fastText-0.9.2/�������������������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�012666� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/get-wikimedia.sh���������������������������������������������������������������������0000755�0001750�0000176�00000006356�13651775021�015757� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# Copyright (c) 2016-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
#
set -e
normalize_text() {
sed -e "s/’/'/g" -e "s/′/'/g" -e "s/''/ /g" -e "s/'/ ' /g" -e "s/“/\"/g" -e "s/”/\"/g" \
-e 's/"/ " /g' -e 's/\./ \. /g' -e 's/
/ /g' -e 's/, / , /g' -e 's/(/ ( /g' -e 's/)/ ) /g' -e 's/\!/ \! /g' \
-e 's/\?/ \? /g' -e 's/\;/ /g' -e 's/\:/ /g' -e 's/-/ - /g' -e 's/=/ /g' -e 's/=/ /g' -e 's/*/ /g' -e 's/|/ /g' \
-e 's/«/ /g' | tr 0-9 " "
}
export LANGUAGE=en_US.UTF-8
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
NOW=$(date +"%Y%m%d")
ROOT="data/wikimedia/${NOW}"
mkdir -p "${ROOT}"
echo "Saving data in ""$ROOT"
read -r -p "Choose a language (e.g. en, bh, fr, etc.): " choice
LANG="$choice"
echo "Chosen language: ""$LANG"
read -r -p "Continue to download (WARNING: This might be big and can take a long time!)(y/n)? " choice
case "$choice" in
y|Y ) echo "Starting download...";;
n|N ) echo "Exiting";exit 1;;
* ) echo "Invalid answer";exit 1;;
esac
wget -c "https://dumps.wikimedia.org/""$LANG""wiki/latest/""${LANG}""wiki-latest-pages-articles.xml.bz2" -P "${ROOT}"
echo "Processing ""$ROOT"/"$LANG""wiki-latest-pages-articles.xml.bz2"
bzip2 -c -d "$ROOT"/"$LANG""wiki-latest-pages-articles.xml.bz2" | awk '{print tolower($0);}' | perl -e '
# Program to filter Wikipedia XML dumps to "clean" text consisting only of lowercase
# letters (a-z, converted from A-Z), and spaces (never consecutive)...
# All other characters are converted to spaces. Only text which normally appears.
# in the web browser is displayed. Tables are removed. Image captions are.
# preserved. Links are converted to normal text. Digits are spelled out.
# *** Modified to not spell digits or throw away non-ASCII characters ***
# Written by Matt Mahoney, June 10, 2006. This program is released to the public domain.
$/=">"; # input record separator
while (<>) {
if (/ ...
if (/#redirect/i) {$text=0;} # remove #REDIRECT
if ($text) {
# Remove any text not normally visible
if (/<\/text>/) {$text=0;}
s/<.*>//; # remove xml tags
s/&/&/g; # decode URL encoded chars
s/<//g;
s///g; # remove references ...
s/<[^>]*>//g; # remove xhtml tags
s/\[http:[^] ]*/[/g; # remove normal url, preserve visible text
s/\|thumb//ig; # remove images links, preserve caption
s/\|left//ig;
s/\|right//ig;
s/\|\d+px//ig;
s/\[\[image:[^\[\]]*\|//ig;
s/\[\[category:([^|\]]*)[^]]*\]\]/[[$1]]/ig; # show categories without markup
s/\[\[[a-z\-]*:[^\]]*\]\]//g; # remove links to other languages
s/\[\[[^\|\]]*\|/[[/g; # remove wiki url, preserve visible text
s/{{[^}]*}}//g; # remove {{icons}} and {tables}
s/{[^}]*}//g;
s/\[//g; # remove [ and ]
s/\]//g;
s/&[^;]*;/ /g; # remove URL encoded chars
$_=" $_ ";
chop;
print $_;
}
}
' | normalize_text | awk '{if (NF>1) print;}' | tr -s " " | shuf > "${ROOT}"/wiki."${LANG}".txt
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/quantization-example.sh��������������������������������������������������������������0000755�0001750�0000176�00000003050�13651775021�017402� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������myshuf() {
perl -MList::Util=shuffle -e 'print shuffle(<>);' "$@";
}
normalize_text() {
tr '[:upper:]' '[:lower:]' | sed -e 's/^/__label__/g' | \
sed -e "s/'/ ' /g" -e 's/"//g' -e 's/\./ \. /g' -e 's/
/ /g' \
-e 's/,/ , /g' -e 's/(/ ( /g' -e 's/)/ ) /g' -e 's/\!/ \! /g' \
-e 's/\?/ \? /g' -e 's/\;/ /g' -e 's/\:/ /g' | tr -s " " | myshuf
}
RESULTDIR=result
DATADIR=data
mkdir -p "${RESULTDIR}"
mkdir -p "${DATADIR}"
if [ ! -f "${DATADIR}/dbpedia.train" ]
then
wget -c "https://github.com/le-scientifique/torchDatasets/raw/master/dbpedia_csv.tar.gz" -O "${DATADIR}/dbpedia_csv.tar.gz"
tar -xzvf "${DATADIR}/dbpedia_csv.tar.gz" -C "${DATADIR}"
cat "${DATADIR}/dbpedia_csv/train.csv" | normalize_text > "${DATADIR}/dbpedia.train"
cat "${DATADIR}/dbpedia_csv/test.csv" | normalize_text > "${DATADIR}/dbpedia.test"
fi
make
echo "Training..."
./fasttext supervised -input "${DATADIR}/dbpedia.train" -output "${RESULTDIR}/dbpedia" -dim 10 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 5 -thread 4
echo "Quantizing..."
./fasttext quantize -output "${RESULTDIR}/dbpedia" -input "${DATADIR}/dbpedia.train" -qnorm -retrain -epoch 1 -cutoff 100000
echo "Testing original model..."
./fasttext test "${RESULTDIR}/dbpedia.bin" "${DATADIR}/dbpedia.test"
echo "Testing quantized model..."
./fasttext test "${RESULTDIR}/dbpedia.ftz" "${DATADIR}/dbpedia.test"
wc -c < "${RESULTDIR}/dbpedia.bin" | awk '{print "Size of the original model:\t",$1;}'
wc -c < "${RESULTDIR}/dbpedia.ftz" | awk '{print "Size of the quantized model:\t",$1;}'
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/word-vector-example.sh���������������������������������������������������������������0000755�0001750�0000176�00000002233�13651775021�017131� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# Copyright (c) 2016-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
#
RESULTDIR=result
DATADIR=data
mkdir -p "${RESULTDIR}"
mkdir -p "${DATADIR}"
if [ ! -f "${DATADIR}/fil9" ]
then
wget -c http://mattmahoney.net/dc/enwik9.zip -P "${DATADIR}"
unzip "${DATADIR}/enwik9.zip" -d "${DATADIR}"
perl wikifil.pl "${DATADIR}/enwik9" > "${DATADIR}"/fil9
fi
if [ ! -f "${DATADIR}/rw/rw.txt" ]
then
wget -c https://nlp.stanford.edu/~lmthang/morphoNLM/rw.zip -P "${DATADIR}"
unzip "${DATADIR}/rw.zip" -d "${DATADIR}"
fi
make
./fasttext skipgram -input "${DATADIR}"/fil9 -output "${RESULTDIR}"/fil9 -lr 0.025 -dim 100 \
-ws 5 -epoch 1 -minCount 5 -neg 5 -loss ns -bucket 2000000 \
-minn 3 -maxn 6 -thread 4 -t 1e-4 -lrUpdateRate 100
cut -f 1,2 "${DATADIR}"/rw/rw.txt | awk '{print tolower($0)}' | tr '\t' '\n' > "${DATADIR}"/queries.txt
cat "${DATADIR}"/queries.txt | ./fasttext print-word-vectors "${RESULTDIR}"/fil9.bin > "${RESULTDIR}"/vectors.txt
python eval.py -m "${RESULTDIR}"/vectors.txt -d "${DATADIR}"/rw/rw.txt
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/tests/�������������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�014030� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/tests/fetch_test_data.sh�������������������������������������������������������������0000755�0001750�0000176�00000014630�13651775021�017514� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# Copyright (c) 2016-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
#
DATADIR=${DATADIR:-data}
report_error() {
echo "Error on line $1 of $0"
}
myshuf() {
perl -MList::Util=shuffle -e 'print shuffle(<>);' "$@";
}
normalize_text() {
tr '[:upper:]' '[:lower:]' | sed -e 's/^/__label__/g' | \
sed -e "s/'/ ' /g" -e 's/"//g' -e 's/\./ \. /g' -e 's/
/ /g' \
-e 's/,/ , /g' -e 's/(/ ( /g' -e 's/)/ ) /g' -e 's/\!/ \! /g' \
-e 's/\?/ \? /g' -e 's/\;/ /g' -e 's/\:/ /g' | tr -s " " | myshuf
}
set -e
trap 'report_error $LINENO' ERR
mkdir -p "${DATADIR}"
# Unsupervised datasets
data_result="${DATADIR}/rw_queries.txt"
if [ ! -f "$data_result" ]
then
cut -f 1,2 "${DATADIR}"/rw/rw.txt | awk '{print tolower($0)}' | tr '\t' '\n' > "$data_result" || rm -f "$data_result"
fi
data_result="${DATADIR}/enwik9.zip"
if [ ! -f "$data_result" ] || \
[ $(md5sum "$data_result" | cut -f 1 -d ' ') != "3e773f8a1577fda2e27f871ca17f31fd" ]
then
wget -c http://mattmahoney.net/dc/enwik9.zip -P "${DATADIR}" || rm -f "$data_result"
unzip "$data_result" -d "${DATADIR}" || rm -f "$data_result"
fi
data_result="${DATADIR}/fil9"
if [ ! -f "$data_result" ]
then
perl wikifil.pl "${DATADIR}/enwik9" > "$data_result" || rm -f "$data_result"
fi
data_result="${DATADIR}/rw/rw.txt"
if [ ! -f "$data_result" ]
then
wget -c https://nlp.stanford.edu/~lmthang/morphoNLM/rw.zip -P "${DATADIR}"
unzip "${DATADIR}/rw.zip" -d "${DATADIR}" || rm -f "$data_result"
fi
# Supervised datasets
# Each datasets comes with a .train and a .test to measure performance
echo "Downloading dataset dbpedia"
data_result="${DATADIR}/dbpedia_csv.tar.gz"
if [ ! -f "$data_result" ] || \
[ $(md5sum "$data_result" | cut -f 1 -d ' ') != "8139d58cf075c7f70d085358e73af9b3" ]
then
wget -c "https://github.com/le-scientifique/torchDatasets/raw/master/dbpedia_csv.tar.gz" -O "$data_result"
tar -xzvf "$data_result" -C "${DATADIR}"
fi
data_result="${DATADIR}/dbpedia.train"
if [ ! -f "$data_result" ]
then
cat "${DATADIR}/dbpedia_csv/train.csv" | normalize_text > "$data_result" || rm -f "$data_result"
fi
data_result="${DATADIR}/dbpedia.test"
if [ ! -f "$data_result" ]
then
cat "${DATADIR}/dbpedia_csv/test.csv" | normalize_text > "$data_result" || rm -f "$data_result"
fi
echo "Downloading dataset tatoeba for langid"
data_result="${DATADIR}"/langid/all.txt
if [ ! -f "$data_result" ]
then
mkdir -p "${DATADIR}"/langid
wget http://downloads.tatoeba.org/exports/sentences.tar.bz2 -O "${DATADIR}"/langid/sentences.tar.bz2
tar xvfj "${DATADIR}"/langid/sentences.tar.bz2 --directory "${DATADIR}"/langid || exit 1
awk -F"\t" '{print"__label__"$2" "$3}' < "${DATADIR}"/langid/sentences.csv | shuf > "$data_result"
fi
data_result="${DATADIR}/langid.train"
if [ ! -f "$data_result" ]
then
tail -n +10001 "${DATADIR}"/langid/all.txt > "$data_result"
fi
data_result="${DATADIR}/langid.valid"
if [ ! -f "$data_result" ]
then
head -n 10000 "${DATADIR}"/langid/all.txt > "$data_result"
fi
echo "Downloading cooking dataset"
data_result="${DATADIR}"/cooking/cooking.stackexchange.txt
if [ ! -f "$data_result" ]
then
mkdir -p "${DATADIR}"/cooking/
wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz -O "${DATADIR}"/cooking/cooking.stackexchange.tar.gz
tar xvzf "${DATADIR}"/cooking/cooking.stackexchange.tar.gz --directory "${DATADIR}"/cooking || exit 1
cat "${DATADIR}"/cooking/cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > "${DATADIR}"/cooking/cooking.preprocessed.txt
fi
data_result="${DATADIR}"/cooking.train
if [ ! -f "$data_result" ]
then
head -n 12404 "${DATADIR}"/cooking/cooking.preprocessed.txt > "${DATADIR}"/cooking.train
fi
data_result="${DATADIR}"/cooking.valid
if [ ! -f "$data_result" ]
then
tail -n 3000 "${DATADIR}"/cooking/cooking.preprocessed.txt > "${DATADIR}"/cooking.valid
fi
echo "Checking for YFCC100M"
data_result="${DATADIR}"/YFCC100M/train
if [ ! -f "$data_result" ]
then
echo 'Download YFCC100M, unpack it and place train into the following path: '"$data_result"
echo 'You can download YFCC100M at :'"https://fasttext.cc/docs/en/dataset.html"
echo 'After you download this, run the script again'
exit 1
fi
data_result="${DATADIR}"/YFCC100M/test
if [ ! -f "$data_result" ]
then
echo 'Download YFCC100M, unpack it and place test into the following path: '"$data_result"
echo 'You can download YFCC100M at :'"https://fasttext.cc/docs/en/dataset.html"
echo 'After you download this, run the script again'
exit 1
fi
DATASET=(
ag_news
sogou_news
dbpedia
yelp_review_polarity
yelp_review_full
yahoo_answers
amazon_review_full
amazon_review_polarity
)
ID=(
0Bz8a_Dbh9QhbUDNpeUdjb0wxRms # ag_news
0Bz8a_Dbh9QhbUkVqNEszd0pHaFE # sogou_news
0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k # dbpedia
0Bz8a_Dbh9QhbNUpYQ2N3SGlFaDg # yelp_review_polarity
0Bz8a_Dbh9QhbZlU4dXhHTFhZQU0 # yelp_review_full
0Bz8a_Dbh9Qhbd2JNdDBsQUdocVU # yahoo_answers
0Bz8a_Dbh9QhbZVhsUnRWRDhETzA # amazon_review_full
0Bz8a_Dbh9QhbaW12WVVZS2drcnM # amazon_review_polarity
)
# Small datasets first
for i in {0..0}
do
echo "Downloading dataset ${DATASET[i]}"
if [ ! -f "${DATADIR}/${DATASET[i]}.train" ]
then
wget -c "https://drive.google.com/uc?export=download&id=${ID[i]}" -O "${DATADIR}/${DATASET[i]}_csv.tar.gz"
tar -xzvf "${DATADIR}/${DATASET[i]}_csv.tar.gz" -C "${DATADIR}"
cat "${DATADIR}/${DATASET[i]}_csv/train.csv" | normalize_text > "${DATADIR}/${DATASET[i]}.train"
cat "${DATADIR}/${DATASET[i]}_csv/test.csv" | normalize_text > "${DATADIR}/${DATASET[i]}.test"
fi
done
# Large datasets require a bit more work due to the extra request page
for i in {1..7}
do
echo "Downloading dataset ${DATASET[i]}"
if [ ! -f "${DATADIR}/${DATASET[i]}.train" ]
then
curl -c /tmp/cookies "https://drive.google.com/uc?export=download&id=${ID[i]}" > /tmp/intermezzo.html
curl -L -b /tmp/cookies "https://drive.google.com$(cat /tmp/intermezzo.html | grep -Po 'uc-download-link" [^>]* href="\K[^"]*' | sed 's/\&/\&/g')" > "${DATADIR}/${DATASET[i]}_csv.tar.gz"
tar -xzvf "${DATADIR}/${DATASET[i]}_csv.tar.gz" -C "${DATADIR}"
cat "${DATADIR}/${DATASET[i]}_csv/train.csv" | normalize_text > "${DATADIR}/${DATASET[i]}.train"
cat "${DATADIR}/${DATASET[i]}_csv/test.csv" | normalize_text > "${DATADIR}/${DATASET[i]}.test"
fi
done
��������������������������������������������������������������������������������������������������������fastText-0.9.2/README.md����������������������������������������������������������������������������0000644�0001750�0000176�00000032454�13651775021�014155� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# fastText
[fastText](https://fasttext.cc/) is a library for efficient learning of word representations and sentence classification.
[](https://circleci.com/gh/facebookresearch/fastText/tree/master)
## Table of contents
* [Resources](#resources)
* [Models](#models)
* [Supplementary data](#supplementary-data)
* [FAQ](#faq)
* [Cheatsheet](#cheatsheet)
* [Requirements](#requirements)
* [Building fastText](#building-fasttext)
* [Getting the source code](#getting-the-source-code)
* [Building fastText using make (preferred)](#building-fasttext-using-make-preferred)
* [Building fastText using cmake](#building-fasttext-using-cmake)
* [Building fastText for Python](#building-fasttext-for-python)
* [Example use cases](#example-use-cases)
* [Word representation learning](#word-representation-learning)
* [Obtaining word vectors for out-of-vocabulary words](#obtaining-word-vectors-for-out-of-vocabulary-words)
* [Text classification](#text-classification)
* [Full documentation](#full-documentation)
* [References](#references)
* [Enriching Word Vectors with Subword Information](#enriching-word-vectors-with-subword-information)
* [Bag of Tricks for Efficient Text Classification](#bag-of-tricks-for-efficient-text-classification)
* [FastText.zip: Compressing text classification models](#fasttextzip-compressing-text-classification-models)
* [Join the fastText community](#join-the-fasttext-community)
* [License](#license)
## Resources
### Models
- Recent state-of-the-art [English word vectors](https://fasttext.cc/docs/en/english-vectors.html).
- Word vectors for [157 languages trained on Wikipedia and Crawl](https://github.com/facebookresearch/fastText/blob/master/docs/crawl-vectors.md).
- Models for [language identification](https://fasttext.cc/docs/en/language-identification.html#content) and [various supervised tasks](https://fasttext.cc/docs/en/supervised-models.html#content).
### Supplementary data
- The preprocessed [YFCC100M data](https://fasttext.cc/docs/en/dataset.html#content) used in [2].
### FAQ
You can find [answers to frequently asked questions](https://fasttext.cc/docs/en/faqs.html#content) on our [website](https://fasttext.cc/).
### Cheatsheet
We also provide a [cheatsheet](https://fasttext.cc/docs/en/cheatsheet.html#content) full of useful one-liners.
## Requirements
We are continuously building and testing our library, CLI and Python bindings under various docker images using [circleci](https://circleci.com/).
Generally, **fastText** builds on modern Mac OS and Linux distributions.
Since it uses some C++11 features, it requires a compiler with good C++11 support.
These include :
* (g++-4.7.2 or newer) or (clang-3.3 or newer)
Compilation is carried out using a Makefile, so you will need to have a working **make**.
If you want to use **cmake** you need at least version 2.8.9.
One of the oldest distributions we successfully built and tested the CLI under is [Debian jessie](https://www.debian.org/releases/jessie/).
For the word-similarity evaluation script you will need:
* Python 2.6 or newer
* NumPy & SciPy
For the python bindings (see the subdirectory python) you will need:
* Python version 2.7 or >=3.4
* NumPy & SciPy
* [pybind11](https://github.com/pybind/pybind11)
One of the oldest distributions we successfully built and tested the Python bindings under is [Debian jessie](https://www.debian.org/releases/jessie/).
If these requirements make it impossible for you to use fastText, please open an issue and we will try to accommodate you.
## Building fastText
We discuss building the latest stable version of fastText.
### Getting the source code
You can find our [latest stable release](https://github.com/facebookresearch/fastText/releases/latest) in the usual place.
There is also the master branch that contains all of our most recent work, but comes along with all the usual caveats of an unstable branch. You might want to use this if you are a developer or power-user.
### Building fastText using make (preferred)
```
$ wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
$ unzip v0.9.2.zip
$ cd fastText-0.9.2
$ make
```
This will produce object files for all the classes as well as the main binary `fasttext`.
If you do not plan on using the default system-wide compiler, update the two macros defined at the beginning of the Makefile (CC and INCLUDES).
### Building fastText using cmake
For now this is not part of a release, so you will need to clone the master branch.
```
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ mkdir build && cd build && cmake ..
$ make && make install
```
This will create the fasttext binary and also all relevant libraries (shared, static, PIC).
### Building fastText for Python
For now this is not part of a release, so you will need to clone the master branch.
```
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ pip install .
```
For further information and introduction see python/README.md
## Example use cases
This library has two main use cases: word representation learning and text classification.
These were described in the two papers [1](#enriching-word-vectors-with-subword-information) and [2](#bag-of-tricks-for-efficient-text-classification).
### Word representation learning
In order to learn word vectors, as described in [1](#enriching-word-vectors-with-subword-information), do:
```
$ ./fasttext skipgram -input data.txt -output model
```
where `data.txt` is a training file containing `UTF-8` encoded text.
By default the word vectors will take into account character n-grams from 3 to 6 characters.
At the end of optimization the program will save two files: `model.bin` and `model.vec`.
`model.vec` is a text file containing the word vectors, one per line.
`model.bin` is a binary file containing the parameters of the model along with the dictionary and all hyper parameters.
The binary file can be used later to compute word vectors or to restart the optimization.
### Obtaining word vectors for out-of-vocabulary words
The previously trained model can be used to compute word vectors for out-of-vocabulary words.
Provided you have a text file `queries.txt` containing words for which you want to compute vectors, use the following command:
```
$ ./fasttext print-word-vectors model.bin < queries.txt
```
This will output word vectors to the standard output, one vector per line.
This can also be used with pipes:
```
$ cat queries.txt | ./fasttext print-word-vectors model.bin
```
See the provided scripts for an example. For instance, running:
```
$ ./word-vector-example.sh
```
will compile the code, download data, compute word vectors and evaluate them on the rare words similarity dataset RW [Thang et al. 2013].
### Text classification
This library can also be used to train supervised text classifiers, for instance for sentiment analysis.
In order to train a text classifier using the method described in [2](#bag-of-tricks-for-efficient-text-classification), use:
```
$ ./fasttext supervised -input train.txt -output model
```
where `train.txt` is a text file containing a training sentence per line along with the labels.
By default, we assume that labels are words that are prefixed by the string `__label__`.
This will output two files: `model.bin` and `model.vec`.
Once the model was trained, you can evaluate it by computing the precision and recall at k (P@k and R@k) on a test set using:
```
$ ./fasttext test model.bin test.txt k
```
The argument `k` is optional, and is equal to `1` by default.
In order to obtain the k most likely labels for a piece of text, use:
```
$ ./fasttext predict model.bin test.txt k
```
or use `predict-prob` to also get the probability for each label
```
$ ./fasttext predict-prob model.bin test.txt k
```
where `test.txt` contains a piece of text to classify per line.
Doing so will print to the standard output the k most likely labels for each line.
The argument `k` is optional, and equal to `1` by default.
See `classification-example.sh` for an example use case.
In order to reproduce results from the paper [2](#bag-of-tricks-for-efficient-text-classification), run `classification-results.sh`, this will download all the datasets and reproduce the results from Table 1.
If you want to compute vector representations of sentences or paragraphs, please use:
```
$ ./fasttext print-sentence-vectors model.bin < text.txt
```
This assumes that the `text.txt` file contains the paragraphs that you want to get vectors for.
The program will output one vector representation per line in the file.
You can also quantize a supervised model to reduce its memory usage with the following command:
```
$ ./fasttext quantize -output model
```
This will create a `.ftz` file with a smaller memory footprint. All the standard functionality, like `test` or `predict` work the same way on the quantized models:
```
$ ./fasttext test model.ftz test.txt
```
The quantization procedure follows the steps described in [3](#fasttextzip-compressing-text-classification-models). You can
run the script `quantization-example.sh` for an example.
## Full documentation
Invoke a command without arguments to list available arguments and their default values:
```
$ ./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-verbose verbosity level [2]
The following arguments for the dictionary are optional:
-minCount minimal number of word occurrences [1]
-minCountLabel minimal number of label occurrences [0]
-wordNgrams max length of word ngram [1]
-bucket number of buckets [2000000]
-minn min length of char ngram [0]
-maxn max length of char ngram [0]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
The following arguments for training are optional:
-lr learning rate [0.1]
-lrUpdateRate change the rate of updates for the learning rate [100]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-neg number of negatives sampled [5]
-loss loss function {ns, hs, softmax} [softmax]
-thread number of threads [12]
-pretrainedVectors pretrained word vectors for supervised learning []
-saveOutput whether output params should be saved [0]
The following arguments for quantization are optional:
-cutoff number of words and ngrams to retain [0]
-retrain finetune embeddings if a cutoff is applied [0]
-qnorm quantizing the norm separately [0]
-qout quantizing the classifier [0]
-dsub size of each sub-vector [2]
```
Defaults may vary by mode. (Word-representation modes `skipgram` and `cbow` use a default `-minCount` of 5.)
## References
Please cite [1](#enriching-word-vectors-with-subword-information) if using this code for learning word representations or [2](#bag-of-tricks-for-efficient-text-classification) if using for text classification.
### Enriching Word Vectors with Subword Information
[1] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
```
@article{bojanowski2017enriching,
title={Enriching Word Vectors with Subword Information},
author={Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas},
journal={Transactions of the Association for Computational Linguistics},
volume={5},
year={2017},
issn={2307-387X},
pages={135--146}
}
```
### Bag of Tricks for Efficient Text Classification
[2] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
```
@InProceedings{joulin2017bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
booktitle={Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers},
month={April},
year={2017},
publisher={Association for Computational Linguistics},
pages={427--431},
}
```
### FastText.zip: Compressing text classification models
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
```
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
```
(\* These authors contributed equally.)
## Join the fastText community
* Facebook page: https://www.facebook.com/groups/1174547215919768
* Google group: https://groups.google.com/forum/#!forum/fasttext-library
* Contact: [egrave@fb.com](mailto:egrave@fb.com), [bojanowski@fb.com](mailto:bojanowski@fb.com), [ajoulin@fb.com](mailto:ajoulin@fb.com), [tmikolov@fb.com](mailto:tmikolov@fb.com)
See the CONTRIBUTING file for information about how to help out.
## License
fastText is MIT-licensed.
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/��������������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�013616� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/python-module.md����������������������������������������������������������������0000644�0001750�0000176�00000032575�13651775021�016760� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: python-module
title: Python module
---
In this document we present how to use fastText in python.
## Table of contents
* [Requirements](#requirements)
* [Installation](#installation)
* [Usage overview](#usage-overview)
* [Word representation model](#word-representation-model)
* [Text classification model](#text-classification-model)
* [IMPORTANT: Preprocessing data / encoding conventions](#important-preprocessing-data-encoding-conventions)
* [More examples](#more-examples)
* [API](#api)
* [`train_unsupervised` parameters](#train_unsupervised-parameters)
* [`train_supervised` parameters](#train_supervised-parameters)
* [`model` object](#model-object)
# Requirements
[fastText](https://fasttext.cc/) builds on modern Mac OS and Linux distributions.
Since it uses C\++11 features, it requires a compiler with good C++11 support. You will need [Python](https://www.python.org/) (version 2.7 or ≥ 3.4), [NumPy](http://www.numpy.org/) & [SciPy](https://www.scipy.org/) and [pybind11](https://github.com/pybind/pybind11).
# Installation
To install the latest release, you can do :
```bash
$ pip install fasttext
```
or, to get the latest development version of fasttext, you can install from our github repository :
```bash
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ sudo pip install .
$ # or :
$ sudo python setup.py install
```
# Usage overview
## Word representation model
In order to learn word vectors, as [described here](/docs/en/references.html#enriching-word-vectors-with-subword-information), we can use `fasttext.train_unsupervised` function like this:
```py
import fasttext
# Skipgram model :
model = fasttext.train_unsupervised('data.txt', model='skipgram')
# or, cbow model :
model = fasttext.train_unsupervised('data.txt', model='cbow')
```
where `data.txt` is a training file containing utf-8 encoded text.
The returned `model` object represents your learned model, and you can use it to retrieve information.
```py
print(model.words) # list of words in dictionary
print(model['king']) # get the vector of the word 'king'
```
### Saving and loading a model object
You can save your trained model object by calling the function `save_model`.
```py
model.save_model("model_filename.bin")
```
and retrieve it later thanks to the function `load_model` :
```py
model = fasttext.load_model("model_filename.bin")
```
For more information about word representation usage of fasttext, you can refer to our [word representations tutorial](/docs/en/unsupervised-tutorial.html).
## Text classification model
In order to train a text classifier using the method [described here](/docs/en/references.html#bag-of-tricks-for-efficient-text-classification), we can use `fasttext.train_supervised` function like this:
```py
import fasttext
model = fasttext.train_supervised('data.train.txt')
```
where `data.train.txt` is a text file containing a training sentence per line along with the labels. By default, we assume that labels are words that are prefixed by the string `__label__`
Once the model is trained, we can retrieve the list of words and labels:
```py
print(model.words)
print(model.labels)
```
To evaluate our model by computing the precision at 1 (P@1) and the recall on a test set, we use the `test` function:
```py
def print_results(N, p, r):
print("N\t" + str(N))
print("P@{}\t{:.3f}".format(1, p))
print("R@{}\t{:.3f}".format(1, r))
print_results(*model.test('test.txt'))
```
We can also predict labels for a specific text :
```py
model.predict("Which baking dish is best to bake a banana bread ?")
```
By default, `predict` returns only one label : the one with the highest probability. You can also predict more than one label by specifying the parameter `k`:
```py
model.predict("Which baking dish is best to bake a banana bread ?", k=3)
```
If you want to predict more than one sentence you can pass an array of strings :
```py
model.predict(["Which baking dish is best to bake a banana bread ?", "Why not put knives in the dishwasher?"], k=3)
```
Of course, you can also save and load a model to/from a file as [in the word representation usage](#saving-and-loading-a-model-object).
For more information about text classification usage of fasttext, you can refer to our [text classification tutorial](/docs/en/supervised-tutorial.html).
### Compress model files with quantization
When you want to save a supervised model file, fastText can compress it in order to have a much smaller model file by sacrificing only a little bit performance.
```py
# with the previously trained `model` object, call :
model.quantize(input='data.train.txt', retrain=True)
# then display results and save the new model :
print_results(*model.test(valid_data))
model.save_model("model_filename.ftz")
```
`model_filename.ftz` will have a much smaller size than `model_filename.bin`.
For further reading on quantization, you can refer to [this paragraph from our blog post](/blog/2017/10/02/blog-post.html#model-compression).
