_length += screen_len(unicode_char)
char_bytes_count = len(unicode_char.encode(encoding))
bytes_count += char_bytes_count
if screen_length > screen_length_limit:
bytes_count -= char_bytes_count
break
return bytes_count
# ============================================================ #
# Display
# ============================================================ #
class Display(object):
def __init__(self, screen, encoding):
self.screen = screen
self.encoding = encoding
self.markup_parser = markup.MarkupParser()
curses.start_color()
self.has_default_colors = curses.COLORS > COLOR_COUNT
if self.has_default_colors:
# xterm-256color
curses.use_default_colors()
FG_COLORS["default"] = -1
BG_COLORS["on_default"] = -1
self.init_color_pairs()
elif curses.COLORS != 0:
# ansi linux rxvt ...etc.
self.init_color_pairs()
FG_COLORS["default"] = curses.COLOR_WHITE
BG_COLORS["on_default"] = curses.COLOR_BLACK
else: # monochrome, curses.COLORS == 0
# vt100 x10term wy520 ...etc.
FG_COLORS["default"] = curses.COLOR_WHITE
BG_COLORS["on_default"] = curses.COLOR_BLACK
self.update_screen_size()
def update_screen_size(self):
self.HEIGHT, self.WIDTH = self.screen.getmaxyx()
@property
def Y_BEGIN(self):
return 0
@property
def Y_END(self):
return self.HEIGHT - 1
@property
def X_BEGIN(self):
return 0
@property
def X_END(self):
return self.WIDTH - 1
# ============================================================ #
# Color Pairs
# ============================================================ #
def init_color_pairs(self):
for fg_s, fg in six.iteritems(FG_COLORS):
for bg_s, bg in six.iteritems(BG_COLORS):
if not (fg == bg == 0):
curses.init_pair(self.get_pair_number(fg, bg), fg, bg)
def get_normalized_number(self, number):
return COLOR_COUNT if number < 0 else number
def get_pair_number(self, fg, bg):
if self.has_default_colors:
# Assume the number of colors is up to 16 (2^4 = 16)
return self.get_normalized_number(fg) | (self.get_normalized_number(bg) << 4)
else:
return self.get_normalized_number(fg) + self.get_normalized_number(bg) * COLOR_COUNT
def get_color_pair(self, fg, bg):
return curses.color_pair(self.get_pair_number(fg, bg))
# ============================================================ #
# Aligned string
# ============================================================ #
def get_pos_x(self, x_align, x_offset, whole_len):
position = 0
if x_align == "left":
position = x_offset
elif x_align == "right":
position = self.WIDTH - whole_len - x_offset
elif x_align == "center":
position = x_offset + (int(self.WIDTH - whole_len) / 2)
return position
def get_pos_y(self, y_align, y_offset):
position = 0
if y_align == "top":
position = y_offset
elif y_align == "bottom":
position = self.HEIGHT - y_offset
elif y_align == "center":
position = y_offset + int(self.HEIGHT / 2)
return position
def get_flag_from_attrs(self, attrs):
flag = self.get_color_pair(get_fg_color(attrs), get_bg_color(attrs))
for attr in get_attributes(attrs):
flag |= attr
return flag
def add_aligned_string_markup(self, markup, **keywords):
return self.add_aligned_string_tokens(self.markup_parser.parse(markup), **keywords)
def add_aligned_string_tokens(self, tokens,
y_align = "top", x_align = "left",
y_offset = 0, x_offset = 0,
fill = False, fill_char = " ", fill_style = None):
dis_lens = [screen_len(s) for (s, attrs) in tokens]
whole_len = sum(dis_lens)
pos_x = self.get_pos_x(x_align, x_offset, whole_len)
pos_y = self.get_pos_y(y_align, y_offset)
org_pos_x = pos_x
for i, (s, attrs) in enumerate(tokens):
self.add_string(s, pos_y, pos_x, self.attrs_to_style(attrs))
pos_x += dis_lens[i]
if fill:
self.add_filling(fill_char, pos_y, 0, org_pos_x, fill_style)
self.add_filling(fill_char, pos_y, pos_x, self.WIDTH, fill_style)
return pos_y, org_pos_x
def add_aligned_string(self, s,
y_align = "top", x_align = "left",
y_offset = 0, x_offset = 0,
style = None,
fill = False, fill_char = " ", fill_style = None):
dis_len = screen_len(s)
pos_x = self.get_pos_x(x_align, x_offset, dis_len)
pos_y = self.get_pos_y(y_align, y_offset)
self.add_string(s, pos_y, pos_x, style)
if fill:
if fill_style is None:
fill_style = style
