././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4631362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/�����������������������������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�012325� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000033�00000000000�010211� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������27 mtime=1696082266.439136
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/.github/���������������������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�013665� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4471362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/.github/workflows/�����������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�015722� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076496.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/.github/workflows/pytest.yml�������������������������������������������������������0000664�0001750�0001750�00000002131�14506011320�017761� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������name: Tests
on:
push:
branches:
- master
pull_request:
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-20.04
strategy:
matrix:
python-version: [3.6, 3.7, 3.8, 3.9, '3.10', 3.11, '3.12-dev']
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
- name: run tests
env:
STACK_DATA_SLOW_TESTS: 1
run: |
pip install --upgrade pip
pip install --upgrade coveralls setuptools setuptools_scm pep517
pip install .[tests]
coverage run --source stack_data -m pytest
coverage report -m
- name: Coveralls Python
uses: AndreMiras/coveralls-python-action@v20201129
with:
parallel: true
flag-name: test-${{ matrix.python-version }}
coveralls_finish:
needs: build
runs-on: ubuntu-latest
steps:
- name: Coveralls Finished
uses: AndreMiras/coveralls-python-action@v20201129
with:
parallel-finished: true
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1618742186.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/.gitignore�������������������������������������������������������������������������0000644�0001750�0001750�00000000165�14037005652�014316� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������dist
build
stack_data/version.py
.eggs
.pytest_cache
.tox
pip-wheel-metadata
venv
*.egg-info
*.pyc
*.pyo
__pycache__
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1581610656.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/LICENSE.txt������������������������������������������������������������������������0000644�0001750�0001750�00000002052�13621273240�014144� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������MIT License
Copyright (c) 2019 Alex Hall
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1660412296.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/MANIFEST.in������������������������������������������������������������������������0000664�0001750�0001750�00000000102�14275760610�014063� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������include LICENSE.txt
include README.md
include stack_data/py.typed
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4631362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/PKG-INFO���������������������������������������������������������������������������0000644�0001750�0001750�00000044001�14506024532�013417� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Metadata-Version: 2.1
Name: stack_data
Version: 0.6.3
Summary: Extract data from python stack frames and tracebacks for informative displays
Home-page: http://github.com/alexmojaki/stack_data
Author: Alex Hall
Author-email: alex.mojaki@gmail.com
License: MIT
Classifier: Intended Audience :: Developers
Classifier: Programming Language :: Python :: 3.5
Classifier: Programming Language :: Python :: 3.6
Classifier: Programming Language :: Python :: 3.7
Classifier: Programming Language :: Python :: 3.8
Classifier: Programming Language :: Python :: 3.9
Classifier: Programming Language :: Python :: 3.10
Classifier: Programming Language :: Python :: 3.11
Classifier: Programming Language :: Python :: 3.12
Classifier: License :: OSI Approved :: MIT License
Classifier: Operating System :: OS Independent
Classifier: Topic :: Software Development :: Debuggers
Description-Content-Type: text/markdown
License-File: LICENSE.txt
Requires-Dist: executing>=1.2.0
Requires-Dist: asttokens>=2.1.0
Requires-Dist: pure_eval
Provides-Extra: tests
Requires-Dist: pytest; extra == "tests"
Requires-Dist: typeguard; extra == "tests"
Requires-Dist: pygments; extra == "tests"
Requires-Dist: littleutils; extra == "tests"
Requires-Dist: cython; extra == "tests"
# stack_data
[](https://github.com/alexmojaki/stack_data/actions/workflows/pytest.yml) [](https://coveralls.io/github/alexmojaki/stack_data?branch=master) [](https://pypi.python.org/pypi/stack_data)
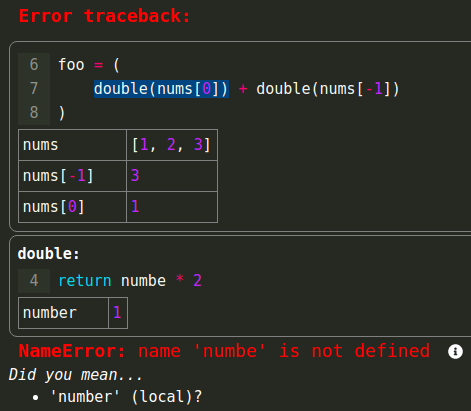
This is a library that extracts data from stack frames and tracebacks, particularly to display more useful tracebacks than the default. It powers the tracebacks in IPython and [futurecoder](https://futurecoder.io/):
You can install it from PyPI:
pip install stack_data
## Basic usage
Here's some code we'd like to inspect:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
row.append(i * j)
return result
```
Note that `foo` calls a function `print_stack()`. In reality we can imagine that an exception was raised at this line, or a debugger stopped there, but this is easy to play with directly. Here's a basic implementation:
```python
import inspect
import stack_data
def print_stack():
frame = inspect.currentframe().f_back
frame_info = stack_data.FrameInfo(frame)
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
(Beware that this has a major bug - it doesn't account for line gaps, which we'll learn about later)
The output of one call to `print_stack()` looks like:
```
foo at line 9
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(row)
--> 9 | print_stack()
10 | for j in range(5):
```
The code for `print_stack()` is fairly self-explanatory. If you want to learn more details about a particular class or method I suggest looking through some docstrings. `FrameInfo` is a class that accepts either a frame or a traceback object and provides a bunch of nice attributes and properties (which are cached so you don't need to worry about performance). In particular `frame_info.lines` is a list of `Line` objects. `line.render()` returns the source code of that line suitable for display. Without any arguments it simply strips any common leading indentation. Later on we'll see a more powerful use for it.
You can see that `frame_info.lines` includes some lines of surrounding context. By default it includes 3 pieces of context before the main line and 1 piece after. We can configure the amount of context by passing options:
```python
options = stack_data.Options(before=1, after=0)
frame_info = stack_data.FrameInfo(frame, options)
```
Then the output looks like:
```
foo at line 9
-----------
8 | result.append(row)
--> 9 | print_stack()
```
Note that these parameters are not the number of *lines* before and after to include, but the number of *pieces*. A piece is a range of one or more lines in a file that should logically be grouped together. A piece contains either a single simple statement or a part of a compound statement (loops, if, try/except, etc) that doesn't contain any other statements. Most pieces are a single line, but a multi-line statement or `if` condition is a single piece. In the example above, all pieces are one line, because nothing is spread across multiple lines. If we change our code to include some multiline bits:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(
row
)
print_stack()
for j in range(
5
):
row.append(i * j)
return result
```
and then run the original code with the default options, then the output is:
```
foo at line 11
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(
9 | row
10 | )
--> 11 | print_stack()
12 | for j in range(
13 | 5
14 | ):
```
Now lines 8-10 and lines 12-14 are each a single piece. Note that the output is essentially the same as the original in terms of the amount of code. The division of files into pieces means that the edge of the context is intuitive and doesn't crop out parts of statements or expressions. For example, if context was measured in lines instead of pieces, the last line of the above would be `for j in range(` which is much less useful.
However, if a piece is very long, including all of it could be cumbersome. For this, `Options` has a parameter `max_lines_per_piece`, which is 6 by default. Suppose we have a piece in our code that's longer than that:
```python
row = [
1,
2,
3,
4,
5,
]
```
`frame_info.lines` will truncate this piece so that instead of 7 `Line` objects it will produce 5 `Line` objects and one `LINE_GAP` in the middle, making 6 objects in total for the piece. Our code doesn't currently handle gaps, so it will raise an exception. We can modify it like so:
```python
for line in frame_info.lines:
if line is stack_data.LINE_GAP:
print(" (...)")
else:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
Now the output looks like:
```
foo at line 15
-----------
6 | for i in range(5):
7 | row = [
8 | 1,
9 | 2,
(...)
12 | 5,
13 | ]
14 | result.append(row)
--> 15 | print_stack()
16 | for j in range(5):
```
Alternatively, you can flip the condition around and check `if isinstance(line, stack_data.Line):`. Either way, you should always check for line gaps, or your code may appear to work at first but fail when it encounters a long piece.
Note that the executing piece, i.e. the piece containing the current line being executed (line 15 in this case) is never truncated, no matter how long it is.
The lines of context never stray outside `frame_info.scope`, which is the innermost function or class definition containing the current line. For example, this is the output for a short function which has neither 3 lines before nor 1 line after the current line:
```
bar at line 6
-----------
4 | def bar():
5 | foo()
--> 6 | print_stack()
```
Sometimes it's nice to ensure that the function signature is always showing. This can be done with `Options(include_signature=True)`. The result looks like this:
```
foo at line 14
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
13 | result.append(row)
--> 14 | print_stack()
15 | for j in range(5):
```
To avoid wasting space, pieces never start or end with a blank line, and blank lines between pieces are excluded. So if our code looks like this:
```python
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
```
The output doesn't change much, except you can see jumps in the line numbers:
```
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
## Variables
You can also inspect variables and other expressions in a frame, e.g:
```python
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
```
which may output:
```python
result = [[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]
i = 4
row = []
j = 4
```
`frame_info.variables` returns a list of `Variable` objects, which have attributes `name`, `value`, and `nodes`, which is a list of all AST representing that expression.
A `Variable` may refer to an expression other than a simple variable name. It can be any expression evaluated by the library [`pure_eval`](https://github.com/alexmojaki/pure_eval) which it deems 'interesting' (see those docs for more info). This includes expressions like `foo.bar` or `foo[bar]`. In these cases `name` is the source code of that expression. `pure_eval` ensures that it only evaluates expressions that won't have any side effects, e.g. where `foo.bar` is a normal attribute rather than a descriptor such as a property.
`frame_info.variables` is a list of all the interesting expressions found in `frame_info.scope`, e.g. the current function, which may include expressions not visible in `frame_info.lines`. You can restrict the list by using `frame_info.variables_in_lines` or even `frame_info.variables_in_executing_piece`. For more control you can use `frame_info.variables_by_lineno`. See the docstrings for more information.
## Rendering lines with ranges and markers
Sometimes you may want to insert special characters into the text for display purposes, e.g. HTML or ANSI color codes. `stack_data` provides a few tools to make this easier.
Let's say we have a `Line` object where `line.text` (the original raw source code of that line) is `"foo = bar"`, so `line.text[6:9]` is `"bar"`, and we want to emphasise that part by inserting HTML at positions 6 and 9 in the text. Here's how we can do that directly:
```python
markers = [
stack_data.MarkerInLine(position=6, is_start=True, string=""),
stack_data.MarkerInLine(position=9, is_start=False, string=""),
]
line.render(markers) # returns "foo = bar"
```
Here `is_start=True` indicates that the marker is the first of a pair. This helps `line.render()` sort and insert the markers correctly so you don't end up with malformed HTML like `foo.bar` where tags overlap.
Since we're inserting HTML, we should actually use `line.render(markers, escape_html=True)` which will escape special HTML characters in the Python source (but not the markers) so for example `foo = bar < spam` would be rendered as `foo = bar < spam`.
Usually though you wouldn't create markers directly yourself. Instead you would start with one or more ranges and then convert them, like so:
```python
ranges = [
stack_data.RangeInLine(start=0, end=3, data="foo"),
stack_data.RangeInLine(start=6, end=9, data="bar"),
]
def convert_ranges(r):
if r.data == "bar":
return "", ""
# This results in `markers` being the same as in the above example.
markers = stack_data.markers_from_ranges(ranges, convert_ranges)
```
`RangeInLine` has a `data` attribute which can be any object. `markers_from_ranges` accepts a converter function to which it passes all the `RangeInLine` objects. If the converter function returns a pair of strings, it creates two markers from them. Otherwise it should return `None` to indicate that the range should be ignored, as with the first range containing `"foo"` in this example.
The reason this is useful is because there are built in tools to create these ranges for you. For example, if we change our `print_stack()` function to contain this:
```python
def convert_variable_ranges(r):
variable, _node = r.data
return f'', ''
markers = stack_data.markers_from_ranges(line.variable_ranges, convert_variable_ranges)
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render(markers, escape_html=True)}")
```
Then the output becomes:
```
foo at line 15
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
`line.variable_ranges` is a list of RangeInLines for each Variable that appears at least partially in this line. The data attribute of the range is a pair `(variable, node)` where node is the particular AST node from the list `variable.nodes` that corresponds to this range.
You can also use `line.token_ranges` (e.g. if you want to do your own syntax highlighting) or `line.executing_node_ranges` if you want to highlight the currently executing node identified by the [`executing`](https://github.com/alexmojaki/executing) library. Or if you want to make your own range from an AST node, use `line.range_from_node(node, data)`. See the docstrings for more info.
### Syntax highlighting with Pygments
If you'd like pretty colored text without the work, you can let [Pygments](https://pygments.org/) do it for you. Just follow these steps:
1. `pip install pygments` separately as it's not a dependency of `stack_data`.
2. Create a pygments formatter object such as `HtmlFormatter` or `Terminal256Formatter`.
3. Pass the formatter to `Options` in the argument `pygments_formatter`.
4. Use `line.render(pygmented=True)` to get your formatted text. In this case you can't pass any markers to `render`.
If you want, you can also highlight the executing node in the frame in combination with the pygments syntax highlighting. For this you will need:
1. A pygments style - either a style class or a string that names it. See the [documentation on styles](https://pygments.org/docs/styles/) and the [styles gallery](https://blog.yjl.im/2015/08/pygments-styles-gallery.html).
2. A modification to make to the style for the executing node, which is a string such as `"bold"` or `"bg:#ffff00"` (yellow background). See the [documentation on style rules](https://pygments.org/docs/styles/#style-rules).
3. Pass these two things to `stack_data.style_with_executing_node(style, modifier)` to get a new style class.
4. Pass the new style to your formatter when you create it.
Note that this doesn't work with `TerminalFormatter` which just uses the basic ANSI colors and doesn't use the style passed to it in general.
## Getting the full stack
Currently `print_stack()` doesn't actually print the stack, it just prints one frame. Instead of `frame_info = FrameInfo(frame, options)`, let's do this:
```python
for frame_info in FrameInfo.stack_data(frame, options):
```
Now the output looks something like this:
```
at line 18
-----------
14 | for j in range(5):
15 | row.append(i * j)
16 | return result
--> 18 | bar()
bar at line 5
-----------
4 | def bar():
--> 5 | foo()
foo at line 13
-----------
10 | for i in range(5):
11 | row = []
12 | result.append(row)
--> 13 | print_stack()
14 | for j in range(5):
```
However, just as `frame_info.lines` doesn't always yield `Line` objects, `FrameInfo.stack_data` doesn't always yield `FrameInfo` objects, and we must modify our code to handle that. Let's look at some different sample code:
```python
def factorial(x):
return x * factorial(x - 1)
try:
print(factorial(5))
except:
print_stack()
```
In this code we've forgotten to include a base case in our `factorial` function so it will fail with a `RecursionError` and there'll be many frames with similar information. Similar to the built in Python traceback, `stack_data` avoids showing all of these frames. Instead you will get a `RepeatedFrames` object which summarises the information. See its docstring for more details.
Here is our updated implementation:
```python
def print_stack():
for frame_info in FrameInfo.stack_data(sys.exc_info()[2]):
if isinstance(frame_info, FrameInfo):
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
print()
else:
print(f"... {frame_info.description} ...\n")
```
And the output:
```
at line 9
-----------
4 | def factorial(x):
5 | return x * factorial(x - 1)
8 | try:
--> 9 | print(factorial(5))
10 | except:
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 5
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 4
... factorial at line 5 (996 times) ...
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = -993
```
In addition to handling repeated frames, we've passed a traceback object to `FrameInfo.stack_data` instead of a frame.
If you want, you can pass `collapse_repeated_frames=False` to `FrameInfo.stack_data` (not to `Options`) and it will just yield `FrameInfo` objects for the full stack.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1645874304.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/README.md��������������������������������������������������������������������������0000644�0001750�0001750�00000041442�14206406200�013600� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# stack_data
[](https://github.com/alexmojaki/stack_data/actions/workflows/pytest.yml) [](https://coveralls.io/github/alexmojaki/stack_data?branch=master) [](https://pypi.python.org/pypi/stack_data)
This is a library that extracts data from stack frames and tracebacks, particularly to display more useful tracebacks than the default. It powers the tracebacks in IPython and [futurecoder](https://futurecoder.io/):

You can install it from PyPI:
pip install stack_data
## Basic usage
Here's some code we'd like to inspect:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
row.append(i * j)
return result
```
Note that `foo` calls a function `print_stack()`. In reality we can imagine that an exception was raised at this line, or a debugger stopped there, but this is easy to play with directly. Here's a basic implementation:
```python
import inspect
import stack_data
def print_stack():
frame = inspect.currentframe().f_back
frame_info = stack_data.FrameInfo(frame)
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
(Beware that this has a major bug - it doesn't account for line gaps, which we'll learn about later)
The output of one call to `print_stack()` looks like:
```
foo at line 9
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(row)
--> 9 | print_stack()
10 | for j in range(5):
```
The code for `print_stack()` is fairly self-explanatory. If you want to learn more details about a particular class or method I suggest looking through some docstrings. `FrameInfo` is a class that accepts either a frame or a traceback object and provides a bunch of nice attributes and properties (which are cached so you don't need to worry about performance). In particular `frame_info.lines` is a list of `Line` objects. `line.render()` returns the source code of that line suitable for display. Without any arguments it simply strips any common leading indentation. Later on we'll see a more powerful use for it.
You can see that `frame_info.lines` includes some lines of surrounding context. By default it includes 3 pieces of context before the main line and 1 piece after. We can configure the amount of context by passing options:
```python
options = stack_data.Options(before=1, after=0)
frame_info = stack_data.FrameInfo(frame, options)
```
Then the output looks like:
```
foo at line 9
-----------
8 | result.append(row)
--> 9 | print_stack()
```
Note that these parameters are not the number of *lines* before and after to include, but the number of *pieces*. A piece is a range of one or more lines in a file that should logically be grouped together. A piece contains either a single simple statement or a part of a compound statement (loops, if, try/except, etc) that doesn't contain any other statements. Most pieces are a single line, but a multi-line statement or `if` condition is a single piece. In the example above, all pieces are one line, because nothing is spread across multiple lines. If we change our code to include some multiline bits:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(
row
)
print_stack()
for j in range(
5
):
row.append(i * j)
return result
```
and then run the original code with the default options, then the output is:
```
foo at line 11
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(
9 | row
10 | )
--> 11 | print_stack()
12 | for j in range(
13 | 5
14 | ):
```
Now lines 8-10 and lines 12-14 are each a single piece. Note that the output is essentially the same as the original in terms of the amount of code. The division of files into pieces means that the edge of the context is intuitive and doesn't crop out parts of statements or expressions. For example, if context was measured in lines instead of pieces, the last line of the above would be `for j in range(` which is much less useful.
However, if a piece is very long, including all of it could be cumbersome. For this, `Options` has a parameter `max_lines_per_piece`, which is 6 by default. Suppose we have a piece in our code that's longer than that:
```python
row = [
1,
2,
3,
4,
5,
]
```
`frame_info.lines` will truncate this piece so that instead of 7 `Line` objects it will produce 5 `Line` objects and one `LINE_GAP` in the middle, making 6 objects in total for the piece. Our code doesn't currently handle gaps, so it will raise an exception. We can modify it like so:
```python
for line in frame_info.lines:
if line is stack_data.LINE_GAP:
print(" (...)")
else:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
Now the output looks like:
```
foo at line 15
-----------
6 | for i in range(5):
7 | row = [
8 | 1,
9 | 2,
(...)
12 | 5,
13 | ]
14 | result.append(row)
--> 15 | print_stack()
16 | for j in range(5):
```
Alternatively, you can flip the condition around and check `if isinstance(line, stack_data.Line):`. Either way, you should always check for line gaps, or your code may appear to work at first but fail when it encounters a long piece.