## IMPORTANT: Preprocessing data / encoding conventions
In general it is important to properly preprocess your data. In particular our example scripts in the [root folder](https://github.com/facebookresearch/fastText) do this.
fastText assumes UTF-8 encoded text. All text must be [unicode for Python2](https://docs.python.org/2/library/functions.html#unicode) and [str for Python3](https://docs.python.org/3.5/library/stdtypes.html#textseq). The passed text will be [encoded as UTF-8 by pybind11](https://pybind11.readthedocs.io/en/master/advanced/cast/strings.html?highlight=utf-8#strings-bytes-and-unicode-conversions) before passed to the fastText C++ library. This means it is important to use UTF-8 encoded text when building a model. On Unix-like systems you can convert text using [iconv](https://en.wikipedia.org/wiki/Iconv).
fastText will tokenize (split text into pieces) based on the following ASCII characters (bytes). In particular, it is not aware of UTF-8 whitespace. We advice the user to convert UTF-8 whitespace / word boundaries into one of the following symbols as appropiate.
* space
* tab
* vertical tab
* carriage return
* formfeed
* the null character
The newline character is used to delimit lines of text. In particular, the EOS token is appended to a line of text if a newline character is encountered. The only exception is if the number of tokens exceeds the MAX\_LINE\_SIZE constant as defined in the [Dictionary header](https://github.com/facebookresearch/fastText/blob/master/src/dictionary.h). This means if you have text that is not separate by newlines, such as the [fil9 dataset](http://mattmahoney.net/dc/textdata), it will be broken into chunks with MAX\_LINE\_SIZE of tokens and the EOS token is not appended.
The length of a token is the number of UTF-8 characters by considering the [leading two bits of a byte](https://en.wikipedia.org/wiki/UTF-8#Description) to identify [subsequent bytes of a multi-byte sequence](https://github.com/facebookresearch/fastText/blob/master/src/dictionary.cc). Knowing this is especially important when choosing the minimum and maximum length of subwords. Further, the EOS token (as specified in the [Dictionary header](https://github.com/facebookresearch/fastText/blob/master/src/dictionary.h)) is considered a character and will not be broken into subwords.
## More examples
In order to have a better knowledge of fastText models, please consider the main [README](https://github.com/facebookresearch/fastText/blob/master/README.md) and in particular [the tutorials on our website](https://fasttext.cc/docs/en/supervised-tutorial.html).
You can find further python examples in [the doc folder](https://github.com/facebookresearch/fastText/tree/master/python/doc/examples).
As with any package you can get help on any Python function using the help function.
For example
```
+>>> import fasttext
+>>> help(fasttext.FastText)
Help on module fasttext.FastText in fasttext:
NAME
fasttext.FastText
DESCRIPTION
# Copyright (c) 2017-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
FUNCTIONS
load_model(path)
Load a model given a filepath and return a model object.
tokenize(text)
Given a string of text, tokenize it and return a list of tokens
[...]
```
# API
## `train_unsupervised` parameters
```python
input # training file path (required)
model # unsupervised fasttext model {cbow, skipgram} [skipgram]
lr # learning rate [0.05]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [5]
minn # min length of char ngram [3]
maxn # max length of char ngram [6]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [ns]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
verbose # verbose [2]
```
## `train_supervised` parameters
```python
input # training file path (required)
lr # learning rate [0.1]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [1]
minCountLabel # minimal number of label occurences [1]
minn # min length of char ngram [0]
maxn # max length of char ngram [0]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [softmax]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
label # label prefix ['__label__']
verbose # verbose [2]
pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
```
## `model` object
`train_supervised`, `train_unsupervised` and `load_model` functions return an instance of `_FastText` class, that we generaly name `model` object.
This object exposes those training arguments as properties : `lr`, `dim`, `ws`, `epoch`, `minCount`, `minCountLabel`, `minn`, `maxn`, `neg`, `wordNgrams`, `loss`, `bucket`, `thread`, `lrUpdateRate`, `t`, `label`, `verbose`, `pretrainedVectors`. So `model.wordNgrams` will give you the max length of word ngram used for training this model.
In addition, the object exposes several functions :
```python
get_dimension # Get the dimension (size) of a lookup vector (hidden layer).
# This is equivalent to `dim` property.
get_input_vector # Given an index, get the corresponding vector of the Input Matrix.
get_input_matrix # Get a copy of the full input matrix of a Model.
get_labels # Get the entire list of labels of the dictionary
# This is equivalent to `labels` property.
get_line # Split a line of text into words and labels.
get_output_matrix # Get a copy of the full output matrix of a Model.
get_sentence_vector # Given a string, get a single vector represenation. This function
# assumes to be given a single line of text. We split words on
# whitespace (space, newline, tab, vertical tab) and the control
# characters carriage return, formfeed and the null character.
get_subword_id # Given a subword, return the index (within input matrix) it hashes to.
get_subwords # Given a word, get the subwords and their indicies.
get_word_id # Given a word, get the word id within the dictionary.
get_word_vector # Get the vector representation of word.
get_words # Get the entire list of words of the dictionary
# This is equivalent to `words` property.
is_quantized # whether the model has been quantized
predict # Given a string, get a list of labels and a list of corresponding probabilities.
quantize # Quantize the model reducing the size of the model and it's memory footprint.
save_model # Save the model to the given path
test # Evaluate supervised model using file given by path
test_label # Return the precision and recall score for each label.
```
The properties `words`, `labels` return the words and labels from the dictionary :
```py
model.words # equivalent to model.get_words()
model.labels # equivalent to model.get_labels()
```
The object overrides `__getitem__` and `__contains__` functions in order to return the representation of a word and to check if a word is in the vocabulary.
```py
model['king'] # equivalent to model.get_word_vector('king')
'king' in model # equivalent to `'king' in model.get_words()`
```
�����������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/english-vectors.md��������������������������������������������������������������0000644�0001750�0000176�00000004764�13651775021�017267� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: english-vectors
title: English word vectors
---
This page gathers several pre-trained word vectors trained using fastText.
### Download pre-trained word vectors
Pre-trained word vectors learned on different sources can be downloaded below:
1. [wiki-news-300d-1M.vec.zip](https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip): 1 million word vectors trained on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens).
2. [wiki-news-300d-1M-subword.vec.zip](https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M-subword.vec.zip): 1 million word vectors trained with subword infomation on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens).
3. [crawl-300d-2M.vec.zip](https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M.vec.zip): 2 million word vectors trained on Common Crawl (600B tokens).
4. [crawl-300d-2M-subword.zip](https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M-subword.zip): 2 million word vectors trained with subword information on Common Crawl (600B tokens).
### Format
The first line of the file contains the number of words in the vocabulary and the size of the vectors.
Each line contains a word followed by its vectors, like in the default fastText text format.
Each value is space separated. Words are ordered by descending frequency.
These text models can easily be loaded in Python using the following code:
```python
import io
def load_vectors(fname):
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
data = {}
for line in fin:
tokens = line.rstrip().split(' ')
data[tokens[0]] = map(float, tokens[1:])
return data
```
### License
These word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
### References
If you use these word vectors, please cite the following paper:
T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, A. Joulin. [*Advances in Pre-Training Distributed Word Representations*](https://arxiv.org/abs/1712.09405)
```markup
@inproceedings{mikolov2018advances,
title={Advances in Pre-Training Distributed Word Representations},
author={Mikolov, Tomas and Grave, Edouard and Bojanowski, Piotr and Puhrsch, Christian and Joulin, Armand},
booktitle={Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018)},
year={2018}
}
```
������������fastText-0.9.2/docs/cheatsheet.md�������������������������������������������������������������������0000644�0001750�0000176�00000003460�13651775021�016260� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: cheatsheet
title: Cheatsheet
---
## Word representation learning
In order to learn word vectors do:
```bash
$ ./fasttext skipgram -input data.txt -output model
```
## Obtaining word vectors
Print word vectors for a text file `queries.txt` containing words.
```bash
$ ./fasttext print-word-vectors model.bin < queries.txt
```
## Text classification
In order to train a text classifier do:
```bash
$ ./fasttext supervised -input train.txt -output model
```
Once the model was trained, you can evaluate it by computing the precision and recall at k (P@k and R@k) on a test set using:
```bash
$ ./fasttext test model.bin test.txt 1
```
In order to obtain the k most likely labels for a piece of text, use:
```bash
$ ./fasttext predict model.bin test.txt k
```
In order to obtain the k most likely labels and their associated probabilities for a piece of text, use:
```bash
$ ./fasttext predict-prob model.bin test.txt k
```
If you want to compute vector representations of sentences or paragraphs, please use:
```bash
$ ./fasttext print-sentence-vectors model.bin < text.txt
```
## Quantization
In order to create a `.ftz` file with a smaller memory footprint do:
```bash
$ ./fasttext quantize -output model
```
All other commands such as test also work with this model
```bash
$ ./fasttext test model.ftz test.txt
```
## Autotune
Activate hyperparameter optimization with `-autotune-validation` argument:
```bash
$ ./fasttext supervised -input train.txt -output model -autotune-validation valid.txt
```
Set timeout (in seconds):
```bash
$ ./fasttext supervised -input train.txt -output model -autotune-validation valid.txt -autotune-duration 600
```
Constrain the final model size:
```bash
$ ./fasttext supervised -input train.txt -output model -autotune-validation valid.txt -autotune-modelsize 2M
```
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/unsupervised-tutorials.md�������������������������������������������������������0000644�0001750�0000176�00000047263�13651775021�020734� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: unsupervised-tutorial
title: Word representations
---
A popular idea in modern machine learning is to represent words by vectors. These vectors capture hidden information about a language, like word analogies or semantic. It is also used to improve performance of text classifiers.
In this tutorial, we show how to build these word vectors with the fastText tool. To download and install fastText, follow the first steps of [the tutorial on text classification](https://fasttext.cc/docs/en/supervised-tutorial.html).
## Getting the data
In order to compute word vectors, you need a large text corpus. Depending on the corpus, the word vectors will capture different information. In this tutorial, we focus on Wikipedia's articles but other sources could be considered, like news or Webcrawl (more examples [here](http://statmt.org/)). To download a raw dump of Wikipedia, run the following command:
```bash
wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
```
Downloading the Wikipedia corpus takes some time. Instead, lets restrict our study to the first 1 billion bytes of English Wikipedia. They can be found on Matt Mahoney's [website](http://mattmahoney.net/):
```bash
$ mkdir data
$ wget -c http://mattmahoney.net/dc/enwik9.zip -P data
$ unzip data/enwik9.zip -d data
```
A raw Wikipedia dump contains a lot of HTML / XML data. We pre-process it with the wikifil.pl script bundled with fastText (this script was originally developed by Matt Mahoney, and can be found on his [website](http://mattmahoney.net/)).
```bash
$ perl wikifil.pl data/enwik9 > data/fil9
```
We can check the file by running the following command:
```bash
$ head -c 80 data/fil9
anarchism originated as a term of abuse first used against early working class
```
The text is nicely pre-processed and can be used to learn our word vectors.
## Training word vectors
Learning word vectors on this data can now be achieved with a single command:
```bash
$ mkdir result
$ ./fasttext skipgram -input data/fil9 -output result/fil9
```
To decompose this command line: ./fastext calls the binary fastText executable (see how to install fastText [here](https://fasttext.cc/docs/en/support.html)) with the 'skipgram' model (it can also be 'cbow'). We then specify the requires options '-input' for the location of the data and '-output' for the location where the word representations will be saved.
While fastText is running, the progress and estimated time to completion is shown on your screen. Once the program finishes, there should be two files in the result directory:
```bash
$ ls -l result
-rw-r-r-- 1 bojanowski 1876110778 978480850 Dec 20 11:01 fil9.bin
-rw-r-r-- 1 bojanowski 1876110778 190004182 Dec 20 11:01 fil9.vec
```
The `fil9.bin` file is a binary file that stores the whole fastText model and can be subsequently loaded. The `fil9.vec` file is a text file that contains the word vectors, one per line for each word in the vocabulary:
```bash
$ head -n 4 result/fil9.vec
218316 100
the -0.10363 -0.063669 0.032436 -0.040798 0.53749 0.00097867 0.10083 0.24829 ...
of -0.0083724 0.0059414 -0.046618 -0.072735 0.83007 0.038895 -0.13634 0.60063 ...
one 0.32731 0.044409 -0.46484 0.14716 0.7431 0.24684 -0.11301 0.51721 0.73262 ...
```
The first line is a header containing the number of words and the dimensionality of the vectors. The subsequent lines are the word vectors for all words in the vocabulary, sorted by decreasing frequency.
Learning word vectors on this data can now be achieved with a single command:
```py
>>> import fasttext
>>> model = fasttext.train_unsupervised('data/fil9')
```
While fastText is running, the progress and estimated time to completion is shown on your screen. Once the training finishes, `model` variable contains information on the trained model, and can be used for querying:
```py
>>> model.words
[u'the', u'of', u'one', u'zero', u'and', u'in', u'two', u'a', u'nine', u'to', u'is', ...
```
It returns all words in the vocabulary, sorted by decreasing frequency. We can get the word vector by:
```py
>>> model.get_word_vector("the")
array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,
0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,
...
-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],
dtype=float32)
```
We can save this model on disk as a binary file:
```py
>>> model.save_model("result/fil9.bin")
```
and reload it later instead of training again:
```py
$ python
>>> import fasttext
>>> model = fasttext.load_model("result/fil9.bin")
```
## Advanced readers: skipgram versus cbow
fastText provides two models for computing word representations: skipgram and cbow ('**c**ontinuous-**b**ag-**o**f-**w**ords').
The skipgram model learns to predict a target word thanks to a nearby word. On the other hand, the cbow model predicts the target word according to its context. The context is represented as a bag of the words contained in a fixed size window around the target word.
Let us illustrate this difference with an example: given the sentence *'Poets have been mysteriously silent on the subject of cheese'* and the target word '*silent*', a skipgram model tries to predict the target using a random close-by word, like '*subject' *or* '*mysteriously*'**. *The cbow model takes all the words in a surrounding window, like {*been, *mysteriously*, on, the*}, and uses the sum of their vectors to predict the target. The figure below summarizes this difference with another example.
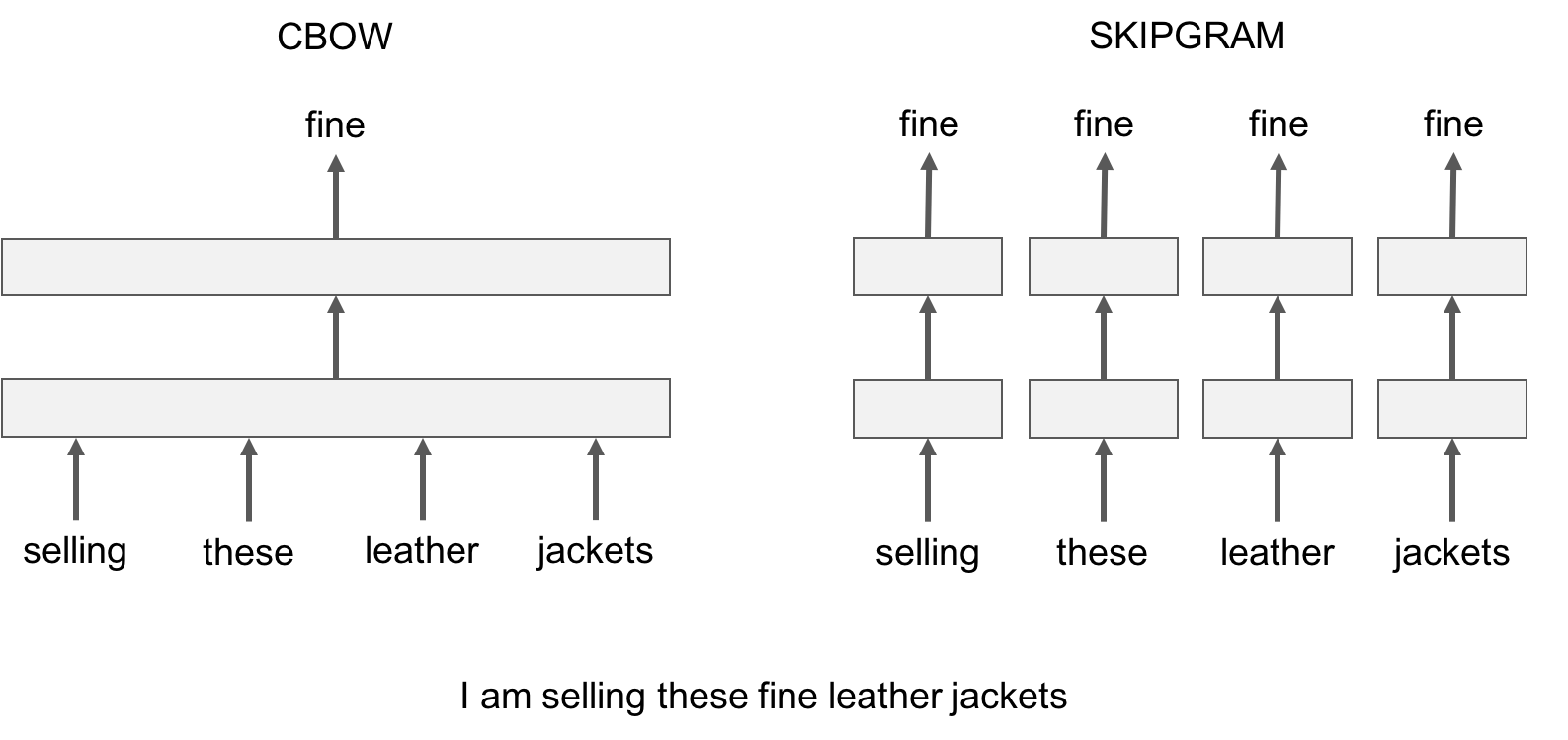
To train a cbow model with fastText, you run the following command:
```bash
./fasttext cbow -input data/fil9 -output result/fil9
```
```py
>>> import fasttext
>>> model = fasttext.train_unsupervised('data/fil9', "cbow")
```
In practice, we observe that skipgram models works better with subword information than cbow.
## Advanced readers: playing with the parameters
So far, we run fastText with the default parameters, but depending on the data, these parameters may not be optimal. Let us give an introduction to some of the key parameters for word vectors.
The most important parameters of the model are its dimension and the range of size for the subwords. The dimension (*dim*) controls the size of the vectors, the larger they are the more information they can capture but requires more data to be learned. But, if they are too large, they are harder and slower to train. By default, we use 100 dimensions, but any value in the 100-300 range is as popular. The subwords are all the substrings contained in a word between the minimum size (*minn*) and the maximal size (*maxn*). By default, we take all the subword between 3 and 6 characters, but other range could be more appropriate to different languages:
```bash
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5 -dim 300
```
```py
>>> import fasttext
>>> model = fasttext.train_unsupervised('data/fil9', minn=2, maxn=5, dim=300)
```
Depending on the quantity of data you have, you may want to change the parameters of the training. The *epoch* parameter controls how many times the model will loop over your data. By default, we loop over the dataset 5 times. If you dataset is extremely massive, you may want to loop over it less often. Another important parameter is the learning rate -*lr*. The higher the learning rate is, the faster the model converge to a solution but at the risk of overfitting to the dataset. The default value is 0.05 which is a good compromise. If you want to play with it we suggest to stay in the range of [0.01, 1]:
```bash
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -epoch 1 -lr 0.5
```
```py
>>> import fasttext
>>> model = fasttext.train_unsupervised('data/fil9', epoch=1, lr=0.5)
```
Finally , fastText is multi-threaded and uses 12 threads by default. If you have less CPU cores (say 4), you can easily set the number of threads using the *thread* flag:
```bash
$ ./fasttext skipgram -input data/fil9 -output result/fil9 -thread 4
```
```py
>>> import fasttext
>>> model = fasttext.train_unsupervised('data/fil9', thread=4)
```
## Printing word vectors
Searching and printing word vectors directly from the `fil9.vec` file is cumbersome. Fortunately, there is a `print-word-vectors` functionality in fastText.
For example, we can print the word vectors of words *asparagus,* *pidgey* and *yellow* with the following command:
```bash
$ echo "asparagus pidgey yellow" | ./fasttext print-word-vectors result/fil9.bin
asparagus 0.46826 -0.20187 -0.29122 -0.17918 0.31289 -0.31679 0.17828 -0.04418 ...
pidgey -0.16065 -0.45867 0.10565 0.036952 -0.11482 0.030053 0.12115 0.39725 ...
yellow -0.39965 -0.41068 0.067086 -0.034611 0.15246 -0.12208 -0.040719 -0.30155 ...
```
```py
>>> [model.get_word_vector(x) for x in ["asparagus", "pidgey", "yellow"]]
[array([-0.25751096, -0.18716481, 0.06921121, 0.06455903, 0.29168844,
0.15426874, -0.33448914, -0.427215 , 0.7813013 , -0.10600132,
...
0.37090245, 0.39266172, -0.4555302 , 0.27452755, 0.00467369],
dtype=float32),
array([-0.20613593, -0.25325796, -0.2422259 , -0.21067499, 0.32879013,
0.7269511 , 0.3782259 , 0.11274897, 0.246764 , -0.6423613 ,
...
0.46302193, 0.2530962 , -0.35795924, 0.5755718 , 0.09843876],
dtype=float32),
array([-0.304823 , 0.2543754 , -0.2198013 , -0.25421786, 0.11219151,
0.38286993, -0.22636674, -0.54023844, 0.41095474, -0.3505803 ,
...
0.54788435, 0.36740595, -0.5678512 , 0.07523401, -0.08701935],
dtype=float32)]
```
A nice feature is that you can also query for words that did not appear in your data! Indeed words are represented by the sum of its substrings. As long as the unknown word is made of known substrings, there is a representation of it!
As an example let's try with a misspelled word:
```bash
$ echo "enviroment" | ./fasttext print-word-vectors result/fil9.bin
```
```py
>>> model.get_word_vector("enviroment")
```
You still get a word vector for it! But how good it is? Let's find out in the next sections!
## Nearest neighbor queries
A simple way to check the quality of a word vector is to look at its nearest neighbors. This give an intuition of the type of semantic information the vectors are able to capture.
This can be achieved with the nearest neighbor (*nn*) functionality. For example, we can query the 10 nearest neighbors of a word by running the following command:
```bash
$ ./fasttext nn result/fil9.bin
Pre-computing word vectors... done.
```
Then we are prompted to type our query word, let us try *asparagus* :
```bash
Query word? asparagus
beetroot 0.812384
tomato 0.806688
horseradish 0.805928
spinach 0.801483
licorice 0.791697
lingonberries 0.781507
asparagales 0.780756
lingonberry 0.778534
celery 0.774529
beets 0.773984
```
```py
>>> model.get_nearest_neighbors('asparagus')
[(0.812384, u'beetroot'), (0.806688, u'tomato'), (0.805928, u'horseradish'), (0.801483, u'spinach'), (0.791697, u'licorice'), (0.781507, u'lingonberries'), (0.780756, u'asparagales'), (0.778534, u'lingonberry'), (0.774529, u'celery'), (0.773984, u'beets')]
```
Nice! It seems that vegetable vectors are similar. Note that the nearest neighbor is the word *asparagus* itself, this means that this word appeared in the dataset. What about pokemons?
```bash
Query word? pidgey
pidgeot 0.891801
pidgeotto 0.885109
pidge 0.884739
pidgeon 0.787351
pok 0.781068
pikachu 0.758688
charizard 0.749403
squirtle 0.742582
beedrill 0.741579
charmeleon 0.733625
```
```py
>>> model.get_nearest_neighbors('pidgey')
[(0.891801, u'pidgeot'), (0.885109, u'pidgeotto'), (0.884739, u'pidge'), (0.787351, u'pidgeon'), (0.781068, u'pok'), (0.758688, u'pikachu'), (0.749403, u'charizard'), (0.742582, u'squirtle'), (0.741579, u'beedrill'), (0.733625, u'charmeleon')]
```
Different evolution of the same Pokemon have close-by vectors! But what about our misspelled word, is its vector close to anything reasonable? Let s find out:
```bash
Query word? enviroment
enviromental 0.907951
environ 0.87146
enviro 0.855381
environs 0.803349
environnement 0.772682
enviromission 0.761168
realclimate 0.716746
environment 0.702706
acclimatation 0.697196
ecotourism 0.697081
```
```py
>>> model.get_nearest_neighbors('enviroment')
[(0.907951, u'enviromental'), (0.87146, u'environ'), (0.855381, u'enviro'), (0.803349, u'environs'), (0.772682, u'environnement'), (0.761168, u'enviromission'), (0.716746, u'realclimate'), (0.702706, u'environment'), (0.697196, u'acclimatation'), (0.697081, u'ecotourism')]
```
Thanks to the information contained within the word, the vector of our misspelled word matches to reasonable words! It is not perfect but the main information has been captured.
## Advanced reader: measure of similarity
In order to find nearest neighbors, we need to compute a similarity score between words. Our words are represented by continuous word vectors and we can thus apply simple similarities to them. In particular we use the cosine of the angles between two vectors. This similarity is computed for all words in the vocabulary, and the 10 most similar words are shown. Of course, if the word appears in the vocabulary, it will appear on top, with a similarity of 1.
## Word analogies
In a similar spirit, one can play around with word analogies. For example, we can see if our model can guess what is to France, and what Berlin is to Germany.
This can be done with the *analogies* functionality. It takes a word triplet (like *Germany Berlin France*) and outputs the analogy:
```bash
$ ./fasttext analogies result/fil9.bin
Pre-computing word vectors... done.
Query triplet (A - B + C)? berlin germany france
paris 0.896462
bourges 0.768954
louveciennes 0.765569
toulouse 0.761916
valenciennes 0.760251
montpellier 0.752747
strasbourg 0.744487
meudon 0.74143
bordeaux 0.740635
pigneaux 0.736122
```
```py
>>> model.get_analogies("berlin", "germany", "france")
[(0.896462, u'paris'), (0.768954, u'bourges'), (0.765569, u'louveciennes'), (0.761916, u'toulouse'), (0.760251, u'valenciennes'), (0.752747, u'montpellier'), (0.744487, u'strasbourg'), (0.74143, u'meudon'), (0.740635, u'bordeaux'), (0.736122, u'pigneaux')]
```
The answer provided by our model is *Paris*, which is correct. Let's have a look at a less obvious example:
```bash
Query triplet (A - B + C)? psx sony nintendo
gamecube 0.803352
nintendogs 0.792646
playstation 0.77344
sega 0.772165
gameboy 0.767959
arcade 0.754774
playstationjapan 0.753473
gba 0.752909
dreamcast 0.74907
famicom 0.745298
```
```py
>>> model.get_analogies("psx", "sony", "nintendo")
[(0.803352, u'gamecube'), (0.792646, u'nintendogs'), (0.77344, u'playstation'), (0.772165, u'sega'), (0.767959, u'gameboy'), (0.754774, u'arcade'), (0.753473, u'playstationjapan'), (0.752909, u'gba'), (0.74907, u'dreamcast'), (0.745298, u'famicom')]
```
Our model considers that the *nintendo* analogy of a *psx* is the *gamecube*, which seems reasonable. Of course the quality of the analogies depend on the dataset used to train the model and one can only hope to cover fields only in the dataset.
## Importance of character n-grams
Using subword-level information is particularly interesting to build vectors for unknown words. For example, the word *gearshift* does not exist on Wikipedia but we can still query its closest existing words:
```bash
Query word? gearshift
gearing 0.790762
flywheels 0.779804
flywheel 0.777859
gears 0.776133
driveshafts 0.756345
driveshaft 0.755679
daisywheel 0.749998
wheelsets 0.748578
epicycles 0.744268
gearboxes 0.73986
```
```py
>>> model.get_nearest_neighbors('gearshift')
[(0.790762, u'gearing'), (0.779804, u'flywheels'), (0.777859, u'flywheel'), (0.776133, u'gears'), (0.756345, u'driveshafts'), (0.755679, u'driveshaft'), (0.749998, u'daisywheel'), (0.748578, u'wheelsets'), (0.744268, u'epicycles'), (0.73986, u'gearboxes')]
```
Most of the retrieved words share substantial substrings but a few are actually quite different, like *cogwheel*. You can try other words like *sunbathe* or *grandnieces*.
Now that we have seen the interest of subword information for unknown words, let's check how it compares to a model that does not use subword information. To train a model without subwords, just run the following command:
```bash
$ ./fasttext skipgram -input data/fil9 -output result/fil9-none -maxn 0
```
The results are saved in result/fil9-non.vec and result/fil9-non.bin.
```py
>>> model_without_subwords = fasttext.train_unsupervised('data/fil9', maxn=0)
```
To illustrate the difference, let us take an uncommon word in Wikipedia, like *accomodation* which is a misspelling of *accommodation**.* Here is the nearest neighbors obtained without subwords:
```bash
$ ./fasttext nn result/fil9-none.bin
Query word? accomodation
sunnhordland 0.775057
accomodations 0.769206
administrational 0.753011
laponian 0.752274
ammenities 0.750805
dachas 0.75026
vuosaari 0.74172
hostelling 0.739995
greenbelts 0.733975
asserbo 0.732465
```
```py
>>> model_without_subwords.get_nearest_neighbors('accomodation')
[(0.775057, u'sunnhordland'), (0.769206, u'accomodations'), (0.753011, u'administrational'), (0.752274, u'laponian'), (0.750805, u'ammenities'), (0.75026, u'dachas'), (0.74172, u'vuosaari'), (0.739995, u'hostelling'), (0.733975, u'greenbelts'), (0.732465, u'asserbo')]
```
The result does not make much sense, most of these words are unrelated. On the other hand, using subword information gives the following list of nearest neighbors:
```bash
Query word? accomodation
accomodations 0.96342
accommodation 0.942124
accommodations 0.915427
accommodative 0.847751
accommodating 0.794353
accomodated 0.740381
amenities 0.729746
catering 0.725975
accomodate 0.703177
hospitality 0.701426
```
```py
>>> model.get_nearest_neighbors('accomodation')
[(0.96342, u'accomodations'), (0.942124, u'accommodation'), (0.915427, u'accommodations'), (0.847751, u'accommodative'), (0.794353, u'accommodating'), (0.740381, u'accomodated'), (0.729746, u'amenities'), (0.725975, u'catering'), (0.703177, u'accomodate'), (0.701426, u'hospitality')]
```
The nearest neighbors capture different variation around the word *accommodation*. We also get semantically related words such as *amenities* or *catering*.
## Conclusion
In this tutorial, we show how to obtain word vectors from Wikipedia. This can be done for any language and we provide [pre-trained models](https://fasttext.cc/docs/en/pretrained-vectors.html) with the default setting for 294 of them.
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/api.md��������������������������������������������������������������������������0000644�0001750�0000176�00000000165�13651775021�014713� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: api
title:API
---
We automatically generate our [API documentation](/docs/en/html/index.html) with doxygen.
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/faqs.md�������������������������������������������������������������������������0000644�0001750�0000176�00000011226�13651775021�015074� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: faqs
title:FAQ
---
## What is fastText? Are there tutorials?
FastText is a library for text classification and representation. It transforms text into continuous vectors that can later be used on any language related task. A few tutorials are available.