self.add_filling(fill_char, pos_y, 0, pos_x, fill_style)
self.add_filling(fill_char, pos_y, pos_x + dis_len, self.WIDTH, fill_style)
return pos_y, pos_x
def add_filling(self, fill_char, pos_y, pos_x_beg, pos_x_end, style):
filling_len = pos_x_end - pos_x_beg
if filling_len > 0:
self.add_string(fill_char * filling_len, pos_y, pos_x_beg, style)
def attrs_to_style(self, attrs):
if attrs is None:
return 0
style = self.get_color_pair(get_fg_color(attrs), get_bg_color(attrs))
for attr in get_attributes(attrs):
style |= attr
return style
def add_string(self, s, pos_y = 0, pos_x = 0, style = None, n = -1):
self.addnstr(pos_y, pos_x, s, n if n >= 0 else self.WIDTH - pos_x, style)
# ============================================================ #
# Fundamental
# ============================================================ #
def erase(self):
self.screen.erase()
def clear(self):
self.screen.clear()
def refresh(self):
self.screen.refresh()
def get_raw_string(self, s):
return s.encode(self.encoding) if isinstance(s, six.text_type) else s
def addnstr(self, y, x, s, n, style):
if not isinstance(style, six.integer_types):
style = self.attrs_to_style(style)
# Compute bytes count of the substring that fits in the screen
bytes_count_to_display = screen_length_to_bytes_count(s, n, self.encoding)
try:
sanitized_str = re.sub(r'[\x00-\x08\x0a-\x1f]', '?', s)
raw_str = self.get_raw_string(sanitized_str)
self.screen.addnstr(y, x, raw_str, bytes_count_to_display, style)
return True
except curses.error:
return False
if __name__ == "__main__":
import locale
locale.setlocale(locale.LC_ALL, '')
screen = curses.initscr()
display = Display(screen, locale.getpreferredencoding())
display.add_string("-" * display.WIDTH, pos_y = 2)
display.add_aligned_string_markup("foo bar baz qux",
x_align = "center", y_offset = 3)
display.add_aligned_string_markup(u"ああ,なんて赤くて太くて太い,そして赤いリンゴ",
y_offset = 4,
x_offset = -20,
x_align = "center",
fill = True, fill_char = "*")
display.add_aligned_string(u"こんにちは",
y_offset = 5,
x_offset = 0,
x_align = "right",
fill = True, fill_char = '*', fill_style = display.attrs_to_style(("bold", "white", "on_green")))
display.add_aligned_string(u" foo bar baz qux ",
x_align = "center", y_align = "center",
style = display.attrs_to_style(("bold", "white", "on_default")),
fill = True, fill_char = '-')
screen.getch()
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/finder.py�����������������������������������������������������������������������0000664�0000000�0000000�00000020743�12556365562�0016130�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
from abc import ABCMeta, abstractmethod
from percol.lazyarray import LazyArray
import six
# ============================================================ #
# Finder
# ============================================================ #
class Finder(object):
__metaclass__ = ABCMeta
def __init__(self, **args):
pass
def clone_as(self, new_finder_class):
new_finder = new_finder_class(collection = self.collection)
new_finder.invert_match = self.invert_match
new_finder.lazy_finding = self.lazy_finding
return new_finder
@abstractmethod
def get_name(self):
pass
@abstractmethod
def find(self, query, collection = None):
pass
invert_match = False
lazy_finding = True
def get_results(self, query, collection = None):
if self.lazy_finding:
return LazyArray((result for result in self.find(query, collection)))
else:
return [result for result in self.find(query, collection)]
# ============================================================ #
# Cached Finder
# ============================================================ #
class CachedFinder(Finder):
def __init__(self, **args):
self.results_cache = {}
def get_collection_from_trie(self, query):
"""
If any prefix of the query matches a past query, use its
result as a collection to improve performance (prefix of the
query constructs a trie)
"""
for i in six.moves.range(len(query) - 1, 0, -1):
query_prefix = query[0:i]
if query_prefix in self.results_cache:
return (line for (line, res, idx) in self.results_cache[query_prefix])
return None
def get_results(self, query):