Note that the executing piece, i.e. the piece containing the current line being executed (line 15 in this case) is never truncated, no matter how long it is.
The lines of context never stray outside `frame_info.scope`, which is the innermost function or class definition containing the current line. For example, this is the output for a short function which has neither 3 lines before nor 1 line after the current line:
```
bar at line 6
-----------
4 | def bar():
5 | foo()
--> 6 | print_stack()
```
Sometimes it's nice to ensure that the function signature is always showing. This can be done with `Options(include_signature=True)`. The result looks like this:
```
foo at line 14
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
13 | result.append(row)
--> 14 | print_stack()
15 | for j in range(5):
```
To avoid wasting space, pieces never start or end with a blank line, and blank lines between pieces are excluded. So if our code looks like this:
```python
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
```
The output doesn't change much, except you can see jumps in the line numbers:
```
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
## Variables
You can also inspect variables and other expressions in a frame, e.g:
```python
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
```
which may output:
```python
result = [[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]
i = 4
row = []
j = 4
```
`frame_info.variables` returns a list of `Variable` objects, which have attributes `name`, `value`, and `nodes`, which is a list of all AST representing that expression.
A `Variable` may refer to an expression other than a simple variable name. It can be any expression evaluated by the library [`pure_eval`](https://github.com/alexmojaki/pure_eval) which it deems 'interesting' (see those docs for more info). This includes expressions like `foo.bar` or `foo[bar]`. In these cases `name` is the source code of that expression. `pure_eval` ensures that it only evaluates expressions that won't have any side effects, e.g. where `foo.bar` is a normal attribute rather than a descriptor such as a property.
`frame_info.variables` is a list of all the interesting expressions found in `frame_info.scope`, e.g. the current function, which may include expressions not visible in `frame_info.lines`. You can restrict the list by using `frame_info.variables_in_lines` or even `frame_info.variables_in_executing_piece`. For more control you can use `frame_info.variables_by_lineno`. See the docstrings for more information.
## Rendering lines with ranges and markers
Sometimes you may want to insert special characters into the text for display purposes, e.g. HTML or ANSI color codes. `stack_data` provides a few tools to make this easier.
Let's say we have a `Line` object where `line.text` (the original raw source code of that line) is `"foo = bar"`, so `line.text[6:9]` is `"bar"`, and we want to emphasise that part by inserting HTML at positions 6 and 9 in the text. Here's how we can do that directly:
```python
markers = [
stack_data.MarkerInLine(position=6, is_start=True, string=""),
stack_data.MarkerInLine(position=9, is_start=False, string=""),
]
line.render(markers) # returns "foo = bar"
```
Here `is_start=True` indicates that the marker is the first of a pair. This helps `line.render()` sort and insert the markers correctly so you don't end up with malformed HTML like `foo.bar` where tags overlap.
Since we're inserting HTML, we should actually use `line.render(markers, escape_html=True)` which will escape special HTML characters in the Python source (but not the markers) so for example `foo = bar < spam` would be rendered as `foo = bar < spam`.
Usually though you wouldn't create markers directly yourself. Instead you would start with one or more ranges and then convert them, like so:
```python
ranges = [
stack_data.RangeInLine(start=0, end=3, data="foo"),
stack_data.RangeInLine(start=6, end=9, data="bar"),
]
def convert_ranges(r):
if r.data == "bar":
return "", ""
# This results in `markers` being the same as in the above example.
markers = stack_data.markers_from_ranges(ranges, convert_ranges)
```
`RangeInLine` has a `data` attribute which can be any object. `markers_from_ranges` accepts a converter function to which it passes all the `RangeInLine` objects. If the converter function returns a pair of strings, it creates two markers from them. Otherwise it should return `None` to indicate that the range should be ignored, as with the first range containing `"foo"` in this example.
The reason this is useful is because there are built in tools to create these ranges for you. For example, if we change our `print_stack()` function to contain this:
```python
def convert_variable_ranges(r):
variable, _node = r.data
return f'', ''
markers = stack_data.markers_from_ranges(line.variable_ranges, convert_variable_ranges)
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render(markers, escape_html=True)}")
```
Then the output becomes:
```
foo at line 15
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
`line.variable_ranges` is a list of RangeInLines for each Variable that appears at least partially in this line. The data attribute of the range is a pair `(variable, node)` where node is the particular AST node from the list `variable.nodes` that corresponds to this range.
You can also use `line.token_ranges` (e.g. if you want to do your own syntax highlighting) or `line.executing_node_ranges` if you want to highlight the currently executing node identified by the [`executing`](https://github.com/alexmojaki/executing) library. Or if you want to make your own range from an AST node, use `line.range_from_node(node, data)`. See the docstrings for more info.
### Syntax highlighting with Pygments
If you'd like pretty colored text without the work, you can let [Pygments](https://pygments.org/) do it for you. Just follow these steps:
1. `pip install pygments` separately as it's not a dependency of `stack_data`.
2. Create a pygments formatter object such as `HtmlFormatter` or `Terminal256Formatter`.
3. Pass the formatter to `Options` in the argument `pygments_formatter`.
4. Use `line.render(pygmented=True)` to get your formatted text. In this case you can't pass any markers to `render`.
If you want, you can also highlight the executing node in the frame in combination with the pygments syntax highlighting. For this you will need:
1. A pygments style - either a style class or a string that names it. See the [documentation on styles](https://pygments.org/docs/styles/) and the [styles gallery](https://blog.yjl.im/2015/08/pygments-styles-gallery.html).
2. A modification to make to the style for the executing node, which is a string such as `"bold"` or `"bg:#ffff00"` (yellow background). See the [documentation on style rules](https://pygments.org/docs/styles/#style-rules).
3. Pass these two things to `stack_data.style_with_executing_node(style, modifier)` to get a new style class.
4. Pass the new style to your formatter when you create it.
Note that this doesn't work with `TerminalFormatter` which just uses the basic ANSI colors and doesn't use the style passed to it in general.
## Getting the full stack
Currently `print_stack()` doesn't actually print the stack, it just prints one frame. Instead of `frame_info = FrameInfo(frame, options)`, let's do this:
```python
for frame_info in FrameInfo.stack_data(frame, options):
```
Now the output looks something like this:
```
at line 18
-----------
14 | for j in range(5):
15 | row.append(i * j)
16 | return result
--> 18 | bar()
bar at line 5
-----------
4 | def bar():
--> 5 | foo()
foo at line 13
-----------
10 | for i in range(5):
11 | row = []
12 | result.append(row)
--> 13 | print_stack()
14 | for j in range(5):
```
However, just as `frame_info.lines` doesn't always yield `Line` objects, `FrameInfo.stack_data` doesn't always yield `FrameInfo` objects, and we must modify our code to handle that. Let's look at some different sample code:
```python
def factorial(x):
return x * factorial(x - 1)
try:
print(factorial(5))
except:
print_stack()
```
In this code we've forgotten to include a base case in our `factorial` function so it will fail with a `RecursionError` and there'll be many frames with similar information. Similar to the built in Python traceback, `stack_data` avoids showing all of these frames. Instead you will get a `RepeatedFrames` object which summarises the information. See its docstring for more details.
Here is our updated implementation:
```python
def print_stack():
for frame_info in FrameInfo.stack_data(sys.exc_info()[2]):
if isinstance(frame_info, FrameInfo):
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
print()
else:
print(f"... {frame_info.description} ...\n")
```
And the output:
```
at line 9
-----------
4 | def factorial(x):
5 | return x * factorial(x - 1)
8 | try:
--> 9 | print(factorial(5))
10 | except:
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 5
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 4
... factorial at line 5 (996 times) ...
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = -993
```
In addition to handling repeated frames, we've passed a traceback object to `FrameInfo.stack_data` instead of a frame.
If you want, you can pass `collapse_repeated_frames=False` to `FrameInfo.stack_data` (not to `Options`) and it will just yield `FrameInfo` objects for the full stack.
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1669579965.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/make_release.sh��������������������������������������������������������������������0000775�0001750�0001750�00000001144�14340742275�015310� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
set -eux
# Ensure that there are no uncommitted changes
# which would mess up using the git tag as a version
[ -z "$(git status --porcelain)" ]
if [ -z "${1+x}" ]
then
set +x
echo Provide a version argument
echo "${0} .."
exit 1
else
if [[ ${1} =~ ^([0-9]+)(\.[0-9]+)?(\.[0-9]+)?$ ]]; then
:
else
echo "Not a valid release tag."
exit 1
fi
fi
tox -p 3
export TAG="v${1}"
git tag "${TAG}"
git push origin master "${TAG}"
rm -rf ./build ./dist
python -m build --sdist --wheel .
twine upload ./dist/*.whl dist/*.tar.gz
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1618742186.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/pyproject.toml���������������������������������������������������������������������0000644�0001750�0001750�00000000351�14037005652�015237� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������[build-system]
requires = ["setuptools>=44", "wheel", "setuptools_scm[toml]>=3.4.3"]
build-backend = "setuptools.build_meta"
[tool.setuptools_scm]
write_to = "stack_data/version.py"
write_to_template = "__version__ = '{version}'\n"
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4631362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/setup.cfg��������������������������������������������������������������������������0000664�0001750�0001750�00000002345�14506024532�014152� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������[metadata]
name = stack_data
author = Alex Hall
author_email = alex.mojaki@gmail.com
license = MIT
description = Extract data from python stack frames and tracebacks for informative displays
url = http://github.com/alexmojaki/stack_data
long_description = file: README.md
long_description_content_type = text/markdown
classifiers =
Intended Audience :: Developers
Programming Language :: Python :: 3.5
Programming Language :: Python :: 3.6
Programming Language :: Python :: 3.7
Programming Language :: Python :: 3.8
Programming Language :: Python :: 3.9
Programming Language :: Python :: 3.10
Programming Language :: Python :: 3.11
Programming Language :: Python :: 3.12
License :: OSI Approved :: MIT License
Operating System :: OS Independent
Topic :: Software Development :: Debuggers
[options]
packages = stack_data
install_requires =
executing>=1.2.0
asttokens>=2.1.0
pure_eval
setup_requires = setuptools>=44; setuptools_scm[toml]>=3.4.3
include_package_data = True
tests_require = pytest; typeguard; pygments; littleutils
[options.extras_require]
tests = pytest; typeguard; pygments; littleutils; cython
[coverage:run]
relative_files = True
[options.package_data]
stack_data = py.typed
[egg_info]
tag_build =
tag_date = 0
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1618742186.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/setup.py���������������������������������������������������������������������������0000644�0001750�0001750�00000000105�14037005652�014032� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������from setuptools import setup
if __name__ == "__main__":
setup()
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000033�00000000000�010211� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������27 mtime=1696082266.451136
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/������������������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�014423� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1661606046.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/__init__.py�������������������������������������������������������������0000664�0001750�0001750�00000000643�14302414236�016535� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������from .core import Source, FrameInfo, markers_from_ranges, Options, LINE_GAP, Line, Variable, RangeInLine, \
RepeatedFrames, MarkerInLine, style_with_executing_node, BlankLineRange, BlankLines
from .formatting import Formatter
from .serializing import Serializer
try:
from .version import __version__
except ImportError:
# version.py is auto-generated with the git tag when building
__version__ = "???"
���������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1669579937.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/core.py�����������������������������������������������������������������0000664�0001750�0001750�00000101113�14340742241�015722� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import ast
import html
import os
import sys
from collections import defaultdict, Counter
from enum import Enum
from textwrap import dedent
from types import FrameType, CodeType, TracebackType
from typing import (
Iterator, List, Tuple, Optional, NamedTuple,
Any, Iterable, Callable, Union,
Sequence)
from typing import Mapping
import executing
from asttokens.util import Token
from executing import only
from pure_eval import Evaluator, is_expression_interesting
from stack_data.utils import (
truncate, unique_in_order, line_range,
frame_and_lineno, iter_stack, collapse_repeated, group_by_key_func,
cached_property, is_frame, _pygmented_with_ranges, assert_)
RangeInLine = NamedTuple('RangeInLine',
[('start', int),
('end', int),
('data', Any)])
RangeInLine.__doc__ = """
Represents a range of characters within one line of source code,
and some associated data.
Typically this will be converted to a pair of markers by markers_from_ranges.
"""
MarkerInLine = NamedTuple('MarkerInLine',
[('position', int),
('is_start', bool),
('string', str)])
MarkerInLine.__doc__ = """
A string that is meant to be inserted at a given position in a line of source code.
For example, this could be an ANSI code or the opening or closing of an HTML tag.
is_start should be True if this is the first of a pair such as the opening of an HTML tag.
This will help to sort and insert markers correctly.
Typically this would be created from a RangeInLine by markers_from_ranges.
Then use Line.render to insert the markers correctly.
"""
class BlankLines(Enum):
"""The values are intended to correspond to the following behaviour:
HIDDEN: blank lines are not shown in the output
VISIBLE: blank lines are visible in the output
SINGLE: any consecutive blank lines are shown as a single blank line
in the output. This option requires the line number to be shown.
For a single blank line, the corresponding line number is shown.
Two or more consecutive blank lines are shown as a single blank
line in the output with a custom string shown instead of a
specific line number.
"""
HIDDEN = 1
VISIBLE = 2
SINGLE=3
class Variable(
NamedTuple('_Variable',
[('name', str),
('nodes', Sequence[ast.AST]),
('value', Any)])
):
"""
An expression that appears one or more times in source code and its associated value.
This will usually be a variable but it can be any expression evaluated by pure_eval.
- name is the source text of the expression.
- nodes is a list of equivalent nodes representing the same expression.
- value is the safely evaluated value of the expression.
"""
__hash__ = object.__hash__
__eq__ = object.__eq__
class Source(executing.Source):
"""
The source code of a single file and associated metadata.
In addition to the attributes from the base class executing.Source,
if .tree is not None, meaning this is valid Python code, objects have:
- pieces: a list of Piece objects
- tokens_by_lineno: a defaultdict(list) mapping line numbers to lists of tokens.
Don't construct this class. Get an instance from frame_info.source.
"""
@cached_property
def pieces(self) -> List[range]:
if not self.tree:
return [
range(i, i + 1)
for i in range(1, len(self.lines) + 1)
]
return list(self._clean_pieces())
@cached_property
def tokens_by_lineno(self) -> Mapping[int, List[Token]]:
if not self.tree:
raise AttributeError("This file doesn't contain valid Python, so .tokens_by_lineno doesn't exist")
return group_by_key_func(
self.asttokens().tokens,
lambda tok: tok.start[0],
)
def _clean_pieces(self) -> Iterator[range]:
pieces = self._raw_split_into_pieces(self.tree, 1, len(self.lines) + 1)
pieces = [
(start, end)
for (start, end) in pieces
if end > start
]
# Combine overlapping pieces, i.e. consecutive pieces where the end of the first
# is greater than the start of the second.
# This can happen when two statements are on the same line separated by a semicolon.
new_pieces = pieces[:1]
for (start, end) in pieces[1:]:
(last_start, last_end) = new_pieces[-1]
if start < last_end:
assert start == last_end - 1
assert ';' in self.lines[start - 1]
new_pieces[-1] = (last_start, end)
else:
new_pieces.append((start, end))
pieces = new_pieces
starts = [start for start, end in pieces[1:]]
ends = [end for start, end in pieces[:-1]]
if starts != ends:
joins = list(map(set, zip(starts, ends)))
mismatches = [s for s in joins if len(s) > 1]
raise AssertionError("Pieces mismatches: %s" % mismatches)
def is_blank(i):
try:
return not self.lines[i - 1].strip()
except IndexError:
return False
for start, end in pieces:
while is_blank(start):
start += 1
while is_blank(end - 1):
end -= 1
if start < end:
yield range(start, end)
def _raw_split_into_pieces(
self,
stmt: ast.AST,
start: int,
end: int,
) -> Iterator[Tuple[int, int]]:
for name, body in ast.iter_fields(stmt):
if (
isinstance(body, list) and body and
isinstance(body[0], (ast.stmt, ast.ExceptHandler, getattr(ast, 'match_case', ())))
):
for rang, group in sorted(group_by_key_func(body, self.line_range).items()):
sub_stmt = group[0]
for inner_start, inner_end in self._raw_split_into_pieces(sub_stmt, *rang):
if start < inner_start:
yield start, inner_start
if inner_start < inner_end:
yield inner_start, inner_end
start = inner_end
yield start, end
def line_range(self, node: ast.AST) -> Tuple[int, int]:
return line_range(self.asttext(), node)
class Options:
"""
Configuration for FrameInfo, either in the constructor or the .stack_data classmethod.
These all determine which Lines and gaps are produced by FrameInfo.lines.
before and after are the number of pieces of context to include in a frame
in addition to the executing piece.
include_signature is whether to include the function signature as a piece in a frame.
If a piece (other than the executing piece) has more than max_lines_per_piece lines,
it will be truncated with a gap in the middle.
"""
def __init__(
self, *,
before: int = 3,
after: int = 1,
include_signature: bool = False,
max_lines_per_piece: int = 6,
pygments_formatter=None,
blank_lines = BlankLines.HIDDEN
):
self.before = before
self.after = after
self.include_signature = include_signature
self.max_lines_per_piece = max_lines_per_piece
self.pygments_formatter = pygments_formatter
self.blank_lines = blank_lines
def __repr__(self):
keys = sorted(self.__dict__)
items = ("{}={!r}".format(k, self.__dict__[k]) for k in keys)
return "{}({})".format(type(self).__name__, ", ".join(items))
class LineGap(object):
"""
A singleton representing one or more lines of source code that were skipped
in FrameInfo.lines.
LINE_GAP can be created in two ways:
- by truncating a piece of context that's too long.
- immediately after the signature piece if Options.include_signature is true
and the following piece isn't already part of the included pieces.
"""
def __repr__(self):
return "LINE_GAP"
LINE_GAP = LineGap()
class BlankLineRange:
"""
Records the line number range for blank lines gaps between pieces.
For a single blank line, begin_lineno == end_lineno.
"""
def __init__(self, begin_lineno: int, end_lineno: int):
self.begin_lineno = begin_lineno
self.end_lineno = end_lineno
class Line(object):
"""
A single line of source code for a particular stack frame.
Typically this is obtained from FrameInfo.lines.
Since that list may also contain LINE_GAP, you should first check
that this is really a Line before using it.
Attributes:
- frame_info
- lineno: the 1-based line number within the file
- text: the raw source of this line. For displaying text, see .render() instead.
- leading_indent: the number of leading spaces that should probably be stripped.
This attribute is set within FrameInfo.lines. If you construct this class
directly you should probably set it manually (at least to 0).
- is_current: whether this is the line currently being executed by the interpreter
within this frame.
- tokens: a list of source tokens in this line
There are several helpers for constructing RangeInLines which can be converted to markers
using markers_from_ranges which can be passed to .render():
- token_ranges
- variable_ranges
- executing_node_ranges
- range_from_node
"""
def __init__(
self,
frame_info: 'FrameInfo',
lineno: int,
):
self.frame_info = frame_info
self.lineno = lineno
self.text = frame_info.source.lines[lineno - 1] # type: str
self.leading_indent = None # type: Optional[int]
def __repr__(self):
return "<{self.__class__.__name__} {self.lineno} (current={self.is_current}) " \
"{self.text!r} of {self.frame_info.filename}>".format(self=self)
@property
def is_current(self) -> bool:
"""
Whether this is the line currently being executed by the interpreter
within this frame.
"""
return self.lineno == self.frame_info.lineno
@property
def tokens(self) -> List[Token]:
"""
A list of source tokens in this line.