## How can I reduce the size of my fastText models?
fastText uses a hashtable for either word or character ngrams. The size of the hashtable directly impacts the size of a model. To reduce the size of the model, it is possible to reduce the size of this table with the option '-hash'. For example a good value is 20000. Another option that greatly impacts the size of a model is the size of the vectors (-dim). This dimension can be reduced to save space but this can significantly impact performance. If that still produce a model that is too big, one can further reduce the size of a trained model with the quantization option.
```bash
./fasttext quantize -output model
```
## What would be the best way to represent word phrases rather than words?
Currently the best approach to represent word phrases or sentence is to take a bag of words of word vectors. Additionally, for phrases like “New York”, preprocessing the data so that it becomes a single token “New_York” can greatly help.
## Why does fastText produce vectors even for unknown words?
One of the key features of fastText word representation is its ability to produce vectors for any words, even made-up ones.
Indeed, fastText word vectors are built from vectors of substrings of characters contained in it.
This allows to build vectors even for misspelled words or concatenation of words.
## Why is the hierarchical softmax slightly worse in performance than the full softmax?
The hierarchical softmax is an approximation of the full softmax loss that allows to train on large number of class efficiently. This is often at the cost of a few percent of accuracy.
Note also that this loss is thought for classes that are unbalanced, that is some classes are more frequent than others. If your dataset has a balanced number of examples per class, it is worth trying the negative sampling loss (-loss ns -neg 100).
However, negative sampling will still be very slow at test time, since the full softmax will be computed.
## Can we run fastText program on a GPU?
As of now, fastText only works on CPU.
Please note that one of the goal of fastText is to be an efficient CPU tool, allowing to train models without requiring a GPU.
## Can I use fastText with python? Or other languages?
[Python is officially supported](/docs/en/support.html#building-fasttext-python-module).
There are few unofficial wrappers for javascript, lua and other languages available on github.
## Can I use fastText with continuous data?
FastText works on discrete tokens and thus cannot be directly used on continuous tokens. However, one can discretize continuous tokens to use fastText on them, for example by rounding values to a specific digit ("12.3" becomes "12").
## There are misspellings in the dictionary. Should we improve text normalization?
If the words are infrequent, there is no need to worry.
## I'm encountering a NaN, why could this be?
You'll likely see this behavior because your learning rate is too high. Try reducing it until you don't see this error anymore.
## My compiler / architecture can't build fastText. What should I do?
Try a newer version of your compiler. We try to maintain compatibility with older versions of gcc and many platforms, however sometimes maintaining backwards compatibility becomes very hard. In general, compilers and tool chains that ship with LTS versions of major linux distributions should be fair game. In any case, create an issue with your compiler version and architecture and we'll try to implement compatibility.
## How do I run fastText in a fully reproducible way? Each time I run it I get different results.
If you run fastText multiple times you'll obtain slightly different results each time due to the optimization algorithm (asynchronous stochastic gradient descent, or Hogwild). If you need to get the same results (e.g. to confront different input params set) you have to set the 'thread' parameter to 1. In this way you'll get exactly the same performances at each run (with the same input params).
## Why do I get a probability of 1.00001?
This is a known rounding issue. You can consider it as 1.0.
## How can I change the dimension of word vectors of a model file?
If you already trained a model, or downloaded a pre-trained word vectors model, you can adapt the dimension of the word vectors with the `reduce_model.py` script or by calling `fasttext.util.reduce_model` from python, as [described here](/docs/en/crawl-vectors.html#adapt-the-dimension)
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/language-identification.md������������������������������������������������������0000644�0001750�0000176�00000005046�13651775021�020717� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: language-identification
title: Language identification
---
### Description
We distribute two models for language identification, which can recognize 176 languages (see the list of ISO codes below). These models were trained on data from [Wikipedia](https://www.wikipedia.org/), [Tatoeba](https://tatoeba.org/eng/) and [SETimes](http://nlp.ffzg.hr/resources/corpora/setimes/), used under [CC-BY-SA](http://creativecommons.org/licenses/by-sa/3.0/).
We distribute two versions of the models:
* [lid.176.bin](https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin), which is faster and slightly more accurate, but has a file size of 126MB ;
* [lid.176.ftz](https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.ftz), which is the compressed version of the model, with a file size of 917kB.
These models were trained on UTF-8 data, and therefore expect UTF-8 as input.
### License
The models are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
### List of supported languages
```
af als am an ar arz as ast av az azb ba bar bcl be bg bh bn bo bpy br bs bxr ca cbk ce ceb ckb co cs cv cy da de diq dsb dty dv el eml en eo es et eu fa fi fr frr fy ga gd gl gn gom gu gv he hi hif hr hsb ht hu hy ia id ie ilo io is it ja jbo jv ka kk km kn ko krc ku kv kw ky la lb lez li lmo lo lrc lt lv mai mg mhr min mk ml mn mr mrj ms mt mwl my myv mzn nah nap nds ne new nl nn no oc or os pa pam pfl pl pms pnb ps pt qu rm ro ru rue sa sah sc scn sco sd sh si sk sl so sq sr su sv sw ta te tg th tk tl tr tt tyv ug uk ur uz vec vep vi vls vo wa war wuu xal xmf yi yo yue zh
```
### References
If you use these models, please cite the following papers:
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
```
@article{joulin2016bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.01759},
year={2016}
}
```
[2] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models* ](https://arxiv.org/abs/1612.03651)
```
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
```
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/autotune.md���������������������������������������������������������������������0000644�0001750�0000176�00000015237�13651775021�016014� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: autotune
title: Automatic hyperparameter optimization
---
As we saw in [the tutorial](/docs/en/supervised-tutorial.html#more-epochs-and-larger-learning-rate), finding the best hyperparameters is crucial for building efficient models. However, searching the best hyperparameters manually is difficult. Parameters are dependent and the effect of each parameter vary from one dataset to another.
FastText's autotune feature allows you to find automatically the best hyperparameters for your dataset.
# How to use it
In order to activate hyperparameter optimization, we must provide a validation file with the `-autotune-validation` argument.
For example, using the same data as our [tutorial example](/docs/en/supervised-tutorial.html#our-first-classifier), the autotune can be used in the following way:
```sh
>> ./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid')
```
Then, fastText will search the hyperparameters that gives the best f1-score on `cooking.valid` file:
```sh
Progress: 100.0% Trials: 27 Best score: 0.406763 ETA: 0h 0m 0s
```
Now we can test the obtained model with:
```sh
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.666
R@1 0.288
```
```py
>>> model.test("cooking.valid")
(3000L, 0.666, 0.288)
```
By default, the search will take 5 minutes. You can set the timeout in seconds with the `-autotune-duration` argument. For example, if you want to set the limit to 10 minutes:
```sh
>> ./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-duration 600
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneDuration=600)
```
While autotuning, fastText displays the best f1-score found so far. If we decide to stop the tuning before the time limit, we can send one `SIGINT` signal (via `CTLR-C` for example). FastText will then finish the current training, and retrain with the best parameters found so far.
# Constrain model size
As you may know, fastText can compress the model with [quantization](/docs/en/cheatsheet.html#quantization). However, this compression task comes with its own [hyperparameters](/docs/en/options.html) (`-cutoff`, `-retrain`, `-qnorm`, `-qout`, `-dsub`) that have a consequence on the accuracy and the size of the final model.
Fortunately, autotune can also find the hyperparameters for this compression task while targeting the desired model size. To this end, we can set the `-autotune-modelsize` argument:
```sh
>> ./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-modelsize 2M
```
This will produce a `.ftz` file with the best accuracy having the desired size:
```sh
>> ls -la model_cooking.ftz
-rw-r--r--. 1 celebio users 1990862 Aug 25 05:39 model_cooking.ftz
>> ./fasttext test model_cooking.ftz cooking.valid
N 3000
P@1 0.57
R@1 0.246
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneModelSize="2M")
```
If you save the model, you will obtain a model file with the desired size:
```py
>>> model.save_model("model_cooking.ftz")
>>> import os
>>> os.stat("model_cooking.ftz").st_size
1990862
>>> model.test("cooking.valid")
(3000L, 0.57, 0.246)
```
# How to set the optimization metric?
By default, autotune will test the validation file you provide, exactly the same way as `./fasttext test model_cooking.bin cooking.valid` and try to optimize to get the highest [f1-score](https://en.wikipedia.org/wiki/F1_score).
But, if we want to optimize the score of a specific label, say `__label__baking`, we can set the `-autotune-metric` argument:
```sh
>> ./fasttext supervised -input cooking.train -output model_cooking -autotune-validation cooking.valid -autotune-metric f1:__label__baking
```
This is equivalent to manually optimize the f1-score we get when we test with `./fasttext test-label model_cooking.bin cooking.valid | grep __label__baking` in command line.
Sometimes, you may be interested in predicting more than one label. For example, if you were optimizing the hyperparameters manually to get the best score to predict two labels, you would test with `./fasttext test model_cooking.bin cooking.valid 2`. You can also tell autotune to optimize the parameters by testing two labels with the `-autotune-predictions` argument.
By default, autotune will test the validation file you provide, exactly the same way as `model.test("cooking.valid")` and try to optimize to get the highest [f1-score](https://en.wikipedia.org/wiki/F1_score).
But, if we want to optimize the score of a specific label, say `__label__baking`, we can set the `autotuneMetric` argument:
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input='cooking.train', autotuneValidationFile='cooking.valid', autotuneMetric="f1:__label__baking")
```
This is equivalent to manually optimize the f1-score we get when we test with `model.test_label('cooking.valid')['__label__baking']`.
Sometimes, you may be interested in predicting more than one label. For example, if you were optimizing the hyperparameters manually to get the best score to predict two labels, you would test with `model.test("cooking.valid", k=2)`. You can also tell autotune to optimize the parameters by testing two labels with the `autotunePredictions` argument.
You can also force autotune to optimize for the best precision for a given recall, or the best recall for a given precision, for all labels, or for a specific label:
For example, in order to get the best precision at recall = `30%`:
```sh
>> ./fasttext supervised [...] -autotune-metric precisionAtRecall:30
```
And to get the best precision at recall = `30%` for the label `__label__baking`:
```sh
>> ./fasttext supervised [...] -autotune-metric precisionAtRecall:30:__label__baking
```
Similarly, you can use `recallAtPrecision`:
```sh
>> ./fasttext supervised [...] -autotune-metric recallAtPrecision:30
>> ./fasttext supervised [...] -autotune-metric recallAtPrecision:30:__label__baking
```
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/supervised-models.md������������������������������������������������������������0000644�0001750�0000176�00000007052�13651775021�017616� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: supervised-models
title: Supervised models
---
This page gathers several pre-trained supervised models on several datasets.
### Description
The regular models are trained using the procedure described in [1]. They can be reproduced using the classification-results.sh script within our github repository. The quantized models are build by using the respective supervised settings and adding the following flags to the quantize subcommand.
```bash
-qnorm -retrain -cutoff 100000
```
### Table of models
Each entry describes the test accuracy and size of the model. You can click on a table cell to download the corresponding model.
| dataset | ag news | amazon review full | amazon review polarity | dbpedia |
|-----------|-----------------------|-----------------------|------------------------|------------------------|
| regular | [0.924 / 387MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/ag_news.bin) | [0.603 / 462MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/amazon_review_full.bin) | [0.946 / 471MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/amazon_review_polarity.bin) | [0.986 / 427MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/dbpedia.bin) |
| compressed | [0.92 / 1.6MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/ag_news.ftz) | [0.599 / 1.6MB]( https://dl.fbaipublicfiles.com/fasttext/supervised-models/amazon_review_full.ftz) | [0.93 / 1.6MB]( https://dl.fbaipublicfiles.com/fasttext/supervised-models/amazon_review_polarity.ftz) | [0.984 / 1.7MB]( https://dl.fbaipublicfiles.com/fasttext/supervised-models/dbpedia.ftz) |
| dataset | sogou news | yahoo answers | yelp review polarity | yelp review full |
|-----------|----------------------|------------------------|----------------------|------------------------|
| regular | [0.969 / 402MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/sogou_news.bin) | [0.724 / 494MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yahoo_answers.bin)| [0.957 / 409MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yelp_review_polarity.bin)| [0.639 / 412MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yelp_review_full.bin)|
| compressed | [0.968 / 1.4MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/sogou_news.ftz) | [0.717 / 1.6MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yahoo_answers.ftz) | [0.957 / 1.5MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yelp_review_polarity.ftz) | [0.636 / 1.5MB](https://dl.fbaipublicfiles.com/fasttext/supervised-models/yelp_review_full.ftz) |
### References
If you use these models, please cite the following paper:
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
```markup
@article{joulin2016bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.01759},
year={2016}
}
```
[2] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
```markup
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
```
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/dataset.md����������������������������������������������������������������������0000644�0001750�0000176�00000000177�13651775021�015572� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: dataset
title: Datasets
---
[Download YFCC100M Dataset](https://fb-public.box.com/s/htfdbrvycvroebv9ecaezaztocbcnsdn)
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/webassembly-module.md�����������������������������������������������������������0000644�0001750�0000176�00000033637�13651775021�017754� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: webassembly-module
title: WebAssembly module
---
In this document we present how to use fastText in javascript with WebAssembly.
## Table of contents
* [Requirements](#requirements)
* [Building WebAssembly binaries](#building-webassembly-binaries)
* [Build a webpage that uses fastText](#build-a-webpage-that-uses-fasttext)
* [Load a model](#load-a-model)
* [Train a model](#train-a-model)
* [Disclaimer](#disclaimer)
* [Text classification](#text-classification)
* [Word representations](#word-representations)
* [Quantized models](#quantized-models)
* [API](#api)
* [`model` object](#model-object)
* [`loadModel`](#loadmodel)
* [`trainSupervised`](#trainsupervised)
* [`trainUnsupervised`](#trainunsupervised)
# Requirements
For building [fastText](https://fasttext.cc/) with WebAssembly bindings, we will need:
- a compiler with good C++11 support, since it uses C\++11 features,
- [emscripten](https://emscripten.org/),
- a [browser that supports WebAssembly](https://caniuse.com/#feat=wasm).
# Building WebAssembly binaries
First, download and install emscripten sdk as [described here](https://emscripten.org/docs/getting_started/downloads.html#installation-instructions).
We need to make sure we activated the PATH for emscripten:
```bash
$ source /path/to/emsdk/emsdk_env.sh
```
Clone [fastText repository](https://github.com/facebookresearch/fastText/):
```bash
$ git clone git@github.com:facebookresearch/fastText.git
```
Build WebAssembly binaries:
```bash
$ cd fastText
$ make wasm
```
This will create `fasttext_wasm.wasm` and `fasttext_wasm.js` in the `webassembly` folder.
- `fasttext_wasm.wasm` is the binary file that will be loaded in the webassembly's virtual machine.
- `fasttext_wasm.js` is a javascript file built by emscripten, that helps to load `fasttext_wasm.wasm` file in the virtual machine and provides some helper functions.
- `fasttext.js` is the wrapper that provides a nice API for fastText.
As the user of the library, we will interact with classes and methods defined in `fasttext.js`. We won't deal with `fasttext_wasm.*` files, but they are necessary to run fastText in the javascript's VM.
# Build a webpage that uses fastText
In this section we are going to build a minimal HTML page that loads fastText WebAssembly module.
At the root of the repository, create a folder `webassembly-test`, and copy the files mentioned in the previous section:
```bash
$ mkdir webassembly-test
$ cp webassembly/fasttext_wasm.wasm webassembly-test/
$ cp webassembly/fasttext_wasm.js webassembly-test/
$ cp webassembly/fasttext.js webassembly-test/
```
Inside that folder, create `test.html` file containing:
```html
```
It is important to add the attribute `type="module"` to the script tag, because we use ES6 style imports. `addOnPostRun` is a function that helps to provide a handler that is called when fastText is successfully loaded in the virtual machine. Once we are called inside that function, we can create an instance of `FastText`, that we will use to access the api.
Let's test it.
Opening `test.html` directly in the browser won't work since we are dynamically loading webassembly resources. The `test.html` file must be served from a webserver. The easiest way to achieve this is to use python's simple http server module:
```bash
$ cd webassembly-test
$ python -m SimpleHTTPServer
```
Then browse `http://localhost:8000/test.html` in your browser. If everything worked as expected, you should see `FastText {f: FastText}` in the javascript console.
# Load a model
In order to load a fastText model that was already trained, we can use `loadModel` function. In the example below we use `lid.176.ftz` that you can download from [here](/docs/en/language-identification.html).
Place the model file you want to load inside the same directory than the HTML file, and inside the script part:
```javascript
import {FastText, addOnPostRun} from "./fasttext.js";
const printVector = function(predictions) {
for (let i=0; i {
let ft = new FastText();
const url = "lid.176.ftz";
ft.loadModel(url).then(model => {
console.log("Model loaded.")
let text = "Bonjour à tous. Ceci est du français";
console.log(text);
printVector(model.predict(text, 5, 0.0));
text = "Hello, world. This is english";
console.log(text);
printVector(model.predict(text, 5, 0.0));
text = "Merhaba dünya. Bu da türkçe"
console.log(text);
printVector(model.predict(text, 5, 0.0));
});
});
```
`loadModel` function returns a [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) that resolves to a `model` object. We can then use [`model` object](#model-object) to call various methods, such as `predict`.
We define `printVector` function that loops through a representation of `std::vector` in javascript, and displays the items. Here, we use it to display prediction results.
You can also refer to `webassembly/doc/examples/predict.html` in the source code.
# Calling other methods
Once the model is loaded, you can call any method like `model.getDimension()` or `model.getSubwords(word)`. You can refer to [this](#api) section of the document for a complete API. You can also have a look to `webassembly/doc/examples/misc.html` file in the source code for further examples.
# Train a model
### Disclaimer
It is also possible to train a model inside the browser with fastText's WebAssembly API. The training can be slow because at the time of writing, it is not possible to use multithreading in WebAssembly (along with dynamic memory growth). So most of the time, we would train a model with the python or command line tool, eventually quantize it, and load it in the WebAssembly module. However, training a model inside the browser can be useful for creating animations or educational tools.
### Text classification
Place the `cooking.train` file (as described [here](/docs/en/supervised-tutorial.html)) inside the same directory:
```javascript
import {FastText, addOnPostRun} from "./fasttext.js";
const trainCallback = (progress, loss, wst, lr, eta) => {
console.log([progress, loss, wst, lr, eta]);
};
addOnPostRun(() => {
let ft = new FastText();
ft.trainSupervised("cooking.train", {
'lr':1.0,
'epoch':10,
'loss':'hs',
'wordNgrams':2,
'dim':50,
'bucket':200000
}, trainCallback).then(model => {
console.log('Trained.');
});
});
```
`trainCallback` function is called by the module to show progress, average training cost, number of words per second (per thread, but there is only one thread), learning rate, estimated remaining time.
### Word representations
Place the `fil9` file (as described [here](/docs/en/unsupervised-tutorial.html)) inside the same directory:
```javascript
import {FastText, addOnPostRun} from "./fasttext.js";
const trainCallback = (progress, loss, wst, lr, eta) => {
console.log([progress, loss, wst, lr, eta]);
};
addOnPostRun(() => {
let ft = new FastText();
ft.trainUnsupervised("fil9", 'skipgram', {
'lr':0.1,
'epoch':1,
'loss':'ns',
'wordNgrams':2,
'dim':50,
'bucket':200000
}, trainCallback).then(model => {
console.log('Trained.');
});
});
```
# Quantized models
Quantization is a technique that reduces the size of your models. You can quantize your model as [described here](/docs/en/faqs.html#how-can-i-reduce-the-size-of-my-fasttext-models).
You can load a quantized model in fastText's WebAssembly module, as we did in ["Load a model" section](#load-a-model).
In the context of web, it is particularly useful to have smaller models since they can be downloaded much faster. You can use our autotune feature as [described here](/docs/en/autotune.html#constrain-model-size) in order to find the best trade-off between accuracy and model size that fits your needs.
# API
## `model` object
`trainSupervised`, `trainUnsupervised` and `loadModel` functions return a Promise that resolves to an instance of `FastTextModel` class, that we generaly name `model` object.
This object exposes several functions:
```javascript
isQuant // true if the model is quantized.
getDimension // the dimension (size) of a lookup vector (hidden layer).
getWordVector(word) // the vector representation of `word`.
getSentenceVector(text) // the vector representation of `text`.
getNearestNeighbors(word, k=10) // nearest `k` neighbors of `word`.
getAnalogies(wordA, wordB, wordC, k) // nearest `k` neighbors of the operation `wordA - wordB + wordC`.
getWordId(word) // get the word id within the dictionary.
getSubwordId(subword) // the index (within input matrix) a subword hashes to.
getSubwords(word) // the subwords and their indicies.
getInputVector(ind) // given an index, get the corresponding vector of the Input Matrix.
predict(text, k = 1, threshold = 0.0) // Given a string, get a list of labels and a list of corresponding
// probabilities. k controls the number of returned labels.
getInputMatrix() // get a reference to the full input matrix of a (non-quantized) Model.
getOutputMatrix() // get a reference to the full output matrix of a (non-quantized) Model.
getWords() // get the entire list of words of the dictionary including the frequency
// of the individual words. This does not include any subwords. For that
// please consult the function get_subwords.
getLabels() // get the entire list of labels of the dictionary including the frequency
getLine(text) // split a line of text into words and labels.
saveModel() // saves the model file in WebAssembly's in-memory FS and returns a blob
test(url, k, threshold) // downloads the test file from the specified url, evaluates the supervised model with it.
```
You can also have a look to `webassembly/doc/examples/misc.html` file in the source code for further examples.
## `loadModel`
You can load a model as follows:
`ft.loadModel(url);`
`loadModel` returns a [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) that resolves to a [`model` object](#model-object).
## `trainSupervised`
You can train a text classification model with fastText's WebAssembly API as follows:
`ft.trainSupervised(trainFile, args, trainCallback);`
- `trainFile`: the url of the input file
- `args`: a dictionary with following keys:
```javascript
lr # learning rate [0.1]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [1]
minCountLabel # minimal number of label occurences [1]
minn # min length of char ngram [0]
maxn # max length of char ngram [0]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [softmax]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
label # label prefix ['__label__']
```
- `trainCallback` is the name of the function that will be called during training to provide various information. Set this argument to `null` if you don't need a callback, or provide a function that has the following signature: `function myCallback(progress, loss, wst, lr, eta){ ... }`
`trainSupervised` returns a [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) that resolves to a [`model` object](#model-object).
## `trainUnsupervised`
You can train a word representation model with fastText's WebAssembly API as follows:
`ft.trainUnsupervised(trainFile, modelname, args, trainCallback);`
- `trainFile`: the url of the input file
- `modelName`: must be `"cbow"` or `"skipgram"`
- `args`: a dictionary with following keys:
```javascript
lr # learning rate [0.05]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [5]
minn # min length of char ngram [3]
maxn # max length of char ngram [6]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [ns]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
```
- `trainCallback` is the name of the function that will be called during training to provide various information. Set this argument to `null` if you don't need a callback, or provide a function that has the following signature: `function myCallback(progress, loss, wst, lr, eta){ ... }`
`trainUnsupervised` returns a [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) that resolves to a [`model` object](#model-object).
�������������������������������������������������������������������������������������������������fastText-0.9.2/docs/pretrained-vectors.md�����������������������������������������������������������0000644�0001750�0000176�00000143774�13651775021�020000� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: pretrained-vectors
title: Wiki word vectors
---
We are publishing pre-trained word vectors for 294 languages, trained on [*Wikipedia*](https://www.wikipedia.org) using fastText.
These vectors in dimension 300 were obtained using the skip-gram model described in [*Bojanowski et al. (2016)*](https://arxiv.org/abs/1607.04606) with default parameters.
Please note that a newer version of multi-lingual word vectors are available at: [Word vectors for 157 languages](https://fasttext.cc/docs/en/crawl-vectors.html).
### Models
The models can be downloaded from:
||||
|-|-|-|
| Abkhazian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ab.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ab.vec) | Acehnese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ace.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ace.vec) | Adyghe: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ady.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ady.vec) |
| Afar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.aa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.aa.vec) | Afrikaans: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.af.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.af.vec) | Akan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ak.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ak.vec) |
| Albanian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sq.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sq.vec) | Alemannic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.als.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.als.vec) | Amharic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.am.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.am.vec) |
| Anglo_Saxon: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ang.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ang.vec) | Arabic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ar.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ar.vec) | Aragonese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.an.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.an.vec) |
| Aramaic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.arc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.arc.vec) | Armenian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hy.vec) | Aromanian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.roa_rup.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.roa_rup.vec) |
| Assamese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.as.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.as.vec) | Asturian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ast.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ast.vec) | Avar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.av.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.av.vec) |
| Aymara: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ay.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ay.vec) | Azerbaijani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.az.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.az.vec) | Bambara: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bm.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bm.vec) |
| Banjar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bjn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bjn.vec) | Banyumasan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.map_bms.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.map_bms.vec) | Bashkir: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ba.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ba.vec) |
| Basque: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eu.vec) | Bavarian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bar.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bar.vec) | Belarusian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.be.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.be.vec) |
| Bengali: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bn.vec) | Bihari: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bh.vec) | Bishnupriya Manipuri: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bpy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bpy.vec) |
| Bislama: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bi.vec) | Bosnian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bs.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bs.vec) | Breton: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.br.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.br.vec) |
| Buginese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bug.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bug.vec) | Bulgarian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bg.vec) | Burmese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.my.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.my.vec) |
| Buryat: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bxr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bxr.vec) | Cantonese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_yue.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_yue.vec) | Catalan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ca.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ca.vec) |
| Cebuano: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ceb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ceb.vec) | Central Bicolano: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bcl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bcl.vec) | Chamorro: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ch.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ch.vec) |
| Chavacano: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cbk_zam.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cbk_zam.vec) | Chechen: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ce.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ce.vec) | Cherokee: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.chr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.chr.vec) |
| Cheyenne: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.chy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.chy.vec) | Chichewa: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ny.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ny.vec) | Chinese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh.vec) |
| Choctaw: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cho.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cho.vec) | Chuvash: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cv.vec) | Classical Chinese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_classical.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_classical.vec) |
| Cornish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kw.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kw.vec) | Corsican: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.co.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.co.vec) | Cree: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cr.vec) |
| Crimean Tatar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.crh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.crh.vec) | Croatian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hr.vec) | Czech: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cs.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cs.vec) |
| Danish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.da.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.da.vec) | Divehi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dv.vec) | Dutch: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nl.vec) |
| Dutch Low Saxon: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nds_nl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nds_nl.vec) | Dzongkha: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dz.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dz.vec) | Eastern Punjabi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pa.vec) |
| Egyptian Arabic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.arz.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.arz.vec) | Emilian_Romagnol: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eml.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eml.vec) | English: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.en.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.en.vec) |
| Erzya: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.myv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.myv.vec) | Esperanto: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.eo.vec) | Estonian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.et.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.et.vec) |
| Ewe: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ee.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ee.vec) | Extremaduran: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ext.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ext.vec) | Faroese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fo.vec) |
| Fiji Hindi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hif.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hif.vec) | Fijian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fj.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fj.vec) | Finnish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fi.vec) |
| Franco_Provençal: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.frp.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.frp.vec) | French: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fr.vec) | Friulian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fur.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fur.vec) |
| Fula: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ff.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ff.vec) | Gagauz: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gag.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gag.vec) | Galician: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gl.vec) |
| Gan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gan.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gan.vec) | Georgian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ka.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ka.vec) | German: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.de.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.de.vec) |
| Gilaki: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.glk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.glk.vec) | Goan Konkani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gom.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gom.vec) | Gothic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.got.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.got.vec) |
| Greek: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.el.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.el.vec) | Greenlandic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kl.vec) | Guarani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gn.vec) |
| Gujarati: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gu.vec) | Haitian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ht.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ht.vec) | Hakka: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hak.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hak.vec) |
| Hausa: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ha.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ha.vec) | Hawaiian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.haw.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.haw.vec) | Hebrew: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.he.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.he.vec) |
| Herero: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hz.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hz.vec) | Hill Mari: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mrj.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mrj.vec) | Hindi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hi.vec) |
| Hiri Motu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ho.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ho.vec) | Hungarian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hu.vec) | Icelandic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.is.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.is.vec) |
| Ido: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.io.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.io.vec) | Igbo: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ig.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ig.vec) | Ilokano: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ilo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ilo.vec) |
| Indonesian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.id.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.id.vec) | Interlingua: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ia.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ia.vec) | Interlingue: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ie.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ie.vec) |
| Inuktitut: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.iu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.iu.vec) | Inupiak: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ik.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ik.vec) | Irish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ga.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ga.vec) |
| Italian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.it.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.it.vec) | Jamaican Patois: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jam.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jam.vec) | Japanese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ja.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ja.vec) |
| Javanese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jv.vec) | Kabardian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kbd.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kbd.vec) | Kabyle: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kab.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kab.vec) |
| Kalmyk: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xal.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xal.vec) | Kannada: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kn.vec) | Kanuri: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kr.vec) |
| Kapampangan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pam.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pam.vec) | Karachay_Balkar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.krc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.krc.vec) | Karakalpak: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kaa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kaa.vec) |
| Kashmiri: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ks.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ks.vec) | Kashubian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.csb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.csb.vec) | Kazakh: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kk.vec) |
| Khmer: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.km.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.km.vec) | Kikuyu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ki.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ki.vec) | Kinyarwanda: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rw.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rw.vec) |
| Kirghiz: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ky.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ky.vec) | Kirundi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rn.vec) | Komi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kv.vec) |
| Komi_Permyak: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.koi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.koi.vec) | Kongo: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kg.vec) | Korean: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ko.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ko.vec) |
| Kuanyama: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kj.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.kj.vec) | Kurdish (Kurmanji): [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ku.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ku.vec) | Kurdish (Sorani): [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ckb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ckb.vec) |
| Ladino: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lad.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lad.vec) | Lak: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lbe.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lbe.vec) | Lao: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lo.vec) |
| Latgalian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ltg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ltg.vec) | Latin: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.la.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.la.vec) | Latvian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lv.vec) |
| Lezgian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lez.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lez.vec) | Ligurian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lij.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lij.vec) | Limburgish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.li.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.li.vec) |
| Lingala: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ln.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ln.vec) | Lithuanian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lt.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lt.vec) | Livvi_Karelian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.olo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.olo.vec) |
| Lojban: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jbo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.jbo.vec) | Lombard: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lmo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lmo.vec) | Low Saxon: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nds.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nds.vec) |
| Lower Sorbian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dsb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.dsb.vec) | Luganda: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lg.vec) | Luxembourgish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lb.vec) |
| Macedonian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mk.vec) | Maithili: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mai.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mai.vec) | Malagasy: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mg.vec) |
| Malay: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ms.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ms.vec) | Malayalam: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ml.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ml.vec) | Maltese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mt.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mt.vec) |
| Manx: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gv.vec) | Maori: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mi.vec) | Marathi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mr.vec) |
| Marshallese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mh.vec) | Mazandarani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mzn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mzn.vec) | Meadow Mari: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mhr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mhr.vec) |
| Min Dong: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cdo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cdo.vec) | Min Nan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_min_nan.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zh_min_nan.vec) | Minangkabau: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.min.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.min.vec) |
| Mingrelian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xmf.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xmf.vec) | Mirandese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mwl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mwl.vec) | Moksha: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mdf.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mdf.vec) |
| Moldovan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mo.vec) | Mongolian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mn.vec) | Muscogee: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mus.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.mus.vec) |
| Nahuatl: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nah.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nah.vec) | Nauruan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.na.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.na.vec) | Navajo: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nv.vec) |
| Ndonga: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ng.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ng.vec) | Neapolitan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nap.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nap.vec) | Nepali: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ne.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ne.vec) |
| Newar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.new.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.new.vec) | Norfolk: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pih.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pih.vec) | Norman: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nrm.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nrm.vec) |
| North Frisian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.frr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.frr.vec) | Northern Luri: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lrc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.lrc.vec) | Northern Sami: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.se.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.se.vec) |
| Northern Sotho: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nso.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nso.vec) | Norwegian (Bokmål): [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.no.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.no.vec) | Norwegian (Nynorsk): [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nn.vec) |
| Novial: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nov.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.nov.vec) | Nuosu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ii.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ii.vec) | Occitan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.oc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.oc.vec) |
| Old Church Slavonic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cu.vec) | Oriya: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.or.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.or.vec) | Oromo: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.om.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.om.vec) |
| Ossetian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.os.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.os.vec) | Palatinate German: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pfl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pfl.vec) | Pali: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pi.vec) |
| Pangasinan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pag.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pag.vec) | Papiamentu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pap.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pap.vec) | Pashto: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ps.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ps.vec) |
| Pennsylvania German: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pdc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pdc.vec) | Persian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fa.vec) | Picard: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pcd.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pcd.vec) |
| Piedmontese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pms.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pms.vec) | Polish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pl.vec) | Pontic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pnt.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pnt.vec) |
| Portuguese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pt.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pt.vec) | Quechua: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.qu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.qu.vec) | Ripuarian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ksh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ksh.vec) |
| Romani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rmy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rmy.vec) | Romanian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ro.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ro.vec) | Romansh: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rm.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rm.vec) |
| Russian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ru.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ru.vec) | Rusyn: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rue.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.rue.vec) | Sakha: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sah.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sah.vec) |
| Samoan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sm.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sm.vec) | Samogitian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bat_smg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bat_smg.vec) | Sango: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sg.vec) |
| Sanskrit: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sa.vec) | Sardinian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sc.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sc.vec) | Saterland Frisian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.stq.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.stq.vec) |
| Scots: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sco.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sco.vec) | Scottish Gaelic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gd.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.gd.vec) | Serbian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sr.vec) |
| Serbo_Croatian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sh.vec) | Sesotho: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.st.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.st.vec) | Shona: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sn.vec) |
| Sicilian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.scn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.scn.vec) | Silesian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.szl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.szl.vec) | Simple English: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.simple.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.simple.vec) |
| Sindhi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sd.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sd.vec) | Sinhalese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.si.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.si.vec) | Slovak: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sk.vec) |
| Slovenian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sl.vec) | Somali: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.so.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.so.vec) | Southern Azerbaijani: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.azb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.azb.vec) |
| Spanish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.es.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.es.vec) | Sranan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.srn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.srn.vec) | Sundanese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.su.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.su.vec) |
| Swahili: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sw.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sw.vec) | Swati: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ss.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ss.vec) | Swedish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.sv.vec) |
| Tagalog: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tl.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tl.vec) | Tahitian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ty.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ty.vec) | Tajik: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tg.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tg.vec) |
| Tamil: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ta.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ta.vec) | Tarantino: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.roa_tara.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.roa_tara.vec) | Tatar: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tt.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tt.vec) |
| Telugu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.te.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.te.vec) | Tetum: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tet.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tet.vec) | Thai: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.th.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.th.vec) |
| Tibetan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.bo.vec) | Tigrinya: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ti.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ti.vec) | Tok Pisin: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tpi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tpi.vec) |
| Tongan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.to.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.to.vec) | Tsonga: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ts.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ts.vec) | Tswana: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tn.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tn.vec) |
| Tulu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tcy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tcy.vec) | Tumbuka: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tum.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tum.vec) | Turkish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tr.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tr.vec) |
| Turkmen: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tk.vec) | Tuvan: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tyv.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tyv.vec) | Twi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tw.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.tw.vec) |
| Udmurt: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.udm.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.udm.vec) | Ukrainian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.uk.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.uk.vec) | Upper Sorbian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hsb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hsb.vec) |
| Urdu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ur.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ur.vec) | Uyghur: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ug.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ug.vec) | Uzbek: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.uz.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.uz.vec) |
| Venda: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ve.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ve.vec) | Venetian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vec.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vec.vec) | Vepsian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vep.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vep.vec) |
| Vietnamese: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vi.vec) | Volapük: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vo.vec) | Võro: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fiu_vro.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fiu_vro.vec) |
| Walloon: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wa.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wa.vec) | Waray: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.war.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.war.vec) | Welsh: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.cy.vec) |
| West Flemish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vls.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.vls.vec) | West Frisian: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fy.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.fy.vec) | Western Punjabi: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pnb.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.pnb.vec) |
| Wolof: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wo.vec) | Wu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wuu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.wuu.vec) | Xhosa: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xh.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.xh.vec) |
| Yiddish: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.yi.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.yi.vec) | Yoruba: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.yo.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.yo.vec) | Zazaki: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.diq.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.diq.vec) |
| Zeelandic: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zea.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zea.vec) | Zhuang: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.za.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.za.vec) | Zulu: [*bin+text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zu.zip), [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.zu.vec) |
### Format
The word vectors come in both the binary and text default formats of fastText.