if query in self.results_cache:
return self.results_cache[query]
collection = self.get_collection_from_trie(query) or self.collection
return Finder.get_results(self, query, collection)
# ============================================================ #
# Finder > multiquery
# ============================================================ #
class FinderMultiQuery(CachedFinder):
def __init__(self, collection, split_str = " "):
CachedFinder.__init__(self)
self.collection = collection
self.split_str = split_str
def clone_as(self, new_finder_class):
new_finder = Finder.clone_as(self, new_finder_class)
new_finder.case_insensitive = self.case_insensitive
new_finder.and_search = self.and_search
return new_finder
split_query = True
case_insensitive = True
dummy_res = [["", [(0, 0)]]]
def find(self, query, collection = None):
query_is_empty = query == ""
# Arrange queries
if self.case_insensitive:
query = query.lower()
# Split query when split_query is True
if self.split_query:
queries = [self.transform_query(sub_query)
for sub_query in query.split(self.split_str)]
else:
queries = [self.transform_query(query)]
if collection is None:
collection = self.collection
for idx, line in enumerate(collection):
if query_is_empty:
res = self.dummy_res
else:
if self.case_insensitive:
line_to_match = line.lower()
else:
line_to_match = line
res = self.find_queries(queries, line_to_match)
# When invert_match is enabled (via "-v" option),
# select non matching line
if self.invert_match:
res = None if res else self.dummy_res
if res:
yield line, res, idx
and_search = True
def find_queries(self, sub_queries, line):
res = []
and_search = self.and_search
for subq in sub_queries:
if subq:
find_info = self.find_query(subq, line)
if find_info:
res.append((subq, find_info))
elif and_search:
return None
return res
@abstractmethod
def find_query(self, needle, haystack):
# return [(pos1, pos1_len), (pos2, pos2_len), ...]
#
# where `pos1', `pos2', ... are begining positions of all occurence of needle in `haystack'
# and `pos1_len', `pos2_len', ... are its length.
pass
# override this method if needed
def transform_query(self, query):
return query
# ============================================================ #
# Finder > AND search
# ============================================================ #
class FinderMultiQueryString(FinderMultiQuery):
def get_name(self):
return "string"
trie_style_matching = True
def find_query(self, needle, haystack):
stride = len(needle)
start = 0
res = []
while True:
found = haystack.find(needle, start)
if found < 0:
break
res.append((found, stride))
start = found + stride
return res
# ============================================================ #
# Finder > AND search > Regular Expression
# ============================================================ #
class FinderMultiQueryRegex(FinderMultiQuery):
def get_name(self):
return "regex"
def transform_query(self, needle):
try:
import re
return re.compile(needle)
except:
return None
def find_query(self, needle, haystack):
try:
matched = needle.search(haystack)
return [(matched.start(), matched.end() - matched.start())]
except:
return None
# ============================================================ #
# Finder > AND search > Migemo
# ============================================================ #
class FinderMultiQueryMigemo(FinderMultiQuery):
def get_name(self):
return "migemo"
dictionary_path = None
minimum_query_length = 2
dictionary_path_candidates = [
"/usr/share/cmigemo/utf-8/migemo-dict",
"/usr/share/migemo/utf-8/migemo-dict",
"/usr/local/share/cmigemo/utf-8/migemo-dict",
"/usr/local/share/migemo/utf-8/migemo-dict"
]
def guess_dictionary_path(self):
import os
for path in [self.dictionary_path] + self.dictionary_path_candidates:
path = os.path.expanduser(path)
if os.access(path, os.R_OK):
return path
return None
migemo_instance = None
@property
def migemo(self):
import cmigemo, os
if self.migemo_instance is None:
dictionary_path = self.guess_dictionary_path()
if dictionary_path is None:
raise Exception("Error: Cannot find migemo dictionary. Install it and set dictionary_path.")