The tokens are Token objects from asttokens:
https://asttokens.readthedocs.io/en/latest/api-index.html#asttokens.util.Token
"""
return self.frame_info.source.tokens_by_lineno[self.lineno]
@cached_property
def token_ranges(self) -> List[RangeInLine]:
"""
A list of RangeInLines for each token in .tokens,
where range.data is a Token object from asttokens:
https://asttokens.readthedocs.io/en/latest/api-index.html#asttokens.util.Token
"""
return [
RangeInLine(
token.start[1],
token.end[1],
token,
)
for token in self.tokens
]
@cached_property
def variable_ranges(self) -> List[RangeInLine]:
"""
A list of RangeInLines for each Variable that appears at least partially in this line.
The data attribute of the range is a pair (variable, node) where node is the particular
AST node from the list variable.nodes that corresponds to this range.
"""
return [
self.range_from_node(node, (variable, node))
for variable, node in self.frame_info.variables_by_lineno[self.lineno]
]
@cached_property
def executing_node_ranges(self) -> List[RangeInLine]:
"""
A list of one or zero RangeInLines for the executing node of this frame.
The list will have one element if the node can be found and it overlaps this line.
"""
return self._raw_executing_node_ranges(
self.frame_info._executing_node_common_indent
)
def _raw_executing_node_ranges(self, common_indent=0) -> List[RangeInLine]:
ex = self.frame_info.executing
node = ex.node
if node:
rang = self.range_from_node(node, ex, common_indent)
if rang:
return [rang]
return []
def range_from_node(
self, node: ast.AST, data: Any, common_indent: int = 0
) -> Optional[RangeInLine]:
"""
If the given node overlaps with this line, return a RangeInLine
with the correct start and end and the given data.
Otherwise, return None.
"""
atext = self.frame_info.source.asttext()
(start, range_start), (end, range_end) = atext.get_text_positions(node, padded=False)
if not (start <= self.lineno <= end):
return None
if start != self.lineno:
range_start = common_indent
if end != self.lineno:
range_end = len(self.text)
if range_start == range_end == 0:
# This is an empty line. If it were included, it would result
# in a value of zero for the common indentation assigned to
# a block of code.
return None
return RangeInLine(range_start, range_end, data)
def render(
self,
markers: Iterable[MarkerInLine] = (),
*,
strip_leading_indent: bool = True,
pygmented: bool = False,
escape_html: bool = False
) -> str:
"""
Produces a string for display consisting of .text
with the .strings of each marker inserted at the correct positions.
If strip_leading_indent is true (the default) then leading spaces
common to all lines in this frame will be excluded.
"""
if pygmented and self.frame_info.scope:
assert_(not markers, ValueError("Cannot use pygmented with markers"))
start_line, lines = self.frame_info._pygmented_scope_lines
result = lines[self.lineno - start_line]
if strip_leading_indent:
result = result.replace(self.text[:self.leading_indent], "", 1)
return result
text = self.text
# This just makes the loop below simpler
markers = list(markers) + [MarkerInLine(position=len(text), is_start=False, string='')]
markers.sort(key=lambda t: t[:2])
parts = []
if strip_leading_indent:
start = self.leading_indent
else:
start = 0
original_start = start
for marker in markers:
text_part = text[start:marker.position]
if escape_html:
text_part = html.escape(text_part)
parts.append(text_part)
parts.append(marker.string)
# Ensure that start >= leading_indent
start = max(marker.position, original_start)
return ''.join(parts)
def markers_from_ranges(
ranges: Iterable[RangeInLine],
converter: Callable[[RangeInLine], Optional[Tuple[str, str]]],
) -> List[MarkerInLine]:
"""
Helper to create MarkerInLines given some RangeInLines.
converter should be a function accepting a RangeInLine returning
either None (which is ignored) or a pair of strings which
are used to create two markers included in the returned list.
"""
markers = []
for rang in ranges:
converted = converter(rang)
if converted is None:
continue
start_string, end_string = converted
if not (isinstance(start_string, str) and isinstance(end_string, str)):
raise TypeError("converter should return None or a pair of strings")
markers += [
MarkerInLine(position=rang.start, is_start=True, string=start_string),
MarkerInLine(position=rang.end, is_start=False, string=end_string),
]
return markers
def style_with_executing_node(style, modifier):
from pygments.styles import get_style_by_name
if isinstance(style, str):
style = get_style_by_name(style)
class NewStyle(style):
for_executing_node = True
styles = {
**style.styles,
**{
k.ExecutingNode: v + " " + modifier
for k, v in style.styles.items()
}
}
return NewStyle
class RepeatedFrames:
"""
A sequence of consecutive stack frames which shouldn't be displayed because
the same code and line number were repeated many times in the stack, e.g.
because of deep recursion.
Attributes:
- frames: list of raw frame or traceback objects
- frame_keys: list of tuples (frame.f_code, lineno) extracted from the frame objects.
It's this information from the frames that is used to determine
whether two frames should be considered similar (i.e. repeating).
- description: A string briefly describing frame_keys
"""
def __init__(
self,
frames: List[Union[FrameType, TracebackType]],
frame_keys: List[Tuple[CodeType, int]],
):
self.frames = frames
self.frame_keys = frame_keys
@cached_property
def description(self) -> str:
"""
A string briefly describing the repeated frames, e.g.
my_function at line 10 (100 times)
"""
counts = sorted(Counter(self.frame_keys).items(),
key=lambda item: (-item[1], item[0][0].co_name))
return ', '.join(
'{name} at line {lineno} ({count} times)'.format(
name=Source.for_filename(code.co_filename).code_qualname(code),
lineno=lineno,
count=count,
)
for (code, lineno), count in counts
)
def __repr__(self):
return '<{self.__class__.__name__} {self.description}>'.format(self=self)
class FrameInfo(object):
"""
Information about a frame!
Pass either a frame object or a traceback object,
and optionally an Options object to configure.
Or use the classmethod FrameInfo.stack_data() for an iterator of FrameInfo and
RepeatedFrames objects.
Attributes:
- frame: an actual stack frame object, either frame_or_tb or frame_or_tb.tb_frame
- options
- code: frame.f_code
- source: a Source object
- filename: a hopefully absolute file path derived from code.co_filename
- scope: the AST node of the innermost function, class or module being executed
- lines: a list of Line/LineGap objects to display, determined by options
- executing: an Executing object from the `executing` library, which has:
- .node: the AST node being executed in this frame, or None if it's unknown
- .statements: a set of one or more candidate statements (AST nodes, probably just one)
currently being executed in this frame.
- .code_qualname(): the __qualname__ of the function or class being executed,
or just the code name.
Properties returning one or more pieces of source code (ranges of lines):
- scope_pieces: all the pieces in the scope
- included_pieces: a subset of scope_pieces determined by options
- executing_piece: the piece currently being executed in this frame
Properties returning lists of Variable objects:
- variables: all variables in the scope
- variables_by_lineno: variables organised into lines
- variables_in_lines: variables contained within FrameInfo.lines
- variables_in_executing_piece: variables contained within FrameInfo.executing_piece
"""
def __init__(
self,
frame_or_tb: Union[FrameType, TracebackType],
options: Optional[Options] = None,
):
self.executing = Source.executing(frame_or_tb)
frame, self.lineno = frame_and_lineno(frame_or_tb)
self.frame = frame
self.code = frame.f_code
self.options = options or Options() # type: Options
self.source = self.executing.source # type: Source
def __repr__(self):
return "{self.__class__.__name__}({self.frame})".format(self=self)
@classmethod
def stack_data(
cls,
frame_or_tb: Union[FrameType, TracebackType],
options: Optional[Options] = None,
*,
collapse_repeated_frames: bool = True
) -> Iterator[Union['FrameInfo', RepeatedFrames]]:
"""
An iterator of FrameInfo and RepeatedFrames objects representing
a full traceback or stack. Similar consecutive frames are collapsed into RepeatedFrames
objects, so always check what type of object has been yielded.
Pass either a frame object or a traceback object,
and optionally an Options object to configure.
"""
stack = list(iter_stack(frame_or_tb))
# Reverse the stack from a frame so that it's in the same order
# as the order from a traceback, which is the order of a printed
# traceback when read top to bottom (most recent call last)
if is_frame(frame_or_tb):
stack = stack[::-1]
def mapper(f):
return cls(f, options)
if not collapse_repeated_frames:
yield from map(mapper, stack)
return
def _frame_key(x):
frame, lineno = frame_and_lineno(x)
return frame.f_code, lineno
yield from collapse_repeated(
stack,
mapper=mapper,
collapser=RepeatedFrames,
key=_frame_key,
)
@cached_property
def scope_pieces(self) -> List[range]:
"""
All the pieces (ranges of lines) contained in this object's .scope,
unless there is no .scope (because the source isn't valid Python syntax)
in which case it returns all the pieces in the source file, each containing one line.
"""
if not self.scope:
return self.source.pieces
scope_start, scope_end = self.source.line_range(self.scope)
return [
piece
for piece in self.source.pieces
if scope_start <= piece.start and piece.stop <= scope_end
]
@cached_property
def filename(self) -> str:
"""
A hopefully absolute file path derived from .code.co_filename,
the current working directory, and sys.path.
Code based on ipython.
"""
result = self.code.co_filename
if (
os.path.isabs(result) or
(
result.startswith("<") and
result.endswith(">")
)
):
return result
# Try to make the filename absolute by trying all
# sys.path entries (which is also what linecache does)
# as well as the current working directory
for dirname in ["."] + list(sys.path):
try:
fullname = os.path.join(dirname, result)
if os.path.isfile(fullname):
return os.path.abspath(fullname)
except Exception:
# Just in case that sys.path contains very
# strange entries...
pass
return result
@cached_property
def executing_piece(self) -> range:
"""
The piece (range of lines) containing the line currently being executed
by the interpreter in this frame.
"""
return only(
piece
for piece in self.scope_pieces
if self.lineno in piece
)
@cached_property
def included_pieces(self) -> List[range]:
"""
The list of pieces (ranges of lines) to display for this frame.
Consists of .executing_piece, surrounding context pieces
determined by .options.before and .options.after,
and the function signature if a function is being executed and
.options.include_signature is True (in which case this might not
be a contiguous range of pieces).
Always a subset of .scope_pieces.
"""
scope_pieces = self.scope_pieces
if not self.scope_pieces:
return []
pos = scope_pieces.index(self.executing_piece)
pieces_start = max(0, pos - self.options.before)
pieces_end = pos + 1 + self.options.after
pieces = scope_pieces[pieces_start:pieces_end]
if (
self.options.include_signature
and not self.code.co_name.startswith('<')
and isinstance(self.scope, (ast.FunctionDef, ast.AsyncFunctionDef))
and pieces_start > 0
):
pieces.insert(0, scope_pieces[0])
return pieces
@cached_property
def _executing_node_common_indent(self) -> int:
"""
The common minimal indentation shared by the markers intended
for an exception node that spans multiple lines.
Intended to be used only internally.
"""
indents = []
lines = [line for line in self.lines if isinstance(line, Line)]
for line in lines:
for rang in line._raw_executing_node_ranges():
begin_text = len(line.text) - len(line.text.lstrip())
indent = max(rang.start, begin_text)
indents.append(indent)
if len(indents) <= 1:
return 0
return min(indents[1:])
@cached_property
def lines(self) -> List[Union[Line, LineGap, BlankLineRange]]:
"""
A list of lines to display, determined by options.
The objects yielded either have type Line, BlankLineRange
or are the singleton LINE_GAP.
Always check the type that you're dealing with when iterating.
LINE_GAP can be created in two ways:
- by truncating a piece of context that's too long, determined by
.options.max_lines_per_piece
- immediately after the signature piece if Options.include_signature is true
and the following piece isn't already part of the included pieces.
The Line objects are all within the ranges from .included_pieces.
"""
pieces = self.included_pieces
if not pieces:
return []
add_empty_lines = self.options.blank_lines in (BlankLines.VISIBLE, BlankLines.SINGLE)
prev_piece = None
result = []
for i, piece in enumerate(pieces):
if (
i == 1
and self.scope
and pieces[0] == self.scope_pieces[0]
and pieces[1] != self.scope_pieces[1]
):
result.append(LINE_GAP)
elif prev_piece and add_empty_lines and piece.start > prev_piece.stop:
if self.options.blank_lines == BlankLines.SINGLE:
result.append(BlankLineRange(prev_piece.stop, piece.start-1))
else: # BlankLines.VISIBLE
for lineno in range(prev_piece.stop, piece.start):
result.append(Line(self, lineno))
lines = [Line(self, i) for i in piece] # type: List[Line]
if piece != self.executing_piece:
lines = truncate(
lines,
max_length=self.options.max_lines_per_piece,
middle=[LINE_GAP],
)
result.extend(lines)
prev_piece = piece
real_lines = [
line
for line in result
if isinstance(line, Line)
]
text = "\n".join(
line.text
for line in real_lines
)
dedented_lines = dedent(text).splitlines()
leading_indent = len(real_lines[0].text) - len(dedented_lines[0])
for line in real_lines:
line.leading_indent = leading_indent
return result
@cached_property
def scope(self) -> Optional[ast.AST]:
"""
The AST node of the innermost function, class or module being executed.
"""
if not self.source.tree or not self.executing.statements:
return None
stmt = list(self.executing.statements)[0]
while True:
# Get the parent first in case the original statement is already
# a function definition, e.g. if we're calling a decorator
# In that case we still want the surrounding scope, not that function
stmt = stmt.parent
if isinstance(stmt, (ast.FunctionDef, ast.AsyncFunctionDef, ast.ClassDef, ast.Module)):
return stmt
@cached_property
def _pygmented_scope_lines(self) -> Optional[Tuple[int, List[str]]]:
# noinspection PyUnresolvedReferences
from pygments.formatters import HtmlFormatter
formatter = self.options.pygments_formatter
scope = self.scope
assert_(formatter, ValueError("Must set a pygments formatter in Options"))
assert_(scope)
if isinstance(formatter, HtmlFormatter):
formatter.nowrap = True
atext = self.source.asttext()
node = self.executing.node
if node and getattr(formatter.style, "for_executing_node", False):
scope_start = atext.get_text_range(scope)[0]
start, end = atext.get_text_range(node)
start -= scope_start
end -= scope_start
ranges = [(start, end)]
else:
ranges = []
code = atext.get_text(scope)
lines = _pygmented_with_ranges(formatter, code, ranges)
start_line = self.source.line_range(scope)[0]
return start_line, lines
@cached_property
def variables(self) -> List[Variable]:
"""
All Variable objects whose nodes are contained within .scope
and whose values could be safely evaluated by pure_eval.
"""
if not self.scope:
return []
evaluator = Evaluator.from_frame(self.frame)
scope = self.scope
node_values = [
pair
for pair in evaluator.find_expressions(scope)
if is_expression_interesting(*pair)
] # type: List[Tuple[ast.AST, Any]]
if isinstance(scope, (ast.FunctionDef, ast.AsyncFunctionDef)):
for node in ast.walk(scope.args):
if not isinstance(node, ast.arg):
continue
name = node.arg
try:
value = evaluator.names[name]
except KeyError:
pass
else:
node_values.append((node, value))
# Group equivalent nodes together
def get_text(n):
if isinstance(n, ast.arg):
return n.arg
else:
return self.source.asttext().get_text(n)
def normalise_node(n):
try:
# Add parens to avoid syntax errors for multiline expressions
return ast.parse('(' + get_text(n) + ')')
except Exception:
return n
grouped = group_by_key_func(
node_values,
lambda nv: ast.dump(normalise_node(nv[0])),
)
result = []
for group in grouped.values():
nodes, values = zip(*group)
value = values[0]
text = get_text(nodes[0])
if not text:
continue
result.append(Variable(text, nodes, value))
return result
@cached_property
def variables_by_lineno(self) -> Mapping[int, List[Tuple[Variable, ast.AST]]]:
"""
A mapping from 1-based line numbers to lists of pairs:
- A Variable object
- A specific AST node from the variable's .nodes list that's
in the line at that line number.
"""
result = defaultdict(list)
for var in self.variables:
for node in var.nodes:
for lineno in range(*self.source.line_range(node)):
result[lineno].append((var, node))
return result
@cached_property
def variables_in_lines(self) -> List[Variable]:
"""
A list of Variable objects contained within the lines returned by .lines.
"""
return unique_in_order(
var
for line in self.lines
if isinstance(line, Line)
for var, node in self.variables_by_lineno[line.lineno]
)
@cached_property
def variables_in_executing_piece(self) -> List[Variable]:
"""
A list of Variable objects contained within the lines
in the range returned by .executing_piece.
"""
return unique_in_order(
var
for lineno in self.executing_piece
for var, node in self.variables_by_lineno[lineno]
)
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1663662596.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/formatting.py�����������������������������������������������������������0000664�0001750�0001750�00000020474�14312275004�017153� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import inspect
import sys
import traceback
from types import FrameType, TracebackType
from typing import Union, Iterable
from stack_data import (style_with_executing_node, Options, Line, FrameInfo, LINE_GAP,
Variable, RepeatedFrames, BlankLineRange, BlankLines)
from stack_data.utils import assert_
class Formatter:
def __init__(
self, *,
options=None,
pygmented=False,
show_executing_node=True,
pygments_formatter_cls=None,
pygments_formatter_kwargs=None,
pygments_style="monokai",
executing_node_modifier="bg:#005080",
executing_node_underline="^",
current_line_indicator="-->",
line_gap_string="(...)",
line_number_gap_string=":",
line_number_format_string="{:4} | ",
show_variables=False,
use_code_qualname=True,
show_linenos=True,
strip_leading_indent=True,
html=False,
chain=True,
collapse_repeated_frames=True
):
if options is None:
options = Options()
if pygmented and not options.pygments_formatter:
if show_executing_node:
pygments_style = style_with_executing_node(
pygments_style, executing_node_modifier
)
if pygments_formatter_cls is None:
from pygments.formatters.terminal256 import Terminal256Formatter \
as pygments_formatter_cls
options.pygments_formatter = pygments_formatter_cls(
style=pygments_style,
**pygments_formatter_kwargs or {},
)
self.pygmented = pygmented
self.show_executing_node = show_executing_node
assert_(
len(executing_node_underline) == 1,
ValueError("executing_node_underline must be a single character"),
)
self.executing_node_underline = executing_node_underline
self.current_line_indicator = current_line_indicator or ""
self.line_gap_string = line_gap_string
self.line_number_gap_string = line_number_gap_string
self.line_number_format_string = line_number_format_string
self.show_variables = show_variables
self.show_linenos = show_linenos
self.use_code_qualname = use_code_qualname
self.strip_leading_indent = strip_leading_indent
self.html = html
self.chain = chain
self.options = options
self.collapse_repeated_frames = collapse_repeated_frames
if not self.show_linenos and self.options.blank_lines == BlankLines.SINGLE:
raise ValueError(
"BlankLines.SINGLE option can only be used when show_linenos=True"
)
def set_hook(self):
def excepthook(_etype, evalue, _tb):
self.print_exception(evalue)
sys.excepthook = excepthook
def print_exception(self, e=None, *, file=None):
self.print_lines(self.format_exception(e), file=file)
def print_stack(self, frame_or_tb=None, *, file=None):
if frame_or_tb is None:
frame_or_tb = inspect.currentframe().f_back
self.print_lines(self.format_stack(frame_or_tb), file=file)
def print_lines(self, lines, *, file=None):
if file is None:
file = sys.stderr
for line in lines:
print(line, file=file, end="")
def format_exception(self, e=None) -> Iterable[str]:
if e is None:
e = sys.exc_info()[1]
if self.chain:
if e.__cause__ is not None:
yield from self.format_exception(e.__cause__)
yield traceback._cause_message
elif (e.__context__ is not None
and not e.__suppress_context__):
yield from self.format_exception(e.__context__)
yield traceback._context_message
yield 'Traceback (most recent call last):\n'
yield from self.format_stack(e.__traceback__)
yield from traceback.format_exception_only(type(e), e)
def format_stack(self, frame_or_tb=None) -> Iterable[str]:
if frame_or_tb is None:
frame_or_tb = inspect.currentframe().f_back
yield from self.format_stack_data(
FrameInfo.stack_data(
frame_or_tb,
self.options,
collapse_repeated_frames=self.collapse_repeated_frames,
)
)
def format_stack_data(
self, stack: Iterable[Union[FrameInfo, RepeatedFrames]]
) -> Iterable[str]:
for item in stack:
if isinstance(item, FrameInfo):
yield from self.format_frame(item)
else:
yield self.format_repeated_frames(item)
def format_repeated_frames(self, repeated_frames: RepeatedFrames) -> str:
return ' [... skipping similar frames: {}]\n'.format(
repeated_frames.description
)
def format_frame(self, frame: Union[FrameInfo, FrameType, TracebackType]) -> Iterable[str]:
if not isinstance(frame, FrameInfo):
frame = FrameInfo(frame, self.options)
yield self.format_frame_header(frame)
for line in frame.lines:
if isinstance(line, Line):
yield self.format_line(line)
elif isinstance(line, BlankLineRange):
yield self.format_blank_lines_linenumbers(line)
else:
assert_(line is LINE_GAP)
yield self.line_gap_string + "\n"
if self.show_variables:
try:
yield from self.format_variables(frame)
except Exception:
pass
def format_frame_header(self, frame_info: FrameInfo) -> str:
return ' File "{frame_info.filename}", line {frame_info.lineno}, in {name}\n'.format(
frame_info=frame_info,
name=(
frame_info.executing.code_qualname()
if self.use_code_qualname else
frame_info.code.co_name
),
)
def format_line(self, line: Line) -> str:
result = ""
if self.current_line_indicator:
if line.is_current:
result = self.current_line_indicator
else:
result = " " * len(self.current_line_indicator)
result += " "
else:
result = " "
if self.show_linenos:
result += self.line_number_format_string.format(line.lineno)
prefix = result
result += line.render(
pygmented=self.pygmented,
escape_html=self.html,
strip_leading_indent=self.strip_leading_indent,
) + "\n"
if self.show_executing_node and not self.pygmented:
for line_range in line.executing_node_ranges:
start = line_range.start - line.leading_indent
end = line_range.end - line.leading_indent
# if end <= start, we have an empty line inside a highlighted
# block of code. In this case, we need to avoid inserting
# an extra blank line with no markers present.
if end > start:
result += (
" " * (start + len(prefix))
+ self.executing_node_underline * (end - start)
+ "\n"
)
return result
def format_blank_lines_linenumbers(self, blank_line):
if self.current_line_indicator:
result = " " * len(self.current_line_indicator) + " "
else:
result = " "
if blank_line.begin_lineno == blank_line.end_lineno:
return result + self.line_number_format_string.format(blank_line.begin_lineno) + "\n"
return result + " {}\n".format(self.line_number_gap_string)
def format_variables(self, frame_info: FrameInfo) -> Iterable[str]:
for var in sorted(frame_info.variables, key=lambda v: v.name):
try:
yield self.format_variable(var) + "\n"
except Exception:
pass
def format_variable(self, var: Variable) -> str:
return "{} = {}".format(
var.name,
self.format_variable_value(var.value),
)
def format_variable_value(self, value) -> str:
return repr(value)
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1660412237.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/py.typed����������������������������������������������������������������0000664�0001750�0001750�00000000111�14275760515�016126� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Marker file for PEP 561. The ``stack_data`` package uses inline types.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1664114683.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/serializing.py����������������������������������������������������������0000664�0001750�0001750�00000014504�14314057773�017333� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import inspect
import logging
import sys
import traceback
from collections import Counter
from html import escape as escape_html
from types import FrameType, TracebackType
from typing import Union, Iterable, List
from stack_data import (
style_with_executing_node,
Options,
Line,
FrameInfo,
Variable,
RepeatedFrames,
)
from stack_data.utils import some_str
log = logging.getLogger(__name__)
class Serializer:
def __init__(
self,
*,
options=None,
pygmented=False,
show_executing_node=True,
pygments_formatter_cls=None,
pygments_formatter_kwargs=None,
pygments_style="monokai",
executing_node_modifier="bg:#005080",
use_code_qualname=True,
strip_leading_indent=True,
html=False,
chain=True,
collapse_repeated_frames=True,
show_variables=False,
):
if options is None:
options = Options()
if pygmented and not options.pygments_formatter:
if show_executing_node:
pygments_style = style_with_executing_node(
pygments_style, executing_node_modifier
)
if pygments_formatter_cls is None:
if html:
from pygments.formatters.html import (
HtmlFormatter as pygments_formatter_cls,
)
else:
from pygments.formatters.terminal256 import (
Terminal256Formatter as pygments_formatter_cls,
)
options.pygments_formatter = pygments_formatter_cls(
style=pygments_style,
**pygments_formatter_kwargs or {},
)
self.pygmented = pygmented
self.use_code_qualname = use_code_qualname
self.strip_leading_indent = strip_leading_indent
self.html = html
self.chain = chain
self.options = options
self.collapse_repeated_frames = collapse_repeated_frames
self.show_variables = show_variables
def format_exception(self, e=None) -> List[dict]:
if e is None:
e = sys.exc_info()[1]
result = []
if self.chain:
if e.__cause__ is not None:
result = self.format_exception(e.__cause__)
result[-1]["tail"] = traceback._cause_message.strip()
elif e.__context__ is not None and not e.__suppress_context__:
result = self.format_exception(e.__context__)
result[-1]["tail"] = traceback._context_message.strip()
result.append(self.format_traceback_part(e))
return result
def format_traceback_part(self, e: BaseException) -> dict:
return dict(
frames=self.format_stack(e.__traceback__ or sys.exc_info()[2]),
exception=dict(
type=type(e).__name__,
message=some_str(e),
),
tail="",
)
def format_stack(self, frame_or_tb=None) -> List[dict]:
if frame_or_tb is None:
frame_or_tb = inspect.currentframe().f_back
return list(
self.format_stack_data(
FrameInfo.stack_data(
frame_or_tb,
self.options,
collapse_repeated_frames=self.collapse_repeated_frames,
)
)
)
def format_stack_data(
self, stack: Iterable[Union[FrameInfo, RepeatedFrames]]
) -> Iterable[dict]:
for item in stack:
if isinstance(item, FrameInfo):
if not self.should_include_frame(item):
continue
yield dict(type="frame", **self.format_frame(item))
else:
yield dict(type="repeated_frames", **self.format_repeated_frames(item))
def format_repeated_frames(self, repeated_frames: RepeatedFrames) -> dict:
counts = sorted(
Counter(repeated_frames.frame_keys).items(),
key=lambda item: (-item[1], item[0][0].co_name),
)
return dict(
frames=[
dict(
name=code.co_name,
lineno=lineno,
count=count,
)
for (code, lineno), count in counts
]
)
def format_frame(self, frame: Union[FrameInfo, FrameType, TracebackType]) -> dict:
if not isinstance(frame, FrameInfo):
frame = FrameInfo(frame, self.options)
result = dict(
name=(
frame.executing.code_qualname()
if self.use_code_qualname
else frame.code.co_name
),
filename=frame.filename,
lineno=frame.lineno,
lines=list(self.format_lines(frame.lines)),
)
if self.show_variables:
result["variables"] = list(self.format_variables(frame))
return result
def format_lines(self, lines):
for line in lines:
if isinstance(line, Line):
yield dict(type="line", **self.format_line(line))
else:
yield dict(type="line_gap")
def format_line(self, line: Line) -> dict:
return dict(
is_current=line.is_current,
lineno=line.lineno,
text=line.render(
pygmented=self.pygmented,
escape_html=self.html,
strip_leading_indent=self.strip_leading_indent,
),
)
def format_variables(self, frame_info: FrameInfo) -> Iterable[dict]:
try:
for var in sorted(frame_info.variables, key=lambda v: v.name):
yield self.format_variable(var)
except Exception: # pragma: no cover
log.exception("Error in getting frame variables")
def format_variable(self, var: Variable) -> dict:
return dict(
name=self.format_variable_part(var.name),
value=self.format_variable_part(self.format_variable_value(var.value)),
)
def format_variable_part(self, text):
if self.html:
return escape_html(text)
else:
return text
def format_variable_value(self, value) -> str:
return repr(value)
def should_include_frame(self, frame_info: FrameInfo) -> bool:
return True # pragma: no cover
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/utils.py����������������������������������������������������������������0000664�0001750�0001750�00000013412�14506010626�016135� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import ast
import itertools
import types
from collections import OrderedDict, Counter, defaultdict
from types import FrameType, TracebackType
from typing import (
Iterator, List, Tuple, Iterable, Callable, Union,
TypeVar, Mapping,
)
from asttokens import ASTText
T = TypeVar('T')
R = TypeVar('R')
def truncate(seq, max_length: int, middle):
if len(seq) > max_length:
right = (max_length - len(middle)) // 2
left = max_length - len(middle) - right
seq = seq[:left] + middle + seq[-right:]
return seq
def unique_in_order(it: Iterable[T]) -> List[T]:
return list(OrderedDict.fromkeys(it))
def line_range(atok: ASTText, node: ast.AST) -> Tuple[int, int]:
"""
Returns a pair of numbers representing a half open range
(i.e. suitable as arguments to the `range()` builtin)
of line numbers of the given AST nodes.
"""
if isinstance(node, getattr(ast, "match_case", ())):
start, _end = line_range(atok, node.pattern)
_start, end = line_range(atok, node.body[-1])
return start, end
else:
(start, _), (end, _) = atok.get_text_positions(node, padded=False)
return start, end + 1
def highlight_unique(lst: List[T]) -> Iterator[Tuple[T, bool]]:
counts = Counter(lst)
for is_common, group in itertools.groupby(lst, key=lambda x: counts[x] > 3):
if is_common:
group = list(group)
highlighted = [False] * len(group)
def highlight_index(f):
try:
i = f()
except ValueError:
return None
highlighted[i] = True
return i
for item in set(group):
first = highlight_index(lambda: group.index(item))
if first is not None:
highlight_index(lambda: group.index(item, first + 1))
highlight_index(lambda: -1 - group[::-1].index(item))
else:
highlighted = itertools.repeat(True)
yield from zip(group, highlighted)
def identity(x: T) -> T:
return x
def collapse_repeated(lst, *, collapser, mapper=identity, key=identity):
keyed = list(map(key, lst))
for is_highlighted, group in itertools.groupby(
zip(lst, highlight_unique(keyed)),
key=lambda t: t[1][1],
):
original_group, highlighted_group = zip(*group)
if is_highlighted:
yield from map(mapper, original_group)
else:
keyed_group, _ = zip(*highlighted_group)
yield collapser(list(original_group), list(keyed_group))
def is_frame(frame_or_tb: Union[FrameType, TracebackType]) -> bool:
assert_(isinstance(frame_or_tb, (types.FrameType, types.TracebackType)))
return isinstance(frame_or_tb, (types.FrameType,))
def iter_stack(frame_or_tb: Union[FrameType, TracebackType]) -> Iterator[Union[FrameType, TracebackType]]:
current: Union[FrameType, TracebackType, None] = frame_or_tb
while current:
yield current
if is_frame(current):
current = current.f_back
else:
current = current.tb_next
def frame_and_lineno(frame_or_tb: Union[FrameType, TracebackType]) -> Tuple[FrameType, int]:
if is_frame(frame_or_tb):
return frame_or_tb, frame_or_tb.f_lineno
else:
return frame_or_tb.tb_frame, frame_or_tb.tb_lineno
def group_by_key_func(iterable: Iterable[T], key_func: Callable[[T], R]) -> Mapping[R, List[T]]:
# noinspection PyUnresolvedReferences
"""
Create a dictionary from an iterable such that the keys are the result of evaluating a key function on elements
of the iterable and the values are lists of elements all of which correspond to the key.
>>> def si(d): return sorted(d.items())
>>> si(group_by_key_func("a bb ccc d ee fff".split(), len))
[(1, ['a', 'd']), (2, ['bb', 'ee']), (3, ['ccc', 'fff'])]
>>> si(group_by_key_func([-1, 0, 1, 3, 6, 8, 9, 2], lambda x: x % 2))
[(0, [0, 6, 8, 2]), (1, [-1, 1, 3, 9])]
"""
result = defaultdict(list)
for item in iterable:
result[key_func(item)].append(item)
return result
class cached_property(object):
"""
A property that is only computed once per instance and then replaces itself
with an ordinary attribute. Deleting the attribute resets the property.
Based on https://github.com/pydanny/cached-property/blob/master/cached_property.py
"""
def __init__(self, func):
self.__doc__ = func.__doc__
self.func = func
def cached_property_wrapper(self, obj, _cls):
if obj is None:
return self
value = obj.__dict__[self.func.__name__] = self.func(obj)
return value
__get__ = cached_property_wrapper
def _pygmented_with_ranges(formatter, code, ranges):
import pygments
from pygments.lexers import get_lexer_by_name
class MyLexer(type(get_lexer_by_name("python3"))):
def get_tokens(self, text):
length = 0
for ttype, value in super().get_tokens(text):
if any(start <= length < end for start, end in ranges):
ttype = ttype.ExecutingNode
length += len(value)
yield ttype, value
lexer = MyLexer(stripnl=False)
try:
highlighted = pygments.highlight(code, lexer, formatter)
except Exception:
# When pygments fails, prefer code without highlighting over crashing
highlighted = code
return highlighted.splitlines()
def assert_(condition, error=""):
if not condition:
if isinstance(error, str):
error = AssertionError(error)
raise error
# Copied from the standard traceback module pre-3.11
def some_str(value):
try:
return str(value)
except:
return '' % type(value).__name__
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data/version.py��������������������������������������������������������������0000644�0001750�0001750�00000000026�14506024532�016456� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������__version__ = '0.6.3'
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000033�00000000000�010211� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������27 mtime=1696082266.451136
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/���������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�016115� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/PKG-INFO�������������������������������������������������������0000644�0001750�0001750�00000044001�14506024532�017207� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Metadata-Version: 2.1
Name: stack-data
Version: 0.6.3
Summary: Extract data from python stack frames and tracebacks for informative displays
Home-page: http://github.com/alexmojaki/stack_data
Author: Alex Hall
Author-email: alex.mojaki@gmail.com
License: MIT
Classifier: Intended Audience :: Developers
Classifier: Programming Language :: Python :: 3.5
Classifier: Programming Language :: Python :: 3.6
Classifier: Programming Language :: Python :: 3.7
Classifier: Programming Language :: Python :: 3.8
Classifier: Programming Language :: Python :: 3.9
Classifier: Programming Language :: Python :: 3.10
Classifier: Programming Language :: Python :: 3.11
Classifier: Programming Language :: Python :: 3.12
Classifier: License :: OSI Approved :: MIT License
Classifier: Operating System :: OS Independent
Classifier: Topic :: Software Development :: Debuggers
Description-Content-Type: text/markdown
License-File: LICENSE.txt
Requires-Dist: executing>=1.2.0
Requires-Dist: asttokens>=2.1.0
Requires-Dist: pure_eval
Provides-Extra: tests
Requires-Dist: pytest; extra == "tests"
Requires-Dist: typeguard; extra == "tests"
Requires-Dist: pygments; extra == "tests"
Requires-Dist: littleutils; extra == "tests"
Requires-Dist: cython; extra == "tests"
# stack_data
[](https://github.com/alexmojaki/stack_data/actions/workflows/pytest.yml) [](https://coveralls.io/github/alexmojaki/stack_data?branch=master) [](https://pypi.python.org/pypi/stack_data)
This is a library that extracts data from stack frames and tracebacks, particularly to display more useful tracebacks than the default. It powers the tracebacks in IPython and [futurecoder](https://futurecoder.io/):

You can install it from PyPI:
pip install stack_data
## Basic usage
Here's some code we'd like to inspect:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
row.append(i * j)
return result
```
Note that `foo` calls a function `print_stack()`. In reality we can imagine that an exception was raised at this line, or a debugger stopped there, but this is easy to play with directly. Here's a basic implementation:
```python
import inspect
import stack_data
def print_stack():
frame = inspect.currentframe().f_back
frame_info = stack_data.FrameInfo(frame)
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
(Beware that this has a major bug - it doesn't account for line gaps, which we'll learn about later)
The output of one call to `print_stack()` looks like:
```
foo at line 9
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(row)
--> 9 | print_stack()
10 | for j in range(5):
```
The code for `print_stack()` is fairly self-explanatory. If you want to learn more details about a particular class or method I suggest looking through some docstrings. `FrameInfo` is a class that accepts either a frame or a traceback object and provides a bunch of nice attributes and properties (which are cached so you don't need to worry about performance). In particular `frame_info.lines` is a list of `Line` objects. `line.render()` returns the source code of that line suitable for display. Without any arguments it simply strips any common leading indentation. Later on we'll see a more powerful use for it.
You can see that `frame_info.lines` includes some lines of surrounding context. By default it includes 3 pieces of context before the main line and 1 piece after. We can configure the amount of context by passing options:
```python
options = stack_data.Options(before=1, after=0)
frame_info = stack_data.FrameInfo(frame, options)
```
Then the output looks like:
```
foo at line 9
-----------
8 | result.append(row)
--> 9 | print_stack()
```
Note that these parameters are not the number of *lines* before and after to include, but the number of *pieces*. A piece is a range of one or more lines in a file that should logically be grouped together. A piece contains either a single simple statement or a part of a compound statement (loops, if, try/except, etc) that doesn't contain any other statements. Most pieces are a single line, but a multi-line statement or `if` condition is a single piece. In the example above, all pieces are one line, because nothing is spread across multiple lines. If we change our code to include some multiline bits:
```python
def foo():
result = []
for i in range(5):
row = []
result.append(
row
)
print_stack()
for j in range(
5
):
row.append(i * j)
return result
```
and then run the original code with the default options, then the output is:
```
foo at line 11
-----------
6 | for i in range(5):
7 | row = []
8 | result.append(
9 | row
10 | )
--> 11 | print_stack()
12 | for j in range(
13 | 5
14 | ):
```
Now lines 8-10 and lines 12-14 are each a single piece. Note that the output is essentially the same as the original in terms of the amount of code. The division of files into pieces means that the edge of the context is intuitive and doesn't crop out parts of statements or expressions. For example, if context was measured in lines instead of pieces, the last line of the above would be `for j in range(` which is much less useful.
However, if a piece is very long, including all of it could be cumbersome. For this, `Options` has a parameter `max_lines_per_piece`, which is 6 by default. Suppose we have a piece in our code that's longer than that:
```python
row = [
1,
2,
3,
4,
5,
]
```
`frame_info.lines` will truncate this piece so that instead of 7 `Line` objects it will produce 5 `Line` objects and one `LINE_GAP` in the middle, making 6 objects in total for the piece. Our code doesn't currently handle gaps, so it will raise an exception. We can modify it like so:
```python
for line in frame_info.lines:
if line is stack_data.LINE_GAP:
print(" (...)")
else:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
```
Now the output looks like:
```
foo at line 15
-----------
6 | for i in range(5):
7 | row = [
8 | 1,
9 | 2,
(...)
12 | 5,
13 | ]
14 | result.append(row)
--> 15 | print_stack()
16 | for j in range(5):
```
Alternatively, you can flip the condition around and check `if isinstance(line, stack_data.Line):`. Either way, you should always check for line gaps, or your code may appear to work at first but fail when it encounters a long piece.
Note that the executing piece, i.e. the piece containing the current line being executed (line 15 in this case) is never truncated, no matter how long it is.