In the text format, each line contains a word followed by its vector. Each value is space separated.
Words are ordered by their frequency in a descending order.
### License
The word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
### References
If you use these word vectors, please cite the following paper:
P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
```markup
@article{bojanowski2017enriching,
title={Enriching Word Vectors with Subword Information},
author={Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas},
journal={Transactions of the Association for Computational Linguistics},
volume={5},
year={2017},
issn={2307-387X},
pages={135--146}
}
```
����fastText-0.9.2/docs/options.md����������������������������������������������������������������������0000644�0001750�0000176�00000004745�13651775021�015645� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: options
title: List of options
---
Invoke a command without arguments to list available arguments and their default values:
```bash
$ ./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-verbose verbosity level [2]
The following arguments for the dictionary are optional:
-minCount minimal number of word occurrences [1]
-minCountLabel minimal number of label occurrences [0]
-wordNgrams max length of word ngram [1]
-bucket number of buckets [2000000]
-minn min length of char ngram [0]
-maxn max length of char ngram [0]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
The following arguments for training are optional:
-lr learning rate [0.1]
-lrUpdateRate change the rate of updates for the learning rate [100]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-neg number of negatives sampled [5]
-loss loss function {ns, hs, softmax} [softmax]
-thread number of threads [12]
-pretrainedVectors pretrained word vectors for supervised learning []
-saveOutput whether output params should be saved [0]
The following arguments for quantization are optional:
-cutoff number of words and ngrams to retain [0]
-retrain finetune embeddings if a cutoff is applied [0]
-qnorm quantizing the norm separately [0]
-qout quantizing the classifier [0]
-dsub size of each sub-vector [2]
```
Defaults may vary by mode. (Word-representation modes `skipgram` and `cbow` use a default `-minCount` of 5.)
Hyperparameter optimization (autotune) is activated when you provide a validation file with `-autotune-validation` argument.
```text
The following arguments are for autotune:
-autotune-validation validation file to be used for evaluation
-autotune-metric metric objective {f1, f1:labelname} [f1]
-autotune-predictions number of predictions used for evaluation [1]
-autotune-duration maximum duration in seconds [300]
-autotune-modelsize constraint model file size [] (empty = do not quantize)
```
���������������������������fastText-0.9.2/docs/aligned-vectors.md��������������������������������������������������������������0000644�0001750�0000176�00000013752�13651775021�017236� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: aligned-vectors
title: Aligned word vectors
---
We are publishing aligned word vectors for 44 languages based on the pre-trained vectors computed on [*Wikipedia*](https://www.wikipedia.org) using fastText.
The alignments are performed with the RCSLS method described in [*Joulin et al (2018)*](https://arxiv.org/abs/1804.07745).
### Vectors
The aligned vectors can be downloaded from:
|||||
|-|-|-|-|
| Afrikaans: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.af.align.vec) | Arabic: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ar.align.vec) | Bulgarian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.bg.align.vec) | Bengali: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.bn.align.vec) |
| Bosnian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.bs.align.vec) | Catalan: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ca.align.vec) | Czech: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.cs.align.vec) | Danish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.da.align.vec) |
| German: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.de.align.vec) | Greek: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.el.align.vec) | English: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.en.align.vec) | Spanish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.es.align.vec) |
| Estonian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.et.align.vec) | Persian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.fa.align.vec) | Finnish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.fi.align.vec) | French: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.fr.align.vec) |
| Hebrew: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.he.align.vec) | Hindi: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.hi.align.vec) | Croatian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.hr.align.vec) | Hungarian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.hu.align.vec) |
| Indonesian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.id.align.vec) | Italian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.it.align.vec) | Korean: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ko.align.vec) | Lithuanian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.lt.align.vec) |
| Latvian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.lv.align.vec) | Macedonian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.mk.align.vec) | Malay: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ms.align.vec) | Dutch: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.nl.align.vec) |
| Norwegian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.no.align.vec) | Polish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.pl.align.vec) | Portuguese: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.pt.align.vec) | Romanian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ro.align.vec) |
| Russian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ru.align.vec) | Slovak: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.sk.align.vec) | Slovenian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.sl.align.vec) | Albanian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.sq.align.vec) |
| Swedish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.sv.align.vec) | Tamil: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.ta.align.vec) | Thai: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.th.align.vec) | Tagalog: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.tl.align.vec) |
| Turkish: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.tr.align.vec) | Ukrainian: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.uk.align.vec) | Vietnamese: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.vi.align.vec) | Chinese: [*text*](https://dl.fbaipublicfiles.com/fasttext/vectors-aligned/wiki.zh.align.vec) |
### Format
The word vectors come in the default text format of fastText.
The first line gives the number of vectors and their dimension.
The other lines contain a word followed by its vector. Each value is space separated.
### License
The word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
### References
If you use these word vectors, please cite the following papers:
[1] A. Joulin, P. Bojanowski, T. Mikolov, H. Jegou, E. Grave, [*Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion*](https://arxiv.org/abs/1804.07745)
```markup
@InProceedings{joulin2018loss,
title={Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion},
author={Joulin, Armand and Bojanowski, Piotr and Mikolov, Tomas and J\'egou, Herv\'e and Grave, Edouard},
year={2018},
booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
}
```
[2] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
```markup
@article{bojanowski2017enriching,
title={Enriching Word Vectors with Subword Information},
author={Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas},
journal={Transactions of the Association for Computational Linguistics},
volume={5},
year={2017},
issn={2307-387X},
pages={135--146}
}
```
����������������������fastText-0.9.2/docs/crawl-vectors.md����������������������������������������������������������������0000644�0001750�0000176�00000077654�13651775021�016756� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: crawl-vectors
title: Word vectors for 157 languages
---
We distribute pre-trained word vectors for 157 languages, trained on [*Common Crawl*](http://commoncrawl.org/) and [*Wikipedia*](https://www.wikipedia.org) using fastText.
These models were trained using CBOW with position-weights, in dimension 300, with character n-grams of length 5, a window of size 5 and 10 negatives.
We also distribute three new word analogy datasets, for French, Hindi and Polish.
### Download directly with command line or from python
In order to download with command line or from python code, you must have installed the python package as [described here](/docs/en/support.html#building-fasttext-python-module).
```bash
$ ./download_model.py en # English
Downloading https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.bin.gz
(19.78%) [=========> ]
```
Once the download is finished, use the model as usual:
```bash
$ ./fasttext nn cc.en.300.bin 10
Query word?
```
```py
>>> import fasttext.util
>>> fasttext.util.download_model('en', if_exists='ignore') # English
>>> ft = fasttext.load_model('cc.en.300.bin')
```
### Adapt the dimension
The pre-trained word vectors we distribute have dimension 300. If you need a smaller size, you can use our dimension reducer.
In order to use that feature, you must have installed the python package as [described here](/docs/en/support.html#building-fasttext-python-module).
For example, in order to get vectors of dimension 100:
```bash
$ ./reduce_model.py cc.en.300.bin 100
Loading model
Reducing matrix dimensions
Saving model
cc.en.100.bin saved
```
Then you can use the `cc.en.100.bin` model file as usual.
```py
>>> import fasttext
>>> import fasttext.util
>>> ft = fasttext.load_model('cc.en.300.bin')
>>> ft.get_dimension()
300
>>> fasttext.util.reduce_model(ft, 100)
>>> ft.get_dimension()
100
```
Then you can use `ft` model object as usual:
```py
>>> ft.get_word_vector('hello').shape
(100,)
>>> ft.get_nearest_neighbors('hello')
[(0.775576114654541, u'heyyyy'), (0.7686290144920349, u'hellow'), (0.7663413286209106, u'hello-'), (0.7579624056816101, u'heyyyyy'), (0.7495524287223816, u'hullo'), (0.7473770380020142, u'.hello'), (0.7407292127609253, u'Hiiiii'), (0.7402616739273071, u'hellooo'), (0.7399682402610779, u'hello.'), (0.7396857738494873, u'Heyyyyy')]
```
or save it for later use:
```py
>>> ft.save_model('cc.en.100.bin')
```
### Format
The word vectors are available in both binary and text formats.
Using the binary models, vectors for out-of-vocabulary words can be obtained with
```
$ ./fasttext print-word-vectors wiki.it.300.bin < oov_words.txt
```
where the file oov_words.txt contains out-of-vocabulary words.
In the text format, each line contain a word followed by its vector.
Each value is space separated, and words are sorted by frequency in descending order.
These text models can easily be loaded in Python using the following code:
```python
import io
def load_vectors(fname):
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
data = {}
for line in fin:
tokens = line.rstrip().split(' ')
data[tokens[0]] = map(float, tokens[1:])
return data
```
### Tokenization
We used the [*Stanford word segmenter*](https://nlp.stanford.edu/software/segmenter.html) for Chinese, [*Mecab*](http://taku910.github.io/mecab/) for Japanese and [*UETsegmenter*](https://github.com/phongnt570/UETsegmenter) for Vietnamese.
For languages using the Latin, Cyrillic, Hebrew or Greek scripts, we used the tokenizer from the [*Europarl*](http://www.statmt.org/europarl/) preprocessing tools.
For the remaining languages, we used the ICU tokenizer.
More information about the training of these models can be found in the article [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893).
### License
The word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
### References
If you use these word vectors, please cite the following paper:
E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893)
```markup
@inproceedings{grave2018learning,
title={Learning Word Vectors for 157 Languages},
author={Grave, Edouard and Bojanowski, Piotr and Gupta, Prakhar and Joulin, Armand and Mikolov, Tomas},
booktitle={Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018)},
year={2018}
}
```
### Evaluation datasets
The analogy evaluation datasets described in the paper are available here: [French](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-fr.txt), [Hindi](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-hi.txt), [Polish](https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-pl.txt).
### Models
The models can be downloaded from:
||||
|-|-|-|
| Afrikaans: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.af.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.af.300.vec.gz) | Albanian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sq.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sq.300.vec.gz) | Alemannic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.als.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.als.300.vec.gz) |
| Amharic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.am.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.am.300.vec.gz) | Arabic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ar.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ar.300.vec.gz) | Aragonese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.an.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.an.300.vec.gz) |
| Armenian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hy.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hy.300.vec.gz) | Assamese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.as.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.as.300.vec.gz) | Asturian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ast.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ast.300.vec.gz) |
| Azerbaijani: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.az.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.az.300.vec.gz) | Bashkir: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ba.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ba.300.vec.gz) | Basque: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eu.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eu.300.vec.gz) |
| Bavarian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bar.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bar.300.vec.gz) | Belarusian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.be.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.be.300.vec.gz) | Bengali: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gz) |
| Bihari: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bh.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bh.300.vec.gz) | Bishnupriya Manipuri: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bpy.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bpy.300.vec.gz) | Bosnian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bs.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bs.300.vec.gz) |
| Breton: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.br.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.br.300.vec.gz) | Bulgarian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bg.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bg.300.vec.gz) | Burmese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.my.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.my.300.vec.gz) |
| Catalan: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ca.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ca.300.vec.gz) | Cebuano: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ceb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ceb.300.vec.gz) | Central Bicolano: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bcl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bcl.300.vec.gz) |
| Chechen: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ce.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ce.300.vec.gz) | Chinese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.vec.gz) | Chuvash: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cv.300.vec.gz) |
| Corsican: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.co.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.co.300.vec.gz) | Croatian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hr.300.vec.gz) | Czech: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cs.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cs.300.vec.gz) |
| Danish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.da.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.da.300.vec.gz) | Divehi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.dv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.dv.300.vec.gz) | Dutch: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nl.300.vec.gz) |
| Eastern Punjabi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pa.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pa.300.vec.gz) | Egyptian Arabic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.arz.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.arz.300.vec.gz) | Emilian-Romagnol: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eml.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eml.300.vec.gz) |
| English: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.vec.gz) | Erzya: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.myv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.myv.300.vec.gz) | Esperanto: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.eo.300.vec.gz) |
| Estonian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.et.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.et.300.vec.gz) | Fiji Hindi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hif.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hif.300.vec.gz) | Finnish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fi.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fi.300.vec.gz) |
| French: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fr.300.vec.gz) | Galician: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gl.300.vec.gz) | Georgian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ka.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ka.300.vec.gz) |
| German: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.de.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.de.300.vec.gz) | Goan Konkani: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gom.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gom.300.vec.gz) | Greek: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.el.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.el.300.vec.gz) |
| Gujarati: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gu.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gu.300.vec.gz) | Haitian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ht.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ht.300.vec.gz) | Hebrew: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.he.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.he.300.vec.gz) |
| Hill Mari: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mrj.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mrj.300.vec.gz) | Hindi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hi.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hi.300.vec.gz) | Hungarian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hu.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hu.300.vec.gz) |
| Icelandic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.is.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.is.300.vec.gz) | Ido: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.io.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.io.300.vec.gz) | Ilokano: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ilo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ilo.300.vec.gz) |
| Indonesian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.id.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.id.300.vec.gz) | Interlingua: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ia.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ia.300.vec.gz) | Irish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ga.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ga.300.vec.gz) |
| Italian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.it.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.it.300.vec.gz) | Japanese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz) | Javanese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.jv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.jv.300.vec.gz) |
| Kannada: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.kn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.kn.300.vec.gz) | Kapampangan: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pam.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pam.300.vec.gz) | Kazakh: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.kk.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.kk.300.vec.gz) |
| Khmer: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.km.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.km.300.vec.gz) | Kirghiz: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ky.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ky.300.vec.gz) | Korean: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ko.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ko.300.vec.gz) |
| Kurdish (Kurmanji): [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ku.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ku.300.vec.gz) | Kurdish (Sorani): [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ckb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ckb.300.vec.gz) | Latin: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.la.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.la.300.vec.gz) |
| Latvian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lv.300.vec.gz) | Limburgish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.li.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.li.300.vec.gz) | Lithuanian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lt.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lt.300.vec.gz) |
| Lombard: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lmo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lmo.300.vec.gz) | Low Saxon: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nds.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nds.300.vec.gz) | Luxembourgish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.lb.300.vec.gz) |
| Macedonian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mk.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mk.300.vec.gz) | Maithili: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mai.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mai.300.vec.gz) | Malagasy: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mg.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mg.300.vec.gz) |
| Malay: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ms.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ms.300.vec.gz) | Malayalam: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ml.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ml.300.vec.gz) | Maltese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mt.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mt.300.vec.gz) |
| Manx: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gv.300.vec.gz) | Marathi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mr.300.vec.gz) | Mazandarani: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mzn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mzn.300.vec.gz) |
| Meadow Mari: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mhr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mhr.300.vec.gz) | Minangkabau: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.min.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.min.300.vec.gz) | Mingrelian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.xmf.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.xmf.300.vec.gz) |
| Mirandese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mwl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mwl.300.vec.gz) | Mongolian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.mn.300.vec.gz) | Nahuatl: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nah.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nah.300.vec.gz) |
| Neapolitan: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nap.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nap.300.vec.gz) | Nepali: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ne.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ne.300.vec.gz) | Newar: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.new.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.new.300.vec.gz) |
| North Frisian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.frr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.frr.300.vec.gz) | Northern Sotho: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nso.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nso.300.vec.gz) | Norwegian (Bokmål): [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.no.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.no.300.vec.gz) |
| Norwegian (Nynorsk): [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.nn.300.vec.gz) | Occitan: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.oc.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.oc.300.vec.gz) | Oriya: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.or.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.or.300.vec.gz) |
| Ossetian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.os.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.os.300.vec.gz) | Palatinate German: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pfl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pfl.300.vec.gz) | Pashto: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ps.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ps.300.vec.gz) |
| Persian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fa.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fa.300.vec.gz) | Piedmontese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pms.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pms.300.vec.gz) | Polish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pl.300.vec.gz) |
| Portuguese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pt.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pt.300.vec.gz) | Quechua: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.qu.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.qu.300.vec.gz) | Romanian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ro.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ro.300.vec.gz) |
| Romansh: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.rm.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.rm.300.vec.gz) | Russian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ru.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ru.300.vec.gz) | Sakha: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sah.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sah.300.vec.gz) |
| Sanskrit: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sa.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sa.300.vec.gz) | Sardinian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sc.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sc.300.vec.gz) | Scots: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sco.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sco.300.vec.gz) |
| Scottish Gaelic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gd.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.gd.300.vec.gz) | Serbian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sr.300.vec.gz) | Serbo-Croatian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sh.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sh.300.vec.gz) |
| Sicilian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.scn.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.scn.300.vec.gz) | Sindhi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sd.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sd.300.vec.gz) | Sinhalese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.si.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.si.300.vec.gz) |
| Slovak: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sk.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sk.300.vec.gz) | Slovenian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sl.300.vec.gz) | Somali: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.so.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.so.300.vec.gz) |
| Southern Azerbaijani: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.azb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.azb.300.vec.gz) | Spanish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.es.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.es.300.vec.gz) | Sundanese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.su.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.su.300.vec.gz) |
| Swahili: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sw.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sw.300.vec.gz) | Swedish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sv.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.sv.300.vec.gz) | Tagalog: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tl.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tl.300.vec.gz) |
| Tajik: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tg.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tg.300.vec.gz) | Tamil: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ta.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ta.300.vec.gz) | Tatar: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tt.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tt.300.vec.gz) |
| Telugu: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.te.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.te.300.vec.gz) | Thai: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.th.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.th.300.vec.gz) | Tibetan: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bo.300.vec.gz) |
| Turkish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tr.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tr.300.vec.gz) | Turkmen: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tk.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.tk.300.vec.gz) | Ukrainian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.uk.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.uk.300.vec.gz) |
| Upper Sorbian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hsb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.hsb.300.vec.gz) | Urdu: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ur.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ur.300.vec.gz) | Uyghur: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ug.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ug.300.vec.gz) |
| Uzbek: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.uz.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.uz.300.vec.gz) | Venetian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vec.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vec.300.vec.gz) | Vietnamese: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vi.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vi.300.vec.gz) |
| Volapük: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vo.300.vec.gz) | Walloon: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.wa.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.wa.300.vec.gz) | Waray: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.war.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.war.300.vec.gz) |
| Welsh: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cy.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.cy.300.vec.gz) | West Flemish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vls.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.vls.300.vec.gz) | West Frisian: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fy.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fy.300.vec.gz) |
| Western Punjabi: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pnb.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pnb.300.vec.gz) | Yiddish: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.yi.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.yi.300.vec.gz) | Yoruba: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.yo.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.yo.300.vec.gz) |
| Zazaki: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.diq.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.diq.300.vec.gz) | Zeelandic: [bin](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zea.300.bin.gz), [text](https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zea.300.vec.gz) |
������������������������������������������������������������������������������������fastText-0.9.2/docs/references.md�������������������������������������������������������������������0000644�0001750�0000176�00000003007�13651775021�016261� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: references
title: References
---
Please cite [1](#enriching-word-vectors-with-subword-information) if using this code for learning word representations or [2](#bag-of-tricks-for-efficient-text-classification) if using for text classification.
[1] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
```markup
@article{bojanowski2016enriching,
title={Enriching Word Vectors with Subword Information},
author={Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.04606},
year={2016}
}
```
[2] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
```markup
@article{joulin2016bag,
title={Bag of Tricks for Efficient Text Classification},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
journal={arXiv preprint arXiv:1607.01759},
year={2016}
}
```
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
```markup
@article{joulin2016fasttext,
title={FastText.zip: Compressing text classification models},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
journal={arXiv preprint arXiv:1612.03651},
year={2016}
}
```
(\* These authors contributed equally.)
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/supervised-tutorial.md����������������������������������������������������������0000644�0001750�0000176�00000054576�13651775021�020213� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: supervised-tutorial
title: Text classification
---
Text classification is a core problem to many applications, like spam detection, sentiment analysis or smart replies. In this tutorial, we describe how to build a text classifier with the fastText tool.
## What is text classification?
The goal of text classification is to assign documents (such as emails, posts, text messages, product reviews, etc...) to one or multiple categories. Such categories can be review scores, spam v.s. non-spam, or the language in which the document was typed. Nowadays, the dominant approach to build such classifiers is machine learning, that is learning classification rules from examples. In order to build such classifiers, we need labeled data, which consists of documents and their corresponding categories (or tags, or labels).
As an example, we build a classifier which automatically classifies stackexchange questions about cooking into one of several possible tags, such as `pot`, `bowl` or `baking`.
## Installing fastText
The first step of this tutorial is to install and build fastText. It only requires a c++ compiler with good support of c++11.
Let us start by downloading the [most recent release](https://github.com/facebookresearch/fastText/releases):
```bash
$ wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
$ unzip v0.9.2.zip
```
Move to the fastText directory and build it:
```bash
$ cd fastText-0.9.2
# for command line tool :
$ make
# for python bindings :
$ pip install .
```
Running the binary without any argument will print the high level documentation, showing the different use cases supported by fastText:
```bash
>> ./fasttext
usage: fasttext
The commands supported by fasttext are:
supervised train a supervised classifier
quantize quantize a model to reduce the memory usage
test evaluate a supervised classifier
predict predict most likely labels
predict-prob predict most likely labels with probabilities
skipgram train a skipgram model
cbow train a cbow model
print-word-vectors print word vectors given a trained model
print-sentence-vectors print sentence vectors given a trained model
nn query for nearest neighbors
analogies query for analogies
```
In this tutorial, we mainly use the `supervised`, `test` and `predict` subcommands, which corresponds to learning (and using) text classifier. For an introduction to the other functionalities of fastText, please see the [tutorial about learning word vectors](https://fasttext.cc/docs/en/unsupervised-tutorial.html).
Calling the help function will show high level documentation of the library:
```py
>>> import fasttext
>>> help(fasttext.FastText)
Help on module fasttext.FastText in fasttext:
NAME
fasttext.FastText
DESCRIPTION
# Copyright (c) 2017-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
FUNCTIONS
load_model(path)
Load a model given a filepath and return a model object.
read_args(arg_list, arg_dict, arg_names, default_values)
tokenize(text)
Given a string of text, tokenize it and return a list of tokens
train_supervised(*kargs, **kwargs)
Train a supervised model and return a model object.
input must be a filepath. The input text does not need to be tokenized
as per the tokenize function, but it must be preprocessed and encoded
as UTF-8. You might want to consult standard preprocessing scripts such
as tokenizer.perl mentioned here: http://www.statmt.org/wmt07/baseline.html
The input file must must contain at least one label per line. For an
example consult the example datasets which are part of the fastText
repository such as the dataset pulled by classification-example.sh.
train_unsupervised(*kargs, **kwargs)
Train an unsupervised model and return a model object.
input must be a filepath. The input text does not need to be tokenized
as per the tokenize function, but it must be preprocessed and encoded
as UTF-8. You might want to consult standard preprocessing scripts such
as tokenizer.perl mentioned here: http://www.statmt.org/wmt07/baseline.html
The input field must not contain any labels or use the specified label prefix
unless it is ok for those words to be ignored. For an example consult the
dataset pulled by the example script word-vector-example.sh, which is
part of the fastText repository.
```
In this tutorial, we mainly use the `train_supervised`, which returns a model object, and call `test` and `predict` on this object. That corresponds to learning (and using) text classifier. For an introduction to the other functionalities of fastText, please see the [tutorial about learning word vectors](https://fasttext.cc/docs/en/unsupervised-tutorial.html).
## Getting and preparing the data
As mentioned in the introduction, we need labeled data to train our supervised classifier. In this tutorial, we are interested in building a classifier to automatically recognize the topic of a stackexchange question about cooking. Let's download examples of questions from [the cooking section of Stackexchange](http://cooking.stackexchange.com/), and their associated tags:
```bash
>> wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
>> head cooking.stackexchange.txt
```
Each line of the text file contains a list of labels, followed by the corresponding document. All the labels start by the `__label__` prefix, which is how fastText recognize what is a label or what is a word. The model is then trained to predict the labels given the word in the document.
Before training our first classifier, we need to split the data into train and validation. We will use the validation set to evaluate how good the learned classifier is on new data.
```bash
>> wc cooking.stackexchange.txt
15404 169582 1401900 cooking.stackexchange.txt
```
Our full dataset contains 15404 examples. Let's split it into a training set of 12404 examples and a validation set of 3000 examples:
```bash
>> head -n 12404 cooking.stackexchange.txt > cooking.train
>> tail -n 3000 cooking.stackexchange.txt > cooking.valid
```
## Our first classifier
We are now ready to train our first classifier:
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking
Read 0M words
Number of words: 14598
Number of labels: 734
Progress: 100.0% words/sec/thread: 75109 lr: 0.000000 loss: 5.708354 eta: 0h0m
```
The `-input` command line option indicates the file containing the training examples, while the `-output` option indicates where to save the model. At the end of training, a file `model_cooking.bin`, containing the trained classifier, is created in the current directory.
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 14598
Number of labels: 734
Progress: 100.0% words/sec/thread: 75109 lr: 0.000000 loss: 5.708354 eta: 0h0m
```
The `input` argument indicates the file containing the training examples. We can now use the `model` variable to access information on the trained model.
We can also call `save_model` to save it as a file and load it later with `load_model` function.