self.migemo_instance = cmigemo.Migemo(dictionary_path)
return self.migemo_instance
def transform_query(self, needle):
if len(needle) >= self.minimum_query_length:
regexp_string = self.migemo.query(needle)
else:
regexp_string = needle
import re
return re.compile(regexp_string)
def find_query(self, needle, haystack):
try:
matched = needle.search(haystack)
return [(matched.start(), matched.end() - matched.start())]
except:
return None
# ============================================================ #
# Finder > AND search > Pinyin support
# ============================================================ #
class FinderMultiQueryPinyin(FinderMultiQuery):
"""
In this matching method, first char of each Chinese character's
pinyin sequence is used for matching. For example, 'zw' matches
'中文' (ZhongWen), '中午'(ZhongWu), '作为' (ZuoWei) etc.
Extra package 'pinyin' needed.
"""
def get_name (self):
return "pinyin"
def find_query (self, needle, haystack):
try:
import pinyin
haystack_py = pinyin.get_initial(haystack, '' )
needle_len = len(needle)
start = 0
result = []
while True :
found = haystack_py.find(needle, start)
if found < 0 :
break
result.append((found, needle_len))
start = found + needle_len
return result
except :
return None
�����������������������������percol-0.2.1/percol/info.py�������������������������������������������������������������������������0000664�0000000�0000000�00000001137�12556365562�0015610�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
__doc__ = """Adds flavor of interactive filtering to the traditional pipe concept of shell.
Try::
$ A | percol | B
and you can display the output of command A and filter it interactively and then pass it to command B.
The interface of percol is highly inspired by anything.el for Emacs.
Full details at https://github.com/mooz/percol"""
__version__ = "0.2.1"
__logo__ = """ __
____ ___ ______________ / /
/ __ \/ _ \/ ___/ ___/ __ \/ /
/ /_/ / __/ / / /__/ /_/ / /
/ .___/\___/_/ \___/\____/_/
/_/"""
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������percol-0.2.1/percol/key.py��������������������������������������������������������������������������0000664�0000000�0000000�00000020260�12556365562�0015443�0����������������������������������������������������������������������������������������������������ustar�00root����������������������������root����������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# -*- coding: utf-8 -*-
import curses, array
import six
SPECIAL_KEYS = {
curses.KEY_A1 : "",
curses.KEY_A3 : "",
curses.KEY_B2 : "",
curses.KEY_BACKSPACE : "",
curses.KEY_BEG : "",
curses.KEY_BREAK : "",
curses.KEY_BTAB : "",