The lines of context never stray outside `frame_info.scope`, which is the innermost function or class definition containing the current line. For example, this is the output for a short function which has neither 3 lines before nor 1 line after the current line:
```
bar at line 6
-----------
4 | def bar():
5 | foo()
--> 6 | print_stack()
```
Sometimes it's nice to ensure that the function signature is always showing. This can be done with `Options(include_signature=True)`. The result looks like this:
```
foo at line 14
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
13 | result.append(row)
--> 14 | print_stack()
15 | for j in range(5):
```
To avoid wasting space, pieces never start or end with a blank line, and blank lines between pieces are excluded. So if our code looks like this:
```python
for i in range(5):
row = []
result.append(row)
print_stack()
for j in range(5):
```
The output doesn't change much, except you can see jumps in the line numbers:
```
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
## Variables
You can also inspect variables and other expressions in a frame, e.g:
```python
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
```
which may output:
```python
result = [[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12], []]
i = 4
row = []
j = 4
```
`frame_info.variables` returns a list of `Variable` objects, which have attributes `name`, `value`, and `nodes`, which is a list of all AST representing that expression.
A `Variable` may refer to an expression other than a simple variable name. It can be any expression evaluated by the library [`pure_eval`](https://github.com/alexmojaki/pure_eval) which it deems 'interesting' (see those docs for more info). This includes expressions like `foo.bar` or `foo[bar]`. In these cases `name` is the source code of that expression. `pure_eval` ensures that it only evaluates expressions that won't have any side effects, e.g. where `foo.bar` is a normal attribute rather than a descriptor such as a property.
`frame_info.variables` is a list of all the interesting expressions found in `frame_info.scope`, e.g. the current function, which may include expressions not visible in `frame_info.lines`. You can restrict the list by using `frame_info.variables_in_lines` or even `frame_info.variables_in_executing_piece`. For more control you can use `frame_info.variables_by_lineno`. See the docstrings for more information.
## Rendering lines with ranges and markers
Sometimes you may want to insert special characters into the text for display purposes, e.g. HTML or ANSI color codes. `stack_data` provides a few tools to make this easier.
Let's say we have a `Line` object where `line.text` (the original raw source code of that line) is `"foo = bar"`, so `line.text[6:9]` is `"bar"`, and we want to emphasise that part by inserting HTML at positions 6 and 9 in the text. Here's how we can do that directly:
```python
markers = [
stack_data.MarkerInLine(position=6, is_start=True, string=""),
stack_data.MarkerInLine(position=9, is_start=False, string=""),
]
line.render(markers) # returns "foo = bar"
```
Here `is_start=True` indicates that the marker is the first of a pair. This helps `line.render()` sort and insert the markers correctly so you don't end up with malformed HTML like `foo.bar` where tags overlap.
Since we're inserting HTML, we should actually use `line.render(markers, escape_html=True)` which will escape special HTML characters in the Python source (but not the markers) so for example `foo = bar < spam` would be rendered as `foo = bar < spam`.
Usually though you wouldn't create markers directly yourself. Instead you would start with one or more ranges and then convert them, like so:
```python
ranges = [
stack_data.RangeInLine(start=0, end=3, data="foo"),
stack_data.RangeInLine(start=6, end=9, data="bar"),
]
def convert_ranges(r):
if r.data == "bar":
return "", ""
# This results in `markers` being the same as in the above example.
markers = stack_data.markers_from_ranges(ranges, convert_ranges)
```
`RangeInLine` has a `data` attribute which can be any object. `markers_from_ranges` accepts a converter function to which it passes all the `RangeInLine` objects. If the converter function returns a pair of strings, it creates two markers from them. Otherwise it should return `None` to indicate that the range should be ignored, as with the first range containing `"foo"` in this example.
The reason this is useful is because there are built in tools to create these ranges for you. For example, if we change our `print_stack()` function to contain this:
```python
def convert_variable_ranges(r):
variable, _node = r.data
return f'', ''
markers = stack_data.markers_from_ranges(line.variable_ranges, convert_variable_ranges)
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render(markers, escape_html=True)}")
```
Then the output becomes:
```
foo at line 15
-----------
9 | def foo():
(...)
11 | for i in range(5):
12 | row = []
14 | result.append(row)
--> 15 | print_stack()
17 | for j in range(5):
```
`line.variable_ranges` is a list of RangeInLines for each Variable that appears at least partially in this line. The data attribute of the range is a pair `(variable, node)` where node is the particular AST node from the list `variable.nodes` that corresponds to this range.
You can also use `line.token_ranges` (e.g. if you want to do your own syntax highlighting) or `line.executing_node_ranges` if you want to highlight the currently executing node identified by the [`executing`](https://github.com/alexmojaki/executing) library. Or if you want to make your own range from an AST node, use `line.range_from_node(node, data)`. See the docstrings for more info.
### Syntax highlighting with Pygments
If you'd like pretty colored text without the work, you can let [Pygments](https://pygments.org/) do it for you. Just follow these steps:
1. `pip install pygments` separately as it's not a dependency of `stack_data`.
2. Create a pygments formatter object such as `HtmlFormatter` or `Terminal256Formatter`.
3. Pass the formatter to `Options` in the argument `pygments_formatter`.
4. Use `line.render(pygmented=True)` to get your formatted text. In this case you can't pass any markers to `render`.
If you want, you can also highlight the executing node in the frame in combination with the pygments syntax highlighting. For this you will need:
1. A pygments style - either a style class or a string that names it. See the [documentation on styles](https://pygments.org/docs/styles/) and the [styles gallery](https://blog.yjl.im/2015/08/pygments-styles-gallery.html).
2. A modification to make to the style for the executing node, which is a string such as `"bold"` or `"bg:#ffff00"` (yellow background). See the [documentation on style rules](https://pygments.org/docs/styles/#style-rules).
3. Pass these two things to `stack_data.style_with_executing_node(style, modifier)` to get a new style class.
4. Pass the new style to your formatter when you create it.
Note that this doesn't work with `TerminalFormatter` which just uses the basic ANSI colors and doesn't use the style passed to it in general.
## Getting the full stack
Currently `print_stack()` doesn't actually print the stack, it just prints one frame. Instead of `frame_info = FrameInfo(frame, options)`, let's do this:
```python
for frame_info in FrameInfo.stack_data(frame, options):
```
Now the output looks something like this:
```
at line 18
-----------
14 | for j in range(5):
15 | row.append(i * j)
16 | return result
--> 18 | bar()
bar at line 5
-----------
4 | def bar():
--> 5 | foo()
foo at line 13
-----------
10 | for i in range(5):
11 | row = []
12 | result.append(row)
--> 13 | print_stack()
14 | for j in range(5):
```
However, just as `frame_info.lines` doesn't always yield `Line` objects, `FrameInfo.stack_data` doesn't always yield `FrameInfo` objects, and we must modify our code to handle that. Let's look at some different sample code:
```python
def factorial(x):
return x * factorial(x - 1)
try:
print(factorial(5))
except:
print_stack()
```
In this code we've forgotten to include a base case in our `factorial` function so it will fail with a `RecursionError` and there'll be many frames with similar information. Similar to the built in Python traceback, `stack_data` avoids showing all of these frames. Instead you will get a `RepeatedFrames` object which summarises the information. See its docstring for more details.
Here is our updated implementation:
```python
def print_stack():
for frame_info in FrameInfo.stack_data(sys.exc_info()[2]):
if isinstance(frame_info, FrameInfo):
print(f"{frame_info.code.co_name} at line {frame_info.lineno}")
print("-----------")
for line in frame_info.lines:
print(f"{'-->' if line.is_current else ' '} {line.lineno:4} | {line.render()}")
for var in frame_info.variables:
print(f"{var.name} = {repr(var.value)}")
print()
else:
print(f"... {frame_info.description} ...\n")
```
And the output:
```
at line 9
-----------
4 | def factorial(x):
5 | return x * factorial(x - 1)
8 | try:
--> 9 | print(factorial(5))
10 | except:
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 5
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = 4
... factorial at line 5 (996 times) ...
factorial at line 5
-----------
4 | def factorial(x):
--> 5 | return x * factorial(x - 1)
x = -993
```
In addition to handling repeated frames, we've passed a traceback object to `FrameInfo.stack_data` instead of a frame.
If you want, you can pass `collapse_repeated_frames=False` to `FrameInfo.stack_data` (not to `Options`) and it will just yield `FrameInfo` objects for the full stack.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/SOURCES.txt����������������������������������������������������0000644�0001750�0001750�00000003333�14506024532�020001� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������.gitignore
LICENSE.txt
MANIFEST.in
README.md
make_release.sh
pyproject.toml
setup.cfg
setup.py
tox.ini
.github/workflows/pytest.yml
stack_data/__init__.py
stack_data/core.py
stack_data/formatting.py
stack_data/py.typed
stack_data/serializing.py
stack_data/utils.py
stack_data/version.py
stack_data.egg-info/PKG-INFO
stack_data.egg-info/SOURCES.txt
stack_data.egg-info/dependency_links.txt
stack_data.egg-info/requires.txt
stack_data.egg-info/top_level.txt
tests/__init__.py
tests/test_core.py
tests/test_formatter.py
tests/test_serializer.py
tests/test_utils.py
tests/utils.py
tests/golden_files/blank_invisible_no_linenos.txt
tests/golden_files/blank_single.txt
tests/golden_files/blank_visible.txt
tests/golden_files/blank_visible_no_linenos.txt
tests/golden_files/blank_visible_with_linenos_no_current_line_indicator.txt
tests/golden_files/block_left_new.txt
tests/golden_files/block_left_old.txt
tests/golden_files/block_right_new.txt
tests/golden_files/block_right_old.txt
tests/golden_files/cython_example.txt
tests/golden_files/f_string_3.8.txt
tests/golden_files/f_string_new.txt
tests/golden_files/f_string_old.txt
tests/golden_files/format_frame.txt
tests/golden_files/format_stack.txt
tests/golden_files/linenos_no_current_line_indicator.txt
tests/golden_files/plain.txt
tests/golden_files/print_stack.txt
tests/golden_files/pygmented.txt
tests/golden_files/pygmented_error.txt
tests/golden_files/serialize.json
tests/golden_files/single_option_linenos_no_current_line_indicator.txt
tests/golden_files/variables.txt
tests/samples/__init__.py
tests/samples/cython_example.pyx
tests/samples/example.py
tests/samples/formatter_example.py
tests/samples/not_code.txt
tests/samples/pieces.py
tests/samples/pygments_example.py
tests/samples/to_exec.py�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/dependency_links.txt�������������������������������������������0000644�0001750�0001750�00000000001�14506024532�022161� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/requires.txt���������������������������������������������������0000644�0001750�0001750�00000000142�14506024532�020510� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������executing>=1.2.0
asttokens>=2.1.0
pure_eval
[tests]
pytest
typeguard
pygments
littleutils
cython
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696082266.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/stack_data.egg-info/top_level.txt��������������������������������������������������0000644�0001750�0001750�00000000013�14506024532�020637� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000033�00000000000�010211� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������27 mtime=1696082266.451136
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/�����������������������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�013467� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/__init__.py������������������������������������������������������������������0000664�0001750�0001750�00000000432�14506010626�015576� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import os
import pyximport
try:
from typeguard import install_import_hook
except ImportError:
from typeguard.importhook import install_import_hook
pyximport.install(language_level=3)
if not os.environ.get("STACK_DATA_SLOW_TESTS"):
install_import_hook(["stack_data"])
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4591362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/����������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�016121� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/blank_invisible_no_linenos.txt����������������������������������0000664�0001750�0001750�00000000357�14506007111�024237� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
def blank_lines():
a = [1, 2, 3]
length = len(a)
return a[length]
^^^^^^^^^
IndexError: list index out of range
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/blank_single.txt������������������������������������������������0000664�0001750�0001750�00000000454�14506007111�021307� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
79 | def blank_lines():
80 | a = [1, 2, 3]
81 |
82 | length = len(a)
:
--> 85 | return a[length]
^^^^^^^^^
IndexError: list index out of range
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/blank_visible.txt�����������������������������������������������0000664�0001750�0001750�00000000473�14506007111�021464� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
79 | def blank_lines():
80 | a = [1, 2, 3]
81 |
82 | length = len(a)
83 |
84 |
--> 85 | return a[length]
^^^^^^^^^
IndexError: list index out of range
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/blank_visible_no_linenos.txt������������������������������������0000664�0001750�0001750�00000000373�14506007111�023706� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
def blank_lines():
a = [1, 2, 3]
length = len(a)
return a[length]
^^^^^^^^^
IndexError: list index out of range
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/blank_visible_with_linenos_no_current_line_indicator.txt��������0000664�0001750�0001750�00000000463�14506007111�031546� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
79 | def blank_lines():
80 | a = [1, 2, 3]
81 |
82 | length = len(a)
83 |
84 |
85 | return a[length]
^^^^^^^^^
IndexError: list index out of range
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/block_left_new.txt����������������������������������������������0000664�0001750�0001750�00000000712�14506007111�021631� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 72, in block_left
71 | def block_left():
--> 72 | nb_characters = len(letter
^^^^^^^^^^
73 | for letter
^^^^^^^^^^
74 |
75 | in
^^^^
76 | "words")
^^^^^^^^
TypeError: object of type 'generator' has no len()
������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075113.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/block_left_old.txt����������������������������������������������0000664�0001750�0001750�00000000712�14506006551�021625� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 76, in block_left
71 | def block_left():
72 | nb_characters = len(letter
^^^^^^^^^^
73 | for letter
^^^^^^^^^^
74 |
75 | in
^^^^
--> 76 | "words")
^^^^^^^^
TypeError: object of type 'generator' has no len()
������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/block_right_new.txt���������������������������������������������0000664�0001750�0001750�00000000652�14506007111�022017� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 65, in block_right
64 | def block_right():
--> 65 | nb = len(letter
^^^^^^^^^^
66 | for letter
^^^^^^^^^^
67 | in
^^^^
68 | "words")
^^^^^^^^
TypeError: object of type 'generator' has no len()
��������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075113.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/block_right_old.txt���������������������������������������������0000664�0001750�0001750�00000000652�14506006551�022013� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 68, in block_right
64 | def block_right():
65 | nb = len(letter
^^^^^^^^^^
66 | for letter
^^^^^^^^^^
67 | in
^^^^
--> 68 | "words")
^^^^^^^^
TypeError: object of type 'generator' has no len()
��������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/cython_example.txt����������������������������������������������0000664�0001750�0001750�00000000533�14506007111�021674� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "cython_example.pyx", line 2, in tests.samples.cython_example.foo
1 | def foo():
--> 2 | bar()
3 |
File "cython_example.pyx", line 5, in tests.samples.cython_example.bar
2 | bar()
3 |
4 | cdef bar():
--> 5 | raise ValueError("bar!")
ValueError: bar!
���������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696074589.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/f_string_3.8.txt������������������������������������������������0000664�0001750�0001750�00000000454�14506005535�021072� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 57, in f_string
54 | def f_string():
55 | f"""{str
56 | (
--> 57 | 1 /
58 | 0 + 4
59 | + 5
60 | )
61 | }"""
ZeroDivisionError: division by zero
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/f_string_new.txt������������������������������������������������0000664�0001750�0001750�00000000532�14506007111�021340� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 57, in f_string
54 | def f_string():
55 | f"""{str
56 | (
--> 57 | 1 /
^^^
58 | 0 + 4
^
59 | + 5
60 | )
61 | }"""
ZeroDivisionError: division by zero
����������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075113.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/f_string_old.txt������������������������������������������������0000664�0001750�0001750�00000000454�14506006551�021337� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 61, in f_string
54 | def f_string():
55 | f"""{str
56 | (
57 | 1 /
58 | 0 + 4
59 | + 5
60 | )
--> 61 | }"""
ZeroDivisionError: division by zero
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/format_frame.txt������������������������������������������������0000664�0001750�0001750�00000000301�14506007111�021310� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� File "formatter_example.py", line 51, in format_frame
49 | def format_frame(formatter):
50 | frame = inspect.currentframe()
--> 51 | return formatter.format_frame(frame)
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/format_stack.txt������������������������������������������������0000644�0001750�0001750�00000000612�14506007111�021326� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� File "formatter_example.py", line 42, in format_stack1
41 | def format_stack1(formatter):
--> 42 | return format_stack2(formatter)
^^^^^^^^^^^^^^^^^^^^^^^^
File "formatter_example.py", line 46, in format_stack2
45 | def format_stack2(formatter):
--> 46 | return list(formatter.format_stack())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
����������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/linenos_no_current_line_indicator.txt���������������������������0000664�0001750�0001750�00000000422�14506007111�025622� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
79 | def blank_lines():
80 | a = [1, 2, 3]
82 | length = len(a)
85 | return a[length]
^^^^^^^^^
IndexError: list index out of range
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/plain.txt�������������������������������������������������������0000644�0001750�0001750�00000003417�14506007111�017762� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 21, in foo
9 | x = 1
10 | lst = (
11 | [
12 | x,
(...)
18 | + []
19 | )
20 | try:
--> 21 | return int(str(lst))
^^^^^^^^^^^^^
22 | except:
ValueError: invalid literal for int() with base 10: '[1]'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "formatter_example.py", line 24, in foo
21 | return int(str(lst))
22 | except:
23 | try:
--> 24 | return 1 / 0
^^^^^
25 | except Exception as e:
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "formatter_example.py", line 30, in bar
29 | def bar():
--> 30 | exec("foo()")
^^^^^^^^^^^^^
File "", line 1, in
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
[... skipping similar frames: foo at line 8 (2 times)]
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
File "formatter_example.py", line 26, in foo
23 | try:
24 | return 1 / 0
25 | except Exception as e:
--> 26 | raise TypeError from e
TypeError
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/print_stack.txt�������������������������������������������������0000644�0001750�0001750�00000000532�14506007111�021173� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� File "formatter_example.py", line 34, in print_stack1
33 | def print_stack1(formatter):
--> 34 | print_stack2(formatter)
^^^^^^^^^^^^^^^^^^^^^^^
File "formatter_example.py", line 38, in print_stack2
37 | def print_stack2(formatter):
--> 38 | formatter.print_stack()
^^^^^^^^^^^^^^^^^^^^^^^
����������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/pygmented.txt���������������������������������������������������0000664�0001750�0001750�00000012417�14506010626�020662� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 21, in foo
9 | �[38;5;15m�[39m�[38;5;15mx�[39m�[38;5;15m �[39m�[38;5;204m=�[39m�[38;5;15m �[39m�[38;5;141m1�[39m
10 | �[38;5;15m�[39m�[38;5;15mlst�[39m�[38;5;15m �[39m�[38;5;204m=�[39m�[38;5;15m �[39m�[38;5;15m(�[39m
11 | �[38;5;15m �[39m�[38;5;15m[�[39m
12 | �[38;5;15m �[39m�[38;5;15mx�[39m�[38;5;15m,�[39m
(...)