```py
>>> model.save_model("model_cooking.bin")
```
Now, we can test our classifier, by :
```bash
>> ./fasttext predict model_cooking.bin -
```
and then typing a sentence. Let's first try the sentence:
*Which baking dish is best to bake a banana bread ?*
The predicted tag is `baking` which fits well to this question. Let us now try a second example:
*Why not put knives in the dishwasher?*
```py
>>> model.predict("Which baking dish is best to bake a banana bread ?")
((u'__label__baking',), array([0.15613931]))
```
The predicted tag is `baking` which fits well to this question. Let us now try a second example:
```py
>>> model.predict("Why not put knives in the dishwasher?")
((u'__label__food-safety',), array([0.08686075]))
```
The label predicted by the model is `food-safety`, which is not relevant. Somehow, the model seems to fail on simple examples.
To get a better sense of its quality, let's test it on the validation data by running:
```bash
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.124
R@1 0.0541
Number of examples: 3000
```
The output of fastText are the precision at one (`P@1`) and the recall at one (`R@1`).
```py
>>> model.test("cooking.valid")
(3000L, 0.124, 0.0541)
```
The output are the number of samples (here `3000`), the precision at one (`0.124`) and the recall at one (`0.0541`).
We can also compute the precision at five and recall at five with:
```bash
>> ./fasttext test model_cooking.bin cooking.valid 5
N 3000
P@5 0.0668
R@5 0.146
Number of examples: 3000
```
```py
>>> model.test("cooking.valid", k=5)
(3000L, 0.0668, 0.146)
```
## Advanced readers: precision and recall
The precision is the number of correct labels among the labels predicted by fastText. The recall is the number of labels that successfully were predicted, among all the real labels. Let's take an example to make this more clear:
*Why not put knives in the dishwasher?*
On Stack Exchange, this sentence is labeled with three tags: `equipment`, `cleaning` and `knives`. The top five labels predicted by the model can be obtained with:
```bash
>> ./fasttext predict model_cooking.bin - 5
```
```py
>>> model.predict("Why not put knives in the dishwasher?", k=5)
((u'__label__food-safety', u'__label__baking', u'__label__equipment', u'__label__substitutions', u'__label__bread'), array([0.0857 , 0.0657, 0.0454, 0.0333, 0.0333]))
```
are `food-safety`, `baking`, `equipment`, `substitutions` and `bread`.
Thus, one out of five labels predicted by the model is correct, giving a precision of 0.20. Out of the three real labels, only one is predicted by the model, giving a recall of 0.33.
For more details, see [the related Wikipedia page](https://en.wikipedia.org/wiki/Precision_and_recall).
## Making the model better
The model obtained by running fastText with the default arguments is pretty bad at classifying new questions. Let's try to improve the performance, by changing the default parameters.
### preprocessing the data
Looking at the data, we observe that some words contain uppercase letter or punctuation. One of the first step to improve the performance of our model is to apply some simple pre-processing. A crude normalization can be obtained using command line tools such as `sed` and `tr`:
```bash
>> cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt
>> head -n 12404 cooking.preprocessed.txt > cooking.train
>> tail -n 3000 cooking.preprocessed.txt > cooking.valid
```
Let's train a new model on the pre-processed data:
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 82041 lr: 0.000000 loss: 5.671649 eta: 0h0m
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.164
R@1 0.0717
Number of examples: 3000
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input="cooking.train")
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 82041 lr: 0.000000 loss: 5.671649 eta: 0h0m
>>> model.test("cooking.valid")
(3000L, 0.164, 0.0717)
```
We observe that thanks to the pre-processing, the vocabulary is smaller (from 14k words to 9k). The precision is also starting to go up by 4%!
### more epochs and larger learning rate
By default, fastText sees each training example only five times during training, which is pretty small, given that our training set only have 12k training examples. The number of times each examples is seen (also known as the number of epochs), can be increased using the `-epoch` option:
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -epoch 25
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 77633 lr: 0.000000 loss: 7.147976 eta: 0h0m
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input="cooking.train", epoch=25)
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 77633 lr: 0.000000 loss: 7.147976 eta: 0h0m
```
Let's test the new model:
```bash
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.501
R@1 0.218
Number of examples: 3000
```
```py
>>> model.test("cooking.valid")
(3000L, 0.501, 0.218)
```
This is much better! Another way to change the learning speed of our model is to increase (or decrease) the learning rate of the algorithm. This corresponds to how much the model changes after processing each example. A learning rate of 0 would mean that the model does not change at all, and thus, does not learn anything. Good values of the learning rate are in the range `0.1 - 1.0`.
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -lr 1.0
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 81469 lr: 0.000000 loss: 6.405640 eta: 0h0m
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.563
R@1 0.245
Number of examples: 3000
```
```py
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0)
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 81469 lr: 0.000000 loss: 6.405640 eta: 0h0m
>>> model.test("cooking.valid")
(3000L, 0.563, 0.245)
```
Even better! Let's try both together:
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 76394 lr: 0.000000 loss: 4.350277 eta: 0h0m
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.585
R@1 0.255
Number of examples: 3000
```
```py
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25)
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 76394 lr: 0.000000 loss: 4.350277 eta: 0h0m
>>> model.test("cooking.valid")
(3000L, 0.585, 0.255)
```
Let us now add a few more features to improve even further our performance!
### word n-grams
Finally, we can improve the performance of a model by using word bigrams, instead of just unigrams. This is especially important for classification problems where word order is important, such as sentiment analysis.
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25 -wordNgrams 2
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 75366 lr: 0.000000 loss: 3.226064 eta: 0h0m
>> ./fasttext test model_cooking.bin cooking.valid
N 3000
P@1 0.599
R@1 0.261
Number of examples: 3000
```
```py
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2)
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 75366 lr: 0.000000 loss: 3.226064 eta: 0h0m
>>> model.test("cooking.valid")
(3000L, 0.599, 0.261)
```
With a few steps, we were able to go from a precision at one of 12.4% to 59.9%. Important steps included:
* preprocessing the data ;
* changing the number of epochs (using the option `-epoch`, standard range `[5 - 50]`) ;
* changing the learning rate (using the option `-lr`, standard range `[0.1 - 1.0]`) ;
* using word n-grams (using the option `-wordNgrams`, standard range `[1 - 5]`).
## Advanced readers: What is a Bigram?
A 'unigram' refers to a single undividing unit, or token, usually used as an input to a model. For example a unigram can be a word or a letter depending on the model. In fastText, we work at the word level and thus unigrams are words.
Similarly we denote by 'bigram' the concatenation of 2 consecutive tokens or words. Similarly we often talk about n-gram to refer to the concatenation any n consecutive tokens.
For example, in the sentence, 'Last donut of the night', the unigrams are 'last', 'donut', 'of', 'the' and 'night'. The bigrams are: 'Last donut', 'donut of', 'of the' and 'the night'.
Bigrams are particularly interesting because, for most sentences, you can reconstruct the order of the words just by looking at a bag of n-grams.
Let us illustrate this by a simple exercise, given the following bigrams, try to reconstruct the original sentence: 'all out', 'I am', 'of bubblegum', 'out of' and 'am all'.
It is common to refer to a word as a unigram.
## Scaling things up
Since we are training our model on a few thousands of examples, the training only takes a few seconds. But training models on larger datasets, with more labels can start to be too slow. A potential solution to make the training faster is to use the [hierarchical softmax](#advanced-readers-hierarchical-softmax), instead of the regular softmax. This can be done with the option `-loss hs`:
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -lr 1.0 -epoch 25 -wordNgrams 2 -bucket 200000 -dim 50 -loss hs
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 2199406 lr: 0.000000 loss: 1.718807 eta: 0h0m
```
```py
>>> model = fasttext.train_supervised(input="cooking.train", lr=1.0, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='hs')
Read 0M words
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 2199406 lr: 0.000000 loss: 1.718807 eta: 0h0m
```
Training should now take less than a second.
## Advanced readers: hierarchical softmax
The hierarchical softmax is a loss function that approximates the softmax with a much faster computation.
The idea is to build a binary tree whose leaves correspond to the labels. Each intermediate node has a binary decision activation (e.g. sigmoid) that is trained, and predicts if we should go to the left or to the right. The probability of the output unit is then given by the product of the probabilities of intermediate nodes along the path from the root to the output unit leave.
For a detailed explanation, you can have a look on [this video](https://www.youtube.com/watch?v=B95LTf2rVWM).
In fastText, we use a Huffman tree, so that the lookup time is faster for more frequent outputs and thus the average lookup time for the output is optimal.
## Multi-label classification
When we want to assign a document to multiple labels, we can still use the softmax loss and play with the parameters for prediction, namely the number of labels to predict and the threshold for the predicted probability. However playing with these arguments can be tricky and unintuitive since the probabilities must sum to 1.
A convenient way to handle multiple labels is to use independent binary classifiers for each label. This can be done with `-loss one-vs-all` or `-loss ova`.
```bash
>> ./fasttext supervised -input cooking.train -output model_cooking -lr 0.5 -epoch 25 -wordNgrams 2 -bucket 200000 -dim 50 -loss one-vs-all
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 72104 lr: 0.000000 loss: 4.340807 ETA: 0h 0m
```
```py
>>> import fasttext
>>> model = fasttext.train_supervised(input="cooking.train", lr=0.5, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='ova')
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 72104 lr: 0.000000 loss: 4.340807 ETA: 0h 0m
```
It is a good idea to decrease the learning rate compared to other loss functions.
Now let's have a look on our predictions, we want as many prediction as possible (argument `-1`) and we want only labels with probability higher or equal to `0.5` :
```bash
>> ./fasttext predict-prob model_cooking.bin - -1 0.5
```
and then type the sentence:
*Which baking dish is best to bake a banana bread ?*
we get:
```
__label__baking 1.00000 __label__bananas 0.939923 __label__bread 0.592677
```
```py
>>> model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
((u''__label__baking, u'__label__bananas', u'__label__bread'), array([1.00000, 0.939923, 0.592677]))
```
We can also evaluate our results with the `test` command :
```bash
>> ./fasttext test model_cooking.bin cooking.valid -1 0.5
N 3000
P@-1 0.702
R@-1 0.2
Number of examples: 3000
```
and play with the threshold to obtain desired precision/recall metrics :
```bash
>> ./fasttext test model_cooking.bin cooking.valid -1 0.1
N 3000
P@-1 0.591
R@-1 0.272
Number of examples: 3000
```
We can also evaluate our results with the `test` function:
```py
>>> model.test("cooking.valid", k=-1)
(3000L, 0.702, 0.2)
```
## Conclusion
In this tutorial, we gave a brief overview of how to use fastText to train powerful text classifiers. We had a light overview of some of the most important options to tune.
����������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/docs/support.md����������������������������������������������������������������������0000644�0001750�0000176�00000002762�13651775021�015663� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
id: support
title: Get started
---
## What is fastText?
fastText is a library for efficient learning of word representations and sentence classification.
## Requirements
fastText builds on modern Mac OS and Linux distributions.
Since it uses C++11 features, it requires a compiler with good C++11 support.
These include :
* (gcc-4.6.3 or newer) or (clang-3.3 or newer)
Compilation is carried out using a Makefile, so you will need to have a working **make**.
For the word-similarity evaluation script you will need:
* python 2.6 or newer
* numpy & scipy
## Building fastText as a command line tool
In order to build `fastText`, use the following:
```bash
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
```
This will produce object files for all the classes as well as the main binary `fasttext`.
If you do not plan on using the default system-wide compiler, update the two macros defined at the beginning of the Makefile (CC and INCLUDES).
## Building `fasttext` python module
In order to build `fasttext` module for python, use the following:
```bash
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ sudo pip install .
$ # or :
$ sudo python setup.py install
```
Then verify the installation went well :
```bash
$ python
Python 2.7.15 |(default, May 1 2018, 18:37:05)
Type "help", "copyright", "credits" or "license" for more information.
>>> import fasttext
>>>
```
If you don't see any error message, the installation was successful.
��������������fastText-0.9.2/alignment/���������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�014644� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/example.sh�����������������������������������������������������������������0000755�0001750�0000176�00000002600�13651775021�016634� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/bin/usr/env sh
# Copyright (c) 2018-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
set -e
s=${1:-en}
t=${2:-es}
echo "Example based on the ${s}->${t} alignment"
if [ ! -d data/ ]; then
mkdir -p data;
fi
if [ ! -d res/ ]; then
mkdir -p res;
fi
dico_train=data/${s}-${t}.0-5000.txt
if [ ! -f "${dico_train}" ]; then
DICO=$(basename -- "${dico_train}")
wget -c "https://dl.fbaipublicfiles.com/arrival/dictionaries/${DICO}" -P data/
fi
dico_test=data/${s}-${t}.5000-6500.txt
if [ ! -f "${dico_test}" ]; then
DICO=$(basename -- "${dico_test}")
wget -c "https://dl.fbaipublicfiles.com/arrival/dictionaries/${DICO}" -P data/
fi
src_emb=data/wiki.${s}.vec
if [ ! -f "${src_emb}" ]; then
EMB=$(basename -- "${src_emb}")
wget -c "https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/${EMB}" -P data/
fi
tgt_emb=data/wiki.${t}.vec
if [ ! -f "${tgt_emb}" ]; then
EMB=$(basename -- "${tgt_emb}")
wget -c "https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/${EMB}" -P data/
fi
output=res/wiki.${s}-${t}.vec
python3 align.py --src_emb "${src_emb}" --tgt_emb "${tgt_emb}" \
--dico_train "${dico_train}" --dico_test "${dico_test}" --output "${output}" \
--lr 25 --niter 10
python3 eval.py --src_emb "${output}" --tgt_emb "${tgt_emb}" \
--dico_test "${dico_test}"
��������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/unsup_align.py�������������������������������������������������������������0000644�0001750�0000176�00000011010�13651775021�017533� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
# Copyright (c) 2018-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import codecs, sys, time, math, argparse, ot
import numpy as np
from utils import *
parser = argparse.ArgumentParser(description='Wasserstein Procrustes for Embedding Alignment')
parser.add_argument('--model_src', type=str, help='Path to source word embeddings')
parser.add_argument('--model_tgt', type=str, help='Path to target word embeddings')
parser.add_argument('--lexicon', type=str, help='Path to the evaluation lexicon')
parser.add_argument('--output_src', default='', type=str, help='Path to save the aligned source embeddings')
parser.add_argument('--output_tgt', default='', type=str, help='Path to save the aligned target embeddings')
parser.add_argument('--seed', default=1111, type=int, help='Random number generator seed')
parser.add_argument('--nepoch', default=5, type=int, help='Number of epochs')
parser.add_argument('--niter', default=5000, type=int, help='Initial number of iterations')
parser.add_argument('--bsz', default=500, type=int, help='Initial batch size')
parser.add_argument('--lr', default=500., type=float, help='Learning rate')
parser.add_argument('--nmax', default=20000, type=int, help='Vocabulary size for learning the alignment')
parser.add_argument('--reg', default=0.05, type=float, help='Regularization parameter for sinkhorn')
args = parser.parse_args()
def objective(X, Y, R, n=5000):
Xn, Yn = X[:n], Y[:n]
C = -np.dot(np.dot(Xn, R), Yn.T)
P = ot.sinkhorn(np.ones(n), np.ones(n), C, 0.025, stopThr=1e-3)
return 1000 * np.linalg.norm(np.dot(Xn, R) - np.dot(P, Yn)) / n
def sqrt_eig(x):
U, s, VT = np.linalg.svd(x, full_matrices=False)
return np.dot(U, np.dot(np.diag(np.sqrt(s)), VT))
def align(X, Y, R, lr=10., bsz=200, nepoch=5, niter=1000,
nmax=10000, reg=0.05, verbose=True):
for epoch in range(1, nepoch + 1):
for _it in range(1, niter + 1):
# sample mini-batch
xt = X[np.random.permutation(nmax)[:bsz], :]
yt = Y[np.random.permutation(nmax)[:bsz], :]
# compute OT on minibatch
C = -np.dot(np.dot(xt, R), yt.T)
P = ot.sinkhorn(np.ones(bsz), np.ones(bsz), C, reg, stopThr=1e-3)
# compute gradient
G = - np.dot(xt.T, np.dot(P, yt))
R -= lr / bsz * G
# project on orthogonal matrices
U, s, VT = np.linalg.svd(R)
R = np.dot(U, VT)
bsz *= 2
niter //= 4
if verbose:
print("epoch: %d obj: %.3f" % (epoch, objective(X, Y, R)))
return R
def convex_init(X, Y, niter=100, reg=0.05, apply_sqrt=False):
n, d = X.shape
if apply_sqrt:
X, Y = sqrt_eig(X), sqrt_eig(Y)
K_X, K_Y = np.dot(X, X.T), np.dot(Y, Y.T)
K_Y *= np.linalg.norm(K_X) / np.linalg.norm(K_Y)
K2_X, K2_Y = np.dot(K_X, K_X), np.dot(K_Y, K_Y)
P = np.ones([n, n]) / float(n)
for it in range(1, niter + 1):
G = np.dot(P, K2_X) + np.dot(K2_Y, P) - 2 * np.dot(K_Y, np.dot(P, K_X))
q = ot.sinkhorn(np.ones(n), np.ones(n), G, reg, stopThr=1e-3)
alpha = 2.0 / float(2.0 + it)
P = alpha * q + (1.0 - alpha) * P
obj = np.linalg.norm(np.dot(P, K_X) - np.dot(K_Y, P))
print(obj)
return procrustes(np.dot(P, X), Y).T
print("\n*** Wasserstein Procrustes ***\n")
np.random.seed(args.seed)
maxload = 200000
w_src, x_src = load_vectors(args.model_src, maxload, norm=True, center=True)
w_tgt, x_tgt = load_vectors(args.model_tgt, maxload, norm=True, center=True)
src2trg, _ = load_lexicon(args.lexicon, w_src, w_tgt)
print("\nComputing initial mapping with convex relaxation...")
t0 = time.time()
R0 = convex_init(x_src[:2500], x_tgt[:2500], reg=args.reg, apply_sqrt=True)
print("Done [%03d sec]" % math.floor(time.time() - t0))
print("\nComputing mapping with Wasserstein Procrustes...")
t0 = time.time()
R = align(x_src, x_tgt, R0.copy(), bsz=args.bsz, lr=args.lr, niter=args.niter,
nepoch=args.nepoch, reg=args.reg, nmax=args.nmax)
print("Done [%03d sec]" % math.floor(time.time() - t0))
acc = compute_nn_accuracy(x_src, np.dot(x_tgt, R.T), src2trg)
print("\nPrecision@1: %.3f\n" % acc)
if args.output_src != '':
x_src = x_src / np.linalg.norm(x_src, 2, 1).reshape([-1, 1])
save_vectors(args.output_src, x_src, w_src)
if args.output_tgt != '':
x_tgt = x_tgt / np.linalg.norm(x_tgt, 2, 1).reshape([-1, 1])
save_vectors(args.output_tgt, np.dot(x_tgt, R.T), w_tgt)
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/README.md������������������������������������������������������������������0000644�0001750�0000176�00000005467�13651775021�016137� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������## Alignment of Word Embeddings
This directory provides code for learning alignments between word embeddings in different languages.
The code is in Python 3 and requires [NumPy](http://www.numpy.org/).
The script `example.sh` shows how to use this code to learn and evaluate a bilingual alignment of word embeddings.
The word embeddings used in [1] can be found on the [fastText project page](https://fasttext.cc) and the supervised bilingual lexicons on the [MUSE project page](https://github.com/facebookresearch/MUSE).
### Supervised alignment
The script `align.py` aligns word embeddings from two languages using a bilingual lexicon as supervision.
The details of this approach can be found in [1].
### Unsupervised alignment
The script `unsup_align.py` aligns word embeddings from two languages without requiring any supervision.
Additionally, the script `unsup_multialign.py` aligns multiple languages to a common space with no supervision.
The details of these approaches can be found in [2] and [3] respectively.
In addition to NumPy, the unsupervised methods require the [Python Optimal Transport](https://pot.readthedocs.io/en/stable/) toolbox.
### Download
Wikipedia fastText embeddings aligned with our method can be found [here](https://fasttext.cc/docs/en/aligned-vectors.html).
### References
If you use the supervised alignment method, please cite:
[1] A. Joulin, P. Bojanowski, T. Mikolov, H. Jegou, E. Grave, [*Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion*](https://arxiv.org/abs/1804.07745)
```
@InProceedings{joulin2018loss,
title={Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion},
author={Joulin, Armand and Bojanowski, Piotr and Mikolov, Tomas and J\'egou, Herv\'e and Grave, Edouard},
year={2018},
booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
}
```
If you use the unsupervised bilingual alignment method, please cite:
[2] E. Grave, A. Joulin, Q. Berthet, [*Unsupervised Alignment of Embeddings with Wasserstein Procrustes*](https://arxiv.org/abs/1805.11222)
```
@article{grave2018unsupervised,
title={Unsupervised Alignment of Embeddings with Wasserstein Procrustes},
author={Grave, Edouard and Joulin, Armand and Berthet, Quentin},
journal={arXiv preprint arXiv:1805.11222},
year={2018}
}
```
If you use the unsupervised alignment script `unsup_multialign.py`, please cite:
[3] J. Alaux, E. Grave, M. Cuturi, A. Joulin, [*Unsupervised Hyperalignment for Multilingual Word Embeddings*](https://arxiv.org/abs/1811.01124)
```
@article{alaux2018unsupervised,
title={Unsupervised hyperalignment for multilingual word embeddings},
author={Alaux, Jean and Grave, Edouard and Cuturi, Marco and Joulin, Armand},
journal={arXiv preprint arXiv:1811.01124},
year={2018}
}
```
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/utils.py�������������������������������������������������������������������0000644�0001750�0000176�00000011303�13651775021�016354� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
# Copyright (c) 2018-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import io
import numpy as np
import collections
def load_vectors(fname, maxload=200000, norm=True, center=False, verbose=True):
if verbose:
print("Loading vectors from %s" % fname)
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
if maxload > 0:
n = min(n, maxload)
x = np.zeros([n, d])
words = []
for i, line in enumerate(fin):
if i >= n:
break
tokens = line.rstrip().split(' ')
words.append(tokens[0])
v = np.array(tokens[1:], dtype=float)
x[i, :] = v
if norm:
x /= np.linalg.norm(x, axis=1)[:, np.newaxis] + 1e-8
if center:
x -= x.mean(axis=0)[np.newaxis, :]
x /= np.linalg.norm(x, axis=1)[:, np.newaxis] + 1e-8
if verbose:
print("%d word vectors loaded" % (len(words)))
return words, x
def idx(words):
w2i = {}
for i, w in enumerate(words):
if w not in w2i:
w2i[w] = i
return w2i
def save_vectors(fname, x, words):
n, d = x.shape
fout = io.open(fname, 'w', encoding='utf-8')
fout.write(u"%d %d\n" % (n, d))
for i in range(n):
fout.write(words[i] + " " + " ".join(map(lambda a: "%.4f" % a, x[i, :])) + "\n")
fout.close()
def save_matrix(fname, x):
n, d = x.shape
fout = io.open(fname, 'w', encoding='utf-8')
fout.write(u"%d %d\n" % (n, d))
for i in range(n):
fout.write(" ".join(map(lambda a: "%.4f" % a, x[i, :])) + "\n")
fout.close()
def procrustes(X_src, Y_tgt):
U, s, V = np.linalg.svd(np.dot(Y_tgt.T, X_src))
return np.dot(U, V)
def select_vectors_from_pairs(x_src, y_tgt, pairs):
n = len(pairs)
d = x_src.shape[1]
x = np.zeros([n, d])
y = np.zeros([n, d])
for k, ij in enumerate(pairs):
i, j = ij
x[k, :] = x_src[i, :]
y[k, :] = y_tgt[j, :]
return x, y
def load_lexicon(filename, words_src, words_tgt, verbose=True):
f = io.open(filename, 'r', encoding='utf-8')
lexicon = collections.defaultdict(set)
idx_src , idx_tgt = idx(words_src), idx(words_tgt)
vocab = set()
for line in f:
word_src, word_tgt = line.split()
if word_src in idx_src and word_tgt in idx_tgt:
lexicon[idx_src[word_src]].add(idx_tgt[word_tgt])
vocab.add(word_src)
if verbose:
coverage = len(lexicon) / float(len(vocab))
print("Coverage of source vocab: %.4f" % (coverage))
return lexicon, float(len(vocab))
def load_pairs(filename, idx_src, idx_tgt, verbose=True):
f = io.open(filename, 'r', encoding='utf-8')
pairs = []
tot = 0
for line in f:
a, b = line.rstrip().split(' ')
tot += 1
if a in idx_src and b in idx_tgt:
pairs.append((idx_src[a], idx_tgt[b]))
if verbose:
coverage = (1.0 * len(pairs)) / tot
print("Found pairs for training: %d - Total pairs in file: %d - Coverage of pairs: %.4f" % (len(pairs), tot, coverage))
return pairs
def compute_nn_accuracy(x_src, x_tgt, lexicon, bsz=100, lexicon_size=-1):
if lexicon_size < 0:
lexicon_size = len(lexicon)
idx_src = list(lexicon.keys())
acc = 0.0
x_src /= np.linalg.norm(x_src, axis=1)[:, np.newaxis] + 1e-8
x_tgt /= np.linalg.norm(x_tgt, axis=1)[:, np.newaxis] + 1e-8
for i in range(0, len(idx_src), bsz):
e = min(i + bsz, len(idx_src))
scores = np.dot(x_tgt, x_src[idx_src[i:e]].T)
pred = scores.argmax(axis=0)
for j in range(i, e):
if pred[j - i] in lexicon[idx_src[j]]:
acc += 1.0
return acc / lexicon_size
def compute_csls_accuracy(x_src, x_tgt, lexicon, lexicon_size=-1, k=10, bsz=1024):
if lexicon_size < 0:
lexicon_size = len(lexicon)
idx_src = list(lexicon.keys())
x_src /= np.linalg.norm(x_src, axis=1)[:, np.newaxis] + 1e-8
x_tgt /= np.linalg.norm(x_tgt, axis=1)[:, np.newaxis] + 1e-8
sr = x_src[list(idx_src)]
sc = np.dot(sr, x_tgt.T)
similarities = 2 * sc
sc2 = np.zeros(x_tgt.shape[0])
for i in range(0, x_tgt.shape[0], bsz):
j = min(i + bsz, x_tgt.shape[0])
sc_batch = np.dot(x_tgt[i:j, :], x_src.T)
dotprod = np.partition(sc_batch, -k, axis=1)[:, -k:]
sc2[i:j] = np.mean(dotprod, axis=1)
similarities -= sc2[np.newaxis, :]
nn = np.argmax(similarities, axis=1).tolist()
correct = 0.0
for k in range(0, len(lexicon)):
if nn[k] in lexicon[idx_src[k]]:
correct += 1.0
return correct / lexicon_size
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/unsup_multialign.py��������������������������������������������������������0000644�0001750�0000176�00000017062�13651775021�020623� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Copyright (c) 2019-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import io, os, ot, argparse, random
import numpy as np
from utils import *
parser = argparse.ArgumentParser(description=' ')
parser.add_argument('--embdir', default='data/', type=str)
parser.add_argument('--outdir', default='output/', type=str)
parser.add_argument('--lglist', default='en-fr-es-it-pt-de-pl-ru-da-nl-cs', type=str,
help='list of languages. The first element is the pivot. Example: en-fr-es to align English, French and Spanish with English as the pivot.')
parser.add_argument('--maxload', default=20000, type=int, help='Max number of loaded vectors')
parser.add_argument('--uniform', action='store_true', help='switch to uniform probability of picking language pairs')
# optimization parameters for the square loss
parser.add_argument('--epoch', default=2, type=int, help='nb of epochs for square loss')
parser.add_argument('--niter', default=500, type=int, help='max number of iteration per epoch for square loss')
parser.add_argument('--lr', default=0.1, type=float, help='learning rate for square loss')
parser.add_argument('--bsz', default=500, type=int, help='batch size for square loss')
# optimization parameters for the RCSLS loss
parser.add_argument('--altepoch', default=100, type=int, help='nb of epochs for RCSLS loss')
parser.add_argument('--altlr', default=25, type=float, help='learning rate for RCSLS loss')
parser.add_argument("--altbsz", type=int, default=1000, help="batch size for RCSLS")
args = parser.parse_args()
###### SPECIFIC FUNCTIONS ######
def getknn(sc, x, y, k=10):
sidx = np.argpartition(sc, -k, axis=1)[:, -k:]
ytopk = y[sidx.flatten(), :]
ytopk = ytopk.reshape(sidx.shape[0], sidx.shape[1], y.shape[1])
f = np.sum(sc[np.arange(sc.shape[0])[:, None], sidx])
df = np.dot(ytopk.sum(1).T, x)
return f / k, df / k
def rcsls(Xi, Xj, Zi, Zj, R, knn=10):
X_trans = np.dot(Xi, R.T)
f = 2 * np.sum(X_trans * Xj)
df = 2 * np.dot(Xj.T, Xi)
fk0, dfk0 = getknn(np.dot(X_trans, Zj.T), Xi, Zj, knn)
fk1, dfk1 = getknn(np.dot(np.dot(Zi, R.T), Xj.T).T, Xj, Zi, knn)
f = f - fk0 -fk1
df = df - dfk0 - dfk1.T
return -f / Xi.shape[0], -df.T / Xi.shape[0]
def GWmatrix(emb0):
N = np.shape(emb0)[0]
N2 = .5* np.linalg.norm(emb0, axis=1).reshape(1, N)
C2 = np.tile(N2.transpose(), (1, N)) + np.tile(N2, (N, 1))
C2 -= np.dot(emb0,emb0.T)
return C2
def gromov_wasserstein(x_src, x_tgt, C2):
N = x_src.shape[0]
C1 = GWmatrix(x_src)
M = ot.gromov_wasserstein(C1,C2,np.ones(N),np.ones(N),'square_loss',epsilon=0.55,max_iter=100,tol=1e-4)
return procrustes(np.dot(M,x_tgt), x_src)
def align(EMB, TRANS, lglist, args):
nmax, l = args.maxload, len(lglist)
# create a list of language pairs to sample from
# (default == higher probability to pick a language pair contianing the pivot)
# if --uniform: uniform probability of picking a language pair
samples = []
for i in range(l):
for j in range(l):
if j == i :
continue
if j > 0 and args.uniform == False:
samples.append((0,j))
if i > 0 and args.uniform == False:
samples.append((i,0))
samples.append((i,j))
# optimization of the l2 loss
print('start optimizing L2 loss')
lr0, bsz, nepoch, niter = args.lr, args.bsz, args.epoch, args.niter
for epoch in range(nepoch):
print("start epoch %d / %d"%(epoch+1, nepoch))
ones = np.ones(bsz)
f, fold, nb, lr = 0.0, 0.0, 0.0, lr0
for it in range(niter):
if it > 1 and f > fold + 1e-3:
lr /= 2
if lr < .05:
break
fold = f
f, nb = 0.0, 0.0
for k in range(100 * (l-1)):
(i,j) = random.choice(samples)
embi = EMB[i][np.random.permutation(nmax)[:bsz], :]
embj = EMB[j][np.random.permutation(nmax)[:bsz], :]
perm = ot.sinkhorn(ones, ones, np.linalg.multi_dot([embi, -TRANS[i], TRANS[j].T,embj.T]), reg = 0.025, stopThr = 1e-3)
grad = np.linalg.multi_dot([embi.T, perm, embj])
f -= np.trace(np.linalg.multi_dot([TRANS[i].T, grad, TRANS[j]])) / embi.shape[0]
nb += 1
if i > 0:
TRANS[i] = proj_ortho(TRANS[i] + lr * np.dot(grad, TRANS[j]))
if j > 0:
TRANS[j] = proj_ortho(TRANS[j] + lr * np.dot(grad.transpose(), TRANS[i]))
print("iter %d / %d - epoch %d - loss: %.5f lr: %.4f" % (it, niter, epoch+1, f / nb , lr))
print("end of epoch %d - loss: %.5f - lr: %.4f" % (epoch+1, f / max(nb,1), lr))
niter, bsz = max(int(niter/2),2), min(1000, bsz * 2)
#end for epoch in range(nepoch):
# optimization of the RCSLS loss
print('start optimizing RCSLS loss')
f, fold, nb, lr = 0.0, 0.0, 0.0, args.altlr
for epoch in range(args.altepoch):
if epoch > 1 and f-fold > -1e-4 * abs(fold):
lr/= 2
if lr < 1e-1:
break
fold = f
f, nb = 0.0, 0.0
for k in range(round(nmax / args.altbsz) * 10 * (l-1)):
(i,j) = random.choice(samples)
sgdidx = np.random.choice(nmax, size=args.altbsz, replace=False)
embi = EMB[i][sgdidx, :]
embj = EMB[j][:nmax, :]
# crude alignment approximation:
T = np.dot(TRANS[i], TRANS[j].T)
scores = np.linalg.multi_dot([embi, T, embj.T])
perm = np.zeros_like(scores)
perm[np.arange(len(scores)), scores.argmax(1)] = 1
embj = np.dot(perm, embj)
# normalization over a subset of embeddings for speed up
fi, grad = rcsls(embi, embj, embi, embj, T.T)
f += fi
nb += 1
if i > 0:
TRANS[i] = proj_ortho(TRANS[i] - lr * np.dot(grad, TRANS[j]))
if j > 0:
TRANS[j] = proj_ortho(TRANS[j] - lr * np.dot(grad.transpose(), TRANS[i]))
print("epoch %d - loss: %.5f - lr: %.4f" % (epoch+1, f / max(nb,1), lr))
#end for epoch in range(args.altepoch):
return TRANS
def convex_init(X, Y, niter=100, reg=0.05, apply_sqrt=False):
n, d = X.shape
K_X, K_Y = np.dot(X, X.T), np.dot(Y, Y.T)
K_Y *= np.linalg.norm(K_X) / np.linalg.norm(K_Y)
K2_X, K2_Y = np.dot(K_X, K_X), np.dot(K_Y, K_Y)
P = np.ones([n, n]) / float(n)
for it in range(1, niter + 1):
G = np.dot(P, K2_X) + np.dot(K2_Y, P) - 2 * np.dot(K_Y, np.dot(P, K_X))
q = ot.sinkhorn(np.ones(n), np.ones(n), G, reg, stopThr=1e-3)
alpha = 2.0 / float(2.0 + it)
P = alpha * q + (1.0 - alpha) * P
return procrustes(np.dot(P, X), Y).T
###### MAIN ######
lglist = args.lglist.split('-')
l = len(lglist)
# embs:
EMB = {}
for i in range(l):
fn = args.embdir + '/wiki.' + lglist[i] + '.vec'
_, vecs = load_vectors(fn, maxload=args.maxload)
EMB[i] = vecs
#init
print("Computing initial bilingual apping with Gromov-Wasserstein...")