curses.KEY_C1 : "",
curses.KEY_C3 : "",
curses.KEY_CANCEL : "",
curses.KEY_CATAB : "",
curses.KEY_CLEAR : "",
curses.KEY_CLOSE : "",
curses.KEY_COMMAND : "",
curses.KEY_COPY : "",
curses.KEY_CREATE : "",
curses.KEY_CTAB : "",
curses.KEY_DC : "",
curses.KEY_DL : "",
curses.KEY_DOWN : "",
curses.KEY_EIC : "",
curses.KEY_END : "",
curses.KEY_ENTER : "",
curses.KEY_EOL : "",
curses.KEY_EOS : "",
curses.KEY_EXIT : "",
curses.KEY_F0 : "",
curses.KEY_F1 : "",
curses.KEY_F10 : "",
curses.KEY_F11 : "",
curses.KEY_F12 : "",
curses.KEY_F13 : "",
curses.KEY_F14 : "",
curses.KEY_F15 : "",
curses.KEY_F16 : "",
curses.KEY_F17 : "",
curses.KEY_F18 : "",
curses.KEY_F19 : "",
curses.KEY_F2 : "",
curses.KEY_F20 : "",
curses.KEY_F21 : "",
curses.KEY_F22 : "",
curses.KEY_F23 : "",
curses.KEY_F24 : "",
curses.KEY_F25 : "",
curses.KEY_F26 : "",
curses.KEY_F27 : "",
curses.KEY_F28 : "",
curses.KEY_F29 : "",
curses.KEY_F3 : "",
curses.KEY_F30 : "",
curses.KEY_F31 : "",
curses.KEY_F32 : "",
curses.KEY_F33 : "",
curses.KEY_F34 : "",
curses.KEY_F35 : "",
curses.KEY_F36 : "",
curses.KEY_F37 : "",
curses.KEY_F38 : "",
curses.KEY_F39 : "",
curses.KEY_F4 : "",
curses.KEY_F40 : "",
curses.KEY_F41 : "",
curses.KEY_F42 : "",
curses.KEY_F43 : "",
curses.KEY_F44 : "",
curses.KEY_F45 : "",
curses.KEY_F46 : "",
curses.KEY_F47 : "",
curses.KEY_F48 : "",
curses.KEY_F49 : "",
curses.KEY_F5 : "",
curses.KEY_F50 : "",
curses.KEY_F51 : "",
curses.KEY_F52 : "",
curses.KEY_F53 : "",
curses.KEY_F54 : "",
curses.KEY_F55 : "",
curses.KEY_F56 : "",
curses.KEY_F57 : "",
curses.KEY_F58 : "",
curses.KEY_F59 : "",
curses.KEY_F6 : "",
curses.KEY_F60 : "",
curses.KEY_F61 : "",
curses.KEY_F62 : "",
curses.KEY_F63 : "",
curses.KEY_F7 : "",
curses.KEY_F8 : "",
curses.KEY_F9 : "",
curses.KEY_FIND : "",
curses.KEY_HELP : "",
curses.KEY_HOME : "",
curses.KEY_IC : "",
curses.KEY_IL : "",
curses.KEY_LEFT : "",
curses.KEY_LL : "",
curses.KEY_MARK : "",
curses.KEY_MAX : "",
curses.KEY_MESSAGE : "",
curses.KEY_MIN : "",
curses.KEY_MOUSE : "",
curses.KEY_MOVE : "",
curses.KEY_NEXT : "",
curses.KEY_NPAGE : "",
curses.KEY_OPEN : "",
curses.KEY_OPTIONS : "",
curses.KEY_PPAGE : "",
curses.KEY_PREVIOUS : "",
curses.KEY_PRINT : "",
curses.KEY_REDO : "",
curses.KEY_REFERENCE : "",
curses.KEY_REFRESH : "",
curses.KEY_REPLACE : "",
curses.KEY_RESET : "",
curses.KEY_RESIZE : "",
curses.KEY_RESTART : "",
curses.KEY_RESUME : "",
curses.KEY_RIGHT : "",
curses.KEY_SAVE : "",
curses.KEY_SBEG : "",
curses.KEY_SCANCEL : "",
curses.KEY_SCOMMAND : "",
curses.KEY_SCOPY : "",
curses.KEY_SCREATE : "",
curses.KEY_SDC : "",
curses.KEY_SDL : "",
curses.KEY_SELECT : "