18 | �[38;5;15m �[39m�[38;5;204m+�[39m�[38;5;15m �[39m�[38;5;15m[�[39m�[38;5;15m]�[39m
19 | �[38;5;15m�[39m�[38;5;15m)�[39m
20 | �[38;5;15m�[39m�[38;5;81mtry�[39m�[38;5;15m:�[39m
--> 21 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;15;48;5;24mint�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;15;48;5;24mstr�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;15;48;5;24mlst�[39;49m�[38;5;15;48;5;24m)�[39;49m�[38;5;15;48;5;24m)�[39;49m
22 | �[38;5;15m�[39m�[38;5;81mexcept�[39m�[38;5;15m:�[39m
ValueError: invalid literal for int() with base 10: '[1]'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "formatter_example.py", line 24, in foo
21 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;15mint�[39m�[38;5;15m(�[39m�[38;5;15mstr�[39m�[38;5;15m(�[39m�[38;5;15mlst�[39m�[38;5;15m)�[39m�[38;5;15m)�[39m
22 | �[38;5;15m�[39m�[38;5;81mexcept�[39m�[38;5;15m:�[39m
23 | �[38;5;15m �[39m�[38;5;81mtry�[39m�[38;5;15m:�[39m
--> 24 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;141;48;5;24m1�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;204;48;5;24m/�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;141;48;5;24m0�[39;49m
25 | �[38;5;15m �[39m�[38;5;81mexcept�[39m�[38;5;15m �[39m�[38;5;148mException�[39m�[38;5;15m �[39m�[38;5;81mas�[39m�[38;5;15m �[39m�[38;5;15me�[39m�[38;5;15m:�[39m
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "formatter_example.py", line 30, in bar
29 | �[38;5;81mdef�[39m�[38;5;15m �[39m�[38;5;148mbar�[39m�[38;5;15m(�[39m�[38;5;15m)�[39m�[38;5;15m:�[39m
--> 30 | �[38;5;15m �[39m�[38;5;15;48;5;24mexec�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;186;48;5;24m"�[39;49m�[38;5;186;48;5;24mfoo()�[39;49m�[38;5;186;48;5;24m"�[39;49m�[38;5;15;48;5;24m)�[39;49m
File "", line 1, in
File "formatter_example.py", line 8, in foo
6 | �[38;5;81mdef�[39m�[38;5;15m �[39m�[38;5;148mfoo�[39m�[38;5;15m(�[39m�[38;5;15mn�[39m�[38;5;204m=�[39m�[38;5;141m5�[39m�[38;5;15m)�[39m�[38;5;15m:�[39m
7 | �[38;5;15m �[39m�[38;5;81mif�[39m�[38;5;15m �[39m�[38;5;15mn�[39m�[38;5;15m �[39m�[38;5;204m>�[39m�[38;5;15m �[39m�[38;5;141m0�[39m�[38;5;15m:�[39m
--> 8 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;15;48;5;24mfoo�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;15;48;5;24mn�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;204;48;5;24m-�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;141;48;5;24m1�[39;49m�[38;5;15;48;5;24m)�[39;49m
9 | �[38;5;15m �[39m�[38;5;15mx�[39m�[38;5;15m �[39m�[38;5;204m=�[39m�[38;5;15m �[39m�[38;5;141m1�[39m
File "formatter_example.py", line 8, in foo
6 | �[38;5;81mdef�[39m�[38;5;15m �[39m�[38;5;148mfoo�[39m�[38;5;15m(�[39m�[38;5;15mn�[39m�[38;5;204m=�[39m�[38;5;141m5�[39m�[38;5;15m)�[39m�[38;5;15m:�[39m
7 | �[38;5;15m �[39m�[38;5;81mif�[39m�[38;5;15m �[39m�[38;5;15mn�[39m�[38;5;15m �[39m�[38;5;204m>�[39m�[38;5;15m �[39m�[38;5;141m0�[39m�[38;5;15m:�[39m
--> 8 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;15;48;5;24mfoo�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;15;48;5;24mn�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;204;48;5;24m-�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;141;48;5;24m1�[39;49m�[38;5;15;48;5;24m)�[39;49m
9 | �[38;5;15m �[39m�[38;5;15mx�[39m�[38;5;15m �[39m�[38;5;204m=�[39m�[38;5;15m �[39m�[38;5;141m1�[39m
[... skipping similar frames: foo at line 8 (2 times)]
File "formatter_example.py", line 8, in foo
6 | �[38;5;81mdef�[39m�[38;5;15m �[39m�[38;5;148mfoo�[39m�[38;5;15m(�[39m�[38;5;15mn�[39m�[38;5;204m=�[39m�[38;5;141m5�[39m�[38;5;15m)�[39m�[38;5;15m:�[39m
7 | �[38;5;15m �[39m�[38;5;81mif�[39m�[38;5;15m �[39m�[38;5;15mn�[39m�[38;5;15m �[39m�[38;5;204m>�[39m�[38;5;15m �[39m�[38;5;141m0�[39m�[38;5;15m:�[39m
--> 8 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;15;48;5;24mfoo�[39;49m�[38;5;15;48;5;24m(�[39;49m�[38;5;15;48;5;24mn�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;204;48;5;24m-�[39;49m�[38;5;15;48;5;24m �[39;49m�[38;5;141;48;5;24m1�[39;49m�[38;5;15;48;5;24m)�[39;49m
9 | �[38;5;15m �[39m�[38;5;15mx�[39m�[38;5;15m �[39m�[38;5;204m=�[39m�[38;5;15m �[39m�[38;5;141m1�[39m
File "formatter_example.py", line 26, in foo
23 | �[38;5;15m�[39m�[38;5;81mtry�[39m�[38;5;15m:�[39m
24 | �[38;5;15m �[39m�[38;5;81mreturn�[39m�[38;5;15m �[39m�[38;5;141m1�[39m�[38;5;15m �[39m�[38;5;204m/�[39m�[38;5;15m �[39m�[38;5;141m0�[39m
25 | �[38;5;15m�[39m�[38;5;81mexcept�[39m�[38;5;15m �[39m�[38;5;148mException�[39m�[38;5;15m �[39m�[38;5;81mas�[39m�[38;5;15m �[39m�[38;5;15me�[39m�[38;5;15m:�[39m
--> 26 | �[38;5;15m �[39m�[38;5;81mraise�[39m�[38;5;15m �[39m�[38;5;148mTypeError�[39m�[38;5;15m �[39m�[38;5;204mfrom�[39m�[38;5;15m �[39m�[38;5;15me�[39m
TypeError
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/pygmented_error.txt���������������������������������������������0000664�0001750�0001750�00000003077�14506007111�022070� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 21, in foo
9 | x = 1
10 | lst = (
11 | [
12 | x,
(...)
18 | + []
19 | )
20 | try:
--> 21 | return int(str(lst))
22 | except:
ValueError: invalid literal for int() with base 10: '[1]'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "formatter_example.py", line 24, in foo
21 | return int(str(lst))
22 | except:
23 | try:
--> 24 | return 1 / 0
25 | except Exception as e:
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "formatter_example.py", line 30, in bar
29 | def bar():
--> 30 | exec("foo()")
File "", line 1, in
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
9 | x = 1
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
9 | x = 1
[... skipping similar frames: foo at line 8 (2 times)]
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
9 | x = 1
File "formatter_example.py", line 26, in foo
23 | try:
24 | return 1 / 0
25 | except Exception as e:
--> 26 | raise TypeError from e
TypeError
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/serialize.json��������������������������������������������������0000664�0001750�0001750�00000207531�14506010626�021012� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������{
"format_frame": {
"name": "format_frame",
"filename": "formatter_example.py",
"lineno": 51,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 49,
"text": "def format_frame(formatter):"
},
{
"type": "line",
"is_current": false,
"lineno": 50,
"text": " frame = inspect.currentframe()"
},
{
"type": "line",
"is_current": true,
"lineno": 51,
"text": " return formatter.format_frame(frame)"
}
]
},
"format_stack": [
{
"type": "frame",
"name": "format_stack1",
"filename": "formatter_example.py",
"lineno": 42,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 41,
"text": "def format_stack1(formatter):"
},
{
"type": "line",
"is_current": true,
"lineno": 42,
"text": " return format_stack2(formatter)"
}
],
"variables": [
{
"name": "formatter",
"value": ""
}
]
},
{
"type": "frame",
"name": "format_stack2",
"filename": "formatter_example.py",
"lineno": 46,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 45,
"text": "def format_stack2(formatter):"
},
{
"type": "line",
"is_current": true,
"lineno": 46,
"text": " return list(formatter.format_stack())"
}
],
"variables": [
{
"name": "formatter",
"value": ""
}
]
}
],
"plain": [
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 21,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "x = 1"
},
{
"type": "line",
"is_current": false,
"lineno": 10,
"text": "lst = ("
},
{
"type": "line",
"is_current": false,
"lineno": 11,
"text": " ["
},
{
"type": "line",
"is_current": false,
"lineno": 12,
"text": " x,"
},
{
"type": "line_gap"
},
{
"type": "line",
"is_current": false,
"lineno": 18,
"text": " + []"
},
{
"type": "line",
"is_current": false,
"lineno": 19,
"text": ")"
},
{
"type": "line",
"is_current": false,
"lineno": 20,
"text": "try:"
},
{
"type": "line",
"is_current": true,
"lineno": 21,
"text": " return int(str(lst))"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "except:"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ValueError",
"message": "invalid literal for int() with base 10: '[1]'"
},
"tail": "During handling of the above exception, another exception occurred:"
},
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 24,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 21,
"text": " return int(str(lst))"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "except:"
},
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": " try:"
},
{
"type": "line",
"is_current": true,
"lineno": 24,
"text": " return 1 / 0"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": " except Exception as e:"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ZeroDivisionError",
"message": "division by zero"
},
"tail": "The above exception was the direct cause of the following exception:"
},
{
"frames": [
{
"type": "frame",
"name": "bar",
"filename": "formatter_example.py",
"lineno": 30,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 29,
"text": "def bar():"
},
{
"type": "line",
"is_current": true,
"lineno": 30,
"text": " exec(\"foo()\")"
}
],
"variables": []
},
{
"type": "frame",
"name": "",
"filename": "",
"lineno": 1,
"lines": [],
"variables": []
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "5"
},
{
"name": "n - 1",
"value": "4"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "4"
},
{
"name": "n - 1",
"value": "3"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "repeated_frames",
"frames": [
{
"name": "foo",
"lineno": 8,
"count": 2
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "1"
},
{
"name": "n - 1",
"value": "0"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 26,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": "try:"
},
{
"type": "line",
"is_current": false,
"lineno": 24,
"text": " return 1 / 0"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": "except Exception as e:"
},
{
"type": "line",
"is_current": true,
"lineno": 26,
"text": " raise TypeError from e"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "TypeError",
"message": ""
},
"tail": ""
}
],
"pygmented": [
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 21,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;15mx\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m1\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 10,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;15mlst\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15m(\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 11,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15m[\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 12,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15mx\u001b[39m\u001b[38;5;15m,\u001b[39m"
},
{
"type": "line_gap"
},
{
"type": "line",
"is_current": false,
"lineno": 18,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;204m+\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15m[\u001b[39m\u001b[38;5;15m]\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 19,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;15m)\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 20,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;81mtry\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 21,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15;48;5;24mint\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;15;48;5;24mstr\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;15;48;5;24mlst\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;81mexcept\u001b[39m\u001b[38;5;15m:\u001b[39m"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ValueError",
"message": "invalid literal for int() with base 10: '[1]'"
},
"tail": "During handling of the above exception, another exception occurred:"
},
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 24,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 21,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15mint\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15mstr\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15mlst\u001b[39m\u001b[38;5;15m)\u001b[39m\u001b[38;5;15m)\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;81mexcept\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mtry\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 24,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141;48;5;24m1\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;204;48;5;24m/\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;141;48;5;24m0\u001b[39;49m"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mexcept\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mException\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;81mas\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15me\u001b[39m\u001b[38;5;15m:\u001b[39m"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ZeroDivisionError",
"message": "division by zero"
},
"tail": "The above exception was the direct cause of the following exception:"
},
{
"frames": [
{
"type": "frame",
"name": "bar",
"filename": "formatter_example.py",
"lineno": 30,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 29,
"text": "\u001b[38;5;81mdef\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mbar\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15m)\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 30,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15;48;5;24mexec\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;186;48;5;24m\"\u001b[39;49m\u001b[38;5;186;48;5;24mfoo()\u001b[39;49m\u001b[38;5;186;48;5;24m\"\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m"
}
],
"variables": []
},
{
"type": "frame",
"name": "",
"filename": "",
"lineno": 1,
"lines": [],
"variables": []
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "\u001b[38;5;81mdef\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mfoo\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;141m5\u001b[39m\u001b[38;5;15m)\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mif\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m>\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m0\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15;48;5;24mfoo\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;15;48;5;24mn\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;204;48;5;24m-\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;141;48;5;24m1\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15mx\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m1\u001b[39m"
}
],
"variables": [
{
"name": "n",
"value": "5"
},
{
"name": "n - 1",
"value": "4"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "\u001b[38;5;81mdef\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mfoo\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;141m5\u001b[39m\u001b[38;5;15m)\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mif\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m>\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m0\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15;48;5;24mfoo\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;15;48;5;24mn\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;204;48;5;24m-\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;141;48;5;24m1\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15mx\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m1\u001b[39m"
}
],
"variables": [
{
"name": "n",
"value": "4"
},
{
"name": "n - 1",
"value": "3"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "repeated_frames",
"frames": [
{
"name": "foo",
"lineno": 8,
"count": 2
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "\u001b[38;5;81mdef\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mfoo\u001b[39m\u001b[38;5;15m(\u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;141m5\u001b[39m\u001b[38;5;15m)\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mif\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15mn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m>\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m0\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15;48;5;24mfoo\u001b[39;49m\u001b[38;5;15;48;5;24m(\u001b[39;49m\u001b[38;5;15;48;5;24mn\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;204;48;5;24m-\u001b[39;49m\u001b[38;5;15;48;5;24m \u001b[39;49m\u001b[38;5;141;48;5;24m1\u001b[39;49m\u001b[38;5;15;48;5;24m)\u001b[39;49m"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;15mx\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m=\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m1\u001b[39m"
}
],
"variables": [
{
"name": "n",
"value": "1"
},
{
"name": "n - 1",
"value": "0"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 26,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;81mtry\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 24,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mreturn\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m1\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204m/\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;141m0\u001b[39m"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": "\u001b[38;5;15m\u001b[39m\u001b[38;5;81mexcept\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mException\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;81mas\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15me\u001b[39m\u001b[38;5;15m:\u001b[39m"
},
{
"type": "line",
"is_current": true,
"lineno": 26,
"text": "\u001b[38;5;15m \u001b[39m\u001b[38;5;81mraise\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;148mTypeError\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;204mfrom\u001b[39m\u001b[38;5;15m \u001b[39m\u001b[38;5;15me\u001b[39m"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "TypeError",
"message": ""
},
"tail": ""
}
],
"pygmented_html": [
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 21,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": "x = 1"
},
{
"type": "line",
"is_current": false,
"lineno": 10,
"text": "lst = ("
},
{
"type": "line",
"is_current": false,
"lineno": 11,
"text": " ["
},
{
"type": "line",
"is_current": false,
"lineno": 12,
"text": " x,"
},
{
"type": "line_gap"
},
{
"type": "line",
"is_current": false,
"lineno": 18,
"text": " + []"
},
{
"type": "line",
"is_current": false,
"lineno": 19,
"text": ")"
},
{
"type": "line",
"is_current": false,
"lineno": 20,
"text": "try:"
},
{
"type": "line",
"is_current": true,
"lineno": 21,
"text": " return int(str(lst))"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "except:"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ValueError",
"message": "invalid literal for int() with base 10: '[1]'"
},
"tail": "During handling of the above exception, another exception occurred:"
},
{
"frames": [
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 24,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 21,
"text": " return int(str(lst))"
},
{
"type": "line",
"is_current": false,
"lineno": 22,
"text": "except:"
},
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": " try:"
},
{
"type": "line",
"is_current": true,
"lineno": 24,
"text": " return 1 / 0"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": " except Exception as e:"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "ZeroDivisionError",
"message": "division by zero"
},
"tail": "The above exception was the direct cause of the following exception:"
},
{
"frames": [
{
"type": "frame",
"name": "bar",
"filename": "formatter_example.py",
"lineno": 30,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 29,
"text": "def bar():"
},
{
"type": "line",
"is_current": true,
"lineno": 30,
"text": " exec("foo()")"
}
],
"variables": []
},
{
"type": "frame",
"name": "",
"filename": "",
"lineno": 1,
"lines": [],
"variables": []
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "5"
},
{
"name": "n - 1",
"value": "4"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "4"
},
{
"name": "n - 1",
"value": "3"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "repeated_frames",
"frames": [
{
"name": "foo",
"lineno": 8,
"count": 2
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 8,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 6,
"text": "def foo(n=5):"
},
{
"type": "line",
"is_current": false,
"lineno": 7,
"text": " if n > 0:"
},
{
"type": "line",
"is_current": true,
"lineno": 8,
"text": " return foo(n - 1)"
},
{
"type": "line",
"is_current": false,
"lineno": 9,
"text": " x = 1"
}
],
"variables": [
{
"name": "n",
"value": "1"
},
{
"name": "n - 1",
"value": "0"
},
{
"name": "n > 0",
"value": "True"
}
]
},
{
"type": "frame",
"name": "foo",
"filename": "formatter_example.py",
"lineno": 26,
"lines": [
{
"type": "line",
"is_current": false,
"lineno": 23,
"text": "try:"
},
{
"type": "line",
"is_current": false,
"lineno": 24,
"text": " return 1 / 0"
},
{
"type": "line",
"is_current": false,
"lineno": 25,
"text": "except Exception as e:"
},
{
"type": "line",
"is_current": true,
"lineno": 26,
"text": " raise TypeError from e"
}
],
"variables": [
{
"name": "[\n x,\n ]",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "[\n x,\n ]\n + []\n + []\n + []\n + []\n + []",
"value": "[1]"
},
{
"name": "lst",
"value": "[1]"
},
{
"name": "n",
"value": "0"
},
{
"name": "n - 1",
"value": "-1"
},
{
"name": "n > 0",
"value": "False"
},
{
"name": "str(lst)",
"value": "'[1]'"
},
{
"name": "x",
"value": "1"
}
]
}
],
"exception": {
"type": "TypeError",
"message": ""
},
"tail": ""
}
]
}�����������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/single_option_linenos_no_current_line_indicator.txt�������������0000664�0001750�0001750�00000000445�14506007111�030560� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 85, in blank_lines
79 | def blank_lines():
80 | a = [1, 2, 3]
81 |
82 | length = len(a)
:
85 | return a[length]
^^^^^^^^^
IndexError: list index out of range
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696075337.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/golden_files/variables.txt���������������������������������������������������0000644�0001750�0001750�00000007005�14506007111�020624� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Traceback (most recent call last):
File "formatter_example.py", line 21, in foo
9 | x = 1
10 | lst = (
11 | [
12 | x,
(...)
18 | + []
19 | )
20 | try:
--> 21 | return int(str(lst))
^^^^^^^^^^^^^
22 | except:
[
x,
] = [1]
[
x,
]
+ [] = [1]
[
x,
]
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ []
+ [] = [1]
lst = [1]
n = 0
n - 1 = -1
n > 0 = False
str(lst) = '[1]'
x = 1
ValueError: invalid literal for int() with base 10: '[1]'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "formatter_example.py", line 24, in foo
21 | return int(str(lst))
22 | except:
23 | try:
--> 24 | return 1 / 0
^^^^^
25 | except Exception as e:
[
x,
] = [1]
[
x,
]
+ [] = [1]
[
x,
]
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ []
+ [] = [1]
lst = [1]
n = 0
n - 1 = -1
n > 0 = False
str(lst) = '[1]'
x = 1
ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "formatter_example.py", line 30, in bar
29 | def bar():
--> 30 | exec("foo()")
^^^^^^^^^^^^^
File "", line 1, in
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
n = 5
n - 1 = 4
n > 0 = True
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
n = 4
n - 1 = 3
n > 0 = True
[... skipping similar frames: foo at line 8 (2 times)]
File "formatter_example.py", line 8, in foo
6 | def foo(n=5):
7 | if n > 0:
--> 8 | return foo(n - 1)
^^^^^^^^^^
9 | x = 1
n = 1
n - 1 = 0
n > 0 = True
File "formatter_example.py", line 26, in foo
23 | try:
24 | return 1 / 0
25 | except Exception as e:
--> 26 | raise TypeError from e
[
x,
] = [1]
[
x,
]
+ [] = [1]
[
x,
]
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ [] = [1]
[
x,
]
+ []
+ []
+ []
+ []
+ [] = [1]
lst = [1]
n = 0
n - 1 = -1
n > 0 = False
str(lst) = '[1]'
x = 1
TypeError
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1696082266.4591362
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/���������������������������������������������������������������������0000775�0001750�0001750�00000000000�14506024532�015133� 5����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1581610656.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/__init__.py����������������������������������������������������������0000644�0001750�0001750�00000000000�13621273240�017227� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1644864693.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/cython_example.pyx���������������������������������������������������0000664�0001750�0001750�00000000077�14202522265�020717� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������def foo():
bar()
cdef bar():
raise ValueError("bar!")