TRANS={}
maxinit = 2000
emb0 = EMB[0][:maxinit,:]
C0 = GWmatrix(emb0)
TRANS[0] = np.eye(300)
for i in range(1, l):
print("init "+lglist[i])
embi = EMB[i][:maxinit,:]
TRANS[i] = gromov_wasserstein(embi, emb0, C0)
# align
align(EMB, TRANS, lglist, args)
print('saving matrices in ' + args.outdir)
languages=''.join(lglist)
for i in range(l):
save_matrix(args.outdir + '/W-' + languages + '-' + lglist[i], TRANS[i])
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/alignment/eval.py��������������������������������������������������������������������0000644�0001750�0000176�00000004656�13651775021�016160� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Copyright (c) 2018-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import io
import numpy as np
import argparse
from utils import *
parser = argparse.ArgumentParser(description='Evaluation of word alignment')
parser.add_argument("--src_emb", type=str, default='', help="Load source embeddings")
parser.add_argument("--tgt_emb", type=str, default='', help="Load target embeddings")
parser.add_argument('--center', action='store_true', help='whether to center embeddings or not')
parser.add_argument("--src_mat", type=str, default='', help="Load source alignment matrix. If none given, the aligment matrix is the identity.")
parser.add_argument("--tgt_mat", type=str, default='', help="Load target alignment matrix. If none given, the aligment matrix is the identity.")
parser.add_argument("--dico_test", type=str, default='', help="test dictionary")
parser.add_argument("--maxload", type=int, default=200000)
parser.add_argument("--nomatch", action='store_true', help="no exact match in lexicon")
params = parser.parse_args()
###### SPECIFIC FUNCTIONS ######
# function specific to evaluation
# the rest of the functions are in utils.py
def load_transform(fname, d1=300, d2=300):
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
R = np.zeros([d1, d2])
for i, line in enumerate(fin):
tokens = line.split(' ')
R[i, :] = np.array(tokens[0:d2], dtype=float)
return R
###### MAIN ######
print("Evaluation of alignment on %s" % params.dico_test)
if params.nomatch:
print("running without exact string matches")
words_tgt, x_tgt = load_vectors(params.tgt_emb, maxload=params.maxload, center=params.center)
words_src, x_src = load_vectors(params.src_emb, maxload=params.maxload, center=params.center)
if params.tgt_mat != "":
R_tgt = load_transform(params.tgt_mat)
x_tgt = np.dot(x_tgt, R_tgt)
if params.src_mat != "":
R_src = load_transform(params.src_mat)
x_src = np.dot(x_src, R_src)
src2tgt, lexicon_size = load_lexicon(params.dico_test, words_src, words_tgt)
nnacc = compute_nn_accuracy(x_src, x_tgt, src2tgt, lexicon_size=lexicon_size)
cslsproc = compute_csls_accuracy(x_src, x_tgt, src2tgt, lexicon_size=lexicon_size)
print("NN = %.4f - CSLS = %.4f - Coverage = %.4f" % (nnacc, cslsproc, len(src2tgt) / lexicon_size))
����������������������������������������������������������������������������������fastText-0.9.2/alignment/align.py�������������������������������������������������������������������0000644�0001750�0000176�00000012327�13651775021�016315� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Copyright (c) 2018-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import numpy as np
import argparse
from utils import *
import sys
parser = argparse.ArgumentParser(description='RCSLS for supervised word alignment')
parser.add_argument("--src_emb", type=str, default='', help="Load source embeddings")
parser.add_argument("--tgt_emb", type=str, default='', help="Load target embeddings")
parser.add_argument('--center', action='store_true', help='whether to center embeddings or not')
parser.add_argument("--dico_train", type=str, default='', help="train dictionary")
parser.add_argument("--dico_test", type=str, default='', help="validation dictionary")
parser.add_argument("--output", type=str, default='', help="where to save aligned embeddings")
parser.add_argument("--knn", type=int, default=10, help="number of nearest neighbors in RCSL/CSLS")
parser.add_argument("--maxneg", type=int, default=200000, help="Maximum number of negatives for the Extended RCSLS")
parser.add_argument("--maxsup", type=int, default=-1, help="Maximum number of training examples")
parser.add_argument("--maxload", type=int, default=200000, help="Maximum number of loaded vectors")
parser.add_argument("--model", type=str, default="none", help="Set of constraints: spectral or none")
parser.add_argument("--reg", type=float, default=0.0 , help='regularization parameters')
parser.add_argument("--lr", type=float, default=1.0, help='learning rate')
parser.add_argument("--niter", type=int, default=10, help='number of iterations')
parser.add_argument('--sgd', action='store_true', help='use sgd')
parser.add_argument("--batchsize", type=int, default=10000, help="batch size for sgd")
params = parser.parse_args()
###### SPECIFIC FUNCTIONS ######
# functions specific to RCSLS
# the rest of the functions are in utils.py
def getknn(sc, x, y, k=10):
sidx = np.argpartition(sc, -k, axis=1)[:, -k:]
ytopk = y[sidx.flatten(), :]
ytopk = ytopk.reshape(sidx.shape[0], sidx.shape[1], y.shape[1])
f = np.sum(sc[np.arange(sc.shape[0])[:, None], sidx])
df = np.dot(ytopk.sum(1).T, x)
return f / k, df / k
def rcsls(X_src, Y_tgt, Z_src, Z_tgt, R, knn=10):
X_trans = np.dot(X_src, R.T)
f = 2 * np.sum(X_trans * Y_tgt)
df = 2 * np.dot(Y_tgt.T, X_src)
fk0, dfk0 = getknn(np.dot(X_trans, Z_tgt.T), X_src, Z_tgt, knn)
fk1, dfk1 = getknn(np.dot(np.dot(Z_src, R.T), Y_tgt.T).T, Y_tgt, Z_src, knn)
f = f - fk0 -fk1
df = df - dfk0 - dfk1.T
return -f / X_src.shape[0], -df / X_src.shape[0]
def proj_spectral(R):
U, s, V = np.linalg.svd(R)
s[s > 1] = 1
s[s < 0] = 0
return np.dot(U, np.dot(np.diag(s), V))
###### MAIN ######
# load word embeddings
words_tgt, x_tgt = load_vectors(params.tgt_emb, maxload=params.maxload, center=params.center)
words_src, x_src = load_vectors(params.src_emb, maxload=params.maxload, center=params.center)
# load validation bilingual lexicon
src2tgt, lexicon_size = load_lexicon(params.dico_test, words_src, words_tgt)
# word --> vector indices
idx_src = idx(words_src)
idx_tgt = idx(words_tgt)
# load train bilingual lexicon
pairs = load_pairs(params.dico_train, idx_src, idx_tgt)
if params.maxsup > 0 and params.maxsup < len(pairs):
pairs = pairs[:params.maxsup]
# selecting training vector pairs
X_src, Y_tgt = select_vectors_from_pairs(x_src, x_tgt, pairs)
# adding negatives for RCSLS
Z_src = x_src[:params.maxneg, :]
Z_tgt = x_tgt[:params.maxneg, :]
# initialization:
R = procrustes(X_src, Y_tgt)
nnacc = compute_nn_accuracy(np.dot(x_src, R.T), x_tgt, src2tgt, lexicon_size=lexicon_size)
print("[init -- Procrustes] NN: %.4f"%(nnacc))
sys.stdout.flush()
# optimization
fold, Rold = 0, []
niter, lr = params.niter, params.lr
for it in range(0, niter + 1):
if lr < 1e-4:
break
if params.sgd:
indices = np.random.choice(X_src.shape[0], size=params.batchsize, replace=False)
f, df = rcsls(X_src[indices, :], Y_tgt[indices, :], Z_src, Z_tgt, R, params.knn)
else:
f, df = rcsls(X_src, Y_tgt, Z_src, Z_tgt, R, params.knn)
if params.reg > 0:
R *= (1 - lr * params.reg)
R -= lr * df
if params.model == "spectral":
R = proj_spectral(R)
print("[it=%d] f = %.4f" % (it, f))
sys.stdout.flush()
if f > fold and it > 0 and not params.sgd:
lr /= 2
f, R = fold, Rold
fold, Rold = f, R
if (it > 0 and it % 10 == 0) or it == niter:
nnacc = compute_nn_accuracy(np.dot(x_src, R.T), x_tgt, src2tgt, lexicon_size=lexicon_size)
print("[it=%d] NN = %.4f - Coverage = %.4f" % (it, nnacc, len(src2tgt) / lexicon_size))
nnacc = compute_nn_accuracy(np.dot(x_src, R.T), x_tgt, src2tgt, lexicon_size=lexicon_size)
print("[final] NN = %.4f - Coverage = %.4f" % (nnacc, len(src2tgt) / lexicon_size))
if params.output != "":
print("Saving all aligned vectors at %s" % params.output)
words_full, x_full = load_vectors(params.src_emb, maxload=-1, center=params.center, verbose=False)
x = np.dot(x_full, R.T)
x /= np.linalg.norm(x, axis=1)[:, np.newaxis] + 1e-8
save_vectors(params.output, x, words_full)
save_matrix(params.output + "-mat", R)
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/�����������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�014355� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/����������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�017043� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/README.md�������������������������������������������������������0000644�0001750�0000176�00000001140�13651775021�020316� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Fast Linear Model for Knowledge Graph Embeddings
## Knowledge base completion
These scripts require the [fastText library](https://github.com/facebookresearch/fastText).
Run the data.sh script to download and format the datasets. Then run any of the scripts to train and test on a given dataset.
## Reference
If you use this code please cite:
@article{joulin2017fast,
title={Fast Linear Model for Knowledge Graph Embeddings},
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Nickel, Maximilian and Mikolov, Tomas},
journal={arXiv preprint arXiv:1710.10881},
year={2017}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/data.sh���������������������������������������������������������0000755�0001750�0000176�00000004630�13651775021�020316� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# Copyright (c) 2017-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
#
set -e
DATADIR=data/
if [ ! -d "$DATADIR" ]; then
mkdir $DATADIR
fi
cd $DATADIR
echo "preparing WN18"
#wget -P . https://everest.hds.utc.fr/lib/exe/fetch.php?media=en:wordnet-mlj12.tar.gz
#mv fetch.php\?media\=en\:wordnet-mlj12.tar.gz wordnet-mlj12.tar.gz
wget -P . https://github.com/mana-ysh/knowledge-graph-embeddings/raw/master/dat/wordnet-mlj12.tar.gz
tar -xzvf wordnet-mlj12.tar.gz
DIR=wordnet-mlj12
for f in ${DIR}/wordnet-ml*.txt;
do
fn=${DIR}/ft_$(basename $f)
awk '{print "__label__"$1,"0_"$2, $3;print $1,"1_"$2," __label__"$3}' < ${f} > ${fn};
done
cat ${DIR}/ft_* > ${DIR}/ft_wordnet-mlj12-full.txt
cat ${DIR}/ft_*train.txt ${DIR}/ft_*valid.txt > ${DIR}/ft_wordnet-mlj12-valid+train.txt
echo "preparing FB15K"
#wget https://everest.hds.utc.fr/lib/exe/fetch.php?media=en:fb15k.tgz
#mv fetch.php\?media\=en\:fb15k.tgz fb15k.tgz
wget https://github.com/mana-ysh/knowledge-graph-embeddings/raw/master/dat/fb15k.tgz
tar -xzvf fb15k.tgz
DIR=FB15k/
for f in ${DIR}/freebase*.txt;
do
fn=${DIR}/ft_$(basename $f)
echo $f " --> " $fn
awk '{print "__label__"$1,"0_"$2, $3;print $1,"1_"$2," __label__"$3}' < ${f} > ${fn};
done
cat ${DIR}/ft_* > ${DIR}/ft_freebase_mtr100_mte100-full.txt
cat ${DIR}/ft_*train.txt ${DIR}/ft_*valid.txt > ${DIR}/ft_freebase_mtr100_mte100-valid+train.txt
echo "preparing FB15K-237"
wget https://download.microsoft.com/download/8/7/0/8700516A-AB3D-4850-B4BB-805C515AECE1/FB15K-237.2.zip
unzip FB15K-237.2.zip
DIR=Release/
for f in train.txt test.txt valid.txt
do
fn=${DIR}/ft_$(basename $f)
echo $f " --> " $fn
awk -F "\t" '{print "__label__"$1,"0_"$2, $3;print $1,"1_"$2," __label__"$3}' < ${DIR}/${f} > ${fn};
done
cat ${DIR}/ft_*.txt > ${DIR}/ft_full.txt
cat ${DIR}/ft_train.txt ${DIR}/ft_valid.txt > ${DIR}/ft_valid+train.txt
echo "preparing SVO"
wget . https://everest.hds.utc.fr/lib/exe/fetch.php?media=en:svo-tensor-dataset.tar.gz
mv fetch.php?media=en:svo-tensor-dataset.tar.gz svo-tensor-dataset.tar.gz
tar -xzvf svo-tensor-dataset.tar.gz
DIR=SVO-tensor-dataset
for f in ${DIR}/svo_data*.dat;
do
fn=${DIR}/ft_$(basename $f)
awk '{print "0_"$1,"1_"$3,"__label__"$2;}' < ${f} > ${fn};
done
cat ${DIR}/ft_*train*.dat ${DIR}/ft_*valid*.dat > ${DIR}/ft_svo_data-valid+train.dat
��������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/svo.sh����������������������������������������������������������0000755�0001750�0000176�00000002010�13651775021�020202� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# copyright (c) 2017-present, facebook, inc.
# all rights reserved.
#
# this source code is licensed under the MIT license found in the
# license file in the root directory of this source tree.
#
# script for SVO
DIR=data/SVO-tensor-dataset
FASTTEXTDIR=../../
# compile
pushd $FASTTEXTDIR
make opt
popd
ft=${FASTTEXTDIR}/fasttext
## Train model and test it on validation:
dim=200
epoch=3
model=svo
echo "---- train ----"
time $ft supervised -input ${DIR}/ft_svo_data_train_1000000.dat \
-dim $dim -epoch $epoch -output ${model} -lr .2 -thread 20
echo "computing raw hit@5%..."
$ft test ${model}.bin ${DIR}/ft_svo_data_test_250000.dat 227 2> /dev/null | awk '{if(NR==3) print "raw hit@5%="$2}'
echo "---- train + valid ----"
time $ft supervised -input ${DIR}/ft_svo_data-valid+train.dat \
-dim $dim -epoch $epoch -output ${model} -lr .2 -thread 20
echo "computing raw hit@5%..."
$ft test ${model}.bin ${DIR}/ft_svo_data_test_250000.dat 227 2> /dev/null | awk '{if(NR==3) print "raw hit@5%="$2}'
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/fb15k237.sh�����������������������������������������������������0000755�0001750�0000176�00000002266�13651775021�020554� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# copyright (c) 2017-present, facebook, inc.
# all rights reserved.
#
# this source code is licensed under the MIT license found in the
# license file in the root directory of this source tree.
#
# script for FB15k237
DIR=data/Release/
FASTTEXTDIR=../../
# compile
pushd $FASTTEXTDIR
make opt
popd
ft=${FASTTEXTDIR}/fasttext
g++ -std=c++0x eval.cpp -o eval
## Train model and test it on validation:
pred=data/fb237pred
model=data/fb15k237
dim=50
epoch=10
neg=500
echo "---- train ----"
$ft supervised -input $DIR/ft_train.txt \
-dim $dim -epoch $epoch -output ${model} -lr .2 -thread 20 -loss ns -neg $neg -minCount 0
echo "computing filtered hit@10..."
$ft predict ${model}.bin $DIR/ft_test.txt 20000 > $pred
./eval $pred ${DIR}/ft_test.txt $DIR/ft_full.txt 10 | awk '{if(NR==2) print "filtered hit@10="$2}'
echo "---- train+val ----"
$ft supervised -input $DIR/ft_valid+train.txt \
-dim ${dim} -epoch ${dim} -output ${model} -lr .2 -thread 20 -loss ns -neg ${neg} -minCount 0
echo "computing filtered hit@10..."
$ft predict ${model}.bin $DIR/ft_test.txt 20000 > $pred
./eval $pred ${DIR}/ft_test.txt $DIR/ft_full.txt 10 | awk '{if(NR==2) print "filtered hit@10="$2}'
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/eval.cpp��������������������������������������������������������0000644�0001750�0000176�00000005267�13651775021�020510� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2017-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include
#include
#include
#include
#include
std::string EOS = "";
bool readWord(std::istream& in, std::string& word)
{
char c;
std::streambuf& sb = *in.rdbuf();
word.clear();
while ((c = sb.sbumpc()) != EOF) {
if (c == ' ' || c == '\n' || c == '\r' || c == '\t' || c == '\v' ||
c == '\f' || c == '\0') {
if (word.empty()) {
if (c == '\n') {
word += EOS;
return true;
}
continue;
} else {
if (c == '\n')
sb.sungetc();
return true;
}
}
word.push_back(c);
}
in.get();
return !word.empty();
}
int main(int argc, char** argv) {
int k = 10;
if (argc < 4) {
std::cerr<<"eval []"< > KB;
while (kbf.peek() != EOF) {
std::string label, key, word;
while (readWord(kbf, word)) {
if (word == EOS) {break;}
if (word.find("__label__") == 0) {label = word;}
else {key += "|" + word;}
}
KB[key][label] = true;
}
kbf.close();
double precision = 0.0;
int32_t nexamples = 0;
while (predf.peek() != EOF || gtf.peek() != EOF) {
if (predf.peek() == EOF || gtf.peek() == EOF) {
std::cerr<<"pred / gt files have diff sizes"< /dev/null | awk '{if(NR==3) print "raw hit@10="$2}'
echo "computing filtered hit@10..."
$ft predict ${model}.bin $DIR/ft_freebase_mtr100_mte100-test.txt 20000 > $pred
./eval $pred ${DIR}/ft_freebase_mtr100_mte100-test.txt $DIR/ft_freebase_mtr100_mte100-full.txt 10 | awk '{if(NR==2) print "filtered hit@10="$2}'
echo "---- train+val ----"
$ft supervised -input $DIR/ft_freebase_mtr100_mte100-valid+train.txt \
-dim ${dim} -epoch ${dim} -output ${model} -lr .2 -thread 20 -loss ns -neg ${neg} -minCount 0
echo "computing raw hits@10..."
$ft test ${model}.bin $DIR/ft_freebase_mtr100_mte100-test.txt 10 2> /dev/null | awk '{if(NR==3) print "raw hit@10="$2}'
echo "computing filtered hit@10..."
$ft predict ${model}.bin $DIR/ft_freebase_mtr100_mte100-test.txt 20000 > $pred
./eval $pred ${DIR}/ft_freebase_mtr100_mte100-test.txt $DIR/ft_freebase_mtr100_mte100-full.txt 10 | awk '{if(NR==2) print "filtered hit@10="$2}'
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/kbcompletion/wn18.sh���������������������������������������������������������0000755�0001750�0000176�00000003053�13651775021�020200� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# copyright (c) 2017-present, facebook, inc.
# all rights reserved.
#
# this source code is licensed under the MIT license found in the
# license file in the root directory of this source tree.
#
# script for WN11
DIR=data/wordnet-mlj12/
FASTTEXTDIR=../../
# compile
pushd $FASTTEXTDIR
make opt
popd
ft=${FASTTEXTDIR}/fasttext
g++ -std=c++0x eval.cpp -o eval
# Train model and test it:
dim=100
epoch=100
neg=500
model=data/wn
pred=data/wnpred
echo "---- train ----"
$ft supervised -input ${DIR}/ft_wordnet-mlj12-train.txt \
-dim $dim -epoch $epoch -output ${model} -lr .2 -thread 20 -loss ns -neg $neg
echo "computing raw hits@10..."
$ft test ${model}.bin ${DIR}/ft_wordnet-mlj12-test.txt 10 2> /dev/null | awk '{if(NR==3) print "raw hit@10 = "$2}'
echo "computing filtered hit@10..."
$ft predict ${model}.bin ${DIR}/ft_wordnet-mlj12-test.txt 20000 > $pred
./eval $pred ${DIR}/ft_wordnet-mlj12-test.txt $DIR/ft_wordnet-mlj12-full.txt 10 | awk '{if(NR==2) print "filtered hit@10 = "$2}'
echo "---- train+val ----"
$ft supervised -input ${DIR}/ft_wordnet-mlj12-valid+train.txt \
-dim $dim -epoch $epoch -output ${model} -lr .2 -thread 20 -loss ns -neg $neg
echo "computing raw hits@10..."
$ft test ${model}.bin ${DIR}/ft_wordnet-mlj12-test.txt 10 2> /dev/null | awk '{if(NR==3) print "raw hit@10 = "$2}'
echo "computing filtered hit@10..."
$ft predict ${model}.bin ${DIR}/ft_wordnet-mlj12-test.txt 20000 > $pred
./eval $pred ${DIR}/ft_wordnet-mlj12-test.txt $DIR/ft_wordnet-mlj12-full.txt 10 | awk '{if(NR==2) print "filtered hit@10 = "$2}'
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/quantization/����������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�017103� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/scripts/quantization/quantization-results.sh�����������������������������������������0000644�0001750�0000176�00000002235�13651775021�023666� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
#
# Copyright (c) 2016-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
#
# This script applies quantization to the models from Table 1 in:
# Bag of Tricks for Efficient Text Classification, arXiv 1607.01759, 2016
set -e
DATASET=(
ag_news
sogou_news
dbpedia
yelp_review_polarity
yelp_review_full
yahoo_answers
amazon_review_full
amazon_review_polarity
)
# These learning rates were chosen by validation on a subset of the training set.
LR=( 0.25 0.5 0.5 0.1 0.1 0.1 0.05 0.05 )
RESULTDIR=result
DATADIR=data
echo 'Warning! Make sure you run the classification-results.sh script before this one'
echo 'Otherwise you can expect the commands in this script to fail'
for i in {0..7}
do
echo "Working on dataset ${DATASET[i]}"
../../fasttext quantize -input "${DATADIR}/${DATASET[i]}.train" \
-output "${RESULTDIR}/${DATASET[i]}" -lr "${LR[i]}" \
-thread 4 -qnorm -retrain -epoch 5 -cutoff 100000 > /dev/null
../../fasttext test "${RESULTDIR}/${DATASET[i]}.ftz" \
"${DATADIR}/${DATASET[i]}.test"
done
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/���������������������������������������������������������������������������������0000755�0001750�0000176�00000000000�13651775021�013455� 5����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/dictionary.h���������������������������������������������������������������������0000644�0001750�0000176�00000006017�13651775021�015777� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
#include
#include
#include "args.h"
#include "real.h"
namespace fasttext {
typedef int32_t id_type;
enum class entry_type : int8_t { word = 0, label = 1 };
struct entry {
std::string word;
int64_t count;
entry_type type;
std::vector subwords;
};
class Dictionary {
protected:
static const int32_t MAX_VOCAB_SIZE = 30000000;
static const int32_t MAX_LINE_SIZE = 1024;
int32_t find(const std::string&) const;
int32_t find(const std::string&, uint32_t h) const;
void initTableDiscard();
void initNgrams();
void reset(std::istream&) const;
void pushHash(std::vector&, int32_t) const;
void addSubwords(std::vector&, const std::string&, int32_t) const;
std::shared_ptr args_;
std::vector word2int_;
std::vector words_;
std::vector pdiscard_;
int32_t size_;
int32_t nwords_;
int32_t nlabels_;
int64_t ntokens_;
int64_t pruneidx_size_;
std::unordered_map pruneidx_;
void addWordNgrams(
std::vector& line,
const std::vector& hashes,
int32_t n) const;
public:
static const std::string EOS;
static const std::string BOW;
static const std::string EOW;
explicit Dictionary(std::shared_ptr);
explicit Dictionary(std::shared_ptr, std::istream&);
int32_t nwords() const;
int32_t nlabels() const;
int64_t ntokens() const;
int32_t getId(const std::string&) const;
int32_t getId(const std::string&, uint32_t h) const;
entry_type getType(int32_t) const;
entry_type getType(const std::string&) const;
bool discard(int32_t, real) const;
std::string getWord(int32_t) const;
const std::vector& getSubwords(int32_t) const;
const std::vector getSubwords(const std::string&) const;
void getSubwords(
const std::string&,
std::vector&,
std::vector&) const;
void computeSubwords(
const std::string&,
std::vector&,
std::vector* substrings = nullptr) const;
uint32_t hash(const std::string& str) const;
void add(const std::string&);
bool readWord(std::istream&, std::string&) const;
void readFromFile(std::istream&);
std::string getLabel(int32_t) const;
void save(std::ostream&) const;
void load(std::istream&);
std::vector getCounts(entry_type) const;
int32_t getLine(std::istream&, std::vector&, std::vector&)
const;
int32_t getLine(std::istream&, std::vector&, std::minstd_rand&)
const;
void threshold(int64_t, int64_t);
void prune(std::vector&);
bool isPruned() {
return pruneidx_size_ >= 0;
}
void dump(std::ostream&) const;
void init();
};
} // namespace fasttext
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/matrix.h�������������������������������������������������������������������������0000644�0001750�0000176�00000001714�13651775021�015135� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
#include "real.h"
namespace fasttext {
class Vector;
class Matrix {
protected:
int64_t m_;
int64_t n_;
public:
Matrix();
explicit Matrix(int64_t, int64_t);
virtual ~Matrix() = default;
int64_t size(int64_t dim) const;
virtual real dotRow(const Vector&, int64_t) const = 0;
virtual void addVectorToRow(const Vector&, int64_t, real) = 0;
virtual void addRowToVector(Vector& x, int32_t i) const = 0;
virtual void addRowToVector(Vector& x, int32_t i, real a) const = 0;
virtual void save(std::ostream&) const = 0;
virtual void load(std::istream&) = 0;
virtual void dump(std::ostream&) const = 0;
};
} // namespace fasttext
����������������������������������������������������fastText-0.9.2/src/vector.h�������������������������������������������������������������������������0000644�0001750�0000176�00000002371�13651775021�015133� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include "real.h"
namespace fasttext {
class Matrix;
class Vector {
protected:
std::vector data_;
public:
explicit Vector(int64_t);
Vector(const Vector&) = default;
Vector(Vector&&) noexcept = default;
Vector& operator=(const Vector&) = default;
Vector& operator=(Vector&&) = default;
inline real* data() {
return data_.data();
}
inline const real* data() const {
return data_.data();
}
inline real& operator[](int64_t i) {
return data_[i];
}
inline const real& operator[](int64_t i) const {
return data_[i];
}
inline int64_t size() const {
return data_.size();
}
void zero();
void mul(real);
real norm() const;
void addVector(const Vector& source);
void addVector(const Vector&, real);
void addRow(const Matrix&, int64_t);
void addRow(const Matrix&, int64_t, real);
void mul(const Matrix&, const Vector&);
int64_t argmax();
};
std::ostream& operator<<(std::ostream&, const Vector&);
} // namespace fasttext
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/real.h���������������������������������������������������������������������������0000644�0001750�0000176�00000000412�13651775021�014546� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
namespace fasttext {
typedef float real;
}
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/densematrix.cc�������������������������������������������������������������������0000644�0001750�0000176�00000010206�13651775021�016306� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include "densematrix.h"
#include
#include
#include
#include
#include "utils.h"
#include "vector.h"
namespace fasttext {
DenseMatrix::DenseMatrix() : DenseMatrix(0, 0) {}
DenseMatrix::DenseMatrix(int64_t m, int64_t n) : Matrix(m, n), data_(m * n) {}
DenseMatrix::DenseMatrix(DenseMatrix&& other) noexcept
: Matrix(other.m_, other.n_), data_(std::move(other.data_)) {}
DenseMatrix::DenseMatrix(int64_t m, int64_t n, real* dataPtr)
: Matrix(m, n), data_(dataPtr, dataPtr + (m * n)) {}
void DenseMatrix::zero() {
std::fill(data_.begin(), data_.end(), 0.0);
}
void DenseMatrix::uniformThread(real a, int block, int32_t seed) {
std::minstd_rand rng(block + seed);
std::uniform_real_distribution<> uniform(-a, a);
int64_t blockSize = (m_ * n_) / 10;
for (int64_t i = blockSize * block;
i < (m_ * n_) && i < blockSize * (block + 1);
i++) {
data_[i] = uniform(rng);
}
}
void DenseMatrix::uniform(real a, unsigned int thread, int32_t seed) {
if (thread > 1) {
std::vector threads;
for (int i = 0; i < thread; i++) {
threads.push_back(std::thread([=]() { uniformThread(a, i, seed); }));
}
for (int32_t i = 0; i < threads.size(); i++) {
threads[i].join();
}
} else {
// webassembly can't instantiate `std::thread`
uniformThread(a, 0, seed);
}
}
void DenseMatrix::multiplyRow(const Vector& nums, int64_t ib, int64_t ie) {
if (ie == -1) {
ie = m_;
}
assert(ie <= nums.size());
for (auto i = ib; i < ie; i++) {
real n = nums[i - ib];
if (n != 0) {
for (auto j = 0; j < n_; j++) {
at(i, j) *= n;
}
}
}
}
void DenseMatrix::divideRow(const Vector& denoms, int64_t ib, int64_t ie) {
if (ie == -1) {
ie = m_;
}
assert(ie <= denoms.size());
for (auto i = ib; i < ie; i++) {
real n = denoms[i - ib];
if (n != 0) {
for (auto j = 0; j < n_; j++) {
at(i, j) /= n;
}
}
}
}
real DenseMatrix::l2NormRow(int64_t i) const {
auto norm = 0.0;
for (auto j = 0; j < n_; j++) {
norm += at(i, j) * at(i, j);
}
if (std::isnan(norm)) {
throw EncounteredNaNError();
}
return std::sqrt(norm);
}
void DenseMatrix::l2NormRow(Vector& norms) const {
assert(norms.size() == m_);
for (auto i = 0; i < m_; i++) {
norms[i] = l2NormRow(i);
}
}
real DenseMatrix::dotRow(const Vector& vec, int64_t i) const {
assert(i >= 0);
assert(i < m_);
assert(vec.size() == n_);
real d = 0.0;
for (int64_t j = 0; j < n_; j++) {
d += at(i, j) * vec[j];
}
if (std::isnan(d)) {
throw EncounteredNaNError();
}
return d;
}
void DenseMatrix::addVectorToRow(const Vector& vec, int64_t i, real a) {
assert(i >= 0);
assert(i < m_);
assert(vec.size() == n_);
for (int64_t j = 0; j < n_; j++) {
data_[i * n_ + j] += a * vec[j];
}
}
void DenseMatrix::addRowToVector(Vector& x, int32_t i) const {
assert(i >= 0);
assert(i < this->size(0));
assert(x.size() == this->size(1));
for (int64_t j = 0; j < n_; j++) {
x[j] += at(i, j);
}
}
void DenseMatrix::addRowToVector(Vector& x, int32_t i, real a) const {
assert(i >= 0);
assert(i < this->size(0));
assert(x.size() == this->size(1));
for (int64_t j = 0; j < n_; j++) {
x[j] += a * at(i, j);
}
}
void DenseMatrix::save(std::ostream& out) const {
out.write((char*)&m_, sizeof(int64_t));
out.write((char*)&n_, sizeof(int64_t));
out.write((char*)data_.data(), m_ * n_ * sizeof(real));
}
void DenseMatrix::load(std::istream& in) {
in.read((char*)&m_, sizeof(int64_t));
in.read((char*)&n_, sizeof(int64_t));
data_ = std::vector(m_ * n_);
in.read((char*)data_.data(), m_ * n_ * sizeof(real));
}
void DenseMatrix::dump(std::ostream& out) const {
out << m_ << " " << n_ << std::endl;
for (int64_t i = 0; i < m_; i++) {
for (int64_t j = 0; j < n_; j++) {
if (j > 0) {
out << " ";
}
out << at(i, j);
}
out << std::endl;
}
};
} // namespace fasttext
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/utils.h��������������������������������������������������������������������������0000644�0001750�0000176�00000003272�13651775021�014772� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include "real.h"
#include
#include
#include
#include
#include
#if defined(__clang__) || defined(__GNUC__)
#define FASTTEXT_DEPRECATED(msg) __attribute__((__deprecated__(msg)))
#elif defined(_MSC_VER)
#define FASTTEXT_DEPRECATED(msg) __declspec(deprecated(msg))
#else
#define FASTTEXT_DEPRECATED(msg)
#endif
namespace fasttext {
using Predictions = std::vector>;
namespace utils {
int64_t size(std::ifstream&);
void seek(std::ifstream&, int64_t);
template
bool contains(const std::vector& container, const T& value) {
return std::find(container.begin(), container.end(), value) !=
container.end();
}
template
bool containsSecond(
const std::vector>& container,
const T2& value) {
return std::find_if(
container.begin(),
container.end(),
[&value](const std::pair& item) {
return item.second == value;
}) != container.end();
}
double getDuration(
const std::chrono::steady_clock::time_point& start,
const std::chrono::steady_clock::time_point& end);
class ClockPrint {
public:
explicit ClockPrint(int32_t duration);
friend std::ostream& operator<<(std::ostream& out, const ClockPrint& me);
private:
int32_t duration_;
};
bool compareFirstLess(const std::pair& l, const double& r);
} // namespace utils
} // namespace fasttext
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/productquantizer.h���������������������������������������������������������������0000644�0001750�0000176�00000003107�13651775021�017252� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
#include "real.h"
#include "vector.h"
namespace fasttext {
class ProductQuantizer {
protected:
const int32_t nbits_ = 8;
const int32_t ksub_ = 1 << nbits_;
const int32_t max_points_per_cluster_ = 256;
const int32_t max_points_ = max_points_per_cluster_ * ksub_;
const int32_t seed_ = 1234;
const int32_t niter_ = 25;
const real eps_ = 1e-7;
int32_t dim_;
int32_t nsubq_;
int32_t dsub_;
int32_t lastdsub_;
std::vector centroids_;
std::minstd_rand rng;
public:
ProductQuantizer() {}
ProductQuantizer(int32_t, int32_t);
real* get_centroids(int32_t, uint8_t);
const real* get_centroids(int32_t, uint8_t) const;
real assign_centroid(const real*, const real*, uint8_t*, int32_t) const;
void Estep(const real*, const real*, uint8_t*, int32_t, int32_t) const;
void MStep(const real*, real*, const uint8_t*, int32_t, int32_t);
void kmeans(const real*, real*, int32_t, int32_t);
void train(int, const real*);
real mulcode(const Vector&, const uint8_t*, int32_t, real) const;
void addcode(Vector&, const uint8_t*, int32_t, real) const;
void compute_code(const real*, uint8_t*) const;
void compute_codes(const real*, uint8_t*, int32_t) const;
void save(std::ostream&) const;
void load(std::istream&);
};
} // namespace fasttext
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/utils.cc�������������������������������������������������������������������������0000644�0001750�0000176�00000002373�13651775021�015131� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include "utils.h"
#include
#include
namespace fasttext {
namespace utils {
int64_t size(std::ifstream& ifs) {
ifs.seekg(std::streamoff(0), std::ios::end);
return ifs.tellg();
}
void seek(std::ifstream& ifs, int64_t pos) {
ifs.clear();
ifs.seekg(std::streampos(pos));
}
double getDuration(
const std::chrono::steady_clock::time_point& start,
const std::chrono::steady_clock::time_point& end) {
return std::chrono::duration_cast>(end - start)
.count();
}
ClockPrint::ClockPrint(int32_t duration) : duration_(duration) {}
std::ostream& operator<<(std::ostream& out, const ClockPrint& me) {
int32_t etah = me.duration_ / 3600;
int32_t etam = (me.duration_ % 3600) / 60;
int32_t etas = (me.duration_ % 3600) % 60;
out << std::setw(3) << etah << "h" << std::setw(2) << etam << "m";
out << std::setw(2) << etas << "s";
return out;
}
bool compareFirstLess(const std::pair& l, const double& r) {
return l.first < r;
}
} // namespace utils
} // namespace fasttext
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/autotune.h�����������������������������������������������������������������������0000644�0001750�0000176�00000004332�13651775021�015474� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
#include "args.h"
#include "fasttext.h"
namespace fasttext {
class AutotuneStrategy {
private:
Args bestArgs_;
int maxDuration_;
std::minstd_rand rng_;
int trials_;
int bestMinnIndex_;
int bestDsubExponent_;
int bestNonzeroBucket_;
int originalBucket_;
std::vector minnChoices_;
int getIndex(int val, const std::vector& choices);
public:
explicit AutotuneStrategy(
const Args& args,
std::minstd_rand::result_type seed);
Args ask(double elapsed);
void updateBest(const Args& args);
};
class Autotune {
protected:
std::shared_ptr fastText_;
double elapsed_;
double bestScore_;
int32_t trials_;
int32_t sizeConstraintFailed_;
std::atomic continueTraining_;
std::unique_ptr strategy_;
std::thread timer_;
bool keepTraining(double maxDuration) const;
void printInfo(double maxDuration);
void timer(
const std::chrono::steady_clock::time_point& start,
double maxDuration);
void abort();
void startTimer(const Args& args);
double getMetricScore(
Meter& meter,
const metric_name& metricName,
const double metricValue,
const std::string& metricLabel) const;
void printArgs(const Args& args, const Args& autotuneArgs);
void printSkippedArgs(const Args& autotuneArgs);
bool quantize(Args& args, const Args& autotuneArgs);
int getCutoffForFileSize(bool qout, bool qnorm, int dsub, int64_t fileSize)
const;
class TimeoutError : public std::runtime_error {
public:
TimeoutError() : std::runtime_error("Autotune timed out.") {}
};
public:
Autotune() = delete;
explicit Autotune(const std::shared_ptr& fastText);
Autotune(const Autotune&) = delete;
Autotune(Autotune&&) = delete;
Autotune& operator=(const Autotune&) = delete;
Autotune& operator=(Autotune&&) = delete;
~Autotune() noexcept = default;
void train(const Args& args);
};
} // namespace fasttext
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/args.h���������������������������������������������������������������������������0000644�0001750�0000176�00000004200�13651775021�014556� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
namespace fasttext {
enum class model_name : int { cbow = 1, sg, sup };
enum class loss_name : int { hs = 1, ns, softmax, ova };
enum class metric_name : int {
f1score = 1,
f1scoreLabel,
precisionAtRecall,
precisionAtRecallLabel,
recallAtPrecision,
recallAtPrecisionLabel
};
class Args {
protected:
std::string boolToString(bool) const;
std::string modelToString(model_name) const;
std::string metricToString(metric_name) const;
std::unordered_set manualArgs_;
public:
Args();
std::string input;
std::string output;
double lr;
int lrUpdateRate;
int dim;
int ws;
int epoch;
int minCount;
int minCountLabel;
int neg;
int wordNgrams;
loss_name loss;
model_name model;
int bucket;
int minn;
int maxn;
int thread;
double t;
std::string label;
int verbose;
std::string pretrainedVectors;
bool saveOutput;
int seed;
bool qout;
bool retrain;
bool qnorm;
size_t cutoff;
size_t dsub;
std::string autotuneValidationFile;
std::string autotuneMetric;
int autotunePredictions;
int autotuneDuration;
std::string autotuneModelSize;
void parseArgs(const std::vector& args);
void printHelp();
void printBasicHelp();
void printDictionaryHelp();
void printTrainingHelp();
void printAutotuneHelp();
void printQuantizationHelp();
void save(std::ostream&);
void load(std::istream&);
void dump(std::ostream&) const;
bool hasAutotune() const;
bool isManual(const std::string& argName) const;
void setManual(const std::string& argName);
std::string lossToString(loss_name) const;
metric_name getAutotuneMetric() const;
std::string getAutotuneMetricLabel() const;
double getAutotuneMetricValue() const;
int64_t getAutotuneModelSize() const;
static constexpr double kUnlimitedModelSize = -1.0;
};
} // namespace fasttext
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/meter.h��������������������������������������������������������������������������0000644�0001750�0000176�00000004716�13651775021�014752� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include "dictionary.h"
#include "real.h"
#include "utils.h"
namespace fasttext {
class Meter {
struct Metrics {
uint64_t gold;
uint64_t predicted;
uint64_t predictedGold;
mutable std::vector> scoreVsTrue;
Metrics() : gold(0), predicted(0), predictedGold(0), scoreVsTrue() {}
double precision() const {
if (predicted == 0) {
return std::numeric_limits::quiet_NaN();
}
return predictedGold / double(predicted);
}
double recall() const {
if (gold == 0) {
return std::numeric_limits::quiet_NaN();
}
return predictedGold / double(gold);
}
double f1Score() const {
if (predicted + gold == 0) {
return std::numeric_limits::quiet_NaN();
}
return 2 * predictedGold / double(predicted + gold);
}
std::vector> getScoreVsTrue() {
return scoreVsTrue;
}
};
std::vector> getPositiveCounts(
int32_t labelId) const;
public:
Meter() = delete;
explicit Meter(bool falseNegativeLabels)
: metrics_(),
nexamples_(0),
labelMetrics_(),
falseNegativeLabels_(falseNegativeLabels) {}
void log(const std::vector& labels, const Predictions& predictions);
double precision(int32_t);
double recall(int32_t);
double f1Score(int32_t);
std::vector> scoreVsTrue(int32_t labelId) const;
double precisionAtRecall(int32_t labelId, double recall) const;
double precisionAtRecall(double recall) const;
double recallAtPrecision(int32_t labelId, double recall) const;
double recallAtPrecision(double recall) const;
std::vector> precisionRecallCurve(
int32_t labelId) const;
std::vector> precisionRecallCurve() const;
double precision() const;
double recall() const;
double f1Score() const;
uint64_t nexamples() const {
return nexamples_;
}
void writeGeneralMetrics(std::ostream& out, int32_t k) const;
private:
Metrics metrics_{};
uint64_t nexamples_;
std::unordered_map labelMetrics_;
bool falseNegativeLabels_;
};
} // namespace fasttext
��������������������������������������������������fastText-0.9.2/src/args.cc��������������������������������������������������������������������������0000644�0001750�0000176�00000037553�13651775021�014735� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include "args.h"
#include
#include
#include
#include
#include
namespace fasttext {
Args::Args() {
lr = 0.05;
dim = 100;
ws = 5;
epoch = 5;
minCount = 5;
minCountLabel = 0;
neg = 5;
wordNgrams = 1;
loss = loss_name::ns;
model = model_name::sg;
bucket = 2000000;
minn = 3;
maxn = 6;
thread = 12;
lrUpdateRate = 100;
t = 1e-4;
label = "__label__";
verbose = 2;
pretrainedVectors = "";
saveOutput = false;
seed = 0;
qout = false;
retrain = false;
qnorm = false;
cutoff = 0;
dsub = 2;
autotuneValidationFile = "";
autotuneMetric = "f1";
autotunePredictions = 1;
autotuneDuration = 60 * 5; // 5 minutes
autotuneModelSize = "";
}
std::string Args::lossToString(loss_name ln) const {
switch (ln) {
case loss_name::hs:
return "hs";
case loss_name::ns:
return "ns";
case loss_name::softmax:
return "softmax";
case loss_name::ova:
return "one-vs-all";
}
return "Unknown loss!"; // should never happen
}
std::string Args::boolToString(bool b) const {
if (b) {
return "true";
} else {
return "false";
}
}
std::string Args::modelToString(model_name mn) const {
switch (mn) {
case model_name::cbow:
return "cbow";
case model_name::sg:
return "sg";
case model_name::sup:
return "sup";
}
return "Unknown model name!"; // should never happen
}
std::string Args::metricToString(metric_name mn) const {
switch (mn) {
case metric_name::f1score:
return "f1score";
case metric_name::f1scoreLabel:
return "f1scoreLabel";
case metric_name::precisionAtRecall:
return "precisionAtRecall";
case metric_name::precisionAtRecallLabel:
return "precisionAtRecallLabel";
case metric_name::recallAtPrecision:
return "recallAtPrecision";
case metric_name::recallAtPrecisionLabel:
return "recallAtPrecisionLabel";
}
return "Unknown metric name!"; // should never happen
}
void Args::parseArgs(const std::vector& args) {
std::string command(args[1]);
if (command == "supervised") {
model = model_name::sup;
loss = loss_name::softmax;
minCount = 1;
minn = 0;
maxn = 0;
lr = 0.1;
} else if (command == "cbow") {
model = model_name::cbow;
}
for (int ai = 2; ai < args.size(); ai += 2) {
if (args[ai][0] != '-') {
std::cerr << "Provided argument without a dash! Usage:" << std::endl;
printHelp();
exit(EXIT_FAILURE);
}
try {
setManual(args[ai].substr(1));
if (args[ai] == "-h") {
std::cerr << "Here is the help! Usage:" << std::endl;
printHelp();
exit(EXIT_FAILURE);
} else if (args[ai] == "-input") {
input = std::string(args.at(ai + 1));
} else if (args[ai] == "-output") {
output = std::string(args.at(ai + 1));
} else if (args[ai] == "-lr") {
lr = std::stof(args.at(ai + 1));
} else if (args[ai] == "-lrUpdateRate") {
lrUpdateRate = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-dim") {
dim = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-ws") {
ws = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-epoch") {
epoch = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-minCount") {
minCount = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-minCountLabel") {
minCountLabel = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-neg") {
neg = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-wordNgrams") {
wordNgrams = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-loss") {
if (args.at(ai + 1) == "hs") {
loss = loss_name::hs;
} else if (args.at(ai + 1) == "ns") {
loss = loss_name::ns;
} else if (args.at(ai + 1) == "softmax") {
loss = loss_name::softmax;
} else if (
args.at(ai + 1) == "one-vs-all" || args.at(ai + 1) == "ova") {
loss = loss_name::ova;
} else {
std::cerr << "Unknown loss: " << args.at(ai + 1) << std::endl;
printHelp();
exit(EXIT_FAILURE);
}
} else if (args[ai] == "-bucket") {
bucket = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-minn") {
minn = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-maxn") {
maxn = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-thread") {
thread = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-t") {
t = std::stof(args.at(ai + 1));
} else if (args[ai] == "-label") {
label = std::string(args.at(ai + 1));
} else if (args[ai] == "-verbose") {
verbose = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-pretrainedVectors") {
pretrainedVectors = std::string(args.at(ai + 1));
} else if (args[ai] == "-saveOutput") {
saveOutput = true;
ai--;
} else if (args[ai] == "-seed") {
seed = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-qnorm") {
qnorm = true;
ai--;
} else if (args[ai] == "-retrain") {
retrain = true;
ai--;
} else if (args[ai] == "-qout") {
qout = true;
ai--;
} else if (args[ai] == "-cutoff") {
cutoff = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-dsub") {
dsub = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-autotune-validation") {
autotuneValidationFile = std::string(args.at(ai + 1));
} else if (args[ai] == "-autotune-metric") {
autotuneMetric = std::string(args.at(ai + 1));
getAutotuneMetric(); // throws exception if not able to parse
getAutotuneMetricLabel(); // throws exception if not able to parse
} else if (args[ai] == "-autotune-predictions") {
autotunePredictions = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-autotune-duration") {
autotuneDuration = std::stoi(args.at(ai + 1));
} else if (args[ai] == "-autotune-modelsize") {
autotuneModelSize = std::string(args.at(ai + 1));
} else {
std::cerr << "Unknown argument: " << args[ai] << std::endl;
printHelp();
exit(EXIT_FAILURE);
}
} catch (std::out_of_range) {
std::cerr << args[ai] << " is missing an argument" << std::endl;
printHelp();
exit(EXIT_FAILURE);
}
}
if (input.empty() || output.empty()) {
std::cerr << "Empty input or output path." << std::endl;
printHelp();
exit(EXIT_FAILURE);
}
if (wordNgrams <= 1 && maxn == 0 && !hasAutotune()) {
bucket = 0;
}
}
void Args::printHelp() {
printBasicHelp();
printDictionaryHelp();
printTrainingHelp();
printAutotuneHelp();
printQuantizationHelp();
}
void Args::printBasicHelp() {
std::cerr << "\nThe following arguments are mandatory:\n"
<< " -input training file path\n"
<< " -output output file path\n"
<< "\nThe following arguments are optional:\n"
<< " -verbose verbosity level [" << verbose << "]\n";
}
void Args::printDictionaryHelp() {
std::cerr << "\nThe following arguments for the dictionary are optional:\n"
<< " -minCount minimal number of word occurences ["
<< minCount << "]\n"
<< " -minCountLabel minimal number of label occurences ["
<< minCountLabel << "]\n"
<< " -wordNgrams max length of word ngram [" << wordNgrams
<< "]\n"
<< " -bucket number of buckets [" << bucket << "]\n"
<< " -minn min length of char ngram [" << minn
<< "]\n"
<< " -maxn max length of char ngram [" << maxn
<< "]\n"
<< " -t sampling threshold [" << t << "]\n"
<< " -label labels prefix [" << label << "]\n";
}
void Args::printTrainingHelp() {
std::cerr
<< "\nThe following arguments for training are optional:\n"
<< " -lr learning rate [" << lr << "]\n"
<< " -lrUpdateRate change the rate of updates for the learning "
"rate ["
<< lrUpdateRate << "]\n"
<< " -dim size of word vectors [" << dim << "]\n"
<< " -ws size of the context window [" << ws << "]\n"
<< " -epoch number of epochs [" << epoch << "]\n"
<< " -neg number of negatives sampled [" << neg << "]\n"
<< " -loss loss function {ns, hs, softmax, one-vs-all} ["
<< lossToString(loss) << "]\n"
<< " -thread number of threads (set to 1 to ensure "
"reproducible results) ["
<< thread << "]\n"
<< " -pretrainedVectors pretrained word vectors for supervised "
"learning ["
<< pretrainedVectors << "]\n"
<< " -saveOutput whether output params should be saved ["
<< boolToString(saveOutput) << "]\n"
<< " -seed random generator seed [" << seed << "]\n";
}
void Args::printAutotuneHelp() {
std::cerr << "\nThe following arguments are for autotune:\n"
<< " -autotune-validation validation file to be used "
"for evaluation\n"
<< " -autotune-metric metric objective {f1, "
"f1:labelname} ["
<< autotuneMetric << "]\n"
<< " -autotune-predictions number of predictions used "
"for evaluation ["
<< autotunePredictions << "]\n"
<< " -autotune-duration maximum duration in seconds ["
<< autotuneDuration << "]\n"
<< " -autotune-modelsize constraint model file size ["
<< autotuneModelSize << "] (empty = do not quantize)\n";
}
void Args::printQuantizationHelp() {
std::cerr
<< "\nThe following arguments for quantization are optional:\n"
<< " -cutoff number of words and ngrams to retain ["
<< cutoff << "]\n"
<< " -retrain whether embeddings are finetuned if a cutoff "
"is applied ["
<< boolToString(retrain) << "]\n"
<< " -qnorm whether the norm is quantized separately ["
<< boolToString(qnorm) << "]\n"
<< " -qout whether the classifier is quantized ["
<< boolToString(qout) << "]\n"
<< " -dsub size of each sub-vector [" << dsub << "]\n";
}
void Args::save(std::ostream& out) {
out.write((char*)&(dim), sizeof(int));
out.write((char*)&(ws), sizeof(int));
out.write((char*)&(epoch), sizeof(int));
out.write((char*)&(minCount), sizeof(int));
out.write((char*)&(neg), sizeof(int));
out.write((char*)&(wordNgrams), sizeof(int));
out.write((char*)&(loss), sizeof(loss_name));
out.write((char*)&(model), sizeof(model_name));
out.write((char*)&(bucket), sizeof(int));
out.write((char*)&(minn), sizeof(int));
out.write((char*)&(maxn), sizeof(int));
out.write((char*)&(lrUpdateRate), sizeof(int));
out.write((char*)&(t), sizeof(double));
}
void Args::load(std::istream& in) {
in.read((char*)&(dim), sizeof(int));
in.read((char*)&(ws), sizeof(int));
in.read((char*)&(epoch), sizeof(int));
in.read((char*)&(minCount), sizeof(int));
in.read((char*)&(neg), sizeof(int));
in.read((char*)&(wordNgrams), sizeof(int));
in.read((char*)&(loss), sizeof(loss_name));
in.read((char*)&(model), sizeof(model_name));
in.read((char*)&(bucket), sizeof(int));
in.read((char*)&(minn), sizeof(int));
in.read((char*)&(maxn), sizeof(int));
in.read((char*)&(lrUpdateRate), sizeof(int));
in.read((char*)&(t), sizeof(double));
}
void Args::dump(std::ostream& out) const {
out << "dim"
<< " " << dim << std::endl;
out << "ws"
<< " " << ws << std::endl;
out << "epoch"
<< " " << epoch << std::endl;
out << "minCount"
<< " " << minCount << std::endl;
out << "neg"
<< " " << neg << std::endl;
out << "wordNgrams"
<< " " << wordNgrams << std::endl;
out << "loss"
<< " " << lossToString(loss) << std::endl;
out << "model"
<< " " << modelToString(model) << std::endl;
out << "bucket"
<< " " << bucket << std::endl;
out << "minn"
<< " " << minn << std::endl;
out << "maxn"
<< " " << maxn << std::endl;
out << "lrUpdateRate"
<< " " << lrUpdateRate << std::endl;
out << "t"
<< " " << t << std::endl;
}
bool Args::hasAutotune() const {
return !autotuneValidationFile.empty();
}
bool Args::isManual(const std::string& argName) const {
return (manualArgs_.count(argName) != 0);
}
void Args::setManual(const std::string& argName) {
manualArgs_.emplace(argName);
}
metric_name Args::getAutotuneMetric() const {
if (autotuneMetric.substr(0, 3) == "f1:") {
return metric_name::f1scoreLabel;
} else if (autotuneMetric == "f1") {