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1644857231.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/example.py�����������������������������������������������������������0000664�0001750�0001750�00000003412�14202503617�017137� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import inspect
from stack_data import FrameInfo, Options, Line, LINE_GAP, markers_from_ranges
def foo():
x = 1
lst = [1]
lst.insert(0, x)
lst.append(
[
1,
2,
3,
4,
5,
6
][0])
result = print_stack(
)
return result
def bar():
names = {}
exec("result = foo()", globals(), names)
return names["result"]
def print_stack():
result = ""
options = Options(include_signature=True)
frame = inspect.currentframe().f_back
for frame_info in list(FrameInfo.stack_data(frame, options))[-3:]:
result += render_frame_info(frame_info) + "\n"
return result
def render_frame_info(frame_info):
result = "{} at line {}".format(
frame_info.executing.code_qualname(),
frame_info.lineno
)
result += '\n' + len(result) * '-' + '\n'
for line in frame_info.lines:
def convert_variable_range(_):
return "", ""
def convert_executing_range(_):
return "", ""
if isinstance(line, Line):
markers = (
markers_from_ranges(line.variable_ranges, convert_variable_range) +
markers_from_ranges(line.executing_node_ranges, convert_executing_range)
)
result += '{:4} {} {}\n'.format(
line.lineno,
'>' if line.is_current else '|',
line.render(markers)
)
else:
assert line is LINE_GAP
result += '(...)\n'
for var in sorted(frame_info.variables, key=lambda v: v.name):
result += " ".join([var.name, '=', repr(var.value), '\n'])
return result
if __name__ == '__main__':
print(bar())
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1661606046.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/formatter_example.py�������������������������������������������������0000664�0001750�0001750�00000002501�14302414236�021217� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import inspect
from stack_data import Formatter
def foo(n=5):
if n > 0:
return foo(n - 1)
x = 1
lst = (
[
x,
]
+ []
+ []
+ []
+ []
+ []
)
try:
return int(str(lst))
except:
try:
return 1 / 0
except Exception as e:
raise TypeError from e
def bar():
exec("foo()")
def print_stack1(formatter):
print_stack2(formatter)
def print_stack2(formatter):
formatter.print_stack()
def format_stack1(formatter):
return format_stack2(formatter)
def format_stack2(formatter):
return list(formatter.format_stack())
def format_frame(formatter):
frame = inspect.currentframe()
return formatter.format_frame(frame)
def f_string():
f"""{str
(
1 /
0 + 4
+ 5
)
}"""
def block_right():
nb = len(letter
for letter
in
"words")
def block_left():
nb_characters = len(letter
for letter
in
"words")
def blank_lines():
a = [1, 2, 3]
length = len(a)
return a[length]
if __name__ == '__main__':
try:
bar()
except Exception:
Formatter(show_variables=True).print_exception()
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1581610656.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/not_code.txt���������������������������������������������������������0000644�0001750�0001750�00000000017�13621273240�017461� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������this isn't code�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1669579937.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/pieces.py������������������������������������������������������������0000664�0001750�0001750�00000003160�14340742241�016755� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import math
def foo(x=1, y=2):
"""
a docstring
"""
z = 0
for i in range(5):
z += i * x * math.sin(y)
# comment1
# comment2
z += math.copysign(
-1,
2,
)
for i in range(
0,
6
):
try:
str(i)
except:
pass
try:
int(i)
except (ValueError,
TypeError):
pass
finally:
str("""
foo
""")
str(f"""
{str(str)}
""")
str(f"""
foo
{
str(
str
)
}
bar
{str(str)}
baz
{
str(
str
)
}
spam
""")
def foo2(
x=1,
y=2,
):
while 9:
while (
9 + 9
):
if 1:
pass
elif 2:
pass
elif (
3 + 3
):
pass
else:
pass
class Foo(object):
@property
def foo(self):
return 3
# noinspection PyTrailingSemicolon
def semicolons():
if 1:
print(1,
2); print(3,
4); print(5,
6)
if 2:
print(1,
2); print(3, 4); print(5,
6)
print(1, 2); print(3,
4); print(5, 6)
print(1, 2);print(3, 4);print(5, 6)
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1663704456.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/pygments_example.py��������������������������������������������������0000664�0001750�0001750�00000002734�14312416610�021071� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import inspect
from pygments.formatters.html import HtmlFormatter
from pygments.formatters.terminal import TerminalFormatter
from pygments.formatters.terminal256 import Terminal256Formatter, TerminalTrueColorFormatter
from stack_data import FrameInfo, Options, style_with_executing_node
def identity(x):
return x
def bar():
x = 1
str(x)
@deco
def foo():
pass
pass
pass
return foo.result
def deco(f):
f.result = print_stack()
return f
def print_stack():
result = ""
for formatter_cls in [
Terminal256Formatter,
TerminalFormatter,
TerminalTrueColorFormatter,
HtmlFormatter,
]:
for style in ["native", style_with_executing_node("native", "bg:#444400")]:
result += "{formatter_cls.__name__} {style}:\n\n".format(**locals())
formatter = formatter_cls(style=style)
options = Options(pygments_formatter=formatter)
frame = inspect.currentframe().f_back
for frame_info in list(FrameInfo.stack_data(frame, options))[-2:]:
for line in frame_info.lines:
result += '{:4} | {}\n'.format(
line.lineno,
line.render(pygmented=True)
)
result += "-----\n"
result += "\n====================\n\n"
return result
if __name__ == '__main__':
print(bar())
print(repr(bar()).replace("\\n", "\n")[1:-1])
������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1581610656.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/samples/to_exec.py�����������������������������������������������������������0000644�0001750�0001750�00000000134�13621273240�017126� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import stack_data
import inspect
frame_info = stack_data.FrameInfo(inspect.currentframe())
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696080918.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/test_core.py�����������������������������������������������������������������0000664�0001750�0001750�00000066625�14506022026�016043� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import ast
import inspect
import os
import re
import sys
import token
from itertools import islice
from pathlib import Path
import pygments
import pytest
from executing import only
# noinspection PyUnresolvedReferences
from pygments.formatters.html import HtmlFormatter
from pygments.lexers import Python3Lexer
from stack_data import Options, Line, LINE_GAP, markers_from_ranges, Variable, RangeInLine, style_with_executing_node
from stack_data import Source, FrameInfo
from stack_data.utils import line_range
samples_dir = Path(__file__).parent / "samples"
pygments_version = tuple(map(int, pygments.__version__.split(".")[:2]))
def test_lines_with_gaps():
lines = []
dedented = False
def gather_lines():
frame = inspect.currentframe().f_back
frame_info = FrameInfo(frame, options)
assert repr(frame_info) == "FrameInfo({})".format(frame)
lines[:] = [
line.render(strip_leading_indent=dedented)
if isinstance(line, Line) else line
for line in frame_info.lines
]
def foo():
x = 1
lst = [1]
lst.insert(0, x)
lst.append(
[
1,
2,
3,
4,
5,
6
][0])
gather_lines()
lst += [99]
return lst
options = Options(include_signature=True)
foo()
assert lines == [
' def foo():',
LINE_GAP,
' lst = [1]',
' lst.insert(0, x)',
' lst.append(',
' [',
' 1,',
LINE_GAP,
' 6',
' ][0])',
' gather_lines()',
' lst += [99]',
]
options = Options()
foo()
assert lines == [
' lst = [1]',
' lst.insert(0, x)',
' lst.append(',
' [',
' 1,',
LINE_GAP,
' 6',
' ][0])',
' gather_lines()',
' lst += [99]',
]
def foo():
gather_lines()
foo()
assert lines == [
' def foo():',
' gather_lines()',
]
def foo():
lst = [1]
lst.insert(0, 2)
lst.append(
[
1,
2,
3,
gather_lines(),
5,
6
][0])
lst += [99]
return lst
foo()
assert lines == [
' def foo():',
' lst = [1]',
' lst.insert(0, 2)',
' lst.append(',
' [',
' 1,',
' 2,',
' 3,',
' gather_lines(),',
' 5,',
' 6',
' ][0])',
' lst += [99]'
]
dedented = True
foo()
assert lines == [
'def foo():',
' lst = [1]',
' lst.insert(0, 2)',
' lst.append(',
' [',
' 1,',
' 2,',
' 3,',
' gather_lines(),',
' 5,',
' 6',
' ][0])',
' lst += [99]'
]
def test_markers():
options = Options(before=0, after=0)
line = only(FrameInfo(inspect.currentframe(), options).lines)
assert line.is_current
assert re.match(r"")
assert repr(LINE_GAP) == "LINE_GAP"
assert '*'.join(t.string for t in line.tokens) == \
'line*=*only*(*FrameInfo*(*inspect*.*currentframe*(*)*,*options*)*.*lines*)*\n'
def convert_token_range(r):
if r.data.type == token.NAME:
return '[[', ']]'
markers = markers_from_ranges(line.token_ranges, convert_token_range)
assert line.render(markers) == \
'[[line]] = [[only]]([[FrameInfo]]([[inspect]].[[currentframe]](), [[options]]).[[lines]])'
assert line.render(markers, strip_leading_indent=False) == \
' [[line]] = [[only]]([[FrameInfo]]([[inspect]].[[currentframe]](), [[options]]).[[lines]])'
def convert_variable_range(r):
return '[[', ' of type {}]]'.format(r.data[0].value.__class__.__name__)
markers = markers_from_ranges(line.variable_ranges, convert_variable_range)
assert sorted(markers) == [
(4, True, '[['),
(8, False, ' of type Line]]'),
(50, True, '[['),
(57, False, ' of type Options]]'),
]
line.text += ' # < > " & done'
assert line.render(markers) == \
'[[line of type Line]] = only(FrameInfo(inspect.currentframe(), [[options of type Options]]).lines)' \
' # < > " & done'
assert line.render(markers, escape_html=True) == \
'[[line of type Line]] = only(FrameInfo(inspect.currentframe(), [[options of type Options]]).lines)' \
' # < > " & done'
def test_invalid_converter():
def converter(_):
return 1, 2
ranges = [RangeInLine(0, 1, None)]
with pytest.raises(TypeError):
# noinspection PyTypeChecker
markers_from_ranges(ranges, converter)
def test_variables():
options = Options(before=1, after=0)
assert repr(options) == ('Options(after=0, before=1, ' +
'blank_lines=,' +
' include_signature=False, ' +
'max_lines_per_piece=6, pygments_formatter=None)')
def foo(arg, _arg2: str = None, *_args, **_kwargs):
y = 123986
str(y)
x = {982347298304}
str(x)
return (
FrameInfo(inspect.currentframe(), options),
arg,
arg,
)[0]
frame_info = foo('this is arg')
assert sum(line.is_current for line in frame_info.lines) == 1
body = frame_info.scope.body
tup = body[-1].value.value.elts
call = tup[0]
assert frame_info.executing.node == call
assert frame_info.code == foo.__code__
assert frame_info.filename.endswith(frame_info.code.co_filename)
assert frame_info.filename.endswith("test_core.py")
assert os.path.isabs(frame_info.filename)
expected_variables = [
Variable(
name='_arg2',
nodes=(
frame_info.scope.args.args[1],
),
value=None,
),
Variable(
name='_args',
nodes=(
frame_info.scope.args.vararg,
),
value=(),
),
Variable(
name='_kwargs',
nodes=(
frame_info.scope.args.kwarg,
),
value={},
),
Variable(
name='arg',
nodes=(
tup[1],
tup[2],
frame_info.scope.args.args[0],
),
value='this is arg',
),
Variable(
name='options',
nodes=(call.args[1],),
value=options,
),
Variable(
name='str(x)',
nodes=(
body[3].value,
),
value='{982347298304}',
),
Variable(
name='str(y)',
nodes=(
body[1].value,
),
value='123986',
),
Variable(
name='x',
nodes=(
body[2].targets[0],
body[3].value.args[0],
),
value={982347298304},
),
Variable(
name='y',
nodes=(
body[0].targets[0],
body[1].value.args[0],
),
value=123986,
),
]
expected_variables = [tuple(v) for v in expected_variables]
variables = [tuple(v) for v in sorted(frame_info.variables)]
assert expected_variables == variables
assert (
sorted(frame_info.variables_in_executing_piece) ==
variables[3:5]
)
assert (
sorted(frame_info.variables_in_lines) ==
[*variables[3:6], variables[7]]
)
def test_pieces():
filename = samples_dir / "pieces.py"
source = Source.for_filename(str(filename))
pieces = [
[
source.lines[i - 1]
for i in piece
]
for piece in source.pieces
]
assert pieces == [
['import math'],
['def foo(x=1, y=2):'],
[' """',
' a docstring',
' """'],
[' z = 0'],
[' for i in range(5):'],
[' z += i * x * math.sin(y)'],
[' # comment1',
' # comment2'],
[' z += math.copysign(',
' -1,',
' 2,',
' )'],
[' for i in range(',
' 0,',
' 6',
' ):'],
[' try:'],
[' str(i)'],
[' except:'],
[' pass'],
[' try:'],
[' int(i)'],
[' except (ValueError,',
' TypeError):'],
[' pass'],
[' finally:'],
[' str("""',
' foo',
' """)'],
[' str(f"""',
' {str(str)}',
' """)'],
[' str(f"""',
' foo',
' {',
' str(',
' str',
' )',
' }',
' bar',
' {str(str)}',
' baz',
' {',
' str(',
' str',
' )',
' }',
' spam',
' """)'],
['def foo2(',
' x=1,',
' y=2,', '):'],
[' while 9:'],
[' while (',
' 9 + 9',
' ):'],
[' if 1:'],
[' pass'],
[' elif 2:'],
[' pass'],
[' elif (',
' 3 + 3',
' ):'],
[' pass'],
[' else:'],
[' pass'],
['class Foo(object):'],
[' @property',
' def foo(self):'],
[' return 3'],
['# noinspection PyTrailingSemicolon'],
['def semicolons():'],
[' if 1:'],
[' print(1,',
' 2); print(3,',
' 4); print(5,',
' 6)'],
[' if 2:'],
[' print(1,',
' 2); print(3, 4); print(5,',
' 6)'],
[' print(1, 2); print(3,',
' 4); print(5, 6)'],
[' print(1, 2);print(3, 4);print(5, 6)']
]
def check_skipping_frames(collapse: bool):
def factorial(n):
if n <= 1:
return 1 / 0 # exception lineno
return n * foo(n - 1) # factorial lineno
def foo(n):
return factorial(n) # foo lineno
try:
factorial(20) # check_skipping_frames lineno
except Exception as e:
# tb = sys.exc_info()[2]
tb = e.__traceback__
result = []
for x in FrameInfo.stack_data(tb, collapse_repeated_frames=collapse):
if isinstance(x, FrameInfo):
result.append((x.code, x.lineno))
else:
result.append(repr(x))
source = Source.for_filename(__file__)
linenos = {}
for lineno, line in enumerate(source.lines):
match = re.search(r" # (\w+) lineno", line)
if match:
linenos[match.group(1)] = lineno + 1
def simple_frame(func):
return func.__code__, linenos[func.__name__]
if collapse:
middle = [
simple_frame(factorial),
simple_frame(foo),
simple_frame(factorial),
simple_frame(foo),
(".factorial at line {factorial} (16 times), "
"check_skipping_frames..foo at line {foo} (16 times)>"
).format(**linenos),
simple_frame(factorial),
simple_frame(foo),
]
else:
middle = [
*([
simple_frame(factorial),
simple_frame(foo),
] * 19)
]
assert result == [
simple_frame(check_skipping_frames),
*middle,
(factorial.__code__, linenos["exception"]),
]
def test_skipping_frames():
check_skipping_frames(True)
check_skipping_frames(False)
def sys_modules_sources():
for module in list(sys.modules.values()):
try:
filename = inspect.getsourcefile(module)
except (TypeError, AttributeError):
continue
if not filename:
continue
filename = os.path.abspath(filename)
print(filename)
source = Source.for_filename(filename)
if not source.tree:
continue
yield source
def test_sys_modules():
modules = sys_modules_sources()
if not os.environ.get('STACK_DATA_SLOW_TESTS'):
modules = islice(modules, 0, 3)
for source in modules:
check_pieces(source)
check_pygments_tokens(source)
def check_pieces(source):
pieces = source.pieces
assert pieces == sorted(pieces, key=lambda p: (p.start, p.stop))
stmts = sorted({
source.line_range(node)
for node in ast.walk(source.tree)
if isinstance(node, ast.stmt)
if not isinstance(getattr(node, 'body', None), list)
})
if not stmts:
return
stmts_iter = iter(stmts)
stmt = next(stmts_iter)
for piece in pieces:
contains_stmt = stmt[0] <= piece.start < piece.stop <= stmt[1]
before_stmt = piece.start < piece.stop <= stmt[0] < stmt[1]
assert contains_stmt ^ before_stmt
if contains_stmt:
try:
stmt = next(stmts_iter)
except StopIteration:
break
blank_linenos = set(range(1, len(source.lines) + 1)).difference(*pieces)
for lineno in blank_linenos:
assert not source.lines[lineno - 1].strip(), lineno
def check_pygments_tokens(source):
lexer = Python3Lexer(stripnl=False, ensurenl=False)
pygments_tokens = [value for ttype, value in pygments.lex(source.text, lexer)]
assert ''.join(pygments_tokens) == source.text
def test_invalid_source():
filename = str(samples_dir / "not_code.txt")
source = Source.for_filename(filename)
assert not source.tree
assert not hasattr(source, "tokens_by_lineno")
def test_absolute_filename():
sys.path.append(str(samples_dir))
short_filename = "to_exec.py"
full_filename = str(samples_dir / short_filename)
source = Source.for_filename(short_filename)
names = {}
code = compile(source.text, short_filename, "exec")
exec(code, names)
frame_info = names["frame_info"]
assert frame_info.source is source
assert frame_info.code is code
assert code.co_filename == source.filename == short_filename
assert frame_info.filename == full_filename
@pytest.mark.parametrize("expected",
[
r".c { color: #(999999|ababab); font-style: italic }",
r".err { color: #a61717; background-color: #e3d2d2 }",
r".c-ExecutingNode { color: #(999999|ababab); font-style: italic; background-color: #ffff00 }",
r".err-ExecutingNode { color: #a61717; background-color: #ffff00 }",
]
)
def test_executing_style_defs(expected):
style = style_with_executing_node("native", "bg:#ffff00")
formatter = HtmlFormatter(style=style)
style_defs = formatter.get_style_defs()
assert re.search(expected, style_defs)
def test_example():
from .samples.example import bar
result = bar()
print(result)
assert result == """\
bar at line 27
--------------
25 | def bar():
26 | names = {}
27 > exec("result = foo()", globals(), names)
28 | return names["result"]
names = {}
at line 1
------------------
foo at line 20
--------------
6 | def foo():
(...)
8 | lst = [1]
10 | lst.insert(0, x)
11 | lst.append(
12 | [
13 | 1,
(...)