return metric_name::f1score;
} else if (autotuneMetric.substr(0, 18) == "precisionAtRecall:") {
size_t semicolon = autotuneMetric.find(":", 18);
if (semicolon != std::string::npos) {
return metric_name::precisionAtRecallLabel;
}
return metric_name::precisionAtRecall;
} else if (autotuneMetric.substr(0, 18) == "recallAtPrecision:") {
size_t semicolon = autotuneMetric.find(":", 18);
if (semicolon != std::string::npos) {
return metric_name::recallAtPrecisionLabel;
}
return metric_name::recallAtPrecision;
}
throw std::runtime_error("Unknown metric : " + autotuneMetric);
}
std::string Args::getAutotuneMetricLabel() const {
metric_name metric = getAutotuneMetric();
std::string label;
if (metric == metric_name::f1scoreLabel) {
label = autotuneMetric.substr(3);
} else if (
metric == metric_name::precisionAtRecallLabel ||
metric == metric_name::recallAtPrecisionLabel) {
size_t semicolon = autotuneMetric.find(":", 18);
label = autotuneMetric.substr(semicolon + 1);
} else {
return label;
}
if (label.empty()) {
throw std::runtime_error("Empty metric label : " + autotuneMetric);
}
return label;
}
double Args::getAutotuneMetricValue() const {
metric_name metric = getAutotuneMetric();
double value = 0.0;
if (metric == metric_name::precisionAtRecallLabel ||
metric == metric_name::precisionAtRecall ||
metric == metric_name::recallAtPrecisionLabel ||
metric == metric_name::recallAtPrecision) {
size_t firstSemicolon = 18; // semicolon position in "precisionAtRecall:"
size_t secondSemicolon = autotuneMetric.find(":", firstSemicolon);
const std::string valueStr =
autotuneMetric.substr(firstSemicolon, secondSemicolon - firstSemicolon);
value = std::stof(valueStr) / 100.0;
}
return value;
}
int64_t Args::getAutotuneModelSize() const {
std::string modelSize = autotuneModelSize;
if (modelSize.empty()) {
return Args::kUnlimitedModelSize;
}
std::unordered_map units = {
{'k', 1000},
{'K', 1000},
{'m', 1000000},
{'M', 1000000},
{'g', 1000000000},
{'G', 1000000000},
};
uint64_t multiplier = 1;
char lastCharacter = modelSize.back();
if (units.count(lastCharacter)) {
multiplier = units[lastCharacter];
modelSize = modelSize.substr(0, modelSize.size() - 1);
}
uint64_t size = 0;
size_t nonNumericCharacter = 0;
bool parseError = false;
try {
size = std::stol(modelSize, &nonNumericCharacter);
} catch (std::invalid_argument&) {
parseError = true;
}
if (!parseError && nonNumericCharacter != modelSize.size()) {
parseError = true;
}
if (parseError) {
throw std::invalid_argument(
"Unable to parse model size " + autotuneModelSize);
}
return size * multiplier;
}
} // namespace fasttext
�����������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/productquantizer.cc��������������������������������������������������������������0000644�0001750�0000176�00000014132�13651775021�017410� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include "productquantizer.h"
#include
#include
#include
#include
#include
namespace fasttext {
real distL2(const real* x, const real* y, int32_t d) {
real dist = 0;
for (auto i = 0; i < d; i++) {
auto tmp = x[i] - y[i];
dist += tmp * tmp;
}
return dist;
}
ProductQuantizer::ProductQuantizer(int32_t dim, int32_t dsub)
: dim_(dim),
nsubq_(dim / dsub),
dsub_(dsub),
centroids_(dim * ksub_),
rng(seed_) {
lastdsub_ = dim_ % dsub;
if (lastdsub_ == 0) {
lastdsub_ = dsub_;
} else {
nsubq_++;
}
}
const real* ProductQuantizer::get_centroids(int32_t m, uint8_t i) const {
if (m == nsubq_ - 1) {
return ¢roids_[m * ksub_ * dsub_ + i * lastdsub_];
}
return ¢roids_[(m * ksub_ + i) * dsub_];
}
real* ProductQuantizer::get_centroids(int32_t m, uint8_t i) {
if (m == nsubq_ - 1) {
return ¢roids_[m * ksub_ * dsub_ + i * lastdsub_];
}
return ¢roids_[(m * ksub_ + i) * dsub_];
}
real ProductQuantizer::assign_centroid(
const real* x,
const real* c0,
uint8_t* code,
int32_t d) const {
const real* c = c0;
real dis = distL2(x, c, d);
code[0] = 0;
for (auto j = 1; j < ksub_; j++) {
c += d;
real disij = distL2(x, c, d);
if (disij < dis) {
code[0] = (uint8_t)j;
dis = disij;
}
}
return dis;
}
void ProductQuantizer::Estep(
const real* x,
const real* centroids,
uint8_t* codes,
int32_t d,
int32_t n) const {
for (auto i = 0; i < n; i++) {
assign_centroid(x + i * d, centroids, codes + i, d);
}
}
void ProductQuantizer::MStep(
const real* x0,
real* centroids,
const uint8_t* codes,
int32_t d,
int32_t n) {
std::vector nelts(ksub_, 0);
memset(centroids, 0, sizeof(real) * d * ksub_);
const real* x = x0;
for (auto i = 0; i < n; i++) {
auto k = codes[i];
real* c = centroids + k * d;
for (auto j = 0; j < d; j++) {
c[j] += x[j];
}
nelts[k]++;
x += d;
}
real* c = centroids;
for (auto k = 0; k < ksub_; k++) {
real z = (real)nelts[k];
if (z != 0) {
for (auto j = 0; j < d; j++) {
c[j] /= z;
}
}
c += d;
}
std::uniform_real_distribution<> runiform(0, 1);
for (auto k = 0; k < ksub_; k++) {
if (nelts[k] == 0) {
int32_t m = 0;
while (runiform(rng) * (n - ksub_) >= nelts[m] - 1) {
m = (m + 1) % ksub_;
}
memcpy(centroids + k * d, centroids + m * d, sizeof(real) * d);
for (auto j = 0; j < d; j++) {
int32_t sign = (j % 2) * 2 - 1;
centroids[k * d + j] += sign * eps_;
centroids[m * d + j] -= sign * eps_;
}
nelts[k] = nelts[m] / 2;
nelts[m] -= nelts[k];
}
}
}
void ProductQuantizer::kmeans(const real* x, real* c, int32_t n, int32_t d) {
std::vector perm(n, 0);
std::iota(perm.begin(), perm.end(), 0);
std::shuffle(perm.begin(), perm.end(), rng);
for (auto i = 0; i < ksub_; i++) {
memcpy(&c[i * d], x + perm[i] * d, d * sizeof(real));
}
auto codes = std::vector(n);
for (auto i = 0; i < niter_; i++) {
Estep(x, c, codes.data(), d, n);
MStep(x, c, codes.data(), d, n);
}
}
void ProductQuantizer::train(int32_t n, const real* x) {
if (n < ksub_) {
throw std::invalid_argument(
"Matrix too small for quantization, must have at least " +
std::to_string(ksub_) + " rows");
}
std::vector perm(n, 0);
std::iota(perm.begin(), perm.end(), 0);
auto d = dsub_;
auto np = std::min(n, max_points_);
auto xslice = std::vector(np * dsub_);
for (auto m = 0; m < nsubq_; m++) {
if (m == nsubq_ - 1) {
d = lastdsub_;
}
if (np != n) {
std::shuffle(perm.begin(), perm.end(), rng);
}
for (auto j = 0; j < np; j++) {
memcpy(
xslice.data() + j * d,
x + perm[j] * dim_ + m * dsub_,
d * sizeof(real));
}
kmeans(xslice.data(), get_centroids(m, 0), np, d);
}
}
real ProductQuantizer::mulcode(
const Vector& x,
const uint8_t* codes,
int32_t t,
real alpha) const {
real res = 0.0;
auto d = dsub_;
const uint8_t* code = codes + nsubq_ * t;
for (auto m = 0; m < nsubq_; m++) {
const real* c = get_centroids(m, code[m]);
if (m == nsubq_ - 1) {
d = lastdsub_;
}
for (auto n = 0; n < d; n++) {
res += x[m * dsub_ + n] * c[n];
}
}
return res * alpha;
}
void ProductQuantizer::addcode(
Vector& x,
const uint8_t* codes,
int32_t t,
real alpha) const {
auto d = dsub_;
const uint8_t* code = codes + nsubq_ * t;
for (auto m = 0; m < nsubq_; m++) {
const real* c = get_centroids(m, code[m]);
if (m == nsubq_ - 1) {
d = lastdsub_;
}
for (auto n = 0; n < d; n++) {
x[m * dsub_ + n] += alpha * c[n];
}
}
}
void ProductQuantizer::compute_code(const real* x, uint8_t* code) const {
auto d = dsub_;
for (auto m = 0; m < nsubq_; m++) {
if (m == nsubq_ - 1) {
d = lastdsub_;
}
assign_centroid(x + m * dsub_, get_centroids(m, 0), code + m, d);
}
}
void ProductQuantizer::compute_codes(const real* x, uint8_t* codes, int32_t n)
const {
for (auto i = 0; i < n; i++) {
compute_code(x + i * dim_, codes + i * nsubq_);
}
}
void ProductQuantizer::save(std::ostream& out) const {
out.write((char*)&dim_, sizeof(dim_));
out.write((char*)&nsubq_, sizeof(nsubq_));
out.write((char*)&dsub_, sizeof(dsub_));
out.write((char*)&lastdsub_, sizeof(lastdsub_));
out.write((char*)centroids_.data(), centroids_.size() * sizeof(real));
}
void ProductQuantizer::load(std::istream& in) {
in.read((char*)&dim_, sizeof(dim_));
in.read((char*)&nsubq_, sizeof(nsubq_));
in.read((char*)&dsub_, sizeof(dsub_));
in.read((char*)&lastdsub_, sizeof(lastdsub_));
centroids_.resize(dim_ * ksub_);
for (auto i = 0; i < centroids_.size(); i++) {
in.read((char*)¢roids_[i], sizeof(real));
}
}
} // namespace fasttext
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fastText-0.9.2/src/fasttext.cc����������������������������������������������������������������������0000644�0001750�0000176�00000057667�13651775021�015653� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#include "fasttext.h"
#include "loss.h"
#include "quantmatrix.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace fasttext {
constexpr int32_t FASTTEXT_VERSION = 12; /* Version 1b */
constexpr int32_t FASTTEXT_FILEFORMAT_MAGIC_INT32 = 793712314;
bool comparePairs(
const std::pair& l,
const std::pair& r);
std::shared_ptr FastText::createLoss(std::shared_ptr& output) {
loss_name lossName = args_->loss;
switch (lossName) {
case loss_name::hs:
return std::make_shared(
output, getTargetCounts());
case loss_name::ns:
return std::make_shared(
output, args_->neg, getTargetCounts());
case loss_name::softmax:
return std::make_shared(output);
case loss_name::ova:
return std::make_shared(output);
default:
throw std::runtime_error("Unknown loss");
}
}
FastText::FastText()
: quant_(false), wordVectors_(nullptr), trainException_(nullptr) {}
void FastText::addInputVector(Vector& vec, int32_t ind) const {
vec.addRow(*input_, ind);
}
std::shared_ptr FastText::getDictionary() const {
return dict_;
}
const Args FastText::getArgs() const {
return *args_.get();
}
std::shared_ptr FastText::getInputMatrix() const {
if (quant_) {
throw std::runtime_error("Can't export quantized matrix");
}
assert(input_.get());
return std::dynamic_pointer_cast(input_);
}
void FastText::setMatrices(
const std::shared_ptr& inputMatrix,
const std::shared_ptr& outputMatrix) {
assert(input_->size(1) == output_->size(1));
input_ = std::dynamic_pointer_cast(inputMatrix);
output_ = std::dynamic_pointer_cast(outputMatrix);
wordVectors_.reset();
args_->dim = input_->size(1);
buildModel();
}
std::shared_ptr FastText::getOutputMatrix() const {
if (quant_ && args_->qout) {
throw std::runtime_error("Can't export quantized matrix");
}
assert(output_.get());
return std::dynamic_pointer_cast(output_);
}
int32_t FastText::getWordId(const std::string& word) const {
return dict_->getId(word);
}
int32_t FastText::getSubwordId(const std::string& subword) const {
int32_t h = dict_->hash(subword) % args_->bucket;
return dict_->nwords() + h;
}
int32_t FastText::getLabelId(const std::string& label) const {
int32_t labelId = dict_->getId(label);
if (labelId != -1) {
labelId -= dict_->nwords();
}
return labelId;
}
void FastText::getWordVector(Vector& vec, const std::string& word) const {
const std::vector& ngrams = dict_->getSubwords(word);
vec.zero();
for (int i = 0; i < ngrams.size(); i++) {
addInputVector(vec, ngrams[i]);
}
if (ngrams.size() > 0) {
vec.mul(1.0 / ngrams.size());
}
}
void FastText::getSubwordVector(Vector& vec, const std::string& subword) const {
vec.zero();
int32_t h = dict_->hash(subword) % args_->bucket;
h = h + dict_->nwords();
addInputVector(vec, h);
}
void FastText::saveVectors(const std::string& filename) {
if (!input_ || !output_) {
throw std::runtime_error("Model never trained");
}
std::ofstream ofs(filename);
if (!ofs.is_open()) {
throw std::invalid_argument(
filename + " cannot be opened for saving vectors!");
}
ofs << dict_->nwords() << " " << args_->dim << std::endl;
Vector vec(args_->dim);
for (int32_t i = 0; i < dict_->nwords(); i++) {
std::string word = dict_->getWord(i);
getWordVector(vec, word);
ofs << word << " " << vec << std::endl;
}
ofs.close();
}
void FastText::saveOutput(const std::string& filename) {
std::ofstream ofs(filename);
if (!ofs.is_open()) {
throw std::invalid_argument(
filename + " cannot be opened for saving vectors!");
}
if (quant_) {
throw std::invalid_argument(
"Option -saveOutput is not supported for quantized models.");
}
int32_t n =
(args_->model == model_name::sup) ? dict_->nlabels() : dict_->nwords();
ofs << n << " " << args_->dim << std::endl;
Vector vec(args_->dim);
for (int32_t i = 0; i < n; i++) {
std::string word = (args_->model == model_name::sup) ? dict_->getLabel(i)
: dict_->getWord(i);
vec.zero();
vec.addRow(*output_, i);
ofs << word << " " << vec << std::endl;
}
ofs.close();
}
bool FastText::checkModel(std::istream& in) {
int32_t magic;
in.read((char*)&(magic), sizeof(int32_t));
if (magic != FASTTEXT_FILEFORMAT_MAGIC_INT32) {
return false;
}
in.read((char*)&(version), sizeof(int32_t));
if (version > FASTTEXT_VERSION) {
return false;
}
return true;
}
void FastText::signModel(std::ostream& out) {
const int32_t magic = FASTTEXT_FILEFORMAT_MAGIC_INT32;
const int32_t version = FASTTEXT_VERSION;
out.write((char*)&(magic), sizeof(int32_t));
out.write((char*)&(version), sizeof(int32_t));
}
void FastText::saveModel(const std::string& filename) {
std::ofstream ofs(filename, std::ofstream::binary);
if (!ofs.is_open()) {
throw std::invalid_argument(filename + " cannot be opened for saving!");
}
if (!input_ || !output_) {
throw std::runtime_error("Model never trained");
}
signModel(ofs);
args_->save(ofs);
dict_->save(ofs);
ofs.write((char*)&(quant_), sizeof(bool));
input_->save(ofs);
ofs.write((char*)&(args_->qout), sizeof(bool));
output_->save(ofs);
ofs.close();
}
void FastText::loadModel(const std::string& filename) {
std::ifstream ifs(filename, std::ifstream::binary);
if (!ifs.is_open()) {
throw std::invalid_argument(filename + " cannot be opened for loading!");
}
if (!checkModel(ifs)) {
throw std::invalid_argument(filename + " has wrong file format!");
}
loadModel(ifs);
ifs.close();
}
std::vector FastText::getTargetCounts() const {
if (args_->model == model_name::sup) {
return dict_->getCounts(entry_type::label);
} else {
return dict_->getCounts(entry_type::word);
}
}
void FastText::buildModel() {
auto loss = createLoss(output_);
bool normalizeGradient = (args_->model == model_name::sup);
model_ = std::make_shared(input_, output_, loss, normalizeGradient);
}
void FastText::loadModel(std::istream& in) {
args_ = std::make_shared();
input_ = std::make_shared();
output_ = std::make_shared();
args_->load(in);
if (version == 11 && args_->model == model_name::sup) {
// backward compatibility: old supervised models do not use char ngrams.
args_->maxn = 0;
}
dict_ = std::make_shared(args_, in);
bool quant_input;
in.read((char*)&quant_input, sizeof(bool));
if (quant_input) {
quant_ = true;
input_ = std::make_shared();
}
input_->load(in);
if (!quant_input && dict_->isPruned()) {
throw std::invalid_argument(
"Invalid model file.\n"
"Please download the updated model from www.fasttext.cc.\n"
"See issue #332 on Github for more information.\n");
}
in.read((char*)&args_->qout, sizeof(bool));
if (quant_ && args_->qout) {
output_ = std::make_shared();
}
output_->load(in);
buildModel();
}
std::tuple FastText::progressInfo(real progress) {
double t = utils::getDuration(start_, std::chrono::steady_clock::now());
double lr = args_->lr * (1.0 - progress);
double wst = 0;
int64_t eta = 2592000; // Default to one month in seconds (720 * 3600)
if (progress > 0 && t >= 0) {
eta = t * (1 - progress) / progress;
wst = double(tokenCount_) / t / args_->thread;
}
return std::tuple(wst, lr, eta);
}
void FastText::printInfo(real progress, real loss, std::ostream& log_stream) {
double wst;
double lr;
int64_t eta;
std::tie(wst, lr, eta) = progressInfo(progress);
log_stream << std::fixed;
log_stream << "Progress: ";
log_stream << std::setprecision(1) << std::setw(5) << (progress * 100) << "%";
log_stream << " words/sec/thread: " << std::setw(7) << int64_t(wst);
log_stream << " lr: " << std::setw(9) << std::setprecision(6) << lr;
log_stream << " avg.loss: " << std::setw(9) << std::setprecision(6) << loss;
log_stream << " ETA: " << utils::ClockPrint(eta);
log_stream << std::flush;
}
std::vector FastText::selectEmbeddings(int32_t cutoff) const {
std::shared_ptr input =
std::dynamic_pointer_cast(input_);
Vector norms(input->size(0));
input->l2NormRow(norms);
std::vector idx(input->size(0), 0);
std::iota(idx.begin(), idx.end(), 0);
auto eosid = dict_->getId(Dictionary::EOS);
std::sort(idx.begin(), idx.end(), [&norms, eosid](size_t i1, size_t i2) {
if (i1 == eosid && i2 == eosid) { // satisfy strict weak ordering
return false;
}
return eosid == i1 || (eosid != i2 && norms[i1] > norms[i2]);
});
idx.erase(idx.begin() + cutoff, idx.end());
return idx;
}
void FastText::quantize(const Args& qargs, const TrainCallback& callback) {
if (args_->model != model_name::sup) {
throw std::invalid_argument(
"For now we only support quantization of supervised models");
}
args_->input = qargs.input;
args_->qout = qargs.qout;
args_->output = qargs.output;
std::shared_ptr input =
std::dynamic_pointer_cast(input_);
std::shared_ptr output =
std::dynamic_pointer_cast(output_);
bool normalizeGradient = (args_->model == model_name::sup);
if (qargs.cutoff > 0 && qargs.cutoff < input->size(0)) {
auto idx = selectEmbeddings(qargs.cutoff);
dict_->prune(idx);
std::shared_ptr ninput =
std::make_shared(idx.size(), args_->dim);
for (auto i = 0; i < idx.size(); i++) {
for (auto j = 0; j < args_->dim; j++) {
ninput->at(i, j) = input->at(idx[i], j);
}
}
input = ninput;
if (qargs.retrain) {
args_->epoch = qargs.epoch;
args_->lr = qargs.lr;
args_->thread = qargs.thread;
args_->verbose = qargs.verbose;
auto loss = createLoss(output_);
model_ = std::make_shared(input, output, loss, normalizeGradient);
startThreads(callback);
}
}
input_ = std::make_shared(
std::move(*(input.get())), qargs.dsub, qargs.qnorm);
if (args_->qout) {
output_ = std::make_shared(
std::move(*(output.get())), 2, qargs.qnorm);
}
quant_ = true;
auto loss = createLoss(output_);
model_ = std::make_shared(input_, output_, loss, normalizeGradient);
}
void FastText::supervised(
Model::State& state,
real lr,
const std::vector& line,
const std::vector& labels) {
if (labels.size() == 0 || line.size() == 0) {
return;
}
if (args_->loss == loss_name::ova) {
model_->update(line, labels, Model::kAllLabelsAsTarget, lr, state);
} else {
std::uniform_int_distribution<> uniform(0, labels.size() - 1);
int32_t i = uniform(state.rng);
model_->update(line, labels, i, lr, state);
}
}
void FastText::cbow(
Model::State& state,
real lr,
const std::vector& line) {
std::vector bow;
std::uniform_int_distribution<> uniform(1, args_->ws);
for (int32_t w = 0; w < line.size(); w++) {
int32_t boundary = uniform(state.rng);
bow.clear();
for (int32_t c = -boundary; c <= boundary; c++) {
if (c != 0 && w + c >= 0 && w + c < line.size()) {
const std::vector& ngrams = dict_->getSubwords(line[w + c]);
bow.insert(bow.end(), ngrams.cbegin(), ngrams.cend());
}
}
model_->update(bow, line, w, lr, state);
}
}
void FastText::skipgram(
Model::State& state,
real lr,
const std::vector& line) {
std::uniform_int_distribution<> uniform(1, args_->ws);
for (int32_t w = 0; w < line.size(); w++) {
int32_t boundary = uniform(state.rng);
const std::vector& ngrams = dict_->getSubwords(line[w]);
for (int32_t c = -boundary; c <= boundary; c++) {
if (c != 0 && w + c >= 0 && w + c < line.size()) {
model_->update(ngrams, line, w + c, lr, state);
}
}
}
}
std::tuple
FastText::test(std::istream& in, int32_t k, real threshold) {
Meter meter(false);
test(in, k, threshold, meter);
return std::tuple(
meter.nexamples(), meter.precision(), meter.recall());
}
void FastText::test(std::istream& in, int32_t k, real threshold, Meter& meter)
const {
std::vector line;
std::vector labels;
Predictions predictions;
Model::State state(args_->dim, dict_->nlabels(), 0);
in.clear();
in.seekg(0, std::ios_base::beg);
while (in.peek() != EOF) {
line.clear();
labels.clear();
dict_->getLine(in, line, labels);
if (!labels.empty() && !line.empty()) {
predictions.clear();
predict(k, line, predictions, threshold);
meter.log(labels, predictions);
}
}
}
void FastText::predict(
int32_t k,
const std::vector& words,
Predictions& predictions,
real threshold) const {
if (words.empty()) {
return;
}
Model::State state(args_->dim, dict_->nlabels(), 0);
if (args_->model != model_name::sup) {
throw std::invalid_argument("Model needs to be supervised for prediction!");
}
model_->predict(words, k, threshold, predictions, state);
}
bool FastText::predictLine(
std::istream& in,
std::vector>& predictions,
int32_t k,
real threshold) const {
predictions.clear();
if (in.peek() == EOF) {
return false;
}
std::vector words, labels;
dict_->getLine(in, words, labels);
Predictions linePredictions;
predict(k, words, linePredictions, threshold);
for (const auto& p : linePredictions) {
predictions.push_back(
std::make_pair(std::exp(p.first), dict_->getLabel(p.second)));
}
return true;
}
void FastText::getSentenceVector(std::istream& in, fasttext::Vector& svec) {
svec.zero();
if (args_->model == model_name::sup) {
std::vector line, labels;
dict_->getLine(in, line, labels);
for (int32_t i = 0; i < line.size(); i++) {
addInputVector(svec, line[i]);
}
if (!line.empty()) {
svec.mul(1.0 / line.size());
}
} else {
Vector vec(args_->dim);
std::string sentence;
std::getline(in, sentence);
std::istringstream iss(sentence);
std::string word;
int32_t count = 0;
while (iss >> word) {
getWordVector(vec, word);
real norm = vec.norm();
if (norm > 0) {
vec.mul(1.0 / norm);
svec.addVector(vec);
count++;
}
}
if (count > 0) {
svec.mul(1.0 / count);
}
}
}
std::vector> FastText::getNgramVectors(
const std::string& word) const {
std::vector> result;
std::vector ngrams;
std::vector substrings;
dict_->getSubwords(word, ngrams, substrings);
assert(ngrams.size() <= substrings.size());
for (int32_t i = 0; i < ngrams.size(); i++) {
Vector vec(args_->dim);
if (ngrams[i] >= 0) {
vec.addRow(*input_, ngrams[i]);
}
result.push_back(std::make_pair(substrings[i], std::move(vec)));
}
return result;
}
void FastText::precomputeWordVectors(DenseMatrix& wordVectors) {
Vector vec(args_->dim);
wordVectors.zero();
for (int32_t i = 0; i < dict_->nwords(); i++) {
std::string word = dict_->getWord(i);
getWordVector(vec, word);
real norm = vec.norm();
if (norm > 0) {
wordVectors.addVectorToRow(vec, i, 1.0 / norm);
}
}
}
void FastText::lazyComputeWordVectors() {
if (!wordVectors_) {
wordVectors_ = std::unique_ptr(
new DenseMatrix(dict_->nwords(), args_->dim));
precomputeWordVectors(*wordVectors_);
}
}
std::vector> FastText::getNN(
const std::string& word,
int32_t k) {
Vector query(args_->dim);
getWordVector(query, word);
lazyComputeWordVectors();
assert(wordVectors_);
return getNN(*wordVectors_, query, k, {word});
}
std::vector> FastText::getNN(
const DenseMatrix& wordVectors,
const Vector& query,
int32_t k,
const std::set& banSet) {
std::vector> heap;
real queryNorm = query.norm();
if (std::abs(queryNorm) < 1e-8) {
queryNorm = 1;
}
for (int32_t i = 0; i < dict_->nwords(); i++) {
std::string word = dict_->getWord(i);
if (banSet.find(word) == banSet.end()) {
real dp = wordVectors.dotRow(query, i);
real similarity = dp / queryNorm;
if (heap.size() == k && similarity < heap.front().first) {
continue;
}
heap.push_back(std::make_pair(similarity, word));
std::push_heap(heap.begin(), heap.end(), comparePairs);
if (heap.size() > k) {
std::pop_heap(heap.begin(), heap.end(), comparePairs);
heap.pop_back();
}
}
}
std::sort_heap(heap.begin(), heap.end(), comparePairs);
return heap;
}
std::vector> FastText::getAnalogies(
int32_t k,
const std::string& wordA,
const std::string& wordB,
const std::string& wordC) {
Vector query = Vector(args_->dim);
query.zero();
Vector buffer(args_->dim);
getWordVector(buffer, wordA);
query.addVector(buffer, 1.0 / (buffer.norm() + 1e-8));
getWordVector(buffer, wordB);
query.addVector(buffer, -1.0 / (buffer.norm() + 1e-8));
getWordVector(buffer, wordC);
query.addVector(buffer, 1.0 / (buffer.norm() + 1e-8));
lazyComputeWordVectors();
assert(wordVectors_);
return getNN(*wordVectors_, query, k, {wordA, wordB, wordC});
}
bool FastText::keepTraining(const int64_t ntokens) const {
return tokenCount_ < args_->epoch * ntokens && !trainException_;
}
void FastText::trainThread(int32_t threadId, const TrainCallback& callback) {
std::ifstream ifs(args_->input);
utils::seek(ifs, threadId * utils::size(ifs) / args_->thread);
Model::State state(args_->dim, output_->size(0), threadId + args_->seed);
const int64_t ntokens = dict_->ntokens();
int64_t localTokenCount = 0;
std::vector line, labels;
uint64_t callbackCounter = 0;
try {
while (keepTraining(ntokens)) {
real progress = real(tokenCount_) / (args_->epoch * ntokens);
if (callback && ((callbackCounter++ % 64) == 0)) {
double wst;
double lr;
int64_t eta;
std::tie(wst, lr, eta) =
progressInfo(progress);
callback(progress, loss_, wst, lr, eta);
}
real lr = args_->lr * (1.0 - progress);
if (args_->model == model_name::sup) {
localTokenCount += dict_->getLine(ifs, line, labels);
supervised(state, lr, line, labels);
} else if (args_->model == model_name::cbow) {
localTokenCount += dict_->getLine(ifs, line, state.rng);
cbow(state, lr, line);
} else if (args_->model == model_name::sg) {
localTokenCount += dict_->getLine(ifs, line, state.rng);
skipgram(state, lr, line);
}
if (localTokenCount > args_->lrUpdateRate) {
tokenCount_ += localTokenCount;
localTokenCount = 0;
if (threadId == 0 && args_->verbose > 1) {
loss_ = state.getLoss();
}
}
}
} catch (DenseMatrix::EncounteredNaNError&) {
trainException_ = std::current_exception();
}
if (threadId == 0)
loss_ = state.getLoss();
ifs.close();
}
std::shared_ptr FastText::getInputMatrixFromFile(
const std::string& filename) const {
std::ifstream in(filename);
std::vector words;
std::shared_ptr mat; // temp. matrix for pretrained vectors
int64_t n, dim;
if (!in.is_open()) {
throw std::invalid_argument(filename + " cannot be opened for loading!");
}
in >> n >> dim;
if (dim != args_->dim) {
throw std::invalid_argument(
"Dimension of pretrained vectors (" + std::to_string(dim) +
") does not match dimension (" + std::to_string(args_->dim) + ")!");
}
mat = std::make_shared(n, dim);
for (size_t i = 0; i < n; i++) {
std::string word;
in >> word;
words.push_back(word);
dict_->add(word);
for (size_t j = 0; j < dim; j++) {
in >> mat->at(i, j);
}
}
in.close();
dict_->threshold(1, 0);
dict_->init();
std::shared_ptr input = std::make_shared(
dict_->nwords() + args_->bucket, args_->dim);
input->uniform(1.0 / args_->dim, args_->thread, args_->seed);
for (size_t i = 0; i < n; i++) {
int32_t idx = dict_->getId(words[i]);
if (idx < 0 || idx >= dict_->nwords()) {
continue;
}
for (size_t j = 0; j < dim; j++) {
input->at(idx, j) = mat->at(i, j);
}
}
return input;
}
std::shared_ptr FastText::createRandomMatrix() const {
std::shared_ptr input = std::make_shared(
dict_->nwords() + args_->bucket, args_->dim);
input->uniform(1.0 / args_->dim, args_->thread, args_->seed);
return input;
}
std::shared_ptr FastText::createTrainOutputMatrix() const {
int64_t m =
(args_->model == model_name::sup) ? dict_->nlabels() : dict_->nwords();
std::shared_ptr output =
std::make_shared(m, args_->dim);
output->zero();
return output;
}
void FastText::train(const Args& args, const TrainCallback& callback) {
args_ = std::make_shared(args);
dict_ = std::make_shared(args_);
if (args_->input == "-") {
// manage expectations
throw std::invalid_argument("Cannot use stdin for training!");
}
std::ifstream ifs(args_->input);
if (!ifs.is_open()) {
throw std::invalid_argument(
args_->input + " cannot be opened for training!");
}
dict_->readFromFile(ifs);
ifs.close();
if (!args_->pretrainedVectors.empty()) {
input_ = getInputMatrixFromFile(args_->pretrainedVectors);
} else {
input_ = createRandomMatrix();
}
output_ = createTrainOutputMatrix();
quant_ = false;
auto loss = createLoss(output_);
bool normalizeGradient = (args_->model == model_name::sup);
model_ = std::make_shared(input_, output_, loss, normalizeGradient);
startThreads(callback);
}
void FastText::abort() {
try {
throw AbortError();
} catch (AbortError&) {
trainException_ = std::current_exception();
}
}
void FastText::startThreads(const TrainCallback& callback) {
start_ = std::chrono::steady_clock::now();
tokenCount_ = 0;
loss_ = -1;
trainException_ = nullptr;
std::vector threads;
if (args_->thread > 1) {
for (int32_t i = 0; i < args_->thread; i++) {
threads.push_back(std::thread([=]() { trainThread(i, callback); }));
}
} else {
// webassembly can't instantiate `std::thread`
trainThread(0, callback);
}
const int64_t ntokens = dict_->ntokens();
// Same condition as trainThread
while (keepTraining(ntokens)) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
if (loss_ >= 0 && args_->verbose > 1) {
real progress = real(tokenCount_) / (args_->epoch * ntokens);
std::cerr << "\r";
printInfo(progress, loss_, std::cerr);
}
}
for (int32_t i = 0; i < threads.size(); i++) {
threads[i].join();
}
if (trainException_) {
std::exception_ptr exception = trainException_;
trainException_ = nullptr;
std::rethrow_exception(exception);
}
if (args_->verbose > 0) {
std::cerr << "\r";
printInfo(1.0, loss_, std::cerr);
std::cerr << std::endl;
}
}
int FastText::getDimension() const {
return args_->dim;
}
bool FastText::isQuant() const {
return quant_;
}
bool comparePairs(
const std::pair& l,
const std::pair& r) {
return l.first > r.first;
}
} // namespace fasttext
�������������������������������������������������������������������������fastText-0.9.2/src/fasttext.h�����������������������������������������������������������������������0000644�0001750�0000176�00000011233�13651775021�015470� 0����������������������������������������������������������������������������������������������������ustar �kenhys��������������������������docker�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/**
* Copyright (c) 2016-present, Facebook, Inc.
* All rights reserved.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*/
#pragma once
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "args.h"
#include "densematrix.h"
#include "dictionary.h"
#include "matrix.h"
#include "meter.h"
#include "model.h"
#include "real.h"
#include "utils.h"
#include "vector.h"
namespace fasttext {
class FastText {
public:
using TrainCallback =
std::function;
protected:
std::shared_ptr args_;
std::shared_ptr dict_;
std::shared_ptr input_;
std::shared_ptr output_;
std::shared_ptr model_;
std::atomic tokenCount_{};
std::atomic loss_{};
std::chrono::steady_clock::time_point start_;
bool quant_;
int32_t version;
std::unique_ptr wordVectors_;
std::exception_ptr trainException_;
void signModel(std::ostream&);
bool checkModel(std::istream&);
void startThreads(const TrainCallback& callback = {});
void addInputVector(Vector&, int32_t) const;
void trainThread(int32_t, const TrainCallback& callback);
std::vector> getNN(
const DenseMatrix& wordVectors,
const Vector& queryVec,
int32_t k,
const std::set& banSet);
void lazyComputeWordVectors();
void printInfo(real, real, std::ostream&);
std::shared_ptr getInputMatrixFromFile(const std::string&) const;
std::shared_ptr createRandomMatrix() const;
std::shared_ptr createTrainOutputMatrix() const;
std::vector getTargetCounts() const;
std::shared_ptr createLoss(std::shared_ptr