18 | 6
19 | ][0])
20 > result = print_stack(
21 | )
22 | return result
[
1,
2,
3,
4,
5,
6
][0] = 1
lst = [1, 1, 1]
x = 1
"""
@pytest.mark.skipif(pygments_version < (2, 14), reason="Different output in older Pygments")
def test_pygments_example():
from .samples.pygments_example import bar
result = bar()
print(result)
assert result == """\
Terminal256Formatter native:
13 | \x1b[38;5;70;01mdef\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;75mbar\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252m)\x1b[39m\x1b[38;5;252m:\x1b[39m
14 | \x1b[38;5;252m \x1b[39m\x1b[38;5;252mx\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252m=\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;75m1\x1b[39m
15 | \x1b[38;5;252m \x1b[39m\x1b[38;5;38mstr\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252mx\x1b[39m\x1b[38;5;252m)\x1b[39m
17 | \x1b[38;5;252m \x1b[39m\x1b[38;5;214m@deco\x1b[39m
18 | \x1b[38;5;252m \x1b[39m\x1b[38;5;70;01mdef\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;75mfoo\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252m)\x1b[39m\x1b[38;5;252m:\x1b[39m
19 | \x1b[38;5;252m \x1b[39m\x1b[38;5;70;01mpass\x1b[39;00m
-----
25 | \x1b[38;5;70;01mdef\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;75mdeco\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252mf\x1b[39m\x1b[38;5;252m)\x1b[39m\x1b[38;5;252m:\x1b[39m
26 | \x1b[38;5;252m \x1b[39m\x1b[38;5;252mf\x1b[39m\x1b[38;5;252m.\x1b[39m\x1b[38;5;252mresult\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252m=\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252mprint_stack\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252m)\x1b[39m
27 | \x1b[38;5;252m \x1b[39m\x1b[38;5;70;01mreturn\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;252mf\x1b[39m
-----
====================
Terminal256Formatter .NewStyle\'>:
13 | \x1b[38;5;70;01mdef\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;75mbar\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252m)\x1b[39m\x1b[38;5;252m:\x1b[39m
14 | \x1b[38;5;252m \x1b[39m\x1b[38;5;252mx\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252m=\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;75m1\x1b[39m
15 | \x1b[38;5;252m \x1b[39m\x1b[38;5;38mstr\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252mx\x1b[39m\x1b[38;5;252m)\x1b[39m
17 | \x1b[38;5;252;48;5;58m \x1b[39;49m\x1b[38;5;214;48;5;58m@deco\x1b[39;49m
18 | \x1b[38;5;252;48;5;58m \x1b[39;49m\x1b[38;5;70;48;5;58;01mdef\x1b[39;49;00m\x1b[38;5;252;48;5;58m \x1b[39;49m\x1b[38;5;75;48;5;58mfoo\x1b[39;49m\x1b[38;5;252;48;5;58m(\x1b[39;49m\x1b[38;5;252;48;5;58m)\x1b[39;49m\x1b[38;5;252;48;5;58m:\x1b[39;49m
19 | \x1b[38;5;252;48;5;58m \x1b[39;49m\x1b[38;5;70;48;5;58;01mpass\x1b[39;49;00m
-----
25 | \x1b[38;5;70;01mdef\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;75mdeco\x1b[39m\x1b[38;5;252m(\x1b[39m\x1b[38;5;252mf\x1b[39m\x1b[38;5;252m)\x1b[39m\x1b[38;5;252m:\x1b[39m
26 | \x1b[38;5;252m \x1b[39m\x1b[38;5;252mf\x1b[39m\x1b[38;5;252m.\x1b[39m\x1b[38;5;252mresult\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252m=\x1b[39m\x1b[38;5;252m \x1b[39m\x1b[38;5;252;48;5;58mprint_stack\x1b[39;49m\x1b[38;5;252;48;5;58m(\x1b[39;49m\x1b[38;5;252;48;5;58m)\x1b[39;49m
27 | \x1b[38;5;252m \x1b[39m\x1b[38;5;70;01mreturn\x1b[39;00m\x1b[38;5;252m \x1b[39m\x1b[38;5;252mf\x1b[39m
-----
====================
TerminalFormatter native:
13 | \x1b[34mdef\x1b[39;49;00m \x1b[32mbar\x1b[39;49;00m():\x1b[37m\x1b[39;49;00m
14 | x = \x1b[34m1\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
15 | \x1b[36mstr\x1b[39;49;00m(x)\x1b[37m\x1b[39;49;00m
17 | \x1b[90m@deco\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
18 | \x1b[34mdef\x1b[39;49;00m \x1b[32mfoo\x1b[39;49;00m():\x1b[37m\x1b[39;49;00m
19 | \x1b[34mpass\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
-----
25 | \x1b[34mdef\x1b[39;49;00m \x1b[32mdeco\x1b[39;49;00m(f):\x1b[37m\x1b[39;49;00m
26 | f.result = print_stack()\x1b[37m\x1b[39;49;00m
27 | \x1b[34mreturn\x1b[39;49;00m f\x1b[37m\x1b[39;49;00m
-----
====================
TerminalFormatter .NewStyle\'>:
13 | \x1b[34mdef\x1b[39;49;00m \x1b[32mbar\x1b[39;49;00m():\x1b[37m\x1b[39;49;00m
14 | x = \x1b[34m1\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
15 | \x1b[36mstr\x1b[39;49;00m(x)\x1b[37m\x1b[39;49;00m
17 | \x1b[90m@deco\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
18 | \x1b[34mdef\x1b[39;49;00m \x1b[32mfoo\x1b[39;49;00m():\x1b[37m\x1b[39;49;00m
19 | \x1b[34mpass\x1b[39;49;00m\x1b[37m\x1b[39;49;00m
-----
25 | \x1b[34mdef\x1b[39;49;00m \x1b[32mdeco\x1b[39;49;00m(f):\x1b[37m\x1b[39;49;00m
26 | f.result = print_stack()\x1b[37m\x1b[39;49;00m
27 | \x1b[34mreturn\x1b[39;49;00m f\x1b[37m\x1b[39;49;00m
-----
====================
TerminalTrueColorFormatter native:
13 | \x1b[38;2;110;191;38;01mdef\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;113;173;255mbar\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m\x1b[38;2;208;208;208m:\x1b[39m
14 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mx\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208m=\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;81;178;253m1\x1b[39m
15 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;47;188;205mstr\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208mx\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m
17 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;255;165;0m@deco\x1b[39m
18 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;110;191;38;01mdef\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;113;173;255mfoo\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m\x1b[38;2;208;208;208m:\x1b[39m
19 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;110;191;38;01mpass\x1b[39;00m
-----
25 | \x1b[38;2;110;191;38;01mdef\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;113;173;255mdeco\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208mf\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m\x1b[38;2;208;208;208m:\x1b[39m
26 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mf\x1b[39m\x1b[38;2;208;208;208m.\x1b[39m\x1b[38;2;208;208;208mresult\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208m=\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mprint_stack\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m
27 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;110;191;38;01mreturn\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mf\x1b[39m
-----
====================
TerminalTrueColorFormatter .NewStyle\'>:
13 | \x1b[38;2;110;191;38;01mdef\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;113;173;255mbar\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m\x1b[38;2;208;208;208m:\x1b[39m
14 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mx\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208m=\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;81;178;253m1\x1b[39m
15 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;47;188;205mstr\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208mx\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m
17 | \x1b[38;2;208;208;208;48;2;68;68;0m \x1b[39;49m\x1b[38;2;255;165;0;48;2;68;68;0m@deco\x1b[39;49m
18 | \x1b[38;2;208;208;208;48;2;68;68;0m \x1b[39;49m\x1b[38;2;110;191;38;48;2;68;68;0;01mdef\x1b[39;49;00m\x1b[38;2;208;208;208;48;2;68;68;0m \x1b[39;49m\x1b[38;2;113;173;255;48;2;68;68;0mfoo\x1b[39;49m\x1b[38;2;208;208;208;48;2;68;68;0m(\x1b[39;49m\x1b[38;2;208;208;208;48;2;68;68;0m)\x1b[39;49m\x1b[38;2;208;208;208;48;2;68;68;0m:\x1b[39;49m
19 | \x1b[38;2;208;208;208;48;2;68;68;0m \x1b[39;49m\x1b[38;2;110;191;38;48;2;68;68;0;01mpass\x1b[39;49;00m
-----
25 | \x1b[38;2;110;191;38;01mdef\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;113;173;255mdeco\x1b[39m\x1b[38;2;208;208;208m(\x1b[39m\x1b[38;2;208;208;208mf\x1b[39m\x1b[38;2;208;208;208m)\x1b[39m\x1b[38;2;208;208;208m:\x1b[39m
26 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mf\x1b[39m\x1b[38;2;208;208;208m.\x1b[39m\x1b[38;2;208;208;208mresult\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208m=\x1b[39m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208;48;2;68;68;0mprint_stack\x1b[39;49m\x1b[38;2;208;208;208;48;2;68;68;0m(\x1b[39;49m\x1b[38;2;208;208;208;48;2;68;68;0m)\x1b[39;49m
27 | \x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;110;191;38;01mreturn\x1b[39;00m\x1b[38;2;208;208;208m \x1b[39m\x1b[38;2;208;208;208mf\x1b[39m
-----
====================
HtmlFormatter native:
13 | def bar():
14 | x = 1
15 | str(x)
17 | @deco
18 | def foo():
19 | pass
-----
25 | def deco(f):
26 | f.result = print_stack()
27 | return f
-----
====================
HtmlFormatter .NewStyle\'>:
13 | def bar():
14 | x = 1
15 | str(x)
17 | @deco
18 | def foo():
19 | pass
-----
25 | def deco(f):
26 | f.result = print_stack()
27 | return f
-----
====================
"""
�����������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/test_formatter.py������������������������������������������������������������0000664�0001750�0001750�00000012174�14506010626�017107� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import os
import re
import sys
from contextlib import contextmanager
import pygments
import pytest
from asttokens.util import fstring_positions_work
from stack_data import Formatter, FrameInfo, Options, BlankLines
from tests.utils import compare_to_file
class BaseFormatter(Formatter):
def format_frame_header(self, frame_info: FrameInfo) -> str:
# noinspection PyPropertyAccess
frame_info.filename = os.path.basename(frame_info.filename)
return super().format_frame_header(frame_info)
def format_variable_value(self, value) -> str:
result = super().format_variable_value(value)
result = re.sub(r'0x\w+', '0xABC', result)
return result
class MyFormatter(BaseFormatter):
def format_frame(self, frame):
if not frame.filename.endswith(("formatter_example.py", "", "cython_example.pyx")):
return
yield from super().format_frame(frame)
def test_example(capsys):
from .samples.formatter_example import bar, print_stack1, format_stack1, format_frame, f_string, blank_lines
@contextmanager
def check_example(name):
yield
stderr = capsys.readouterr().err
compare_to_file(stderr, name)
with check_example("variables"):
try:
bar()
except Exception:
MyFormatter(show_variables=True).print_exception()
with check_example("pygmented"):
try:
bar()
except Exception:
MyFormatter(pygmented=True).print_exception()
with check_example("plain"):
MyFormatter().set_hook()
try:
bar()
except Exception:
sys.excepthook(*sys.exc_info())
with check_example("pygmented_error"):
h = pygments.highlight
pygments.highlight = lambda *args, **kwargs: 1/0
try:
bar()
except Exception:
MyFormatter(pygmented=True).print_exception()
finally:
pygments.highlight = h
with check_example("print_stack"):
print_stack1(MyFormatter())
with check_example("format_stack"):
formatter = MyFormatter()
formatted = format_stack1(formatter)
formatter.print_lines(formatted)
with check_example("format_frame"):
formatter = BaseFormatter()
formatted = format_frame(formatter)
formatter.print_lines(formatted)
if sys.version_info[:2] < (3, 8):
f_string_suffix = 'old'
elif not fstring_positions_work():
f_string_suffix = '3.8'
else:
f_string_suffix = 'new'
with check_example(f"f_string_{f_string_suffix}"):
try:
f_string()
except Exception:
MyFormatter().print_exception()
from .samples.formatter_example import block_right, block_left
with check_example(f"block_right_{'old' if sys.version_info[:2] < (3, 8) else 'new'}"):
try:
block_right()
except Exception:
MyFormatter().print_exception()
with check_example(f"block_left_{'old' if sys.version_info[:2] < (3, 8) else 'new'}"):
try:
block_left()
except Exception:
MyFormatter().print_exception()
from .samples import cython_example
with check_example("cython_example"):
try:
cython_example.foo()
except Exception:
MyFormatter().print_exception()
with check_example("blank_visible"):
try:
blank_lines()
except Exception:
MyFormatter(options=Options(blank_lines=BlankLines.VISIBLE)).print_exception()
with check_example("blank_single"):
try:
blank_lines()
except Exception:
MyFormatter(options=Options(blank_lines=BlankLines.SINGLE)).print_exception()
with check_example("blank_invisible_no_linenos"):
try:
blank_lines()
except Exception:
MyFormatter(show_linenos=False, current_line_indicator="").print_exception()
with check_example("blank_visible_no_linenos"):
try:
blank_lines()
except Exception:
MyFormatter(show_linenos=False,
current_line_indicator="",
options=Options(blank_lines=BlankLines.VISIBLE)).print_exception()
with check_example("linenos_no_current_line_indicator"):
try:
blank_lines()
except Exception:
MyFormatter(current_line_indicator="").print_exception()
with check_example("blank_visible_with_linenos_no_current_line_indicator"):
try:
blank_lines()
except Exception:
MyFormatter(current_line_indicator="",
options=Options(blank_lines=BlankLines.VISIBLE)).print_exception()
with check_example("single_option_linenos_no_current_line_indicator"):
try:
blank_lines()
except Exception:
MyFormatter(current_line_indicator="",
options=Options(blank_lines=BlankLines.SINGLE)).print_exception()
def test_invalid_single_option():
with pytest.raises(ValueError):
MyFormatter(show_linenos=False, options=Options(blank_lines=BlankLines.SINGLE))
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/test_serializer.py�����������������������������������������������������������0000664�0001750�0001750�00000002530�14506010626�017250� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import os.path
import re
from stack_data import FrameInfo
from stack_data.serializing import Serializer
from tests.utils import compare_to_file_json
class MyFormatter(Serializer):
def should_include_frame(self, frame_info: FrameInfo) -> bool:
return frame_info.filename.endswith(("formatter_example.py", "", "cython_example.pyx"))
def format_variable_value(self, value) -> str:
result = super().format_variable_value(value)
result = re.sub(r'0x\w+', '0xABC', result)
return result
def format_frame(self, frame) -> dict:
result = super().format_frame(frame)
result["filename"] = os.path.basename(result["filename"])
return result
def test_example():
from .samples.formatter_example import bar, format_frame, format_stack1
result = dict(
format_frame=(format_frame(MyFormatter())),
format_stack=format_stack1(MyFormatter(show_variables=True)),
)
try:
bar()
except Exception:
result.update(
plain=MyFormatter(show_variables=True).format_exception(),
pygmented=MyFormatter(show_variables=True, pygmented=True).format_exception(),
pygmented_html=MyFormatter(show_variables=True, pygmented=True, html=True).format_exception(),
)
compare_to_file_json(result, "serialize", pygmented=True)
������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1581610656.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/test_utils.py����������������������������������������������������������������0000644�0001750�0001750�00000004505�13621273240�016241� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import random
from collections import Counter
from stack_data import FrameInfo
from stack_data.utils import highlight_unique, collapse_repeated, cached_property
def assert_collapsed(lst, expected, summary):
assert ''.join(collapse_repeated(lst, collapser=lambda group, _: '.' * len(group))) == expected
assert list(collapse_repeated(lst, collapser=lambda group, _: Counter(group))) == summary
def test_collapse_repeated():
assert_collapsed(
'0123456789BBCBCBBCBACBACBBBBCABABBABCCCCAACBABBCBBBAAACBBBCABACACCAACABBCBCCBBABBAAAAACBCCCAAAABBCBB',
'0123456789BBC.C....A..A.......................................................................A..C.B',
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'B', 'B', 'C', Counter({'B': 1}), 'C',
Counter({'B': 3, 'C': 1}), 'A', Counter({'C': 1, 'B': 1}), 'A', Counter({'B': 26, 'A': 24, 'C': 21}), 'A',
Counter({'B': 2}), 'C', Counter({'B': 1}), 'B']
)
assert_collapsed(
'BAAABABC3BCBBCBBCBAACBBBABBCCACCACB7BBBCA8ABB9B0AACABBCACCCCAAAAABBBBBCA2CBABCCCBB4ACCAACBBA1BBCB6A5',
'BAA.BABC3BCB.C....AA............ACB7BBBCA8ABB9B0AAC.BBC..............BCA2CBABC.C.B4ACCA.CBBA1BBCB6A5',
['B', 'A', 'A', Counter({'A': 1}), 'B', 'A', 'B', 'C', '3', 'B', 'C', 'B', Counter({'B': 1}), 'C',
Counter({'B': 3, 'C': 1}), 'A', 'A', Counter({'C': 5, 'B': 5, 'A': 2}),
'A', 'C', 'B', '7', 'B', 'B', 'B', 'C', 'A', '8', 'A', 'B', 'B', '9', 'B', '0', 'A', 'A', 'C',
Counter({'A': 1}), 'B', 'B', 'C', Counter({'A': 6, 'C': 4, 'B': 4}),
'B', 'C', 'A', '2', 'C', 'B', 'A', 'B', 'C', Counter({'C': 1}), 'C',
Counter({'B': 1}), 'B', '4', 'A', 'C', 'C', 'A', Counter({'A': 1}),
'C', 'B', 'B', 'A', '1', 'B', 'B', 'C', 'B', '6', 'A', '5'],
)
def test_highlight_unique_properties():
for _ in range(20):
lst = list('0123456789' * 3) + [random.choice('ABCD') for _ in range(1000)]
random.shuffle(lst)
result = list(highlight_unique(lst))
assert len(lst) == len(result)
vals, highlighted = zip(*result)
assert set(vals) == set('0123456789ABCD')
assert set(highlighted) == {True, False}
def test_cached_property_from_class():
assert FrameInfo.filename is FrameInfo.__dict__["filename"]
assert isinstance(FrameInfo.filename, cached_property)
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076182.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tests/utils.py���������������������������������������������������������������������0000664�0001750�0001750�00000002062�14506010626�015200� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������import os
import pygments
from littleutils import string_to_file, file_to_string, json_to_file, file_to_json
def parse_version(version: str):
return tuple(int(x) for x in version.split("."))
old_pygments = parse_version(pygments.__version__) < (2, 16, 1)
def compare_to_file(text, name):
if old_pygments and "pygment" in name:
return
filename = os.path.join(
os.path.dirname(__file__),
'golden_files',
name + '.txt',
)
if os.environ.get('FIX_STACK_DATA_TESTS'):
string_to_file(text, filename)
else:
expected_output = file_to_string(filename)
assert text == expected_output
def compare_to_file_json(data, name, *, pygmented):
if old_pygments and pygmented:
return
filename = os.path.join(
os.path.dirname(__file__),
'golden_files',
name + '.json',
)
if os.environ.get('FIX_STACK_DATA_TESTS'):
json_to_file(data, filename, indent=4)
else:
expected_output = file_to_json(filename)
assert data == expected_output
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1696076213.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������stack_data-0.6.3/tox.ini����������������������������������������������������������������������������0000664�0001750�0001750�00000000237�14506010665�013644� 0����������������������������������������������������������������������������������������������������ustar�00alex����������������������������alex�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������[tox]
envlist = py{36,37,38,39,310,311,312}
[testenv]
commands = pytest {posargs}
extras = tests
passenv =
STACK_DATA_SLOW_TESTS
FIX_STACK_DATA_TESTS
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������